第一章、安全规则
模块 1:了解信息保障的安全概念 (D1.1)
CIA
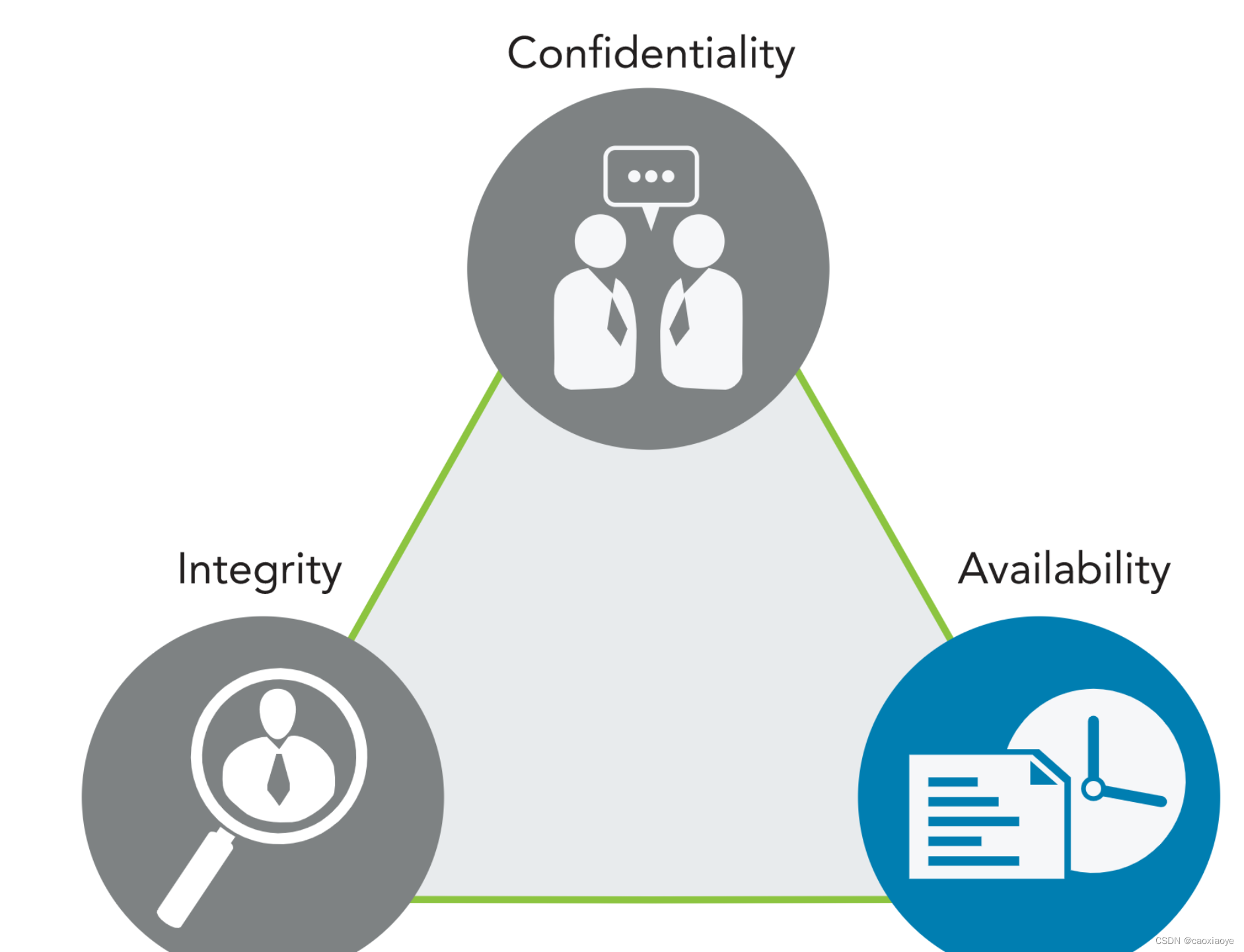
保密 當許多系統用戶是來賓或客戶時,很難實現平衡,並且不知道他們是否從受感染的機器或易受攻擊的移動應用程序訪問系統。 因此,安全專業人員的義務是規範訪問——保護需要保護的數據,但允許授權個人訪問。
個人身份信息 (PII) 是與保密領域相關的術語。 它涉及可用於識別個人身份的任何個人數據。 其他與保密相關的條款是 受保護的健康信息 (PHI) , 這是關於一個人的健康狀況的信息,以及 機密或敏感信息,包括商業秘密、研究、商業計劃和知識產權。
另一個有用的定義是 靈敏度, 這是對其所有者分配給信息的重要性的度量,或者表示其需要保護的目的。 敏感信息是指如果不當披露(保密)或修改(完整性)將會損害組織或個人的信息。 在許多情況下,敏感性與對外部利益相關者的危害有關; 也就是說,可能不屬於處理或使用信息的組織的人員或組織
完整性 衡量事物完整、完整、內部一致和正確的程度。 誠信理念適用於:
- 信息或數據
- 業務運營的系統和流程
- 組織
- 人和他們的行為
數據的完整性 是保證數據沒有以未經授權的方式被更改。 這需要保護系統中和處理過程中的數據,以確保它不會被不當修改、錯誤或信息丟失,並以確保其完整性的方式進行記錄、使用和維護。 數據完整性涵蓋存儲中、處理過程中和傳輸過程中的數據。
信息必須準確、內部一致並且對既定目的有用。 信息的內部一致性確保信息在所有相關係統上都是正確的,以便它在所有系統上以相同的方式顯示和存儲。 作為數據完整性的一部分,一致性要求數據的所有實例在形式、內容和含義上都相同。
系統完整性 是指在系統處理信息時維護已知的良好配置和預期的操作功能。 確保誠信始於對 狀態, 這是系統的當前狀況。 具體來說,這種意識涉及記錄和理解數據或系統在特定時間點的狀態,從而創建基線的能力。 例如,一個基線 可以指信息的當前狀態——它是否受到保護。 然後,為了保持該狀態,信息必須始終通過事務繼續受到保護。
從該基線出發,始終可以通過將基線與當前狀態進行比較來確定數據或系統的完整性。 如果兩者匹配,則數據或系統的完整性完好無損; 如果兩者不匹配,則數據或系統的完整性已受到損害。 完整性是信息和系統可靠性的主要因素。
保護信息和系統完整性的需要可能由法律法規規定。 通常,它取決於組織訪問和使用可靠、準確信息的需要。
可用性 可定義為 (1) 及時可靠地訪問信息和使用信息的能力,以及 (2) 授權用戶及時可靠地訪問數據和信息服務。
可用性的核心概念是授權用戶可以在需要的時間和地點以所需的形式和格式訪問數據。 這並不意味著數據或系統 100% 可用。 相反,系統和數據滿足業務對及時可靠訪問的要求。
有些系統和數據比其他系統和數據重要得多,因此安全專業人員必須確保提供適當級別的可用性。 這需要與相關企業協商,以確保關鍵系統得到識別和可用。 可用性通常與術語相關聯 關鍵性, 因為它代表了組織在執行其操作或實現其使命時對數據或信息系統的重視程度。
验证
当用户表明他们的身份时,有必要验证他们是该身份的合法所有者。这个验证或证明用户身份的过程称为 驗證. 简单来说,认证就是证明请求者身份的过程。
常见的身份验证方法有以下三种:
认证方法
有两种类型的身份验证。仅使用前面所述的一种身份验证方法称为 單因素身份驗證 (SFA) . 只有在成功演示或显示这些方法中的两个或多个之后才授予用户访问权限,这称为 多重身份驗證 (MFA) .
