文章目录
简介
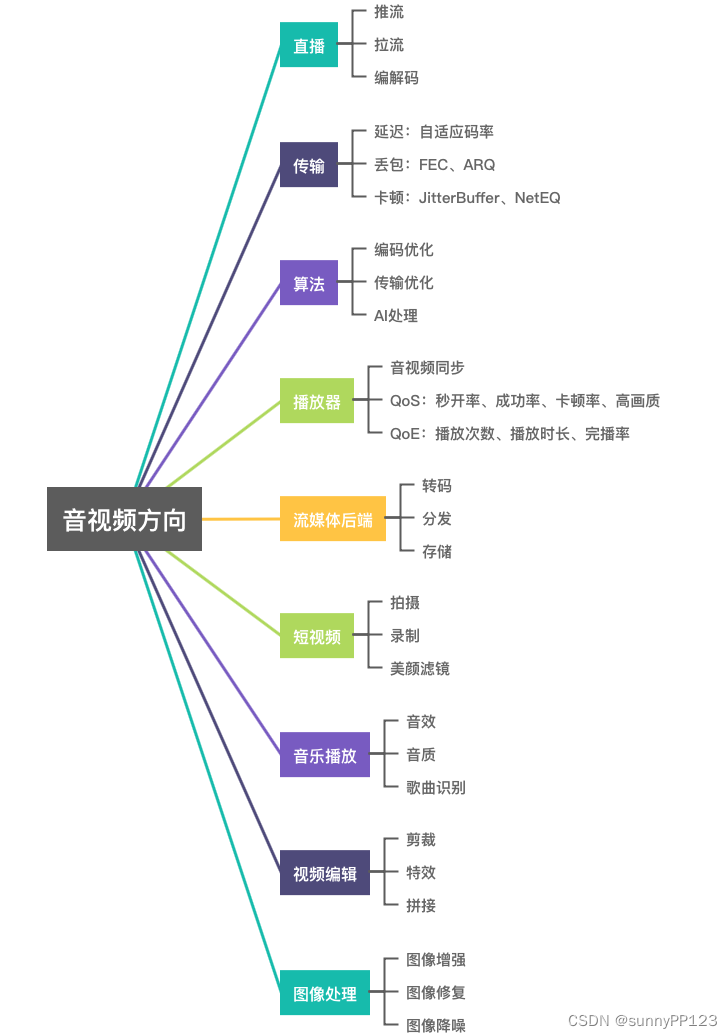
音视频技术涉及广泛。包括语音信号处理、数字图像处理、信息论、封装格式、编解码、流媒体协议、网络传输、渲染、算法等方面。在现实生活中,音视频也扮演着越来越重要的角色,比如 视频会议、直播、短视频、播放器、语音聊天 等。接下来将从几个维度进行介绍:简单理解音视频原理、音视频理论基础、音视频学习路线、媒体协议和音视频发展方向。
简单理解,音视频原理
很多人小时候,应该玩过个小游戏,在笔记本上连续几页绘制一只动物前后迈脚,然后快速翻页,就有了如下图 0的效果。这个过程就蕴含着,(视频)动画原理。音视频原理也是基于此。如再在翻页的时候,再配上声音,你学一声马叫”嘶……”。

图0
**音视频的简单原理,就是一段序列播放的图片,再同步播放相应的序列音频采样片。**如同 图0到3中所揭示的,里面就包含三个关键元素。
-
1、YUV图片。从H264、HEAC等编码的二进制数据中,解码出来的序列图片叫YUV图片,本质上跟常见的jpg、png一样。显卡的主要工作内容就是处理这些图形数据。
-
2、PCM音频。从mp3、aac等编码的二进制数据中,解码出来的序列音频采样点叫PCM音频数据,可以理解每一片PCM音频波形就是一个单位的声音.
-
3、音画同步。将序列图片帧连续渲染到计算机图层,同时根据同步参数DTS、PTS来同步播放音频帧,这就是视频的播放过程了。

图. 1
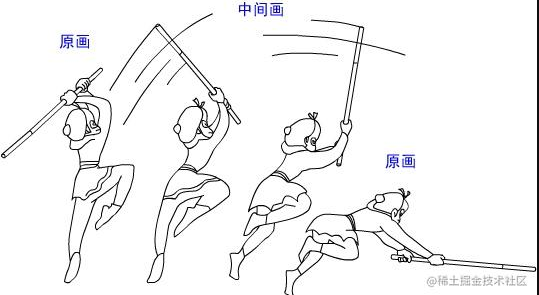
图. 2

图. 3
音视频理论基础
音频
音频(Audio)指人能听到的声音包括语音、音乐和其它声音如环境声、音效声、自然声等。
声音介绍

声音是一种物理现象。物体振动时产生声波通过空气传到人们的耳膜经过大脑的反射被感知为声音。
声音有频率和振幅的特征,频率对应于时间轴线,振幅对应于电平轴线。
为什么要存在数字音频 ?
由物理学可知,复杂的声波由许许多多具有不同振幅和频率的正弦波组成。

代表声音的模拟信息是个连续的量,不能由计算机直接处理,必须将其数字化。经过数字化处理之后的数字声音信息能够像文字和图形信息一样进行存储、检索、编辑和其它处理。
什么是数字音频?
