20 世纪 90 年代末,当时南佛罗里达大学的研究生 Niesh V Chawla(SMOTE 背后的主要大脑)正在研究二元分类问题。他正在处理乳房 X 光检查图像,他的任务是构建一个分类器,该分类器将像素作为输入,并将其分类为正常像素或癌变像素。当他达到 97% 的分类准确率时,他非常高兴。当他看到 97.6% 的像素都是正常的时,他的快乐是短暂的。
您可能会想,问题出在哪里?有两个问题
-
假设在 100 个像素的样本中,98 个像素是正常的,2 个是癌变的,如果我们编写一个程序,它可以预测任何情况都是正常的。分类准确率是多少?高达98%。程序学会了吗?一点也不。
-
还有一个问题。分类器努力在训练数据中获得良好的性能,并且随着正常观察的增多,它们将更多地专注于学习“正常”类的模式。这就像任何学生知道 98% 的问题来自代数而 2% 来自三角学时会做的那样。他们会安全地忽略三角函数
那么,为什么会出现这个问题,是因为班级的频率或数量之间存在很大的差异。我们称这样的数据集为表现类别不平衡的数据集。正常类称为多数类,稀有类称为少数类。

白色海鸥作为少数群体
这在现实生活中的应用中存在吗?以垃圾邮件检测、假新闻检测、欺诈检测、可疑活动检测、入侵检测等为例,类别不平衡问题就表现出来了。
带来一些平衡的解决方案:
基本方法称为重采样技术。有两种基本方法。
欠采样:-

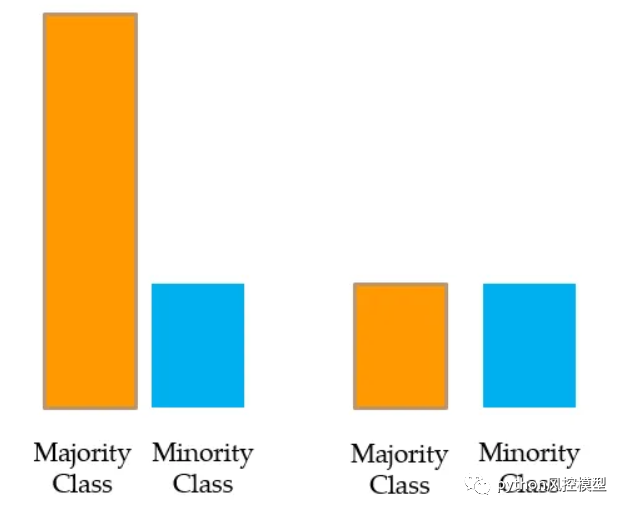
对多数类进行欠采样或下采样
我们从多数类中随机抽取样本,并使其等于少数类的数量。这称为多数类的欠采样或下采样。