常见的最佳实践是至少实施三种常见的身份验证技术中的两种:
- 以知识为基础
- 基于令牌
- 基于特征
基于知识的身份验证使用密码或密码来区分授权用户和未授权用户。如果您选择了个人识别码 (別針)、创建了密码或其他只有您知道的秘密值,那么您就体验了基于知识的身份验证。单独使用这种类型的身份验证的问题在于它通常容易受到各种攻击。例如,帮助台可能会接到重置用户密码的电话。挑战在于确保只为正确的用户重置密码,而不是假装为该用户的其他人。为了更好的安全性,在重置密码之前需要基于令牌或特征的第二种或第三种形式的身份验证。用户 ID 和密码的组合使用由已知的两件事组成,并且由于它不满足使用两种或多种所述身份验证方法的要求,因此不被视为 MFA。
不可否认性
不可否認性 是一个法律术语,被定义为防止个人错误地否认已执行特定行动的保护。它提供了确定给定个人是否采取特定行动的能力,例如创建信息、批准信息或发送或接收消息。
在当今的电子商务和电子交易世界中,存在冒充他人或拒绝某项行为的机会,例如在线购买并随后拒绝。重要的是所有参与者都信任在线交易。不可否认性方法确保人们对他们进行的交易负责。
隱私
隱私 是个人控制有关自己的信息的分发的权利。虽然安全和隐私都侧重于保护个人和敏感数据,但它们之间存在差异。随着所有行业收集和数字存储数据的速度越来越快,隐私立法和遵守现有政策的推动力稳步增长。在当今的全球经济中,有关隐私和数据保护的隐私立法和法规可能会影响公司和行业,无论其地理位置如何。在考虑有关个人信息的收集和安全的要求时,全球隐私是一个特别重要的问题。有几部法律定义了隐私和数据保护,这些法律会定期更改。确保保护性安全措施到位并不足以满足隐私法规或保护公司免受不当处理、滥用或不当保护个人或私人信息的处罚或罚款。具有跨国影响的法律的一个例子是欧盟的 通用數據保護條例 (通用數據保護條例) 该条例适用于在欧盟开展业务的所有外国或国内组织或欧盟的任何个人。在美国境内经营或开展业务的公司也可能受到监管消费者数据和隐私收集和使用的若干州立法的管辖。同样,欧盟成员国制定法律将 通用數據保護條例 付诸实践,有时还会增加更严格的要求。这些法律,包括国家和州一级的法律,规定世界任何地方处理特定法律管辖范围内人员私人数据的任何实体都必须遵守其隐私要求。作为组织数据保护团队的成员,您不需要解释这些法律,但您需要了解它们如何适用于您的组织。
模块 2:了解风险管理流程 (D1.2)
风险评估
風險評估 被定义为识别、估计和优先考虑对组织的运营(包括其使命、职能、形象和声誉)、资产、个人、其他组织甚至国家的风险的过程。风险评估应导致将信息系统运行所产生的每个已识别风险与组织使用的目标、目标、资产或过程保持一致(或关联),这反过来又与组织的目标和目标保持一致或直接支持实现。
一项常见的风险评估活动可识别建筑物发生火灾的风险。虽然有很多方法可以缓解这种风险,但风险评估的主要目标是估计和确定优先级。例如,火灾警报器成本最低,可以提醒人员撤离并降低人身伤害的风险,但它们不会阻止火势蔓延或造成更大的销毁。喷水灭火系统不能防止火灾,但可以最大限度地减少造成的损失。然而,虽然数据中心的洒水装置限制了火势的蔓延,但它们很可能会销毁其中的所有系统和数据。基于气体的系统可能是保护系统的最佳解决方案,但成本可能过高。风险评估可以对这些项目进行优先级管理,以确定最适合受保护资产的缓解方法。
风险评估过程的结果通常以报告或演示文稿的形式记录在案,以提供给管理层,用于确定已识别风险的优先级。该报告提交给管理层进行审查和批准。在某些情况下,管理层可能表示需要由内部或外部资源进行更深入或更详细的风险评估。
风险处理
風險處理 涉及就已识别和优先处理的风险做出关于采取最佳行动的决策。做出的决定取决于管理层对风险的态度以及风险缓解的可用性和成本。通常用于应对风险的选项有:
規避風險是試圖完全消除風險的決定。 這可能包括停止某些或所有暴露於特定風險的組織活動的運營。 當給定風險的潛在影響太高或風險實現的可能性太大時,組織領導可能會選擇避免風險。
風險接受是不採取任何行動來降低風險發生的可能性。 管理層可能會選擇執行與風險相關的業務功能,而無需組織採取進一步行動,因為影響或發生的可能性可以忽略不計,或者因為收益足以超過風險。
風險緩解是最常見的風險管理類型,包括採取行動預防或減少風險事件或其影響的可能性。 緩解可能涉及補救措施或控制,例如安全控制、建立政策、程序和標準,以最大限度地減少不利風險。 風險無法始終得到緩解,但應始終實施安全措施等緩解措施。
風險轉移是將風險轉移給另一方的做法,另一方將接受因實現風險而造成的損害的財務影響,以換取付款。 這通常是一份保險單。
风险优先级
识别出风险后,就可以通过 定性風險分析 和/或 定量風險分析. 这对于确定根本原因并缩小明显风险和核心风险是必要的。安全专业人员与他们的团队一起进行定性和定量分析。
了解组织的整体使命和支持使命的职能有助于将风险置于上下文中,确定根本原因并优先评估和分析这些项目。在大多数情况下,管理层将为使用风险评估的结果确定一组优先的风险应对措施提供指导。
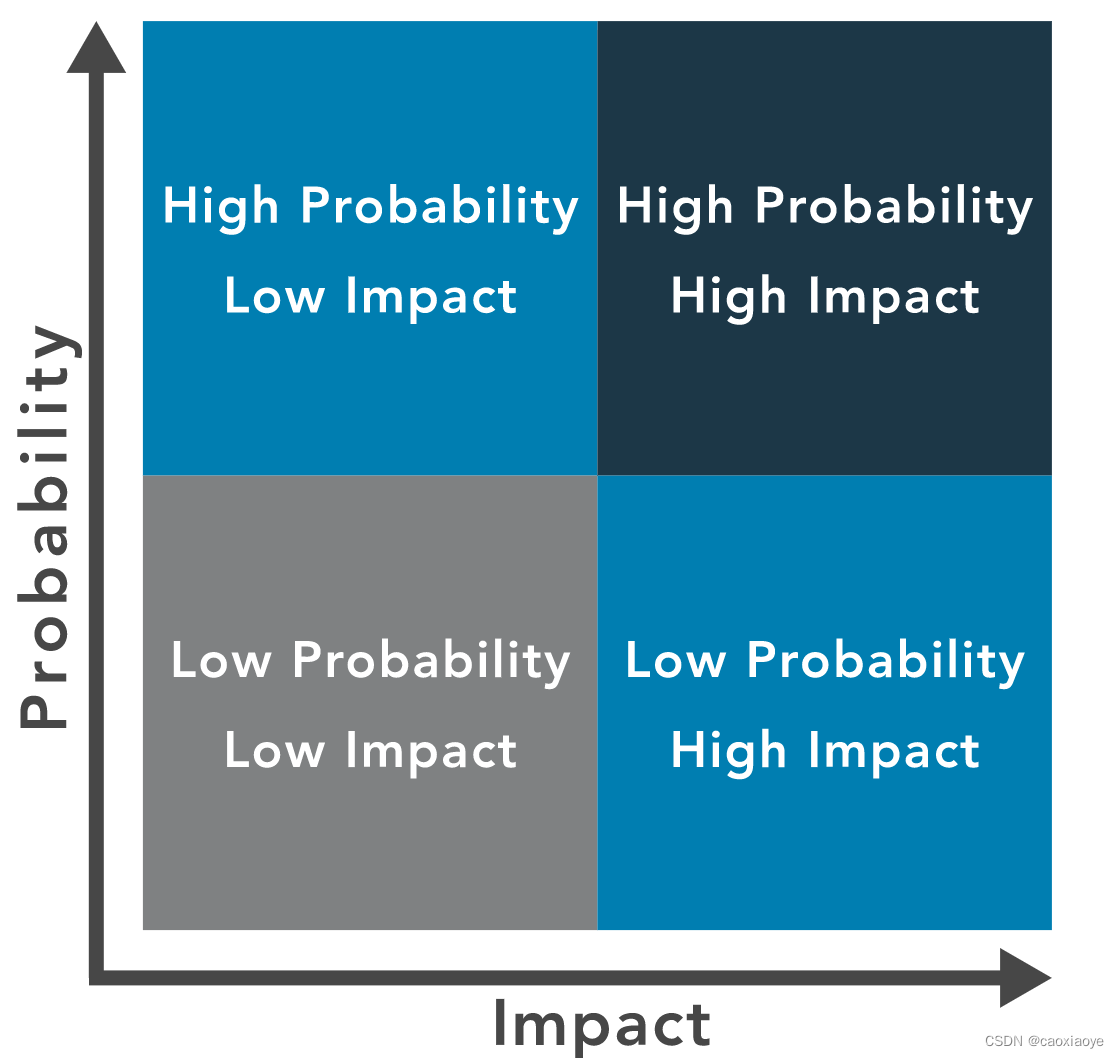
确定风险优先级的一种有效方法是使用风险矩阵,它有助于将优先级确定为发生可能性和影响的交叉点。它还为团队提供了一种共同语言,可在确定最终优先级时与管理层一起使用。例如,低可能性和低影响可能导致低优先级,而具有高可能性和高影响的事件将导致高优先级。优先级的分配可能与业务优先级、降低风险的成本或发生事故时的潜在损失有关。
基于风险优先级的决策
在根据风险优先级做出决策时,组织必须评估风险的可能性和影响以及它们对不同类型风险的容忍度。夏威夷的公司比芝加哥的公司更关心火山爆发的风险,但芝加哥公司将不得不为暴风雪做好准备。在这些情况下,确定风险承受能力取决于执行管理层和董事会。如果一家公司选择忽视或接受风险,例如让工人接触石棉,这会使公司承担巨大的责任。