我们知道声音可以表达成一种随着时间的推移形成的一种波形:

但是如果想要直接描述这样的一个曲线存储到计算机中,是没有办法描述的。
假如描述也只能是这样表达:曲线下去了,上去了,又下去了,又上去了,显然这样是很不合理的。
人们想到了一个办法:

每隔一个小小的时间间隔,去用尺子量一下这个点的位置在哪里。
那么只要这个间隔是一定的,我们就可以把这个曲线描述成:{9,11,12,13,14,14,15,15,15,14,14,13,12,10,9,7…}
这样描述是不是比刚才的方法要精确多了?如果我们把这个时间间隔取得更小,拿的尺子越精确,那么测量得到的,用来描述这个曲线的数字也可以做到更加地精确。
然后我们可以把这些电平信号转化成二进制数据保存,播放的时候就把这些数据转换为模拟的电平信号再送到喇叭播出,就可以了。
总的来说:数字音频是指使用数字编码的方式也就是使用0和1来记录音频信息,它是相对于模拟音频来说的。
从“模拟信号”到“数字化”的过程:
对于自然界的音频都是模拟信号,为了能够让计算机识别,需要从模拟信号转化为数字信号。
模拟信号到数字化的过程需要三个步骤:

1. 采样
所谓采样,又称为取样。采样的过程就是抽取某点的频率值,很显然,在一秒中内抽取的点越多,获取得频率信息更丰富。
采样的基本定理:为了复原波形,一次振动中,必须有2个点的采样,人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样。
2. 量化
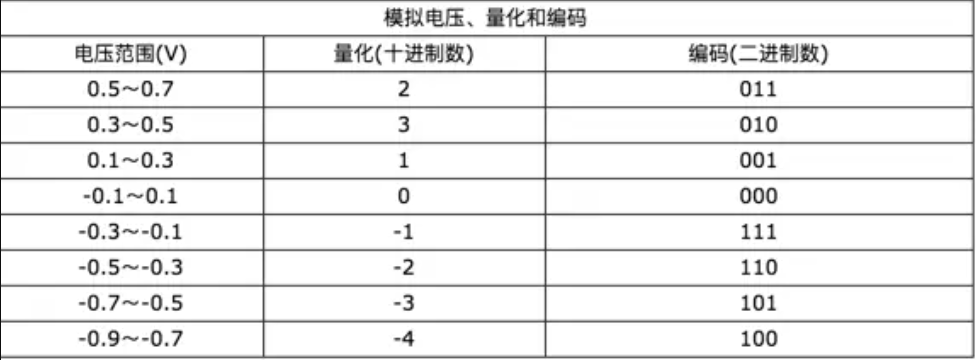
在数字音频技术中,把表示声音强弱的模拟电压用数字表示,如0.5V电压用数字20表示,2V电压是80表示。模拟电压的幅度,即使在某电平范围内,仍然可以有无穷多个,如1.2V,1.21V,1.215V…。而用数字来表示音频幅度时,只能把无穷多个电压幅度用有限个数字表示。即把某一幅度范围内的电压用一个数字表示,这称之为量化。
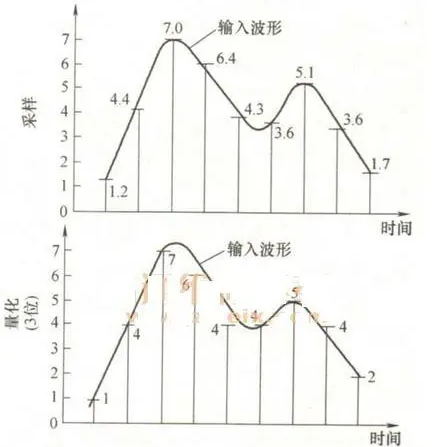
3. 编码
计算机内的基本数制是二进制,为此我们也要把声音数据写成计算机的数据格式,这称之为编码。
音频存储空间
计算公式为:(采样频率*采样位数*声道数)/8*时间(秒)。假设采样率为44.1k,声道数为2,采样位数为16。那么,每秒所占存储空间字节数=44100 * 2 * 16 / 8=176.4kb , 1分钟为10.09Mb 。
音频编码
音频编码的作用: 将音频采样数据(PCM 等)压缩成音频码流,从而降低音频的数据量。
音频压缩,主要压缩了哪些东西:
音频压缩技术是在保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩。
压缩的主要方法是去除采集到音频冗余信息。所谓冗余信息包括人耳听觉范围外的音频信号以及被遮蔽掉的音频信号。
信号的遮蔽可以分为频域遮蔽和时域遮蔽。
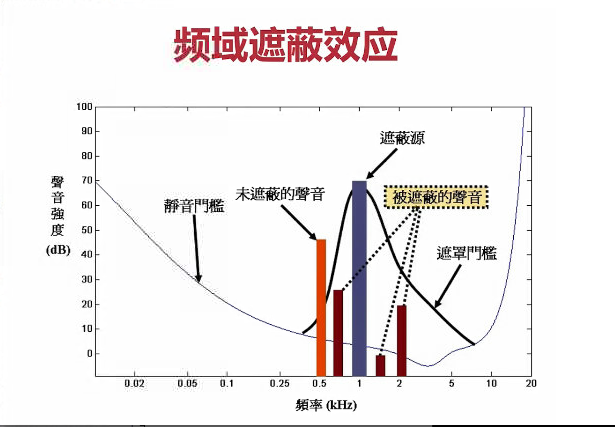
频域遮蔽效应就是,频率很相似的话,在一定的频率范围内,声音大的就会遮蔽声音小的。图中遮蔽源黑线覆盖了虚线指向的被遮蔽的声音,原因就是频率相似,但是声音小于遮蔽源的声音。所以被遮蔽了。
时域遮蔽效应,超出遮蔽时间的范围外,就被遮蔽了。
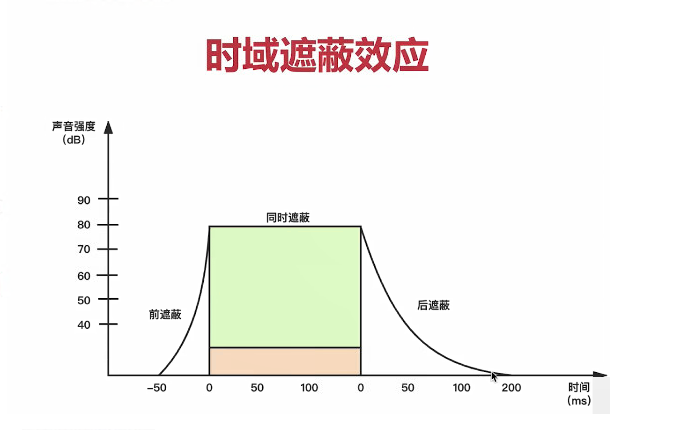
在听到某个强烈的声音后,听觉系统可能会暂时屏蔽掉某段时间内较弱的声音,导致这些声音在听觉系统内无法被处理和辨别。
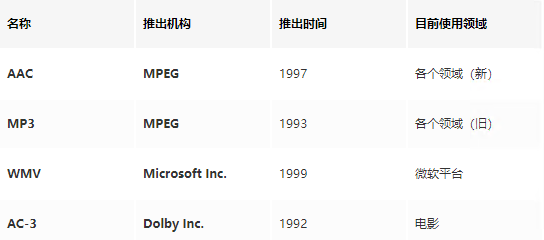
常用的音频编码方式有以下几种:
音频解码
音频解码是将压缩编码后的数字音频文件解码成原始音频信号PCM的过程。解码的过程是编码的逆过程,由于不同的音频文件使用的编码格式不同,因此也需要相应的解码器进行解码。
视频
连续的图象变化每秒超过24帧(Frame)画面以上时,根据视觉暂留原理,人眼无法辨别单幅的静态画面,看上去是平滑连续的视觉效果,这样连续的画面叫做视频。
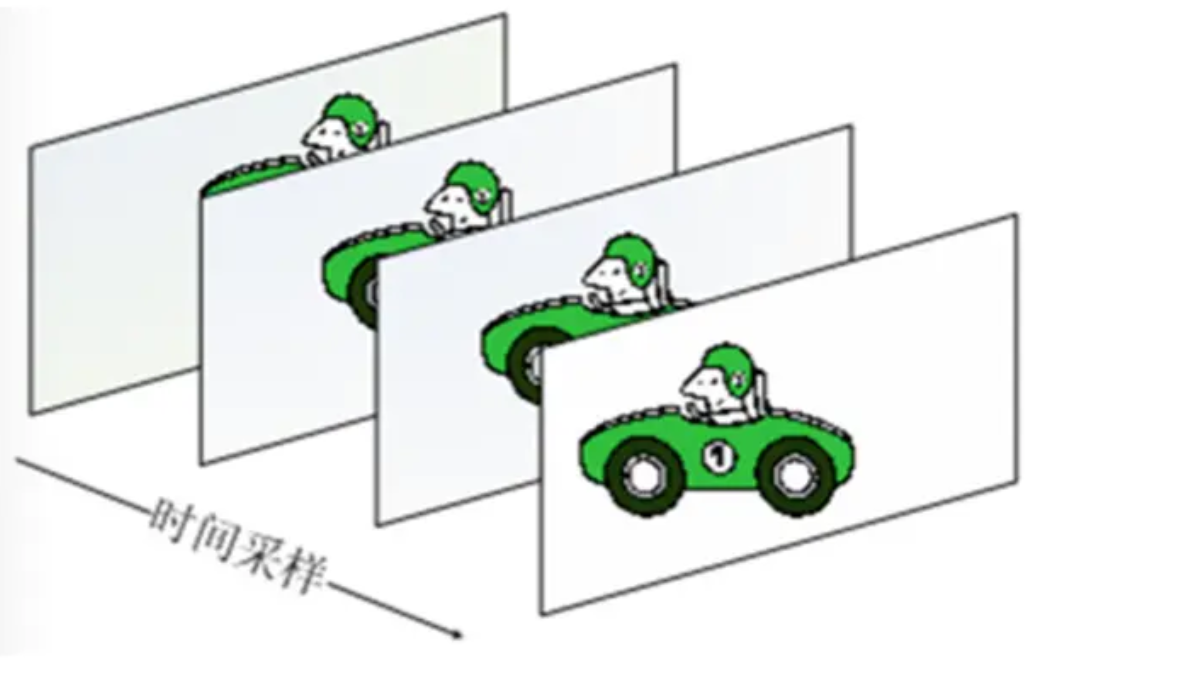
视频的基本单元其实是图像。
颜色模型
光和颜色
光是一种肉眼可以看见(接受)的电磁波可见光谱。
人类肉眼所能看到的可见光只是整个电磁波谱的一部分。电磁波之可见光谱范围大约为390~760nm(1nm=10-9m=0.000000001m)。
颜色是视觉系统对可见光的感知结果,研究表明人的视网膜有对红、绿、蓝颜色敏感程度不同的三种锥体细胞。红、绿和蓝三种锥体细胞对不同频率的光的感知程度不同,对不同亮度的感知程度也不同。
自然界中的任何一种颜色都可以由R,G,B 这 3 种颜色值之和来确定,以这三种颜色为基色构成一个RGB 颜色空间。
颜色=R(红色的百分比)+G(绿色的百分比)+B(蓝色的百分比),只要其中一种不是由其它两种颜色生成,可以选择不同的三基色构造不同的颜色空间。
YUV(YCbCr)颜色编码
相关实验表明,人眼对亮度敏感而对色度不敏感。因而可以将亮度信息和色度信息分离,以这样“欺骗”人的眼睛的手段来节省空间,从而适合于图像处理领域,从而提高压缩效率。

从上图我们可以看出,我们更容易识别去除色彩的图像,而对于单独剥离出的只有色彩的图像,不好识别。
