一、数据同步
1. 原子类
在针对多线程数据原子性问题除了通过加锁的方式外, Java 提供了一系列原子类(如 AtomicInteger 等)以保证数据的原子性,其核心通过反射获取 Unsafe 实例从而实现 CAS 操作,保证了数据的原子性。
以 AtomicInteger 类为例,下表中列出其常用方法及其描述信息。
| 方法 | 作用 |
|---|---|
| set() | 为对象设置值。 |
| get() | 获取对象值。 |
| incrementAndGet() | 返回对象自增 1 后的值,同理还有 getAndIncrement()。 |
| decrementAndGet() | 返回对象自减 1 后的值,同理还有 getAndDecrement()。 |
同样以 AtomicInteger 举例,示例代码如下:
java
复制代码
public void AtomicDemo() { AtomicInteger atomicInteger = new AtomicInteger(1); // 修改值 atomicInteger.set(2); System.out.println("get: " + atomicInteger.get()); // 等价自增 atomicInteger.incrementAndGet(); System.out.println("incrementAndGet: " + atomicInteger); // 等价自减 atomicInteger.decrementAndGet(); System.out.println("decrementAndGet: " + atomicInteger); }
(1)AtomicReference
除了自带的 AtomicInteger 等原子类,可通过 AtomicReference 为泛型类提供原子操作。
AtomicReference 声明的对象操作与 AtomicInteger 等系统已经封装好的原子类类似,可在定义时通过 new 关键字设置初始化值,也可通过后续的 set() 方法设置值,其操作皆满足线程安全。
java
复制代码
public void referenceDemo() { AtomicReference<Integer> atomicReference = new AtomicReference<>(0); atomicReference.updateAndGet(it -> it + 1); System.out.println("Get: " + atomicReference.get()); AtomicReference<User> userAtomic = new AtomicReference<>(new User("Alex")); userAtomic.getAndUpdate(it -> new User("Beth")); System.out.println("Get: " + userAtomic.get()); } static class User { private String name; public User(String name) { this.name = name; } }
2. Volatile
在了解 volatile 关键字之前,我们需要先初步了解一下 JVM 内存工作机制。
(1)内存机制
在 JVM 中内存可以粗暴的分为 主内存 和 本地内存,默认所有的变量声明都存放在 主内存 中,当一个线程需要修改变量的值时需要先从 主内存 中以副本的形式读取至线程的 本地内存 ,完成更改后再将新值重新写回 主内存。而读取到写回这个过程中即存在时间差,若未能及时写回 主内存,其它进程获取的值仍为未发生改变之前的值,从而引发数据不一致问题。
(2)Volatile 作用
为了解决上述提到的读写时间差造成的影响,在 Java 中提供了 volatile 关键字,即通过 volatile 声明的变量对任意一个线程都是实时可见的,同时能够避免程序的指令重排。
注意其只能保证变量的 可见性,即变量发生变化会立即更新主存数据,但若并发操作 volatile 变量仍会出现原子性问题,同时注意 volatile 只能修饰 类变量 和 实例变量 ,对于 方法参数 与 常量 等等均非法。
(3)示例演示
下面通过一个示例演示 volatile 的效果,示例中分别创建了两个读写线程,一个用于更新数据,另一个用于监控变量 num 的变化情况并打印输出。
完整的测试代码如下,分别执行 num 在没有使用 volatile 修饰与使用 volatile 修饰的情况。
java
复制代码
public class VolatileExample { private volatile static int num = 0; public static void main(String[] args) throws InterruptedException { new Thread(() -> { int local = num; while (local < 3) { // 监控 num 值变化,记录最新值 if (num != local) { System.out.println("receive change: " + num); local = num; } } }, "Reader").start(); new Thread(() -> { int local = num; while (local < 3) { // 修改 num 值 System.out.println("change to: " + ++local); num = local; try { // 休眠使 Reader 获取变化 sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }, "Updater").start(); // 等待线程结束 TimeUnit.SECONDS.sleep(10); } }
在未使用 volatile 的情况下,当 Updater 更新 num 的值并不是立刻写回主存,导致 Reader 未能读的数据仍是变更之前的变量,因此在判断 num != local 条件时永远是 false,最后打印的信息中 update 也因此缺失。
txt
复制代码