风险承受能力
管理层对风险的看法通常被比作实体对风险的偏好。他们愿意承担多大的风险?管理层是欢迎风险还是想避免风险?不同组织甚至内部的 風險承受能力 水平各不相同:不同部门可能对可接受或不可接受的风险有不同的态度。
了解组织和高级管理层对风险的态度通常是让管理层针对风险采取行动的起点。
执行管理层和/或董事会确定组织可接受的风险水平。安全专业人员的目标是将风险水平保持在管理层的风险容忍度范围内。
通常,风险承受能力取决于地理位置。例如,冰岛的公司为附近的火山给他们的业务带来的风险制定了计划。位于熔岩流预计路径之外的公司所面临的风险将低于直接位于熔岩流路径中的公司。同样,影响数据中心的断电的可能性是世界所有地区的真正威胁。在雷雨多发的地区,停电一个月可能不止一次,而其他地区每年可能只有一两次停电。计算不同停机时间可能发生的停机时间将有助于确定公司的风险承受能力。如果一家公司对停机风险的容忍度较低,他们更有可能投资一台发电机来为关键系统供电。对停机时间的容忍度更低的公司将投资于具有多种燃料源的多台发电机,以提供更高水平的电力不会发生故障的保证。
模块 3:了解安全控制 (D1.3)
什么是安全控制?
安全控制 涉及物理、技术和管理机制,它们充当为信息系统规定的保障措施或对策,以保护系统及其信息的机密性、完整性和可用性。控制措施的实施应能降低风险,有望达到可接受的水平。
- 物理控制
物理控制 使用物理硬件設備解決基於流程的安全需求,例如徽章閱讀器、建築物和設施的建築特徵,以及人們要採取的具體安全措施。 它們通常提供控制、指揮或阻止人員和設備在特定物理位置(例如辦公室、工廠或其他設施)移動的方法。 物理控制還可以保護和控制進入建築物、停車場或組織控制範圍內的其他區域周圍的土地。 在大多數情況下,物理控制由技術控制支持,作為將它們納入整體安全系統的一種手段。
例如,訪問工作場所的來訪者和客人必須經常通過指定的入口和出口進入設施,在那裡可以識別他們的身份,評估他們的訪問目的,然後允許或拒絕進入。 員工可能會通過其他入口進入,使用公司頒發的徽章或其他令牌來聲明他們的身份並獲得訪問權限。 這些需要技術控制,以將徽章或令牌讀取器、門釋放機制以及身份管理和訪問控制系統集成到一個更加無縫的安全系統中。
- 技術控制
技術控制 (也稱為邏輯控制)是計算機系統和網絡直接實施的安全控制。 這些控制可以提供自動保護,防止未經授權的訪問或濫用,促進安全違規檢測,並支持應用程序和數據的安全要求。 技術控制可以是作為數據存儲的配置設置或參數,通過軟件圖形用戶界面 (圖形用戶界面) 進行管理,也可以是通過開關、跳線插頭或其他方式完成的硬件設置。 然而,技術控制的實施總是需要重要的操作考慮,並且應該與組織內的安全管理保持一致。 當我們在本章後面的部分和後續章節中查看它們時,我們將更深入地研究其中的許多內容。
- 行政控制
行政控制 (也稱為管理控制)是針對組織內人員的指令、指南或建議。 它們為人類行為提供框架、約束和標準,並應涵蓋組織活動的整個範圍及其與外部各方和利益相關者的互動。
認識到管理控制可以而且應該是實現信息安全的強大、有效的工具是非常重要的。 即使是最簡單的安全意識策略也可以成為有效的控制,如果你能通過系統的培訓和實踐幫助組織充分實施它們。
許多組織正在通過將他們的管理控制集成到他們的員工全天使用的任務級活動和運營決策流程中來改善他們的整體安全態勢。 這可以通過將它們作為在上下文中準備好的參考和諮詢資源提供,或者通過將它們直接鏈接到培訓活動來實現。 這些和其他技術使政策達到更中立的水平,並遠離僅由高級管理人員做出的決策。 它還使它們在日常和每個任務的基礎上即時、有用和可操作。
模块 4:了解治理要素 (D1.5)
治理要素
任何企业或组织的存在都是为了实现一个目的,无论是为行业提供原材料、制造用于构建计算机硬件的设备、开发软件应用程序、建造建筑物或提供商品和服务。要完成目标,需要做出决策、定义规则和实践,并制定政策和程序来指导组织实现其目标和使命。
当领导者和管理层实施组织将用于实现其目标的系统和结构时,他们会受到政府制定的法律和法规的指导,以制定公共政策。法律法规引导标准制定,标准培育政策,形成程序。
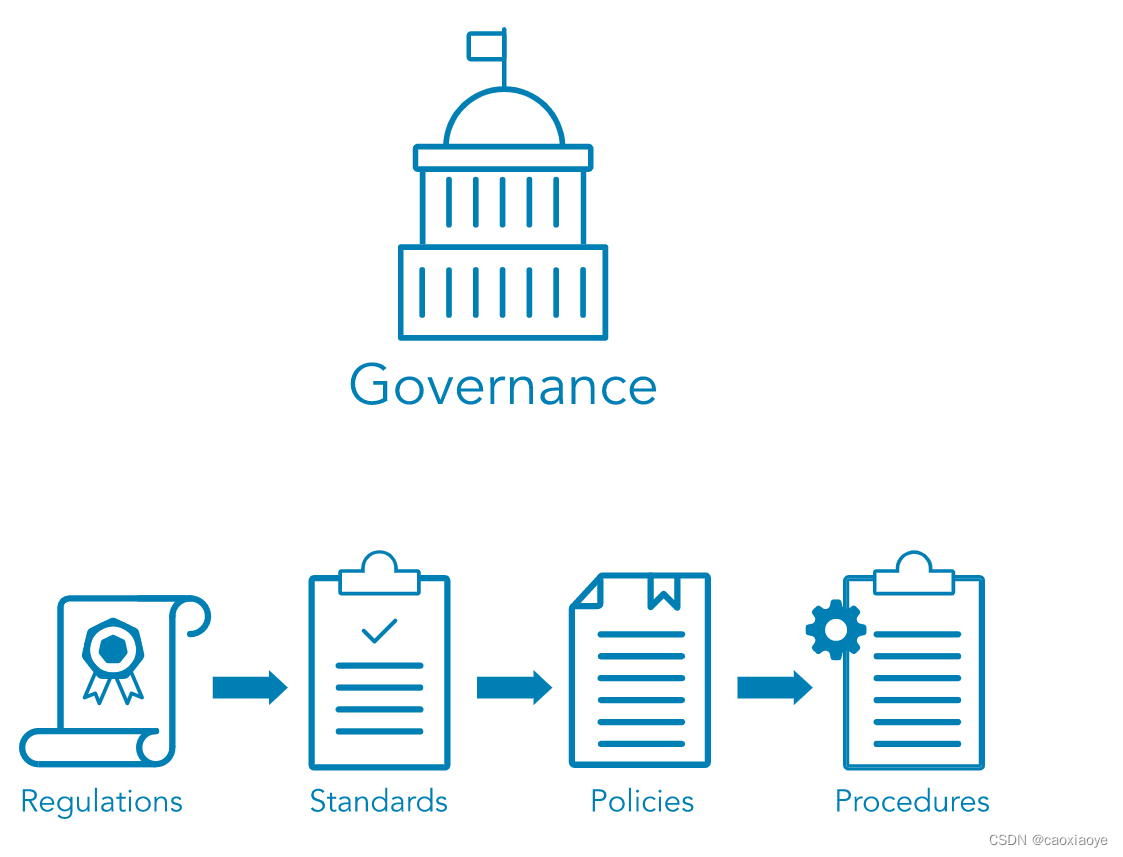
法规、标准、政策和程序如何相关?反向查看列表可能会有所帮助。
- 程序是完成支持部门或组织策略的任务的详细步骤。
- 组织治理(例如执行管理层)制定了政策,以在所有活动中提供指导,以确保组织支持行业标准和法规。
- 治理团队经常使用标准来提供一个框架,以引入支持法规的政策和程序。
- 法规通常以法律的形式发布,通常来自政府(不要与治理混淆),并且通常会对违规行为进行经济处罚。
法规和法律
国家、地区或地方各级政府可以实施法规和相关的罚款和处罚。由于法规和法律在世界不同地区的实施和执行方式可能不同,因此这里有一些示例将概念与实际法规联系起来。
這1996 年的健康保险流通与责任法案 (HIPAA) 是管理美国受保护健康信息 (PHI) 使用的法律示例。违反 HIPAA 规则可能会对个人和公司造成罚款和/或监禁。
這通用数据保护条例 (通用數據保護條例) 以控制其公民和欧盟公民对其个人身份信息 (個人身份信息) 的使用。它包括对处理欧盟公民和居住在欧盟的数据的公司实施经济处罚的规定,即使该公司在欧盟没有实体存在,也使该法规具有国际影响力。
最后,在多个层面上受到监管是很常见的。除了多个地区和城市之外,跨国组织还受制于多个国家的法规。组织需要考虑适用于其业务的各个层面(国家、地区和地方)的法规,并确保它们符合最严格的法规。
標準