因此有了YUV。YUV是另一种表示颜色的方式。 YUV也称为YCbCr。YUV 颜色编码采用的是 明亮度 Y 和 色度 UV 来指定像素的颜色。 “Y”表示明亮度(Luminance 或 Luma),也就是灰阶值。 “U” 和 “V” 表示的则是色度(Chrominance 或Chroma),作用是描述影像色调和饱和度。
YUV是一种亮度与色度分离的颜色空间表示方法。因此,与 RGB 相比,YUV 在响应亮度信息方面更为准确,同时去除了人眼感知中色度无关的特性,使得相对于 RGB,它具有更高的压缩性能,更适合于视频传输或存储。
YUV采样格式
RGB的采样格式每个像素有R、G、B三个分量,每个分量占8位或16位,这样每个像素就占了24位或48位。为节省带宽,大多数 YUV 格式平均使用的每像素位数都少于24位。
主要的采样格式有YUV4:2:0(使用最多)、YUV4:2:2和YUV4:4:4。4:2:0表示每4个像素有4个亮度分量,2个色度分量 (YYYYCbCr)。4:2:2表示每4个像素有4个亮度分量,4个色度分量(YYYYCbCrCbCr)、4:4:4表示全像素点阵(YYYYCbCrCbCrCbCrCbCr)。
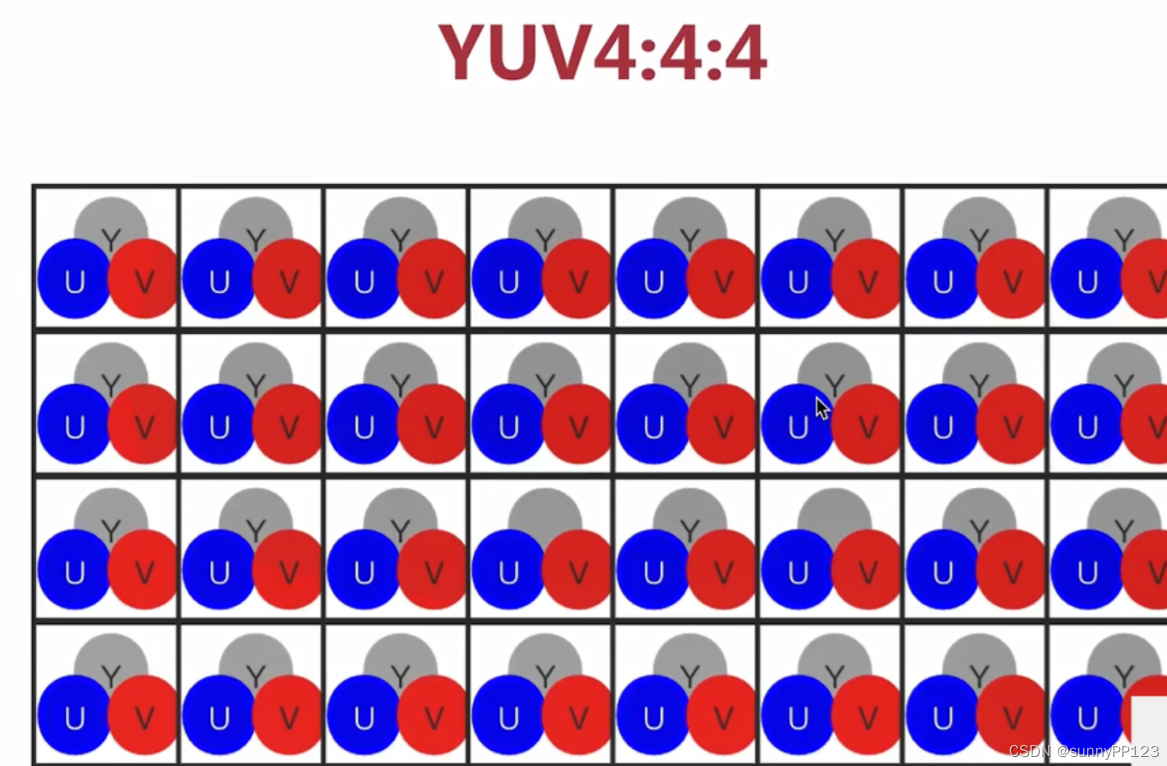
4:4:4 表示完全取样。和 RGB 大小一样
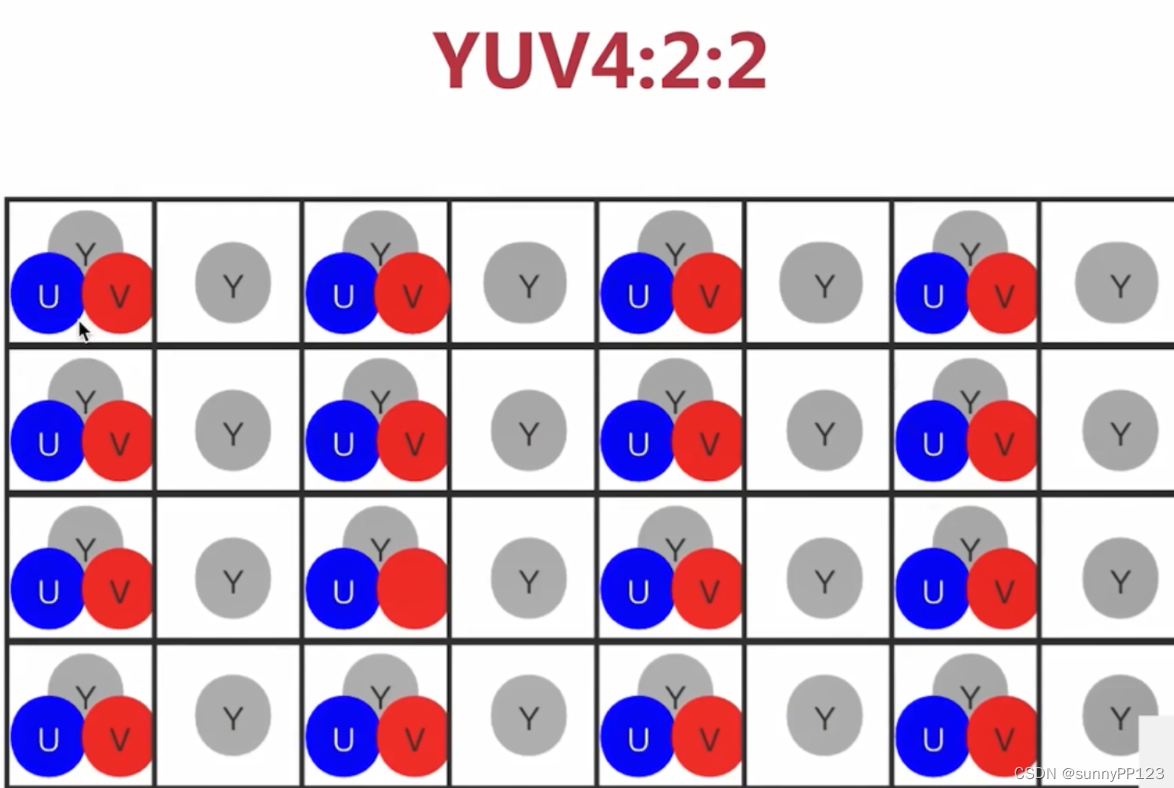
4:2:2 表示 2:1 的水平取样,垂直完全采样。比 RGB 小了三分之一。
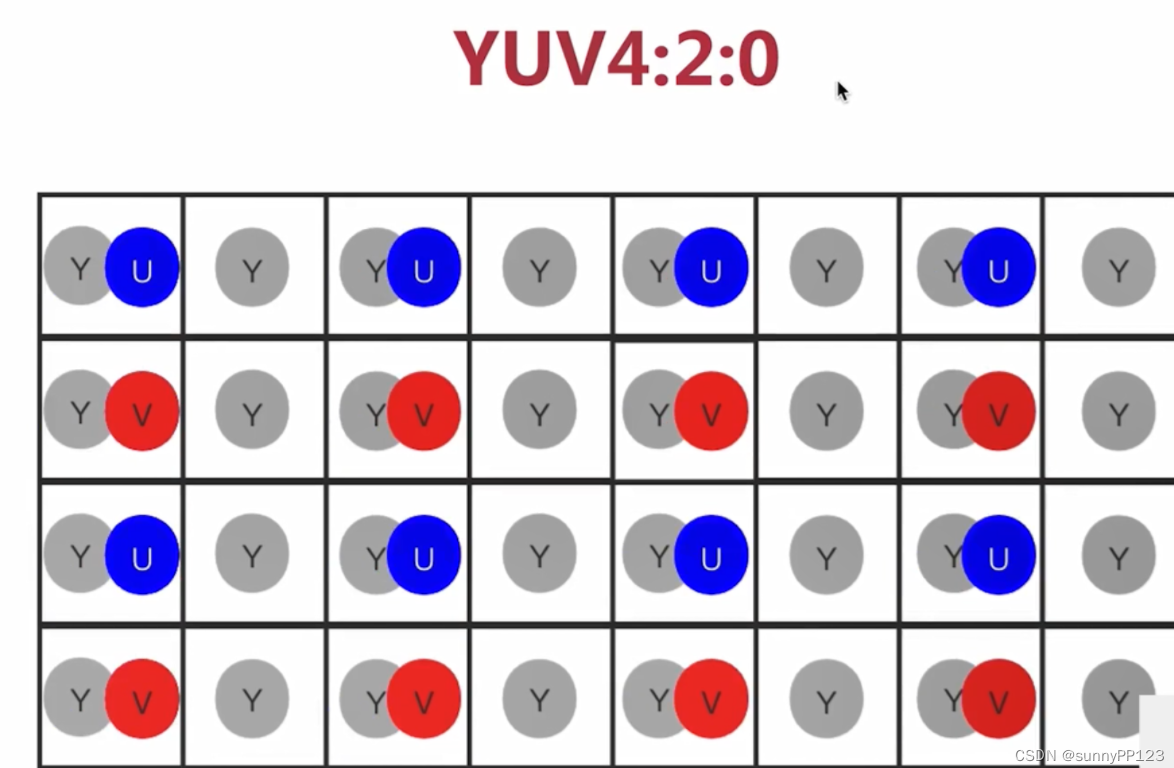
4:2:0 表示 2:1 的水平取样,垂直 2:1 采样,可以看出是每存储两行 Y,才会存储半行 U 和半行 V。比 RGB 小了二分之一
存储空间
视频码率 * 时间。
视频码率计算公式为:(帧率)* (图像分辨率)* (采样精度)* 1s。
那么一个 1小时电影的RGB24格式的数据体积为: 3600 * 25 * 1920 * 1080 * 24 / (8 * 1024 * 1024 * 1024) = 521.421 GByte (PS:这里帧率为 25Hz,RGB24图像使用24位表示每个像素,分辨率为1920*1080)。
视频编码
**采集的原始音视频信号体积都非常大,里面有很多相同的、眼看不到的、耳听不到的内容,**比如,如果视频不经过压缩编码的话,体积通常是非常大的,一部电影可能就要上百G的空间。
专业的来说,视频编码也就是文件当中的视频所采用的压缩算法,视频编码的主要作用是将视频像素数据(RGB,YUV等)压缩成为视频码流,从而降低视频的数据量。