// 未使用 volatile change to: 1 receive change: 1 change to: 2 change to: 3
而在使用 volatile 的情况下,因为实现了 num 变量的多线程可见性,Reader 线程也就能够实现监控 num 变量的实际变更状况。
txt
复制代码
// 使用 volatile change to: 1 receive change: 1 change to: 2 receive change: 2 change to: 3 receive change: 3
(4)单例模式
volatile 通常用于多线程下的状态监控记录,同时其还可搭配锁实现单例模式。
如下实例代码中通过 volatile 与 synchronized 搭配实现了简易的单例模式,在多线程的情况下通过 volatile 保证了 instance 实例的可见性,同时利用 synchronized 保证对象不会被重复初始化。
主要注意这里在 synchronized 的同步块中需要二次判断实例对象,假设在并发情况下若 线程A 成功拿到锁并进行实例化,在此过程中其它线程正处于自旋取锁状态,当 线程A 完成对象实例化并通过 volatile 关键字将数据回写主存并释放锁之后,之前自旋状态的线程将会取得锁并执行同步块内容,若不进行二次判断则会造成重复实例化,且因为实例声明为 volatile 因此判断结果将为 false 退出同步块返回已经完成实例的对象。
java
复制代码
public class Singleton { private volatile static Singleton instance = null; public static Singleton getInstance() { // 实例为空则获取锁 if (instance == null) { synchronized (Singleton.class) { // synchronized 防止多线程同时初始化实例 if (instance == null) instance = new Singleton(); } } return instance; } }
3. 指令重排
在上一点中讲到了 Volatile 可以禁止实现指令重排,首先介绍一下什么是指令重排。
在运行 Java 文件时,当代码行之间没有强依赖时它的执行顺序不一样是按照编写的顺序,如图示例在实际编译时 int b = 20 的执行可能会在 int a = 10 之前,因为二者并无强关联,谁先定义都不影响程序的正确执行。但 int sum = a + b 一定是在 a 和 b 定义之后才会运行,因为 sum 的值强依赖于 a 和 b ,这个过程就是指令重排。
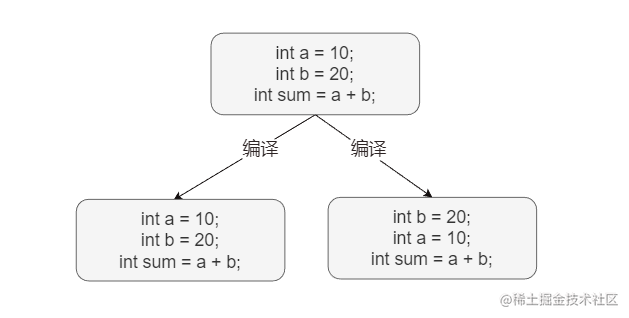
而由 Volatile 关键字修饰的变量其在写入之前需要先完成读取,同时写入完成之后需立即回写进主内存,其读写的顺序是确定且无法改变的,因此也就无法实现指令重排。
4. ThreadLocal
ThreadLocal 正如名称所示,是每个人线程单独的存储的空间,通常用于存储线程中的某些状态值。不同线程之间的 ThreadLocal 变量都独立存在无法相互通讯,子线程会继承父线程的 ThreadLocal 变量。
注意 ThreadLocal 在使用完成之后一定要通过 remove() 方法回收,因为 ThreadLocal 变量会随着线程的周期终止而回收,但在涉及到线程池时,每个线程在完成任务之后并返回线程池后不一定会被销毁而是进入空闲状态,意味着创建的 ThreadLocal 也将一直存在无法被垃圾回收,从而导致内存泄漏,因此在设置 ThreadLocal 操作时建议配合 try catch 使用并在 finally 中通过 remove() 释放。
| 方法 | 作用 |
|---|---|
| get() | 为当前线程创建一个存储对象。 |
| set() | 修改当前线程其本地对象的值。 |
| remove() | 释放当前线程其本地对象。 |
(1) 示例介绍
在下述的示例中,我们创建了一个 ThreadLocal<Integer> 对象,该对象可以存储 Integer 类型的值,当在不同的线程中通过 get() 方法将会为每个线程初始化一份单独的副本。接着我们创建两个子线程,并在每个子线程中通过 threadLocal.get() 与 threadLocal.set() 方法获取值与设置值。
运行示例可以看到每个线程都有自己独立的值,并不会相互干扰,两个子线程各自输出的其设置的哈希值。
java
复制代码
public class ThreadLocalExample { private static ThreadLocal<Integer> threadLocal = new ThreadLocal<>(); public static void main(String[] args) { // 创建两个子线程 Thread thread1 = new Thread(new MyRunnable()); Thread thread2 = new Thread(new MyRunnable()); // 启动子线程 thread1.start(); thread2.start(); try { // 等待子线程执行完毕 thread1.join(); thread2.join(); } catch (InterruptedException e) { e.printStackTrace(); } } static class MyRunnable implements Runnable { @Override public void run() { // 在子线程中获取值 System.out.println("Thread value: " + threadLocal.get()); // 在子线程中设置新值 threadLocal.set(Thread.currentThread().hashCode()); // 再次获取值 System.out.println("Thread value after set: " + threadLocal.get()); } } }
(2) 应用场景
当在并发操作中涉及非线程安全操作时,通常即使用 ThreadLocal 避免非线程安全对象的并发操作。