组织使用多个标准作为其信息系统安全计划的一部分,既作为合规文件,也作为建议或指南。标准涵盖了广泛的问题和想法,并且可以保证组织正在使用支持法规和被广泛接受的最佳实践的政策和程序来运作。
這 国际标准化组织 (國際標準化組織) 制定和发布有关各种技术主题的国际标准,包括信息系统和信息安全以及加密标准。 國際標準化組織 征求国际专家社区云的意见,以便在发布之前就其标准提供意见。可以在线购买概述 國際標準化組織 标准的文件。
這 國家標準技術研究所(美國國家標準與技術研究院)是商務部下的美國政府機構,除了信息技術和信息安全標準外,還發布了各種技術標準。 美國國家標準與技術研究院發布的許多標準都是對美國政府機構的要求,被全球行業視為建議標準。 美國國家標準與技術研究院標準徵求和整合行業的意見,並可以從NIST網站免費下載。
最后,想想计算机如何与全球其他计算机通信。人们说不同的语言,并不总是相互理解。计算机如何进行通信?当然,通过标准!
多亏了互聯網工程工作隊(IETF), 通信协议中的标准可以确保所有计算机都可以跨越国界相互连接,即使操作员不会说同一种语言。
這 电气和电子工程师协会 (IEEE) 还为电信、计算机工程和类似学科制定标准。
政策
政策以适用法律为依据,并指定组织将遵循的标准和指南。政策范围广泛,但不详细;它确定了背景并确定了战略方向和优先事项。治理政策用于调节和控制决策制定,以确保必要时的合规性,并指导其他政策的创建和实施。
策略通常在整个组织的多个级别上编写。高级管理人员使用高级治理政策来塑造和控制决策过程。其他高级策略指导整个组织的行为和活动,因为它朝着特定或一般目标和目标前进。人力资源管理、财务和会计以及安全和资产保护等职能领域通常有自己的一套政策。无论是法律法规还是合同规定,合规性的需要还可能需要制定特定的高级政策,这些政策被记录并评估以供组织有效使用。
政策由人执行或执行;为此,必须有人将政策从意图和方向声明扩展为逐步说明或程序。
程序
过程定义了完成特定任务或一组任务所需的明确的、可重复的活动。它们提供执行每项任务所需的支持数据、决策标准或其他明确的知识。程序可以处理一次性或不经常发生的行为或常见的、经常发生的事件。此外,程序建立了用于确定任务是否已成功完成的测量标准和方法。正确记录程序并培训人员如何定位和遵循它们对于从程序中获得最大的组织利益是必要的。
模块5:理解 ISC2 道德规范 (D1.4)
所有获得 ISC2 认证的信息安全专业人员都认识到,认证是一项必须获得和维护的特权。每个 ISC2 成员都必须承诺完全支持 ISC2 道德准则。
序言陈述了 ISC2道德准则的目的和意图。
- 社会的安全和福利以及共同利益,对我们的负责人以及对彼此的责任,要求我们遵守并被视为遵守最高的道德行为标准。
- 因此,严格遵守本准则是获得认证的条件
经典代表了 ISC2成员共同持有的重要信念。作为 ISC2成员的网络安全专业人员对规范中的以下四个实体负有责任。
- 保护社会、共同利益、必要的公众信任和信心以及基础设施。
- 以光榮、誠實、公正、負責任和合法的方式行事。
- 为校长提供勤勉、称职的服务。
- 推进和保护职业。
模块 6:总结
在本章中,我们从信息保障的概念开始介绍了安全原则。我们强调 CIA 三元组是信息保障的主要组成部分。 “C”代表机密性;我们必须保护需要保护的数据并防止未经授权的个人访问。 “我”代表诚信;我们必须确保数据没有以未经授权的方式被更改。 “A”代表可用性;我们必须确保授权用户可以在需要的时间和地点以所需的形式和格式访问数据。我们还讨论了隐私、身份验证、不可否认性和授权的重要性。
您探索了为信息系统规定的保护措施和对策,以保护系统及其信息的机密性、完整性和可用性。通过应用风险管理,我们能够评估组织的风险(可被威胁利用的资产漏洞)并确定其优先级。组织可以决定是否接受风险(忽略风险并继续进行有风险的活动)、避免风险(停止有风险的活动以消除事态发生的可能性)、减轻风险(采取措施防止或减少影响)事态),或转移风险(将风险转移给第三方)。
然后,您了解了三种类型的安全控制:物理、技术和管理。它们充当为信息系统规定的保障措施或对策,以保护系统及其信息的机密性、完整性和可用性。安全控制的实施应该可以降低风险,希望达到可接受的水平。物理控制使用物理硬件设备(例如徽章阅读器)、建筑物和设施的架构特征以及人们采取的特定安全措施来解决基于流程的安全需求。技术控制(也称为逻辑控制)是计算机系统和网络直接实施的安全控制。行政控制(也称为管理控制)是针对组织内人员的指令、指南或建议。
然后向您介绍了组织安全角色和治理,以及塑造组织管理和推动决策制定的政策和程序。正如所讨论的,我们通常从政策中获得程序,从标准中获得政策,从法规中获得标准。法规通常以法律的形式发布,通常来自政府(不要与治理混淆),并且通常会对违规行为进行经济处罚。治理团队经常使用标准来提供一个框架,以引入支持法规的政策和程序。组织治理(例如执行管理层)制定了政策,以在所有活动中提供指导,以确保组织支持行业标准和法规。程序是完成支持部门或组织政策的任务的详细步骤。
最后,我们介绍了 ISC2 道德准则,该组织的成员承诺全力支持。归根结底,我们必须在网络安全领域以合法和合乎道德的方式行事。
最终为用户负责
第二章、事件响应、业务连续性、灾难恢复
本章重点介绍 中央情報局 三元组的可用性部分以及维护人力和系统资源可用性的重要性。这些通常是通过实施事件响应、业务连续性 (公元前) 和灾难恢复 (DR) 计划来实现的。虽然这三个计划的范围似乎重叠,但它们是对任何组织的生存都至关重要的三个不同的计划。
以下是本章要记住的主要内容:首先,事件响应计划响应运营条件的意外变化以保持业务运营;其次,业务连续性计划使企业能够在整个危机期间继续运营;最后,如果事件响应和业务连续性计划均失败,则启动灾难恢复计划以帮助业务尽快恢复正常运营。