视频压缩,主要压缩了哪些东西:
空间冗余:图像相邻像素之间有较强的相关性
时间冗余:视频序列的相邻图像之间内容相似
编码冗余:不同像素值出现的概率不同
视觉冗余:人的视觉系统对某些细节不敏感
知识冗余:规律性的结构可由先验知识和背景知识得到
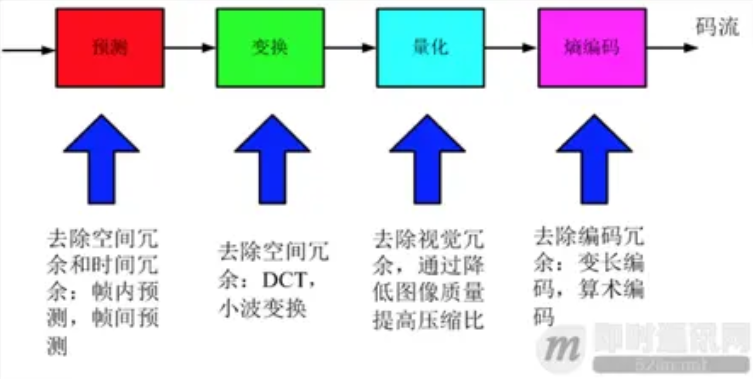
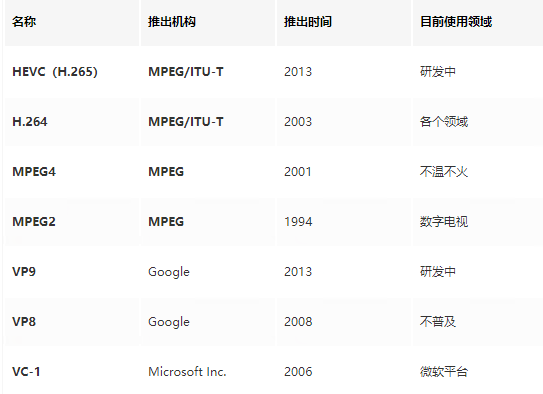
常见的视频编解码方式有,H.26X(H.264,H.265等),MPEG等。这里需要留意到,不同的视频封装格式,其实里面使用的编解码方式很多是可能一样的,封装格式是不同厂家的包装。这就好比,多个雪糕厂家生产一个口味的雪糕,外面的包装都是不一样的。
视频解码
有了编码,当然也需要有解码。
因为编码过的内容无法直接使用,使用(观看)时必须解码,还原为原始的信号(比如视频中某个点的颜色等),这就是解码。
视频解码的过程,就是将以某种编码方式(H264)进行编码的二进制数据,解码成YUV图片的过程,即“H.264->YUV”。 最广泛使用的莫过于FFmpeg这个开源的编解码套件,里面广泛涵盖了常见的编解码方式,还有封装格式(视频格式)。
封装格式
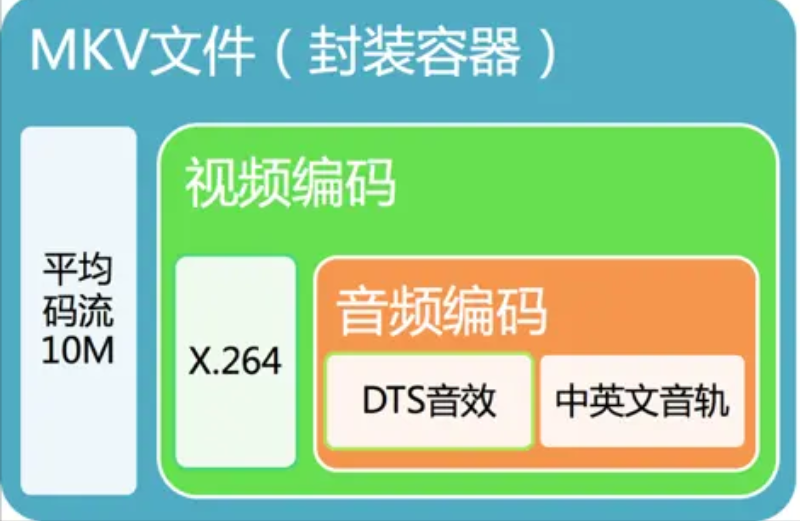
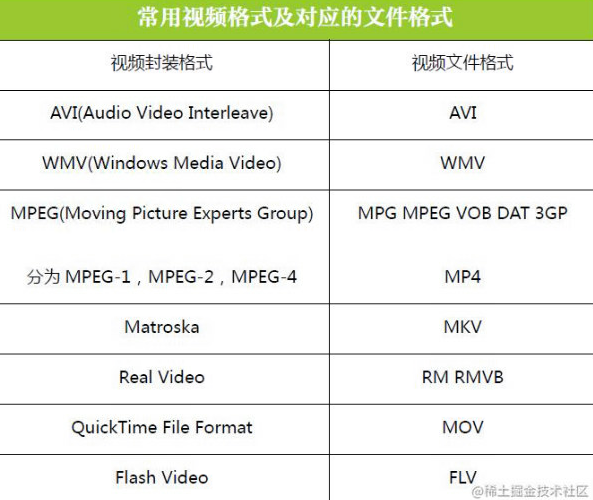
我们经常看到的视频格式mp4、avi、mkv。在技术概念中,叫『视频封装格式』,简称视频格式,里面包含了封装视频文件所需要的视频信息、音频信息和相关的配置信息(比如:视频和音频的关联信息、如何解码等等)。它就是一个外壳,相当于一个容器。常见的封装格式有:mp4、mkv、webm、avi、3gp、mov、wmv、flv、mpeg、asf、rmvb等。

(1)封装格式(也叫容器)就是将已经编码压缩好的视频轨和音频轨按照一定的格式放到一个文件中,也就是说仅仅是一个外壳,可以把它当成一个放视频轨和音频轨的文件夹也可以。
(2)通俗点说视频轨相当于饭,而音频轨相当于菜,封装格式就是一个碗,或者一个锅,用来盛放饭菜的容器。
(3)封装格式和专利是有关系的,关系到推出封装格式的公司的盈利。
(4)有了封装格式,才能把字幕,配音,音频和视频组合起来。
举例MKV格式的封装:
视频播放器原理
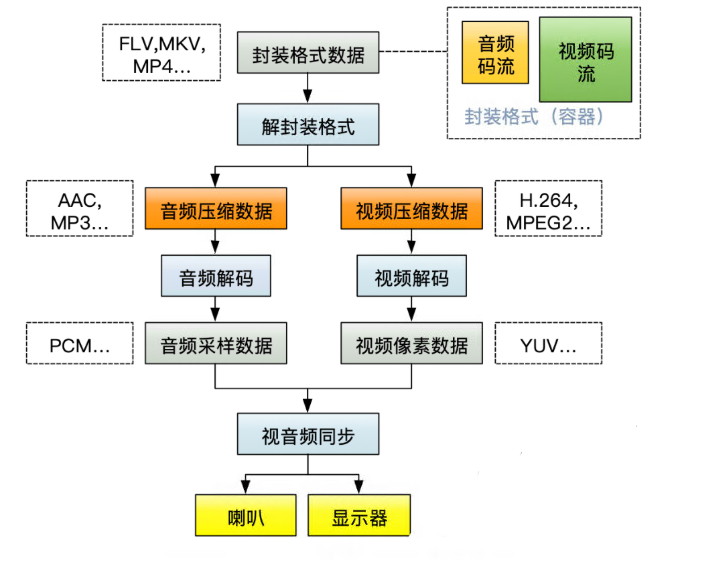
说了这么多概念就可以理解视频播放器的原理是怎么做的。
下面是播放一个视频文件时的流程图。
媒体协议
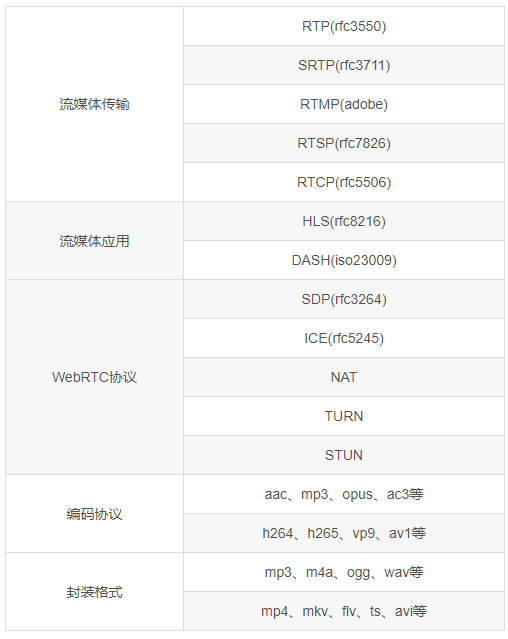