如 Java 中时间格式化 SimpleDateFormat 对象是非线程安全的,当多线程并发操作时将会抛出异常,此时即可通过 ThreadLocal 为每个线程定义单独的 SimpleDateFormat 对象。
如下示例中定义了容量为 5 的线程池模拟并发,并在每个线程中通过 SimpleDateFormat 实现时间格式化,若在 for 循环上一步定义公共的 SimpleDateFormat 对象并在每个子线程调用其实现时间转为将会抛出异常。
java
复制代码
public class SafeDateFormatTest { private static final ThreadLocal<DateFormat> dateFormatThreadLocal = ThreadLocal.withInitial(() -> { return new SimpleDateFormat("yyyy-MM-dd"); }); public static void main(String[] args) throws ExecutionException, InterruptedException { ExecutorService threadPool = Executors.newFixedThreadPool(5); List<Future<Date>> results = new ArrayList<Future<Date>>(); // perform 10 date conversions for (int i = 0; i < 10; i++) { results.add(threadPool.submit(() -> { Date date; try { date = dateFormatThreadLocal.get().parse("2023-01-01"); } catch (ParseException e) { throw new RuntimeException(e); } return date; })); } threadPool.shutdown(); // look at the results for (Future<Date> result : results) { System.out.println(result.get()); } } }
二、锁的介绍
1. 基本分类
Java 线程锁的分类如果进行细分的话是非常多的,这里仅对常遇到的一些分类简要介绍,注意下面分类之间并不是互斥的。
-
乐观锁
乐观锁顾名思义就是以更宽松的方式进行加锁,认为别的线程在持有锁的时候不进行值变化只做读取,因此允许多个对象同时持有锁,同伴版本号机制控制实现一致性。
-
悲观锁
悲观锁与乐观锁则恰好相反,任务任何进程在持有锁都可能对变量进行更改,因此在持锁期间其它进程均无法获取同一个锁实例。
-
自旋锁
自旋锁即当锁实例被其它进程获取而当前进程不断重复尝试获取锁(阻塞)的情况,则称此类行为是自旋锁。
-
公平锁
公平锁即当锁被进程占用时,其它进程若需要获取锁则进入排队等待,采取先到先得的分配机制,如通过
new ReentrantLock(true)创建的即为公平锁。 -
非公平锁
非公平锁即当锁被进程持有结束后,其它进程若需要获取锁则会随机进行分配,此机制可能导致线程饥饿问题,即最先请求的进程却一直无法获取锁,常见的
synchronized与ReentrantLock皆为非公平锁。 -
可重入锁
可重入锁即一个锁实例可以被同一个进程重复获取,如
ReentrantLock就是典型的可重入锁,通常需要配合计数器进行使用,当计数器归零则释放锁。 -
不可重入锁
不可重入锁即锁实例无法被同一进程重复的获取,
synchronized自身为可重入锁,但搭配计数器即可实现一个不可重入效果。
2. 锁的意义
在单线程中我们很清楚的知道哪个线程在操作变量,但在多线程中显然这一切就不那么明朗了,因为其有一个明显的问题,那就是变量冲突。
举个简单例子,程序中一共存在两个线程,分别需要针对变量 count 做 1000 次自增与自减,理论上当程序执行完毕后 count 的结果值应该为 0 ,示例代码如下:
java
复制代码
private int count = 0; public void demo() throws InterruptedException { Thread thread1 = new Thread(() -> { for (int i = 0; i < 10000; i++) { count += 1; } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 10000; i++) { count -= 1; } }); thread1.start(); thread2.start(); thread1.join(); thread2.join(); // 输出结果未知 System.out.println(count); }
但执行上述程序却发现每次输出得到的结果却并非为 0 且每次结果都不相同,这其实是因为 Java 中的一个加减乘除在底层编译时其对应的步骤不止一步。
如最常用的自增 i = i + 1 ,在底层编译实现时其对应着三个步骤: 读取 -> 增加 -> 写入 ,而这三步中的任意一步出现问题都会导致最终的结果异常。回到上面的代码中,当 线程 1 进行自增操作时,实际上可能只做了 读取 增加 ,在完成写入之前 线程 2 却获取变量实例完成自减导致自增 写入 失败,结果就是经过一次自增自减结果却为 -1 。
3. 分级锁
在 JDK1.8 中 JVM 会根据使用情况对 synchronized 的锁进行升级,它大体可以按照下面的路径:偏向锁 -> 轻量级锁 -> 重量级锁。锁只能升级不能降级,所以一旦升级为重量级锁就只能依靠操作系统进行调度。
锁升级过程中关系最大的就是对象头里的 MarkWord ,它包含 Thread ID、 Age、 Biased、 Tag 四个部分。其中Biased 有 1bit 大小,Tag 有 2bit ,锁升级即依据 Thread Id、 Biased、 Tag 三个变量值进行。
-
偏向锁
在只有一个线程使用了锁的情况下,偏向锁能够保证更高的效率。
当第一个线程第一次访问同步块时,会先检测对象头