问题:忽略或放弃如此多的原始数据并不是一个好主意。
过采样:-
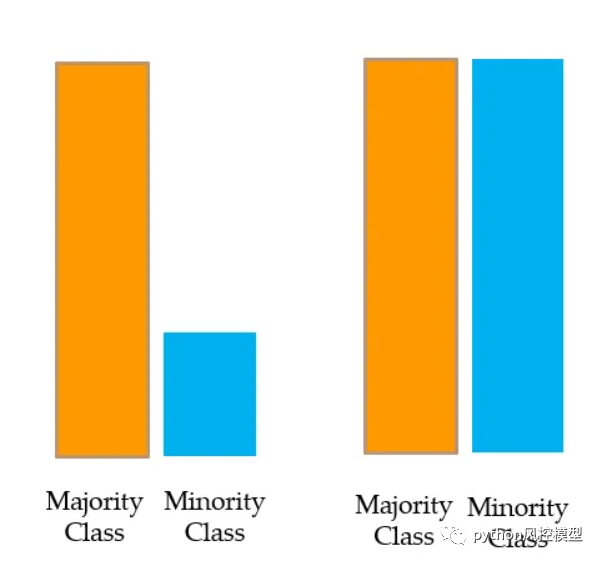
对少数类进行过采样或上采样
在这里,对少数类应用放回抽样,以创建与多数类中一样多的观测值,并且两个类是平衡的。这称为少数类的过采样或上采样。
问题:重复相同的少数类数据会导致过度拟合。
SMOTE:
SMOTE的完整形式,即综合少数群体采样技术。这里综合观察是从少数类生成的。
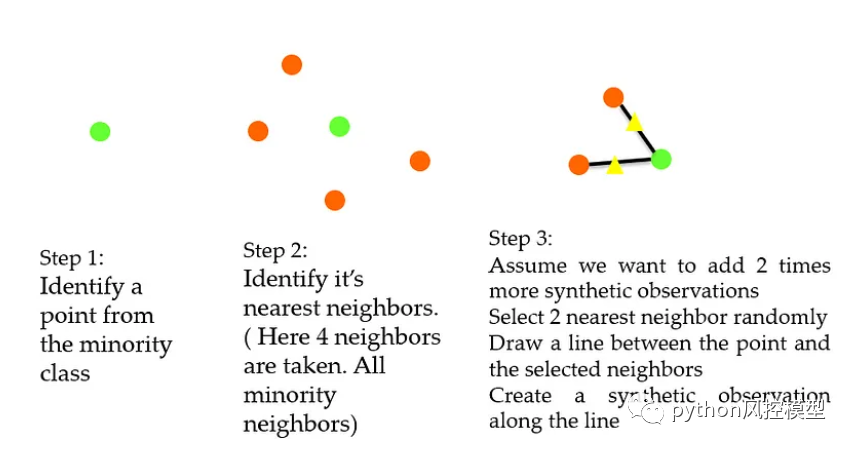
SMOTE,综合少数观察生成过程
假设有来自少数类的两个观察值 (x1,y1) 和 (x2,y2)。第一步,创建一个 0 到 1 之间的随机数,我们称之为 r。合成点将为 (x1 + r*(x2 -x1), y1 + r*(y2 -y1))。下面的例子进一步说明了这一点。
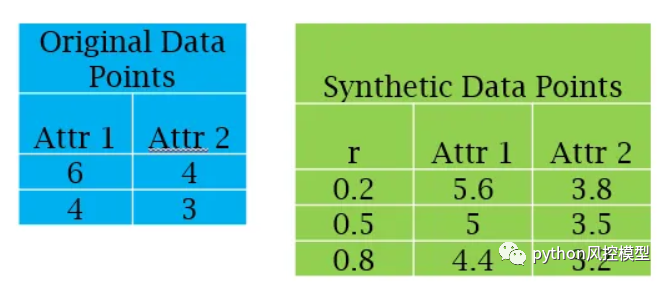
综合点由少数类生成(图片来源:作者)
SMOTE 的一个问题:
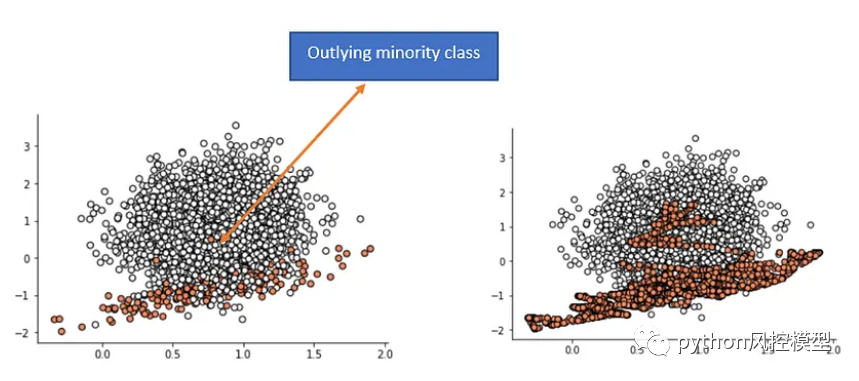
左侧:原始数据右侧:应用SMOTE后的数据
如果少数类中的样本是较远的并出现在多数类中,合成新数据会造成类别错误,这是SMOTE算法缺陷。
Borderline SMOTE:
Borderline SMOTE是SMOTE算法改良版本,并这解决了上述问题。
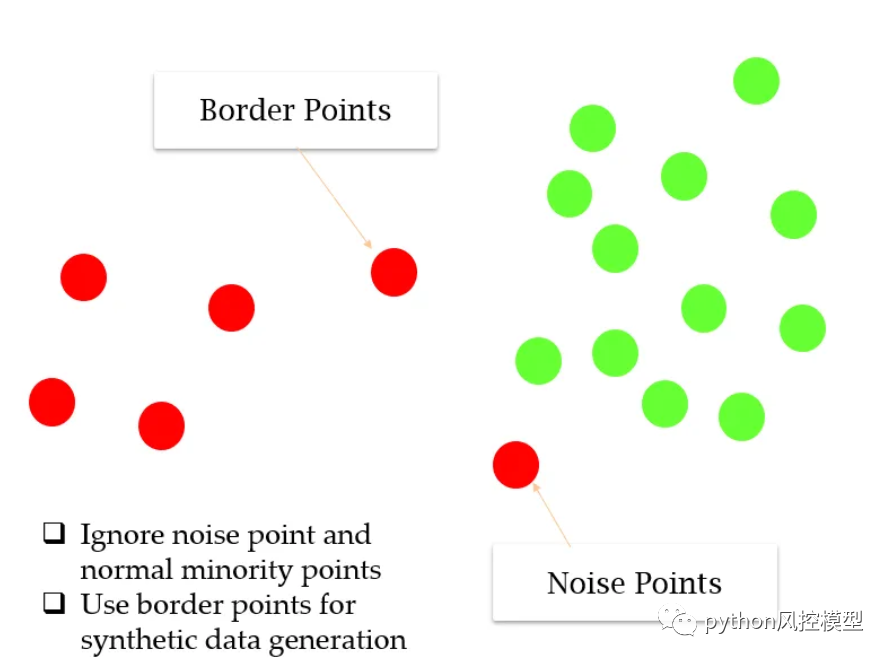
