目录
一、FFmpeg核心结构体
AVFormatContext:解封装功能的结构体,包含文件名、音视频流、时长、比特率等信息;
AVCodecContext:编解码器上下文,编码和解码时必须用到的结构体,包含编解码器类型、视频宽高、音频通道数和采样率等信息;
AVCodec:存储编解码器信息的结构体;
AVStream:存储音频或视频流信息的结构体;
AVPacket:存储音频或视频编码数据;
AVFrame:存储音频或视频解码数据(原始数据)
二、解码流程

三、FFmpeg解码实现
解码实现的是将压缩域的视频数据解码为像素域的 YUV 数据。实现的过程,可以大致用如下图所示

从图中可以看出,大致可以分为下面三个步骤:
- 首先要有待解码的压缩域的视频。
- 其次根据压缩域的压缩格式获得解码器。
- 最后解码器的输出即为像素域的 YUV 数据
四、FFmpeg编码实现
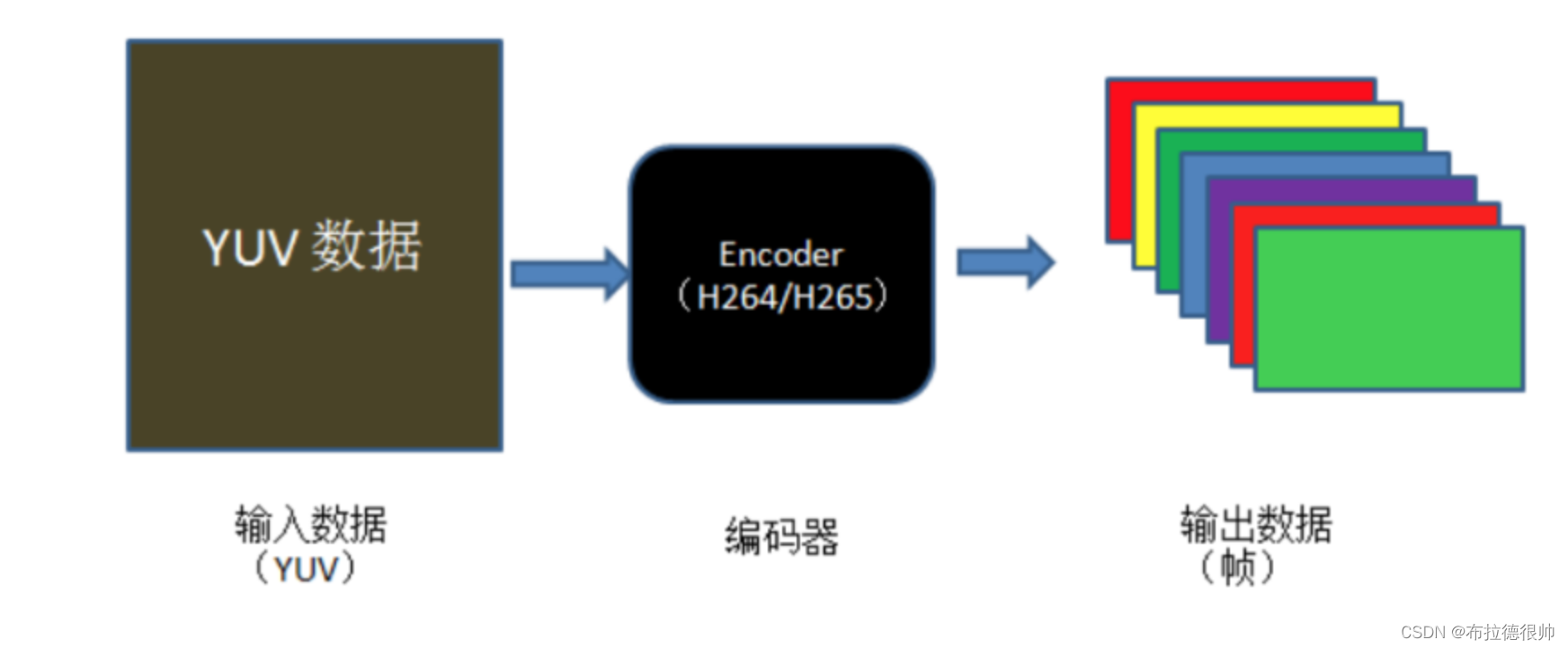
从图中可以大致看出视频编码的流程:
- 首先要有未压缩的 YUV 原始数据。
- 其次要根据想要编码的格式选择特定的编码器。
- 最后编码器的输出即为编码后的视频帧
五、FFmpeg转码实现
传统的编码转换程序工作原理图
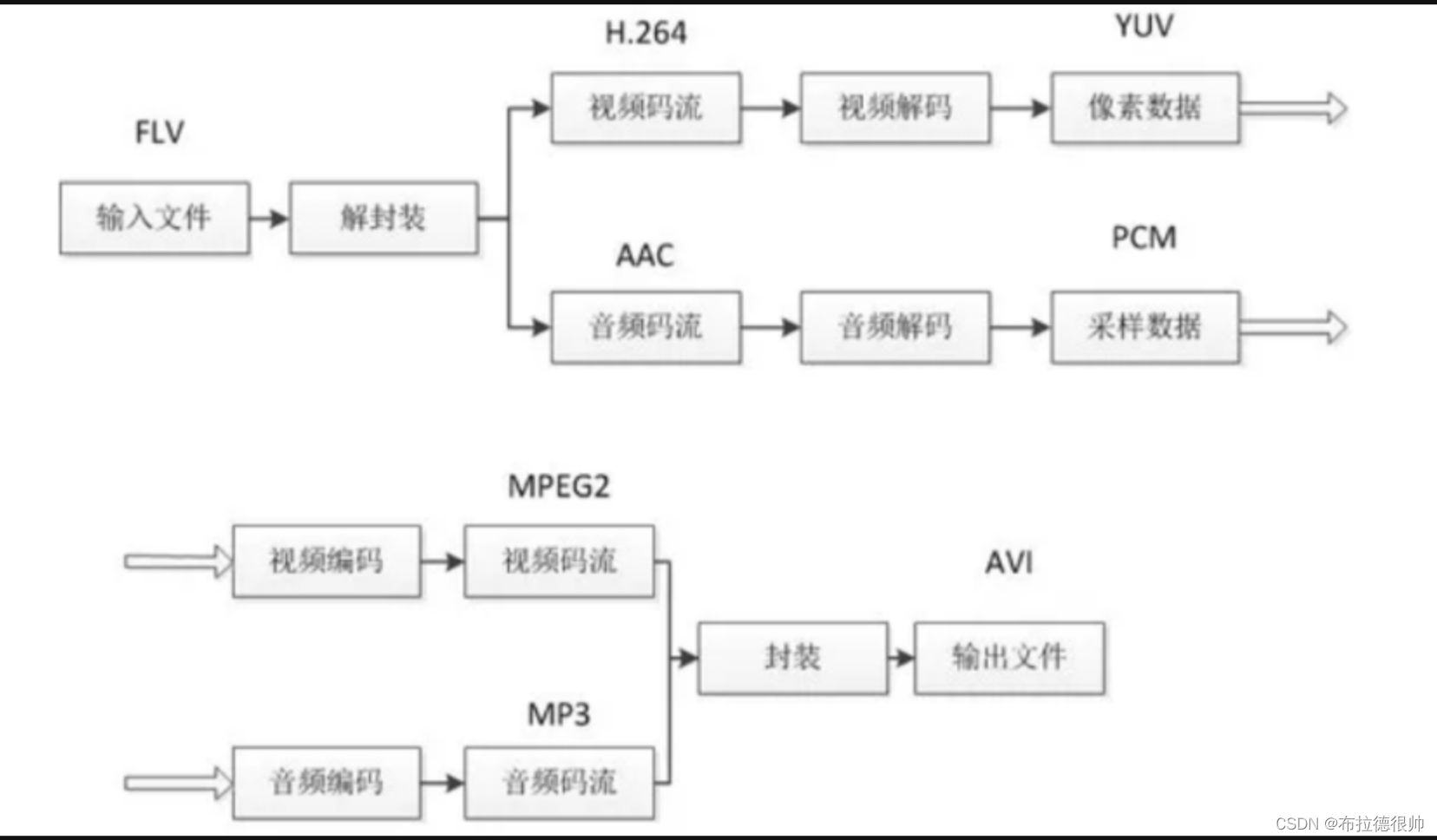

封装的目的:
1. 是为了在一个文件流(Stream)中能同时存储视频流(Video Stream)、音频流(Audio Stream)、字幕(Subtitle)、附件(t)、数据(d)等内容。这正是“复用”的含义所在(分时复用)。
2. 是在网络环境下确保数据的可靠快速传输。
编码的目的:
是为了压缩媒体数据。有别于通用文件数据的压缩,在图像或音频压缩的时候,可以借助图像特性(如前后关联、相邻图块关联)或声音特性(听觉模型)进行压缩,可以达到比通用压缩技术更高的压缩比