Mark Word中的标志位Tag是否为01,以此判断此时对象锁是否处于无锁状态或者偏向锁状态(匿名偏向锁)。01也是锁默认的状态,线程一旦获取了这把锁,就会把自己的线程ID写到MarkWord中,在其他线程来获取这把锁之前,锁都处于偏向锁状态。 -
轻量级锁
当下一个线程参与到偏向锁竞争时,会先判断
MarkWord中保存的线程ID是否与这个线程ID相等,如果不相等,会立即撤销偏向锁,升级为轻量级锁。参与竞争的每个线程,会在自己的线程栈中生成一个
LockRecord(LR),然后每个线程通过自旋(CAS)的方式(即不断的尝试取锁),将锁对象头中的MarkWord设置为指向自己的LR的指针,哪个线程设置成功,就意味着哪个线程获得锁。当锁处于轻量级锁的状态时,就不能够再通过简单的对比
Tag的值进行判断,每次对锁的获取,都需要通过自旋。当然自旋也是面向不存在锁竞争的场景,比如一个线程运行完了,另外一个线程去获取这把锁,但如果自旋失败达到一定的次数,锁就会膨胀为重量级锁。 -
重量级锁
重量级锁即为我们对
synchronized的直观认识,这种情况下线程会挂起,进入到操作系统内核态等待操作系统的调度,然后再映射回用户态。系统调用是昂贵的,重量级锁的名称由此而来。如果系统的共享变量竞争非常激烈,锁会迅速膨胀到重量级锁,这些优化就名存实亡。如果并发非常严重,可以通过参数
-XX:-UseBiasedLocking禁用偏向锁,理论上会有一些性能提升,但实际上并不确定。
三、常用锁
在多线程中常需要对共享变量或操作加锁,从而保证在同一时刻保证只能有一个线程能对变量进行操作,实现变量的原子性,下面即介绍 Java 中常用的锁对象。
1. synchronized
synchronized 是最基础的锁对象之一,通过在方法前添加 synchronized 可隐式锁住 this 关键字,使得当其它进程想要访问变量时则无法获取,只有在同步块代码执行结束后自动释放的锁其它进程才能再次获取,从而达到原子性的目的。
改造之前提到的示例代码即可得到我们想要的结果。
java
复制代码
private int count = 0; public void demo() throws InterruptedException { Thread thread1 = new Thread(() -> { for (int i = 0; i < 10000; i++) { synchronized(this) { // 加锁 synCount += 1; } } }); Thread thread2 = new Thread(() -> { for (int i = 0; i < 10000; i++) { synchronized(this) { // 加锁 synCount -= 1; } } }); thread1.start(); thread2.start(); thread1.join(); thread2.join(); System.out.println(count); }
2. ReentrantLock
在 Java 中提供了 ReentrantLock 实现更轻量化的加锁操作。
我们知道一个锁只能同时被一个线程获取,因此当一个锁被其它线程持有时,使用 synchronized 将会一直尝试取锁直至获取锁对象,一旦逻辑异常极易出现死循环。而 ReentrantLock 除了基础加锁外提供 tryLock() 方法可设置取锁超时时间,到期未获取锁将推出阻塞继续执行剩余代码。
(1)lock()
通过 lock() 即可实现加锁操作,同一个线程对象只能持有一把锁,注意当使用 lock() 执行加锁操作若失败则会一直尝试取锁,导致程序陷入阻塞无法执行后续代码。
在使用时建议将代码块置于 try catch 中,并在 finally 中通过 unlock() 释放锁,防止程序异常导致未正常释放锁从而引发死锁问题。
java
复制代码
public void demo1() throws Exception { Lock lock = new ReentrantLock(); Thread thread1 = new Thread(() -> { // 加锁 lock.lock(); try { sleep(10 * 1000); } finally { // 一定要释放锁 lock.unlock(); } }); Thread thread2 = new Thread(() -> { // 锁被线程 1 持有无法获取 lock.lock(); System.out.println("get lock"); }); thread1.start(); Thread.sleep(500); thread2.start(); thread1.join(); thread2.join(); }
(2)tryLock()
tryLock() 作用与 lock() 类似,但其可以设置取锁超时时间,在指定时间内若没有取到锁将继续返回 false 并继续执行剩余代码。
如在下述示例中 thread2 在尝试加锁两秒后若未能加锁成功将会返回 false 并继续执行其后代码,若将其替换为 lock() 方法则其将进入死锁循环,导致程序资源的浪费。
java
复制代码
public void demo2() throws Exception { Lock lock = new ReentrantLock(); Thread thread1 = new Thread(() -> { // 加锁, 但不释放锁 lock.lock(); }); Thread thread2 = new Thread(() -> { try { // 尝试加锁,两秒后未取锁继续执行后续内容 boolean isLock = lock.tryLock(2, TimeUnit.SECONDS); System.out.println("carry on..."); } catch (InterruptedException e) { e.printStackTrace(); } }); thread1.start(); Thread.sleep(500); thread2.start(); thread1.join(); thread2.join(); }
3. ReadWriteLock
上述的两类锁虽然能够实现原子性,但一刀切的锁显然在效率上会略到折扣,因此 Java 中提供了一系列读写锁, ReadWriteLock 即为其中之一。