边界线 SMOTE :(图片来源作者)
该算法首先对少数类观测值进行分类。如果所有邻居都是多数类,并且在创建合成数据时忽略这些样本数据(类似于 DBSCAN),它将任何少数观察结果分类为噪声点。此外,它将一些点分类为边界点,这些点同时具有多数类和少数类作为邻域,并从这些点完全重新采样(支持向量通常会关注的极端观察)。
ADASYN:
ADASYN 是一个更通用的框架,对于每个少数观测值,它首先通过采用邻域中多数观测值与 k 的比率来找到邻域的杂质。
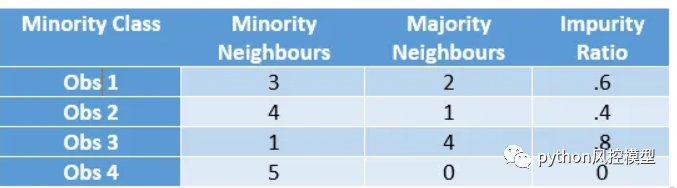
ADASYN 杂质比
现在,首先,通过将总和设为 1,将该杂质比率转换为概率分布。然后,比率越高,为该特定点生成的合成点就越多。因此,为 Obs 3 创建的综合观测数量将是 Obs 2 的两倍。所以它不像Borderline SMOTE那么极端,并且噪声点、边界点和常规少数点之间的边界要柔和得多。(不是硬性边界)。因此得名适应性。
结尾:
类别不平衡是机器学习一个非常实际的问题,特别实在金融风控领域,欺诈客户占比一般低于2%。基于重采样的方法效果不佳,这促使大家开发 SMOTE,并通过borderline SMOTE、ADASYN 等逐渐优化新采样算法。
欢迎学习更多csdn学院风控建模相关知识《python金融风控评分卡模型和数据分析微专业课》,微信二维码扫一扫收藏课程。

版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。