健康和人类安全
当谈到网络安全职业时,日常的重点是监控信息系统并寻找异常的网络活动、恶意软件和威胁参与者。安全专业人员每天都在确保系统和数据的机密性、完整性和可用性,但除了保护网络以及保护数据和共享资源的交换之外,重要的是要认识到网络安全超越了技术方面。其范围包括对人员及其个人信息的保护。没有什么比我们的用户、同事和客户的健康和安全更重要的了。
模块 1: 了解事件响应 (D2.3)
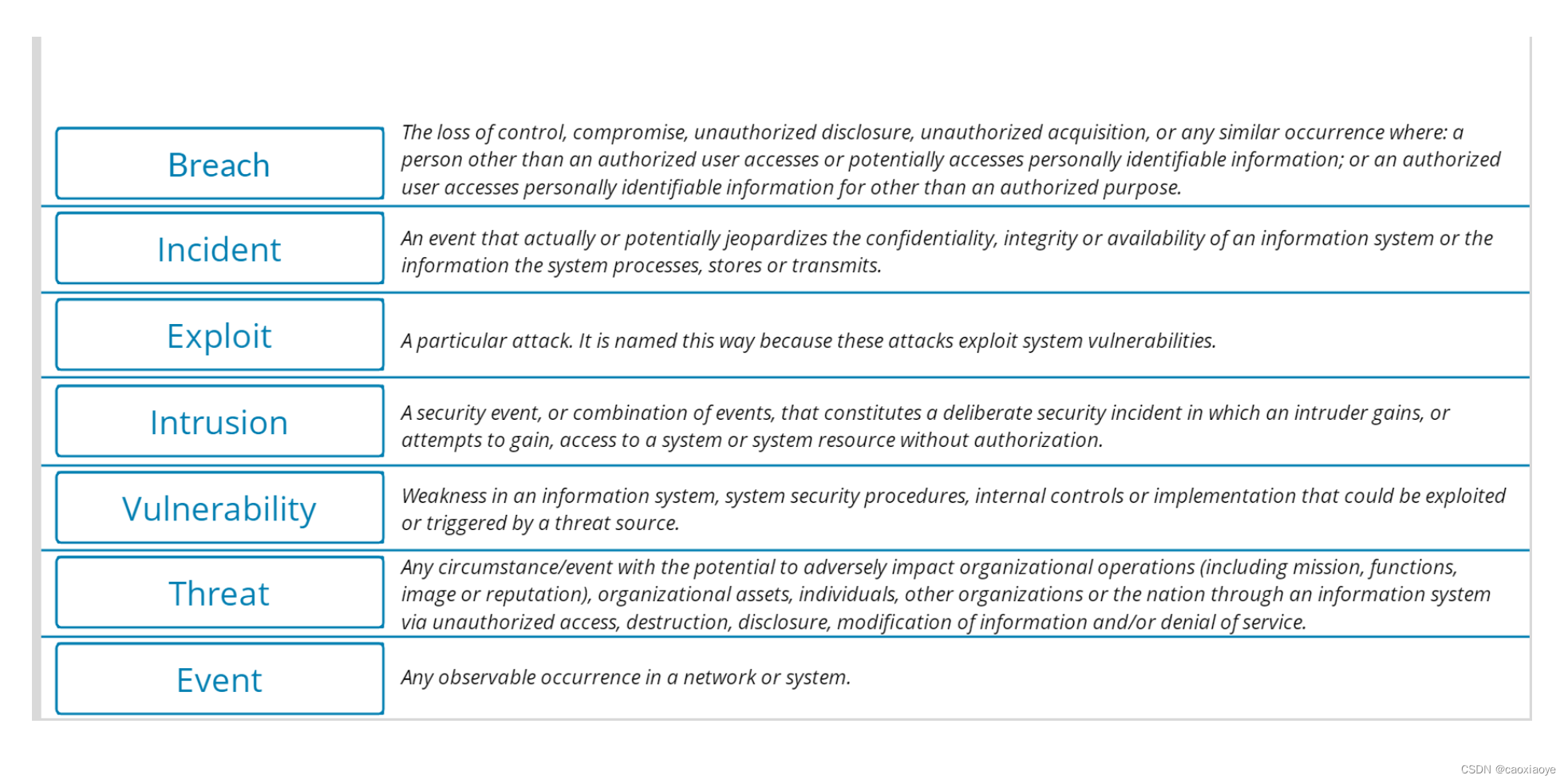
事件术语
虽然安全专业人员努力保护系统免受恶意攻击或人为疏忽,但尽管做出了这些努力,但不可避免地会出现问题。出于这个原因,安全专业人员也扮演着第一响应者的角色。要了解事件响应,首先要了解用于描述各种网络攻击的术语。
Breach 违反
失控、妥协、未经授权的披露、未经授权的获取或任何类似情况:授权用户以外的人访问或可能访问个人身份信息;或授权用户出于授权目的以外的目的访问个人身份信息。 NIST SP 800-53 修订版 5
EVENT 事件
网络或系统中任何可观察到的事件。 NIST SP 800-61 修订版 2
EXPLOIT 利用
特殊的攻击。之所以这样命名,是因为这些攻击利用了系统漏洞。
INCIDENT 事件
实际或潜在危害信息系统或系统处理、存储或传输的信息的机密性、完整性或可用性的事件。
An event that actually or potentially jeopardizes the confidentiality, integrity or availability of an information system or the information the system processes, stores or transmits.
INTRUTION 入侵
构成故意安全事件的安全事件或事件组合,其中入侵者未经授权获得或试图获得对系统或系统资源的访问。 IETF RFC 4949 第 2 版
Threat 威胁
任何可能通过未经授权的访问、破坏、披露、修改信息和/或拒绝服务。 NIST SP 800-30 修订版 1
vulnerability 漏洞
信息系统、系统安全程序、内部控制或实施中可能被威胁源利用的弱点。 NIST SP 800-30 修订版 1
zero-days 零日
以前未知的系统漏洞,具有被利用的潜力,没有被检测或预防的风险,因为它通常不符合公认的模式、签名或方法。
事件响应的目标
每个组织都必须为事件做好准备。尽管组织的管理和安全团队尽最大努力避免或预防问题,但不可避免地会发生可能影响业务使命或目标的不利事件。
任何事件响应的首要任务是保护生命、健康和安全。当要做出任何与优先事项相关的决定时,始终选择安全第一。
事件管理的主要目标是做好准备。准备工作需要制定政策和应对计划,引导组织度过危机。一些组织使用术语“危机管理”来描述此过程,因此您可能也会听到这个术语。
事件是任何可测量的事件,大多数事件是无害的。但是,如果事件有可能破坏企业的使命,则称为事件。每个组织都必须有一个事件响应计划,这将有助于保持业务的活力和生存。
事件响应过程旨在减少事件的影响,以便组织可以尽快恢复中断的操作。请注意,事件响应计划是更大的业务连续性管理 (車身控制模塊) 学科的一个子集,我们将在稍后介绍。
The Goal of Incident Response
Every organization must be prepared for incidents. Despite the best efforts of an organization’s management and security teams to avoid or prevent problems, it is inevitable that adverse events will happen that have the potential to affect the business mission or objectives.
The priority of any incident response is to protect life, health and safety. When any decision related to priorities is to be made, always choose safety first.
The primary goal of incident management is to be prepared. Preparation requires having a policy and a response plan that will lead the organization through the crisis. Some organizations use the term “crisis management” to describe this process, so you might hear this term as well.
An event is any measurable occurrence, and most events are harmless. However, if the event has the potential to disrupt the business’s mission, then it is called an incident. Every organization must have an incident response plan that will help preserve business viability and survival.