在查看需求大于修改的业务下,如针对论坛等功能,允许多用户同时查看但禁止多用户同时修改,通过读写锁将互斥逻辑实现剥离,实现更细粒度的并发控制,在保证线程安全的情况下实现不错的性能表现。
(1)特性
ReadWriteLock 中分为 读锁 和 写锁 ,其特性如下:
读锁之间是不互斥的,即读锁可同时被多个线程持有。写锁之间也是互斥的,在同一时刻最多仅有一个线程能持有写锁。读锁和写锁之间是互斥的,即读锁和写锁不能同时持有,二者有且仅有一个处于持有状态。
(2)初始化
ReadWriteLock 初始化方式如下所示:
java
复制代码
public void init() { // 声明一个读写锁 ReadWriteLock rwLock = new ReentrantReadWriteLock(); // 读锁,允许多线程持有 Lock rLock = rwLock.readLock(); // 写锁,仅允许单线程持有 Lock wLock = rwLock.writeLock(); }
(3) 同步示例
了解的读写锁的基本概念之后通过简单的示例更深入明白其作用。
为了方便后续测试这里分别定义了一个 读线程 与 写线程 ,并通过休眠操作模拟程序耗时。
java
复制代码
class ReadThread extends Thread { private String name; public ReadThread(String name){ this.name = name; } @Override public void run() { rLock.lock(); try { System.out.println(name + " do read."); // Simulate program timing TimeUnit.SECONDS.sleep(3); System.out.println(name + " sleep over."); } catch (InterruptedException e) { e.printStackTrace(); } finally { rLock.unlock(); } } } class WriteThread extends Thread { private String name; public WriteThread(String name){ this.name = name; } @Override public void run() { wLock.lock(); try { System.out.println(name + " do write."); // Simulate program timing TimeUnit.SECONDS.sleep(3); System.out.println(name + " sleep over."); } catch (InterruptedException e) { e.printStackTrace(); } finally { wLock.unlock(); } } }
根据上面声明的读写线程,下面分别提供了 双读锁 、 一读一写 以及 双写锁 三个示例。
具体的测试代码如下:
java
复制代码
/** * 双读锁示例,不互斥 */ public void demo1() throws InterruptedException { Thread reader1 = new ReadThread("Reader-1"); Thread reader2 = new ReadThread("Reader-2"); // Start thread reader1.start(); TimeUnit.MILLISECONDS.sleep(200); reader2.start(); // waiting for finish. reader1.join(); reader2.join(); } /** * 一读一写,互斥 */ public void demo2() throws InterruptedException { Thread reader1 = new ReadThread("Reader-1"); Thread writer1 = new WriteThread("Writer-1"); // Start thread reader1.start(); TimeUnit.MILLISECONDS.sleep(200); writer1.start(); // waiting for finish. reader1.join(); writer1.join(); } /** * 双写锁,互斥 */ public void demo3() throws InterruptedException { Thread writer1 = new WriteThread("Writer-1"); Thread writer2 = new WriteThread("Writer-2"); // Start thread writer1.start(); TimeUnit.MILLISECONDS.sleep(200); writer2.start(); // waiting for finish. writer1.join(); writer2.join(); }
运行上述程序可以看到 demo1 中的读锁两个线程读取操作基本是在同时触发,而 demo2 在读线程在运行时写线程无法取到锁,只有在读线程退出释放锁后写线程才被触发。同理 demo3 也是在写线程释放锁后第二个写线程才被触发。
根据结果也验证了之前提出的结论,读锁之间允许共存,但读锁与写锁互斥,写锁之前同样互斥。
txt
复制代码
// demo1 Reader-1 do read. Reader-2 do read. Reader-1 sleep over. Reader-2 sleep over. // demo2 Reader-1 do read. Reader-1 sleep over. Writer-1 do write. Writer-1 sleep over. // demo3 Writer-1 do write. Writer-1 sleep over. Writer-2 do write. Writer-2 sleep over.
