系列文章目录
(一)使用pytorch搭建模型并训练
(二)将pth格式转为onnx格式
(三)onxx格式转为engine序列化文件并进行推理
前言
上一节我们已经成功搭从pth文件转为onnx格式的文件,并对导出的onnx文件进行了验证,结果并无问题。这一节我们就从这个onnx文件入手,一步一步生成engine文件并使用tensorrt进行推理。
一、TensorRT是什么?
NVIDIA TensorRT™ 是用于高性能深度学习推理的 SDK。此 SDK 包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。通俗来说,TensorRT是NVIDIA针对自家GPU开发出来的一个推理框架,它使用了一些算法和操作来优化网络推理性能,提高深度学习模型在GPU上的推理速度。
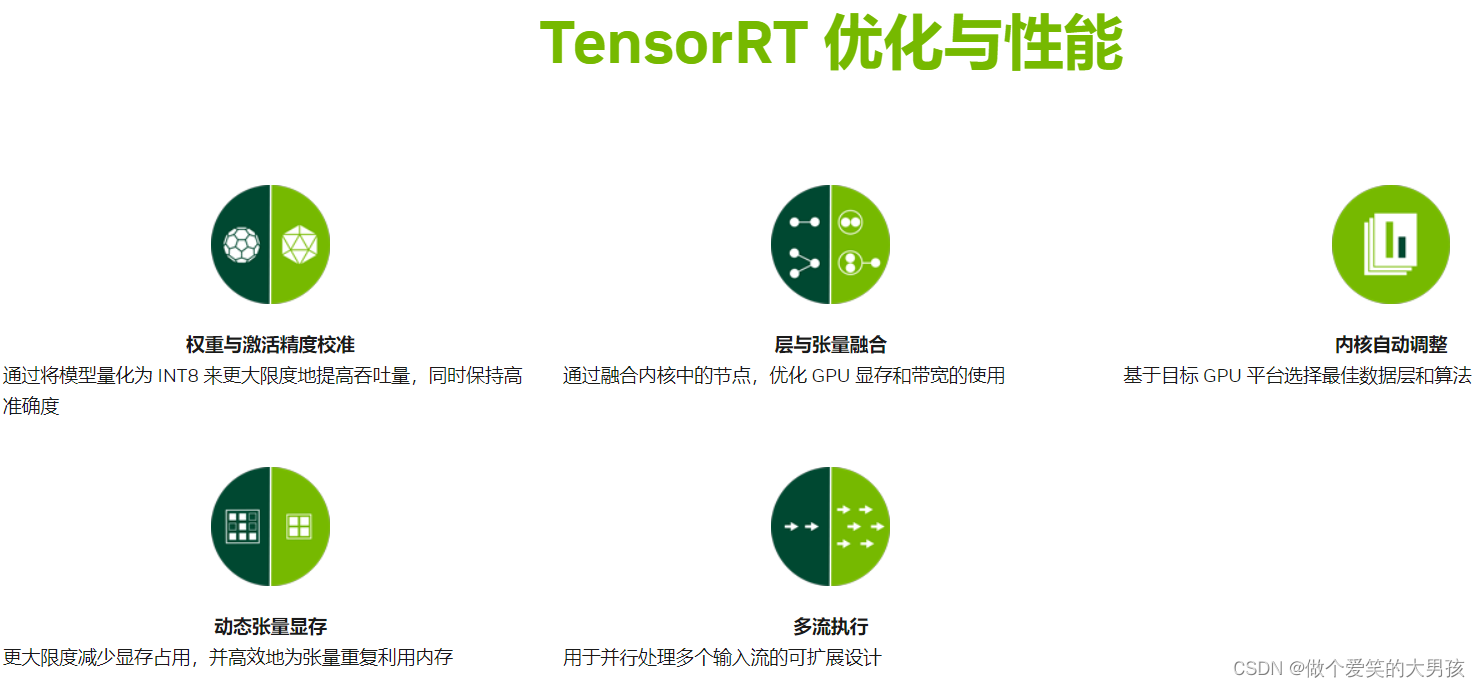
我们使用TensorRT这个框架可以加快我们手写数字分类模型的推理速度。
TensorRT的安装方式我之前也写过一期博客:参考这里。
这里我们假设已经安装好了TensorRT,我这里安装的版本是TensorRT-8.0.1.6。在生成engine文件之前,先介绍一个很有用的工具trtexec。trtexec是一个命令行工具,它可以帮助我们不用写代码就可以生成engine,以及很多其他有用的功能,感兴趣的读者可以自己探索,这里我们只使用几种常见的命令行参数。
有关trtexec的详细参数可以参考这篇博客。
二、如何通过onnx生成engine
整理一下,我们现在已经有了onnx文件,并且安装好了tensorrt,现在我们的目的是通过生成engine文件。onnx文件之前我们我们已经介绍过了它是一个什么东西,那engine文件又是什么呢?