1、流媒体传输协议
除了本地视频的播放,我们经常用到的就是视频的在线播放(点播、直播)。需要在线播放就需要使用到流媒体协议的支持,常见的流媒体传输协议有:RTP、SRTP、RTMP、RTSP、RTCP等。其中RTP(Real-time Transport Protocol)是实时传输协议,而SRTP是安全实时传输协议,即在RTP基础上加密传输,防止音视频数据被窃取。RTMP(Real Time Messaging Protocol)是Adobe开源的实时消息传输协议,基于TCP,基本协议包括:RTMPE、RTMPS、RTMPT。RTSP(Real Time Streaming Protocol)是实时流传输协议,字段包括:OPTIONS、DESCRIBE、SETUP、PLAY、PAUSE、TEARDOWN等。RTCP(RTP Control Protocol)是RTP传输控制协议,用于统计丢包、发送延时。
2、流媒体应用协议
流媒体应用协议有:HLS、DASH。其中HLS是Apple公司开源的流媒体传输应用协议,同时涉及m3u8协议和ts流。而DASH是Google在广泛运用的流媒体协议,使用fmp4切片,支持自适应码率、多码率的无缝切换。
3、WebRTC信令协议
WebRTC (Web Real-Time Communications) 是一项实时通讯技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点]Peer-to-Peer)的连接,实现视频流和(或)音频流或者其他任意数据的传输。WebRTC信令协议有:SDP、ICE、NAT、STUN、TURN。当然,WebRTC的网络传输协议也有用到上面提及的流媒体传输协议。
4、音视频编码协议
常用的音频编码协议有:MP3、AAC、OPUS、FLAC、AC3、EAC3、AMR_NB、PCM_S16LE。视频编码协议有:H264、HEVC、VP9、MPEG4、AV1等。相关的音视频编解码协议,可参考:走进音视频的世界——音视频编码和走进音视频的世界——音视频解码。
5、音视频封装格式
常用的视频封装格式有:mp4、mov、mkv、webm、flv、avi、ts、mpg、wmv等。常用的音频封装格式有:mp3、m4a、flac、ogg、wav、wma、amr等。封装格式是多媒体容器,包含多媒体信息、音视频码流。其中多媒体信息包括:时长、分辨率、帧率、码率、采样率、声道数等等,即上面提及的音视频开发基础的相关概念。而音视频码流是原始数据经过编码压缩得到的若干帧组成的stream,字幕码流一般是由特定格式的文本或位图组成。关于封装格式,可以参考以前写过的文章:走进音视频的世界——音频封装格式和走进音视频的世界——视频封装格式。
