爬虫终结者 Chrome Headless
简介
- 自从Google官方发布了Chrome浏览器的无形态模式之后,
PhantomJS维护者 Vitaly Slobodin 随即在邮件列表上宣布辞职,可见该模式的影响力,那么下面小编带大家快速入门如何使用该技术实现数据抓取,可以说掌握这套技术能够应对90%的网站,从此爬虫0门槛。
安装
Chrome Headless 配置
- 打开chrome浏览器,地址栏输入
chrome://version/,需要版本59.0以上 - Mac配置如下(
vim ~/.bashrc):
alias chrome="/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome"
alias chrome-canary="/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary"
alias chromium="/Applications/Chromium.app/Contents/MacOS/Chromium"
alias start_chrome_server="chrome --disable-gpu --remote-debugging-port=9222"- 配置完成后记得
$ source ~/.bashrc - 在终端运行
$ start_chrome_server,可以看到如下图所示,且有一个新的浏览器打开: ps. 如果按照上面没有操作成功或者其他系统配置,可以看这里

相关库安装
$ sudo pip install pychrome下载chrome headless spider 源码 (ps.
如果有基础的直接看源码即可)或者
$ git clone https://github.com/MrPaoBrother/headless_spider.git
实战
ps. 因为所有的操作都是模拟浏览器进行操作,所以运行前必须先打开chrome headless:$ start_chrome_server
知乎自动化爬虫
- 上面源码下载好了之后,在根目录下运行:
$ python run_zhihu.py运行成功后可以看到知乎网站在不停的下滑刷新,直到最后一页。
结果:
法治在线自动翻页爬虫
- 上面源码下载好了之后,在根目录下运行:
$ python run_fazhizaixian.py运行成功后可以看到页面会自动翻页且会在最后一页停住,完全自动化。
结果:
豆瓣模拟登陆爬虫
上面源码下载好了之后,在源码中填入自己的
豆瓣账号用于模拟登陆:
之后在根目录运行
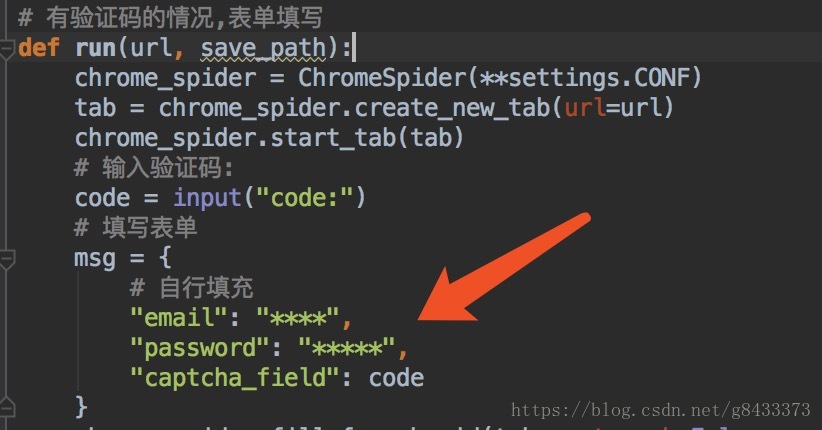
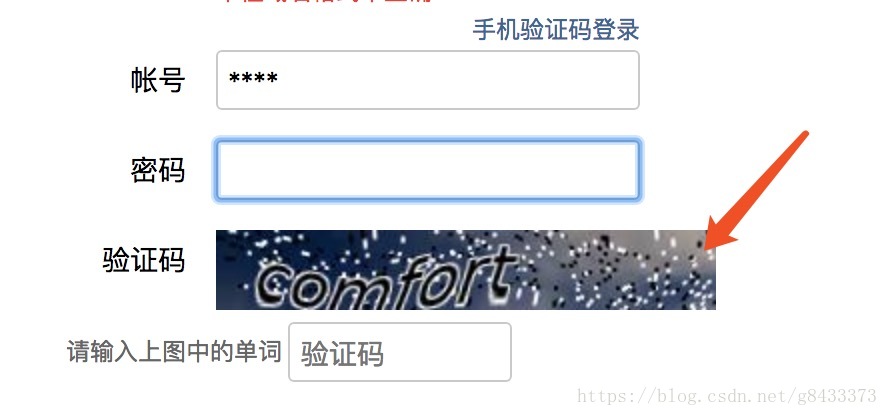
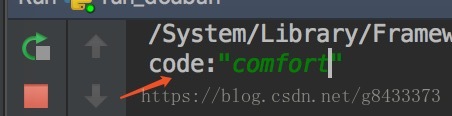
$ python run_douban.py- 有些时候需要验证码,注意控制台需要填写
code:这里按照自己看到的填就行:
- 成功的话,我们可以看到几秒之后浏览器自动进入豆瓣电影页面进行自动翻页爬虫了。
- 结果:
核心代码简介
- 下载页面
def download_html(self, url=None, delay=1, tab=None, disable_css=False, close_tab=True):
"""
返回一个页面的html
:param tab: 页面对象,默认为空,自己会自动创建一个
:param url: 传入的url
:param delay: 下载延迟
:param disable_css: 是否禁止CSS
:param close_tab: 每次爬完是否关闭tab
:return:
"""
try:
if tab is None:
tab = self.create_new_tab(url=url)
self.start_tab(tab)
tab.wait(timeout=delay)
html = self.exec_js_cmd(tab, js_cmd.DOWNLOAD_HTML)
if disable_css:
self.disable_css(tab=tab)
if html is not None:
html = html["result"]["value"]
if close_tab:
self.close_tab(tab)
return html
except Exception as e:
print "download_html error:", e
self.close_tab(tab)
return None- 该函数是整个框架的核心函数,爬虫的
核心也就是将浏览器上看到的用户信息抓取下来,其中我这里只给出了一部分功能即delay(控制下载延迟),disable_css(下载时候是否需要css资源),close_tab(每次抓取后是否关闭网页),源码中 还封装了很多其他功能,读者可以自行挖掘,理论上来说只要你能在浏览器上看到的东西基本都能抓下来,就是控制delay这个参数就行。
总结
- 该技术通常用来获取一些
数据加密网站的方法,对一般的静态网站抓取成本较高,因为在时间上相对来说慢一些,大家可以试着用该框架爬下淘宝,京东等网站,小编有测试过,也是没什么问题的,最后希望大家给我点个赞或者在项目中给个star!