TensorRT中的engine文件是一个二进制文件,它包含了一个经过优化的深度学习模型。这个文件可以被用来进行推理,而不需要重新加载和优化模型。在使用TensorRT进行推理时,首先需要将训练好的模型转换为TensorRT engine文件,然后使用这个文件进行推理。
也就是说,我们只需先生成一次engine,这个engine文件包含了优化后的模型(这个优化是TensoRT自己做的)。在以后进行推理的时候,我们只需要加载这个engine即可,而不需要重头开始。
使用trtexec生成engine
TensorRT-8.0.1.6/bin/trtexec --onnx=model.onnx --saveEngine=model.engine --buildOnly
在命令行输入这行指令即可帮助我们生成model.engine。trtexec命令还有许多其他的参数,感兴趣自行了解,这里我们只使用了–onnx,表示输入的是onnx文件,–saveEngine表示存储engine文件,–buildOnly表示只构建,不进行推理。
使用python接口
代码如下(示例):
import os
import tensorrt as trt
onnx_file = '/home/wjq/wjqHD/pytorch_mnist/model.onnx'
nHeight, nWidth = 28, 28
trtFile = '/home/wjq/wjqHD/pytorch_mnist/model.engine'
# Parse network, rebuild network, and build engine, then save engine
logger = trt.Logger(trt.Logger.VERBOSE)
builder = trt.Builder(logger)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
profile = builder.create_optimization_profile()
config = builder.create_builder_config()
parser = trt.OnnxParser(network, logger)
if not os.path.exists(onnx_file):
print('ONNX file {} not found.'.format(onnx_file))
exit()
print("Loading ONNX file from path {}...".format(onnx_file))
with open(onnx_file, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
exit()
print("Succeed to parse the ONNX file.")
input_tensor = network.get_input(0)
# 这是输入大小
profile.set_shape(input_tensor.name, [1, 1, nHeight, nWidth], [1, 1, nHeight, nWidth], [1, 1, nHeight, nWidth])
config.add_optimization_profile(profile)
engineString = builder.build_serialized_network(network, config) # 序列化engine文件
if engineString == None:
print("Failed building engine!")
exit()
print("Succeeded building engine!")
with open(trtFile, "wb") as f:
f.write(engineString)
使用上述的python代码,最终我们也可以生成一个engine文件。这段代码里面的api,大家可以具体去google寻找解释,我在这里只是展示了一种可能。如有问题,欢迎评论区沟通。
我们也可以使用trtexec工具来验证我们生成的engine是否正确,命令行指令为:
TensorRT-8.0.1.6/bin/trtexec --loadEngine=model.engine --exportProfile=layerProfile.json --batch=1 --warmUp=1000 --verbose
–loadEngine为加载的engine文件路径,–exportProfile这个参数可以输出网络中每一层运行的平均时间以及占总时间的百分数,–verbose为打印日志,–warmUp为提前显卡预热。
三、进行推理
我们已经得到了model.engine文件,最后一步我们要使用tensorrt的接口读取engine文件和图像文件进行推理得到最终的分类结果。
由于我的环境现在无法安装pycuda和cuda的python包,所以最后推理的这一步等环境妥当,再补上。
总结
本节我们介绍了如将使用trtexec工具和python代码通过onnx生成engine文件,并使用tensorrt的api接口调用engine文件进行推理。TensorRT推理手写数字分类总共三节,笼统地介绍了部署一个深度学习模型的流程,希望大家能有所收获。接下来如果有时间准备更新另一个工作:pytorch遇到不支持的算子,tensorrt遇到不支持的算子,onnx遇到不支持的算子该怎么办。