以上涉及的协议具体如下:
学习路线
1. 音视频基础
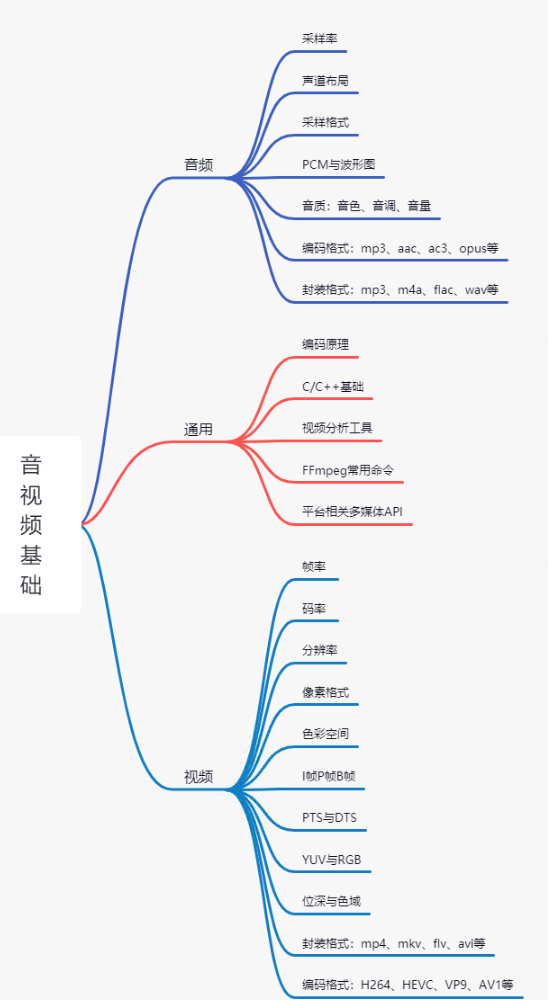
音频基础
音频包括:采样率、声道数与声道布局、采样格式、PCM与波形图、音质、音频编码格式、音频封装格式。详细内容见上述内容,音视频的基础概念。
通用基础
通用包括:编码原理、C/C++基础、视频分析工具、FFmpeg常用命令、平台相关多媒体API。
视频基础
视频包括:帧率、码率、分辨率、像素格式、色彩空间、I帧P帧B帧、DTS与PTS、YUV与RGB、位深与色域、视频编码格式、视频封装格式。详细内容见上述内容,音视频的基础概念。
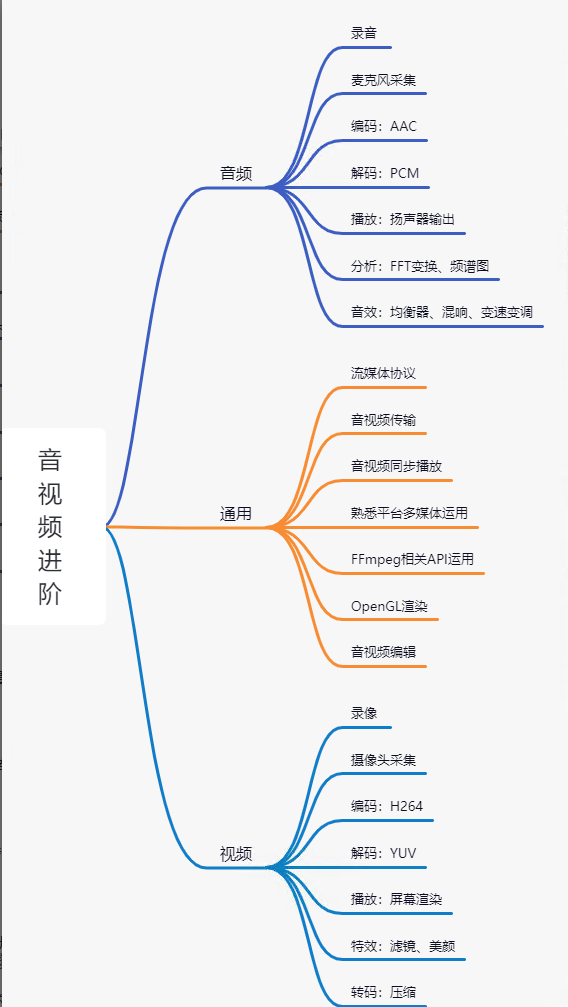
2. 音视频进阶
1、音频进阶
音视频进阶成长也是分为:音频、通用、视频。其中音频包括:录音、麦克风采集、音频编解码、音频播放、音频分析、音效。
2、通用进阶
通用包括:熟悉流媒体协议、音视频传输、音视频同步播放、平台相关多媒体运用、FFmpeg相关API运用、OpenGL渲染、音视频编辑。
3、视频进阶
视频包括:录像、摄像头采集、视频编解码、视频播放、滤镜特效、视频转码。在熟悉音视频基础上深入学习,如下图所示:
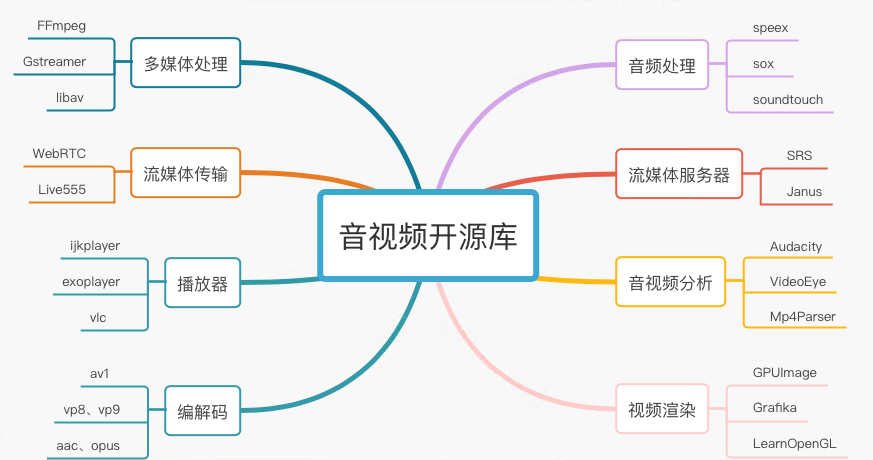
3. 音视频相关开源库
1、多媒体处理
多媒体处理包括:FFmpeg、libav、Gstreamer。其中FFmpeg是目前最常用的音视频处理库,包括封装格式、编解码、滤镜、图像缩放、音频重采样等模块。
2、流媒体传输
流媒体传输包括WebRTC、live555。其中WebRTC是目前最常用的RTC库,比较著名的模块有JitterBuffer、NetEQ、pacer、网络带宽估计。
3、播放器
播放器包括:ijkplayer、exoplayer、vlc。其中ijkplayer是B站开源的跨平台播放器,exoplayer是Google开源的Android平台播放器,vlc属于VideoLAN非盈利组织所开源。
4、编解码
常用的编解码包括:aac、mp3、opus、vp9、x264、av1。其中aac一般用于点播、短视频,opus用于RTC直播。vp9是Google开源的编码器,VideoLAN有提供x264编码器,av1是AOMedia(开放媒体联盟)开源的新一代视频编码器。
5、音频处理