The incident response process is aimed at reducing the impact of an incident so the organization can resume the interrupted operations as soon as possible. Note that incident response planning is a subset of the greater discipline of business continuity management (BCM), which we will cover shortly.
当然,沟通是关键。 “尽早沟通,经常沟通”,我想这是很多人所说的。另一个技巧是确保我们在正确的水平上进行这些沟通,以确保我们与人沟通而不是与人沟通
我认为在该领域能够与不同层次进行交流是一件好事,你知道,为他们进行翻译
,在正确的水平上进行沟通。并确保该通信绝对包含在业务连续性计划、事件响应计划和灾难恢复计划中,所有这些都结合在一起
此,当您这么说并记录这些步骤时,作为业务连续性、事件响应和灾难恢复的一部分绝对是关键。因此,请确保您已将这些记录在案,并确保将这些记录在哪里。所以这是一个很好的总结
事件响应计划的组成部分the Incident Response Plan
事件响应政策应参考所有员工都将遵循的事件响应计划,具体取决于他们在流程中的角色。该计划可能包含与事件响应相关的若干程序和标准。它是组织事件响应策略的生动体现。
组织的愿景、战略和使命应塑造事件响应过程。实施计划的程序应定义团队在响应事件时将使用的技术流程、技术、清单和其他工具。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FpSpWDyI-1691460795989)(C:\Users\cyrilcao\AppData\Roaming\Typora\typora-user-images\image-20230731135137700.png)]](https://img-blog.csdnimg.cn/ef01f306d01944fe8b017170ed3993cc.png)
准备
- 制定经管理层批准的政策。
- 识别关键数据和系统、单点故障。
- 对员工进行事件响应培训。
- 实施事件响应团队。 (在后续主题中介绍)
- 练习事件识别。 (第一反应)
- 确定角色和责任。
- 计划利益相关者之间的沟通协调。
- 考虑一种主要的交流方法可能不可用的可能性。
检测分析
- 监控所有可能的攻击媒介。
- 使用已知数据和威胁情报分析事件。
- 优先考虑事件响应。
- 标准化事件文档。
遏制、根除和恢复
- 收集证据。
- 选择适当的遏制策略。
- 识别攻击者。
- 隔离攻击。
事后活动
- 确定可能需要保留的证据。
- 记录经验教训。
回顾展
-
准备
-
检测分析
-
遏制、根除和恢复
-
事后活动
旁白:准备工作的第一部分是识别需要保护的关键信息并避免任何单点故障。这意味着,如果我们有一些特别重要的东西,但它只受到一扇门的保护,我们会创建多层保护来降低攻击成功的可能性。纵深防御的原理我们后面会多讲,但是就像堡垒一样,防御层数越多,攻击者想要突破的难度就越大。 对员工进行事件响应培训非常重要,这样每个人都知道该怎么做。培训可以包括模拟和场景,以便团队可以练习他们的反应并学习协调组织不同利益相关者之间的沟通。这包括同事、上级、信息所有者和客户。我们需要考虑可用的通信类型,因为我们无法向所有人传达相同的信息。有些材料是保密的,有些材料只对某些人有用,对媒体或外部个人没有用。 在检测和分析方面,我们需要监控攻击向量、攻击方式以及使用的技术。标准化事件文档很重要,因为在一群人中,每个人都会对如何记录活动和程序有自己的想法。为了组织的一致性和我们对数据所有者的责任,我们需要有一个标准化的事件响应,每个人都知道需要做什么以及按照什么顺序完成。这样可以更轻松地确定响应的优先级,因为每个人都有自己的任务并且知道如何处理自己的责任,然后与其他相关人员进行适当的沟通。 接下来,我们需要找到适当的遏制策略,识别攻击者以及他们如何突破我们的防御系统,并隔离攻击,确保它不会进一步发展或造成额外的破坏。事件发生后,我们确定可能需要保留的证据,然后通常会对发生的事情进行内部审计。可能还需要进行外部调查,尤其是在涉及执法的重大网络攻击中。吸取的教训必须记录在案。也许,会发现我们的反应比之前的攻击更好,但我们仍然需要改进准备或检测分析。通常,这些事件后活动受监管要求的约束,并且必须提交某些文件。如果泄露的关键信息受到法律保护,这一点尤其重要。
事件响应小组
除了组织需要建立安全运营中心 (SOC)之外,还需要创建合适的事件响应团队。根据组织的要求,可以利用、专门或两者结合使用配备适当人员和训练有素的事件响应团队。
许多 它 专业人员被归类为事件的第一响应者。他们是第一批出现在现场的人,并且知道如何区分典型的 IT 问题和安全事件。他们类似于医疗急救人员,他们具备在事故现场提供医疗援助的技能和知识,并在必要时帮助患者前往医疗机构。医疗急救人员经过专门培训,可以帮助他们确定轻伤和重伤之间的区别。此外,他们知道在遇到重大伤害时该怎么做。
同样,IT 专业人员需要特定的培训,以便他们能够确定需要排除故障的典型问题与需要在更高级别报告和解决的安全事件之间的区别。
典型的事件响应团队是一个跨职能的个人小组,他们代表受安全事件最直接影响的管理、技术和职能领域的责任。潜在的团队成员包括:
- 高级管理人员代表
- 信息安全专业人员
- 法定代表人
- 公共事务/传播代表
- 工程代表(系统和网络)
团队成员应接受有关事件响应和组织的事件响应计划的培训。通常,团队成员协助调查事件、评估损害、收集证据、报告事件和启动恢复程序。他们还将参与补救和经验教训阶段,并帮助进行根本原因分析。
许多组织现在都有专门的团队负责调查发生的任何计算机安全事件。这些团队通常称为计算机事件响应团队 (CIRT) 或计算机安全事件响应团队 (CSIRT)。当事件发生时,响应团队有四个主要职责:
- 确定事件造成的损害的数量和范围。
- 确定事件期间是否有任何机密信息被泄露。
- 实施任何必要的恢复程序以恢复安全并从与事件相关的损坏中恢复。
- 监督任何必要的额外安全措施的实施,以提高安全性并防止事件再次发生。
Incident Response Team
Along with the organizational need to establish a Security Operations Center (SOC) is the need to create a suitable incident response team. A properly staffed and trained incident response team can be leveraged, dedicated or a combination of the two, depending on the requirements of the organization.
Many IT professionals are classified as first responders for incidents. They are the first ones on the scene and know how to differentiate typical IT problems from security incidents. They are similar to medical first responders who have the skills and knowledge to provide medical assistance at accident scenes and help get the patients to medical facilities when necessary. The medical first responders have specific training to help them determine the difference between minor and major injuries. Further, they know what to do when they come across a major injury.
Similarly, IT professionals need specific training so they can determine the difference between a typical problem that needs troubleshooting and a security incident that they need to report and address at a higher level.
A typical incident response team is a cross-functional group of individuals who represent the management, technical and functional areas of responsibility most directly impacted by a security incident. Potential team members include the following:
- Representative(s) of senior management
- Information security professionals
- Legal representatives
- Public affairs/communications representatives
- Engineering representatives (system and network)
Team members should have training on incident response and the organization’s incident response plan. Typically, team members assist with investigating the incident, assessing the damage, collecting evidence, reporting the incident and initiating recovery procedures. They would also participate in the remediation and lessons learned stages and help with root cause analysis.
Many organizations now have a dedicated team responsible for investigating any computer security incidents that take place. These teams are commonly known as computer incident response teams (CIRTs) or computer security incident response teams (CSIRTs). When an incident occurs, the response team has four primary responsibilities:
- Determine the amount and scope of damage caused by the incident.
- Determine whether any confidential information was compromised during the incident.
- Implement any necessary recovery procedures to restore security and recover from incident-related damage.
- Supervise the implementation of any additional security measures necessary to improve security and prevent recurrence of the incident.