4. StampedLock
StampedLock 同样分为读写锁,但其为乐观锁的一种,通过为锁提供版本号进行区别不同操作。
(1)悲观锁
StampedLock 中的 readLock() 与 writeLock() 即为悲观锁,具体效果与 ReentrantReadWriteLock 类似,这里不作详细介绍,具体方法参考下表。
| 方法 | 作用 |
|---|---|
| readLock() | 获取一个读锁,返回版本号用于释放锁或升级锁。 |
| isReadLocked() | 判断当前是否存在读锁。 |
| getReadLockCount() | 获取当前激活的读锁数量。 |
| unlockRead() | 根据传入的版本号释放对应的读锁。 |
| writeLock() | 获取一个写锁,返回版本号用于释放锁或升级锁。 |
| isWriteLocked() | 判断当前是否存在写锁。 |
| unlockWrite() | 根据传入的版本号释放对应的写锁。 |
(2)乐观锁
通过 tryOptimisticRead() 可返回一个版本号,注意此时并没有仍是无锁状态,通过 validate(stamp) 方法可以验证此时是否有写入发生即是否有写锁处于持有状态,可根据结果设计不同的处理逻辑
常用的接口方法与其对应的描述信息参考下表。
| 方法 | 作用 |
|---|---|
| tryOptimisticRead() | 乐观读,返回一个版本号。 |
| validate() | 判断对应版本的获取之后是否获取过写锁。 |
| tryConvertToReadLock() | 尝试将当前锁升级为读锁,返回 0 表示失败。 |
| tryConvertToWriteLock() | 尝试将当前锁升级为写锁,返回 0 表示失败。 |
| unlock() | 释放对应版本号的所有锁(读锁与写锁)。 |
如下即为由乐观锁升级为悲观锁的示例,其中 WriteThread 为获取写锁 writeLock 操作这里略去具体内容。
java
复制代码
public class RwTest { private static long stamp = 1L; private static final StampedLock stampedLock = new StampedLock(); @Test public void optimisticDemo() throws InterruptedException { // Start write thread Thread write = new WriteThread(); write.setName("Writer-1"); write.start(); TimeUnit.MILLISECONDS.sleep(100); // Optimistic read stamp = stampedLock.tryOptimisticRead(); try { // 验证是否发生写操作 if (stampedLock.validate(stamp)) { // 若是从乐观读升级为悲观读 stamp = stampedLock.tryConvertToReadLock(stamp); if (stamp != 0L) { // convert success System.out.println("Is read lock: " + stampedLock.isReadLocked()); System.out.println("Convert read success, do read."); } } } catch (Exception e) { e.printStackTrace(); } finally { stampedLock.unlock(stamp); } } }
五、分布式锁
在实际生产开发中,为了实现高可用我们通过将服务通过集群部署在不同节点上,而此时用户的单个操作可能就会被集群中的多个节点重复执行。针对这种情况,上面的两类锁显然就不太适用,因为二者都是针对单节点的服务而言,因此这时候就需要用到分布式锁。
用简单一点的大白话来讲,可以把整个集群环境当成一个主线程,而每个节点就是一个线程,分布式锁就是用于控制不同节点间的操作原子性。
1. RedissonLock
RedissonLock 是一款基于 Redis 实现的分布式锁,下面详细介绍一下其使用。
(1)Redis连接
因为是基于 Redis 实现所以需要提前创建服务连接。
java
复制代码
public void connect() { Config config = new Config(); config.useSingleServer() // Redis 服务地址 .setAddress("redis://127.0.0.1:6379") // 设置密码 .setPassword("123456") // 设置存储数据库 .setDatabase(2); // 创建连接 redissonClient = Redisson.create(config); }
(2)基本使用
RedissonLock 使用方式与 ReentrantLock 其实基本一致,不同点在于前者会将锁对象存储于 Redis 内存中,这里就不再具体举例,仅介绍一下其常用方法。
需要注意一点如果在加锁时未设置过期时间则默认为 30s 。
java
复制代码
public void infoDemo() throws InterruptedException { RLock lock = redissonClient.getLock("test"); // 加锁 lock.lock(); // 加锁,并指定超时时间 lock.lock(6000, TimeUnit.MILLISECONDS); // 异步加锁 RFuture<Void> future = lock.lockAsync(); // 异步加锁, 指定锁超时时长 future = lock.lockAsync(6000, TimeUnit.MILLISECONDS); // tryLock() 可以设置等待时间 boolean isL1 = lock.tryLock(); System.out.println("tryLock: " + isL1); // 尝试获取锁 waitTime: 等待时间; leaseTime: 锁过期时间 // 在 5 秒内未取到锁返回 false, 取到锁则设置锁过期为 6 秒 boolean isL2 = lock.tryLock(5 * 1000, 6 * 1000, TimeUnit.MILLISECONDS); System.out.println("tryLock: " + isL2); // 解锁 lock.unlock(); // 是否加锁 System.out.println("is locked: " + lock.isLocked()); // 加锁次数 System.out.println("lock count: " + lock.getHoldCount()); }
(3)看门狗机制
RedissonLock 默认锁的过期时间为 30s ,如果在任务耗时超过 30s 则会出现提前释放锁的情况,但若手动设置过期时间,有时并无法准确估计任务耗时,又可能存在持锁时间过长造成资源浪费的情况。针对这种情况, RedissonLock 引入了看门狗机制 watchDog ,看门狗程序会固定间隔持锁情况,若锁仍在持有状态将自动续期加锁时间,从而实现动态加锁时长。