音频处理的开源库包括:sox、soundtouch、speex。其中sox称为音频处理界的瑞士军刀,可以做各种音效、提供各种滤波器。soundtouch用于变速变调、变速不变调。speex严格意义上讲,它是一个编码器,但是它有丰富的音频处理模块:PLC(丢包隐藏)、VAD(静音检测)、DTX(非连续传输)、AEC(回声消除)、NS(噪声抑制)。
6、流媒体服务器
流媒体服务器主流的有:SRS、janus。其中SRS是一款简单高效的视频服务器,支持RTMP、WebRTC、HLS、HTTP-FLV、SRT。而janus是MeetEcho公司开源的基于WebRTC的流媒体服务器,严格意义上讲它是一个网关。
7、音视频分析
做音视频开发绕不开分析工具,掌握使用分析工具至关重要。常用的音视频分析工具包括但不限于:Mp4Parser、VideoEye、Audacity。其中Mp4Parser用于分析mp4格式及其结构。VideoEye是雷神开源的基于Windows平台分析视频码流工具(在此致敬雷神的开源精神)。Audacity是一款开源的音频编辑器,可用于添加各种音效、分析音频波形图。
8、视频渲染
视频渲染相关开源库有:GPUImage、Grafika、LearnOpenGL。其中GPUImage可用于添加各种滤镜特效。Grafika是Google一位工程师开源的基于Android平台渲染示例库。LearnOpenGL主要是配套其网站的学习OpenGL教程。
相关的开源网站与地址如下:
| 项目 | Value |
|---|---|
| FFmpeg | https://ffmpeg.org/ |
| WebRTC | https://webrtc.org.cn/ |
| RTC社区 | https://rtcdeveloper.agora.io/ |
| RFC协议 | https://www.rfc-editor.org/rfc/ |
| OpenGL | https://learnopengl-cn.github.io/ |
| GPUIimage | https://github.com/BradLarson/GPUImage |
| 电脑 | https://www.videolan.org/projects/ |
| AOMedia | https://aomedia.org/ |
| xiph.org | https://gitlab.xiph.org/ |
| VP9 | https://www.encoding.com/vp9/ |
| soundtouch | http://soundtouch.surina.net/ |
| sox | http://sox.sourceforge.net/ |
发展方向