模块 2: 了解业务连续性 (BC) (D2.1)
业务连续性计划的目的
是在从重大中断中恢复的同时维持业务运营。一个事件在环境中造成了干扰,现在您需要知道如何维持业务。
该计划的一个关键部分是通信,包括多种联系方法和备用号码,以防电源或通信中断。许多组织会建立电话树,这样如果一个人不可用,他们就知道该给谁打电话。组织将通过他们的程序和清单,以确保他们确切地知道谁对哪些行动负责。无论他们飞行了多少次,飞行员都会在起飞前检查清单。同样,必须有既定的程序和完整的清单,这样就不会错过业务连续性的关键要素。
我们召集适当的人员并开始启动业务连续性计划。必须包括管理,因为有时优先级可能会根据情况而改变。具有适当权限的个人必须在那里执行操作,例如,如果有需要关闭的关键区域。
我们需要手头有供应链、执法部门和设施外其他地点的关键联系电话。例如,医院可能遭受严重的网络攻击,影响药房、互联网或电话线的通信。在美国,如果发生这种破坏通信的网络攻击,特定网络中的特定号码可以绕过正常的手机服务,使用军用级网络。这些将被分配给医院或其他关键基础设施的授权人员,以防发生重大中断或网络攻击,因此他们仍然可以维持基本活动。
The intent of a business continuity plan is to sustain business operations while recovering from a significant disruption. An event has created a disturbance in the environment, and now you need to know how to maintain the business.
A key part of the plan is communication, including multiple contact methodologies and backup numbers in case of a disruption of power or communications. Many organizations will establish a phone tree, so that if one person is not available, they know who else to call. Organizations will go through their procedures and checklists to make sure they know exactly who is responsible for which action. No matter how many times they have flown, without fail, pilots go through a checklist before take-off. Similarly, there must be established procedures and a thorough checklist, so that no vital element of business continuity will be missed.
We call the appropriate individuals and start to activate the business continuity plan. Management must be included, because sometimes priorities may change depending on the situation. Individuals with proper authority must be there to execute operations, for instance, if there are critical areas that need to be shut down.
We need to have at hand the critical contact numbers for the supply chain, as well as law enforcement and other sites outside of the facility. For example, a hospital may suffer a severe cyberattack that affects communications from the pharmacy, the internet or phone lines. In the United States, in case of this type of cyberattack that knocks out communications, specific numbers in specific networks can bypass the normal cell phone services and use military-grade networks. Those will be assigned to authorized individuals for hospitals or other critical infrastructures in case of a major disruption or cyberattack, so they can still maintain essential activity.
旁白:业务连续性是指在任何形式的干扰、攻击、基础设施故障或自然灾害造成的中断期间,使组织的关键方面能够发挥作用,也许能力会降低。大多数事件都很轻微,可以轻松处理,影响最小。例如,系统需要重新启动,但几分钟后系统恢复运行并且事件结束。但是偶尔,重大事件会在不可接受的时间内中断业务,组织不能仅仅遵循事件计划,而是必须朝着业务连续性迈进。
业务连续性包括计划、准备、响应和恢复操作,但通常不包括支持完全恢复所有业务活动和服务的活动。它专注于组织提供的关键产品和服务,并确保这些重要领域即使在性能水平降低的情况下也能继续运营,直到业务恢复正常。
制定业务连续性计划需要在人员和财务资源方面做出重大的组织承诺。为了获得这一承诺,执行管理层或执行发起人必须为业务连续性规划工作提供组织支持。如果没有适当的支持,业务连续性规划工作几乎没有成功的机会。
业务连续性计划的组成部分
业务连续性计划 (BCP)) 是在发生灾难或对组织造成其他重大破坏后,主动制定恢复业务运营的程序。来自整个组织的成员应参与创建 過境點,以确保在计划中考虑所有系统、流程和操作。
业务一词经常被使用,因为这主要是一种业务功能,而不是技术功能。然而,为了保护信息的机密性、完整性和可用性,该技术必须与业务需求保持一致。
以下是全面业务连续性计划的一些常见组成部分:
- BCP团队成员列表,包括多种联系方式和备用成员
- 即时响应程序和清单(安保和安全程序、灭火程序、通知适当的紧急响应机构等)
- 通知系统和呼叫树,用于提醒人员BCP 正在制定
- 管理指南,包括为特定管理人员指定权限
- 如何/何时制定计划
- 供应链关键成员(供应商、客户、可能的外部应急供应商、第三方合作伙伴)的联系电话
Business continuity planning (BCP) is the proactive development of procedures to restore business operations after a disaster or other significant disruption to the organization. Members from across the organization should participate in creating the BCP to ensure all systems, processes and operations are accounted for in the plan.
The term business is used often, as this is mostly a business function as opposed to a technical one. However, in order to safeguard the confidentiality, integrity and availability of information, the technology must align with the business needs.
Here are some common components of a comprehensive business continuity plan:
- List of the BCP team members, including multiple contact methods and backup members
- Immediate response procedures and checklists (security and safety procedures, fire suppression procedures, notification of appropriate emergency-response agencies, etc.)
- Notification systems and call trees for alerting personnel that the BCP is being enacted
- Guidance for management, including designation of authority for specific managers
- How/when to enact the plan
- Contact numbers for critical members of the supply chain (vendors, customers, possible external emergency providers, third-party partners)
工作场所的业务连续性
旁白: 显然,业务连续性计划需要维护在可以访问的地方。通常,在现代组织中,一切都是数字的,而不是作为硬拷贝提供的。这可能很危险,就像将所有东西都存放在公司主楼内一样。
一些组织有所谓的红皮书,它被提供给设施外的适当个人。该文件中概述了所有程序——例如,以防飓风来袭、停电、所有设施受到损害并且无法访问电子备份。每次更新电子版时,务必更新此硬拷贝红皮书,以使两个版本保持一致。
Narrator: Obviously, the business continuity plan needs to be maintained somewhere where it can be accessed. Often, in modern organizations, everything is digital and not provided as a hard copy. This can be dangerous, just like storing everything within the main company building. Some organizations have what is called the Red Book, which is given to the appropriate individual outside the facility. All the procedures are outlined in that document—in case, for example, a hurricane hits, the power is out and all the facilities are compromised and there is no access to electronic backups. It is important to update this hard-copy Red Book any time the electronic copy is updated so both versions remain consistent.
业务连续性在行动中是什么样的?
想象一下,一家公司的计费部门在一场火灾中遭受了完全的损失。火灾发生在一夜之间,因此当时大楼内没有人员。四个月前进行的业务影响分析 (BIA)确定计费部门的职能对公司非常重要,但不会立即影响其他工作领域。通过之前签署的协议,该公司有一个可供计费部门工作的替代区域,并且可以在不到一周的时间内完成。在该区域完全准备好之前,客户服务人员将回答客户账单查询。计费部门人员将留在备用工作区域,直到有新的永久区域可用。
在这种情况下,BIA 已经确定了客户计费查询和收入的依赖关系。由于公司有充足的现金储备,因此在正常业务中断期间一周不计费是可以接受的。通过为人员准备好备用工作区域并让客户服务部门在过渡到临时办公空间期间处理计费部门的电话,实现了预先规划。随着计划的执行,公司的业务或向客户提供服务的能力没有受到重大干扰——表明业务连续性计划的成功实施。
What does business continuity look like in action?
Imagine that the billing department of a company suffers a complete loss in a fire. The fire occurred overnight, so no personnel were in the building at the time. A Business Impact Analysis (BIA) was performed four months ago and identified the functions of the billing department as very important to the company, but not immediately affecting other areas of work. Through a previously signed agreement, the company has an alternative area in which the billing department can work, and it can be available in less than one week. Until that area can be fully ready, customer billing inquiries will be answered by customer service staff. The billing department personnel will remain in the alternate working area until a new permanent area is available.
In this scenario, the BIA already identified the dependencies of customer billing inquiries and revenue. Because the company has ample cash reserves, a week without billing is acceptable during this interruption to normal business. Pre-planning was realized by having an alternate work area ready for the personnel and having the customer service department handle the billing department’s calls during the transition to temporary office space. With the execution of the plan, there was no material interruption to the company’s business or its ability to provide services to its customers—indicating a successful implementation of the business continuity plan.
模块 3:了解灾难恢复 (DR) (D2.2)
The Goal of Disaster Recovery
In the Business Continuity module, the essential elements of business continuity planning were explored. Disaster recovery planning steps in where BC leaves off. When a disaster strikes or an interruption of business activities occurs, the Disaster recovery plan (DRP) guides the actions of emergency response personnel until the end goal is reached—which is to see the business restored to full last-known reliable operations.