默认的看门狗时间为 30s,即每隔 10s 会读取当前锁的状态,若锁仍为持有状态则自动延长加锁时间 30s 。当然你也可以在创建连接时通过 setLockWatchdogTimeout() 指定看门狗程序时间,如设置为 60s 则每隔 60/3=20s 会检查锁的状态,若锁未释放则延长 60s。
下面看一个具体示例,在 线程 1 中创建锁时并没有指定过期时间,因此默认过期时间为 30s ,但是因为看门狗机制将会每隔 10s 读取一次锁状态,这里通过 sleep() 模拟任务耗时 60s ,因此当 30s 后锁过期时间又会自动续期到 30s,因此 线程 2 将无法获取锁。只有当休眠结束后释放锁看门狗机制失效后 线程 2 才能获取锁。
java
复制代码
public void watchDogDemo() throws InterruptedException { RLock lock = redissonClient.getLock("test"); Thread thread1 = new Thread(() -> { // 不指定时间,默认 30s 过期 lock.lock(); try { // 模拟任务耗时,看门狗会自动给续期 Thread.sleep(60 * 1000); } catch (InterruptedException e) { e.printStackTrace(); } finally { // 任务结束释放锁 lock.unlock(); } }).start(); // 间隔启动第二个线程 Thread.sleep(500); Thread thread2 = new Thread(() -> { // 无法拿到锁 lock.lock(); try { System.out.println("get lock"); } finally { // 任务结束释放锁 lock.unlock(); } }).start(); }
六、线程工具
1. CountDownLatch
CountDownLatch 可以理解为计数器,通过巧妙的应用它我们即可控制线程的流程。
(1)初始化
计数器的 await() 方法会判断当前计数器值是否为 0 ,若否则会进入阻塞状态。
java
复制代码
public void demo() { // 初始化值为 1 的计数器 CountDownLatch latch = new CountDownLatch(1); // 计数器减 1 latch.countDown(); // 获取计数器大小 latch.getCount() try { // 等待计数器归零, 进入阻塞 latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("end"); }
(2)并发模拟
通过 CountDownLatch 可以快速实现并发事件的任务模拟,具体示例如下:
java
复制代码
public void concurrentDemo() throws InterruptedException { CountDownLatch latch = new CountDownLatch(3); for (int i = 0; i < 3; i++) { int finalI = i; new Thread(() -> { try { // 阻塞,等待计数器归 0 模拟并发 latch.await(); // 需进行的并发操作 System.out.println(finalI); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); // 计数器递减 latch.countDown(); TimeUnit.SECONDS.sleep(1); } }
2. CyclicBarrier
CyclicBarrier 又译为栅栏,即可以实现批量的线程控制,当一组线程到达都到达该临界状态的时候触发。
(1)初始化
通过 await() 方法实现线程阻塞的效果,当指定数量的线程进入该阻塞状态则触发 CyclicBarrier 中定义的事件,注意当该事件抛出异常时将会在 await() 处抛出 BrokenBarrierException 异常。
java
复制代码
public void demo1() { // 当指定数量的线程到达 await 状态则触发事件 CyclicBarrier cyclicBarrier = new CyclicBarrier(3, () -> { // 定义事件 System.out.println("\nAll threads have reached the barrier!\n"); }); for (int i = 0; i <= 3; i++) { new Thread(() -> { String threadName = Thread.currentThread().getName(); System.out.println(threadName + " has reached the barrier."); try { // 进入阻塞,等待其它线程到达 await 状态 cyclicBarrier.await(); } catch (Exception e) { // 若 CyclicBarrier 事件抛出异常则会抛到此处 e.printStackTrace(); } System.out.println(threadName + " has continued executing."); }, "Thread-" + i).start(); } }
(2)同步示例
了解了基本使用下面来看一个更贴合实际的案例。
通过 Random 库模拟生成了十万个随机数并实现求和的目的,为了达到更高效的目的这里将数组集合拆分为 3 个子数组并分别求和最后将 3 个任务结果相加即可。当每个子任务计算完成后通过 await() 进入阻塞,等待其它子任务完成计算,而当 3 个子任务都计算完成进入阻塞则触发 CyclicBarrier 的最后累加,将三个任务的结果相加得到最终结果。
java
复制代码
public void demo2() throws InterruptedException { List<Integer> list = new ArrayList<>(); for (int i = 1; i < 100000; i++) { list.add(new Random().nextInt(100)); } // 将数组拆分为 3 个子任务 List<List<Integer>> subLists = new ArrayList<>(); subLists.add(list.subList(0, 30000)); subLists.add(list.subList(30000, 70000)); subLists.add(list.subList(70000, 99999)); // 设置栅栏触发事件 List<Integer> result = new ArrayList<>(); CyclicBarrier cyclicBarrier = new CyclicBarrier(3, () -> { AtomicInteger total = new AtomicInteger(0); result.forEach(it -> { total.getAndUpdate(i -> i + it); }); System.out.println("\nAll task finish, result is : " + total); }); // 提交计算子任务 for (int i = 0; i < 3; i++) { int batch = i; new Thread(() -> { AtomicInteger sum = new AtomicInteger(0); subLists.get(batch).forEach(sum::getAndAdd); result.add(sum.get()); try { String threadName = Thread.currentThread().getName(); System.out.println(threadName + " calculate finish, wait other task done."); cyclicBarrier.await(); } catch (Exception e) { e.printStackTrace(); } }, "Thread-" + i).start(); } TimeUnit.SECONDS.sleep(5); }
3. Semaphore
Semaphore 能够实现限制线程访问数量的效果,可以粗暴的理解为一个阻塞的线程队列,只有指定数量的线程能同时访问资源,到达阈值后将陷入阻塞。
Semaphore 作用类似于普通的线程锁都是用于限制并发访问,不同是 Semaphore 允许被多线程同时持有。
(1)初始化
Semaphore 同样提供 acquire() 与 tryAcquire() 两种方式访问资源。
java
复制代码
public void demo1() throws InterruptedException { // 初始化并指定并发大小 Semaphore semaphore = new Semaphore(3); // 请求访问,并发数满则阻塞 semaphore.acquire(); // 请求访问,失败不会阻塞 boolean b1 = semaphore.tryAcquire(); boolean b2 = semaphore.tryAcquire(3, TimeUnit.SECONDS); try { System.out.println(UUID.randomUUID()); } finally { // 释放资源 semaphore.release(); } }
(2)同步示例
我们知道常见的 IO 是阻塞的,因此在文件下载等业务场景下想实现多任务下载就必须通过多线程方式,但若没有合理限制并发数将导致系统资源被大量占用。这种情况可以通过创建一个指定大小的 IO 专用线程池资源来实现,但往往一个系统中还有其它服务需要使用线程如果为每个模块创建单独的线程池显然是不合适且耗费资源的。
Semaphore 则完美解决这个问题,通过其即可限制同一资源的线程并发数,下面看个例子让我们更好的理解:
java
复制代码
/** * 初始化大小为 3,即只能同时 3 个任务并发 */ private static final Semaphore semaphore = new Semaphore(3); public void demo2() throws InterruptedException { for (int i = 0; i < 5; i++) { new MyThread().start(); } // 等待主线程中子任务结束 TimeUnit.SECONDS.sleep(25); } static class MyThread extends Thread { @Override public void run() { try { // 达到指定数量访问将阻塞 semaphore.acquire(); try { System.out.println(UUID.randomUUID()); // 模拟耗时 TimeUnit.SECONDS.sleep(3); } finally { // 一定要释放! semaphore.release(); } } catch (InterruptedException e) { e.printStackTrace(); } } }
七、线程死锁
1. 死锁介绍
线程死锁顾名思义即两个线程相互等待对方释放锁对象导致两个线程都进入无限的循环等待中,在多线程任务中如果没有设计好恰当的锁的获取与释放,就十分容易出现死锁问题。
举个简单例子,user-1 向 user-2 进行转账,为了保证数据的一致性即不出现一方扣款一方却未收到的情况,在转账操作中需要同时对两个对象进行加锁操作,即对 user-1 加锁后再对 user-2 加锁,然后执行具体的转账业务操作。
将上述的文字逻辑转化为对应的代码后如下:
java
复制代码
public void transfer(User fromUser, User toUser, double amount) { synchronized(toUser) { synchronized(fromUser) { // 扣除来源用户余额 fromUser.debit(amount); // 增加目标用户余额 toUser.credit(amount) } } }
在上述的示例中,当同时存在 user-1 向 user-2 转账与 user-2 向 user-1 转账两个线程时,由于正好作用顺序相反,两个线程在上述代码中的第一个 synchronized 都加锁成功,此时 user-1 与 user-2 都将进入被锁状态。而到了第二个 synchronized 时,线程一持有 user-2 的锁并等待线程二释放 user-1 的锁,线程二持有 user-1 的锁等待线程一释放 user-2 的锁,二者都在等待对方解锁从而导致死锁状态。
2. 解决方案
想要规避死锁问题有两个常用的方式,第一种就是确定锁的执行顺序,第二种则是通过 ReentrantLock 的 tryLock() 等非阻塞加锁方式。
第二种方式较为简单,通过 tryLock() 方法实现超时退出从而规避死锁问题,当然弊端就是会导致其中一个任务执行失败。
下面着重对方式一的实现思路解析。
方式一的核心在于确定流程的加锁顺序,对于同一组操作要保证加锁顺序的一致性。如之前 user-1 向 user-2 与 user-2 向 user-1 转账的示例中,因保证其无论如何触发都保证先对对 user-1 加锁再对 user-2 加锁,或者顺序倒置,但重点的是要保证应用每次调用都使用这个顺序。
稍微修改上述的示例,通过计算对象的哈希值进行比对从而保证加锁顺序的一致,通过引入第三个加锁对象用于防止两个对象 hashCode() 一致的情况,相应的代码示例如下:
java
复制代码
public final Object obj = new Object(); public void transfer(User fromUser, User toUser, double amount) { int fromId = fromUser.hashCode(); int toId = toUser.hashCode(); if(fromId < toId) { synchronized(toUser) { synchronized(fromUser) { fromUser.debit(amount); toUser.credit(amount) } } } else if (fromId > toId) { synchronized(fromUser) { synchronized(toUser) { fromUser.debit(amount); toUser.credit(amount) } } } else { synchronized(obj) { synchronized(fromUser) { synchronized(toUser) { fromUser.debit(amount); toUser.credit(amount) } } } } }