Disaster recovery refers specifically to restoring the information technology and communications services and systems needed by an organization, both during the period of disruption caused by any event and during restoration of normal services. The recovery of a business function may be done independently of the recovery of IT and communications services; however, the recovery of IT is often crucial to the recovery and sustainment of business operations. Whereas business continuity planning is about maintaining critical business functions, disaster recovery planning is about restoring IT and communications back to full operations after a disruption.
在业务连续性模块中,探讨了业务连续性计划的基本要素。BC 停止的地方的灾难恢复 计划步骤。当灾难发生或业务活动中断时, 灾难恢复计划 (DRP)会指导应急响应人员的行动,直到达到最终目标——即看到业务恢复到最后一次已知的完全可靠运营。
灾难恢复专门指在任何事件造成的中断期间以及在恢复正常服务期间恢复组织所需的信息技术和通信服务和系统。业务功能的恢复可以独立于 它 和通信服务的恢复进行;但是,它 的恢复通常对业务运营的恢复和维持至关重要。业务连续性计划是关于维护关键业务功能,而灾难恢复计划是关于在中断后将 它 和通信恢复到全面运营。
复杂的系统通常可以跨多个服务器存储有价值的信息。虽然在最基本的层面上,灾难恢复计划包括在服务器层面备份数据,但还需要考虑数据库本身以及对其他系统的任何依赖关系。在这个更复杂的场景中,用户将数据输入到一个系统和数据库中,然后分发到其他系统。这在大型企业中很常见,其中多个系统需要相互通信以维护公共数据。在另一个医院示例中,放射科使用与实验室不同的系统。在这种情况下,一个单独的例程将患者数据从登记系统复制到实验室和放射系统,这些系统在技术上使用单独的数据库。重要的是要了解数据流和一个系统对另一个系统的复杂依赖关系,以便正确记录和实施灾难恢复计划,以便在需要时成功。
×
Complex systems can often store valuable information across several servers. While at its most basic level, disaster recovery plans include backing up data at a server level, it is also necessary to consider the database itself, as well as any dependencies on other systems. In this more complex scenario, data is entered by users into one system and database and is then distributed to other systems. This is common in large enterprises where multiple systems need to talk to each other to maintain common data. In another hospital example, the radiology department used a different system than the laboratory. In this case, a separate routine copied the patient data from the registration system to the laboratory and the radiology systems, which technically use separate databases. It is important to understand the flow of data and the intricate dependencies of one system on another to properly document and implement a disaster recovery plan that will be successful when it is needed.
灾难恢复计划的组成部分
根据组织的规模和参与 數字資源計劃 工作的人数,组织通常会维护多种类型的计划文档,用于不同的受众。以下列表包括值得考虑的各种类型的文档:
-
执行摘要提供计划的高级概述
-
部门特定计划
-
负责实施和维护关键备份系统的 它 人员的技术指南
-
关键灾难恢复团队成员的完整计划副本
-
某些个人的清单:
-
关键灾难恢复团队成员将拥有清单,以帮助指导他们在灾难的混乱气氛中采取行动。
-
它 人员将获得技术指导,帮助他们启动和运行备用站点。
-
经理和公共关系人员将拥有易于理解的高级文档,以帮助他们准确地传达问题,而无需来自忙于恢复工作的团队成员的输入。
Depending on the size of the organization and the number of people involved in the DRP effort, organizations often maintain multiple types of plan documents, intended for different audiences. The following list includes various types of documents worth considering:
-
Executive summary providing a high-level overview of the plan
-
Department-specific plans
-
Technical guides for IT personnel responsible for implementing and maintaining critical backup systems
-
Full copies of the plan for critical disaster recovery team members
-
Checklists for certain individuals:
-
Critical disaster recovery team members will have checklists to help guide their actions amid the chaotic atmosphere of a disaster.
-
IT personnel will have technical guides helping them get the alternate sites up and running.
-
Managers and public relations personnel will have simple-to-follow, high-level documents to help them communicate the issue accurately without requiring input from team members who are busy working on the recovery.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L6uNN0kp-1691460795990)(C:\Users\cyrilcao\AppData\Roaming\Typora\typora-user-images\image-20230731151424375.png)]](https://img-blog.csdnimg.cn/1b6bce9bb63f43f4a6131fd6974568f8.png)
旁白:灾难恢复的一个例子是使用系统备份。此图像中的时间线从事态检测的那一刻(右侧)开始向后看,作为识别从备份重新加载将丢失的工作量的一种方式。事务处理事态(三角形)和一些备份事态(显示为数据库符号)已沿时间线从左到右编号为事态 1 到 21。绿色事务(事态 1 到 14)是在入侵或事态开始之前已完全处理的事务。据推测,如果防病毒和其他系统正常工作,这可能是一个安全的假设。这些交易不会遭受完整性、真实性、隐私或任何其他所需安全属性的可能损失。
以灰色显示的数据库符号(事态 2、5、9 和 13 — 均在事态之前)表示某种形式的系统和数据备份,它可能已捕获由于正确完成绿色事务而对系统所做的更改。
然而,值得怀疑的是事态 15 到 21。它们可能没问题,或者如果数据被泄露,它们可能代表缺乏完整性。橙色的数据库备份符号,在事态发生时间和被检测到之间,显然对其完整性或安全性存在疑问。它们可能包含虚假、损坏的数据,甚至可能包含各种形式的恶意软件。从事态检测到时间倒退,直到我们找到最右边的灰色数据库符号(事态 13,即事态发生前的备份),我们才有最后一个干净、可靠的备份。
可以识别自事态开始发生以来丢失的三组工作:在最后一次良好备份之前不属于该备份的所有事务或更改(如果它是增量备份或部分备份而不是完整备份)事态15、17至19和21;从该备份及时处理或尝试的所有事务和其他更改,直到检测到事态之后,都没有开始发生;以及从检测到事态到系统再次完全运行期间通常会处理的所有事务更改等,但由于中断而根本无法处理。
模块 4:总结
本章主要关注 CIA 三元组的可用性部分以及维护业务运营可用性的重要性。通过实施事态响应、业务连续性 (BC) 和/或灾难恢复 (DR) 计划,在事态、事态、违规、入侵、利用或漏洞期间或之后维持业务运营。虽然这三个计划在范围上似乎重叠,但它们是三个不同的计划,对于任何面临非正常运营条件的组织的生存至关重要。以下是本章要记住的主要内容:
首先,事态响应计划对异常运营状况做出响应以保持业务运营。事态响应的四个主要组成部分是: 准备;检测与分析;遏制、根除和恢复;和事态后活动。事态响应团队通常是一个跨职能的个人团体,他们代表受安全事态最直接影响的管理、技术和职能领域的责任。团队接受了事态响应和组织的事态响应计划的培训。当事态发生时,团队负责确定损害的数量和范围以及是否有任何机密信息被泄露,实施恢复程序以恢复安全并从与事态相关的损害中恢复,并监督未来措施的实施以提高安全性和预防事态再次发生。
其次,业务连续性计划旨在让组织在危机中保持运营。业务连续性计划的组成部分包括有关如何以及何时制定计划和通知系统的详细信息,以及用于提醒团队成员和组织员工计划已经制定的调用树。此外,它还包括用于联系关键第三方合作伙伴、外部应急供应商、供应商和客户的联系电话。该计划为团队提供了即时响应程序、清单和管理指南。
最后,当事件响应和业务连续性 (BC) 计划均失败时,将激活灾难恢复 (DR) 计划以尽快使运营恢复正常。灾难恢复 (DR) 计划可能包括以下组成部分:提供计划高级概述的执行摘要、部门特定计划、负责实施和维护关键备份系统的 IT 人员的技术指南、计划的完整副本关键灾难恢复团队成员,以及某些个人的清单
Discretionary access control is a model wherein permissions are granted by operational managers, allowing them to make the determination of which personnel can get specific access to particular assets controlled by the manager. B is the correct answer. A is incorrect; in mandatory access control, managers do not have the authority (discretion) to determine who gets access to specific assets. C is incorrect; in role-based access control, managers do not have the authority to determine who gets access to particular assets. D is incorrect; defense in depth is not an access control model, it’s a security philosophy.