《Go 语言第一课》课程学习笔记(八)
编程语言
2023-08-25 18:14:41
阅读次数: 0
Go 语言的类型大体可分为基本数据类型、复合数据类型和接口类型这三种。
其中,我们日常 Go 编码中使用最多的就是基本数据类型,而基本数据类型中使用占比最大的又是数值类型。
Go 语言的整型,主要用来表示现实世界中整型数量等。它可以分为平台无关整型和平台相关整型这两种,它们的区别主要就在,这些整数类型在不同 CPU 架构或操作系统下面,它们的长度是否是一致的。
平台无关整型
它们在任何 CPU 架构或任何操作系统下面,长度都是固定不变的。
有符号整型(int8-int64)和无符号整型(uint8-uint64)的本质差别在于最高二进制位(bit 位)是否被解释为符号位,这点会影响到无符号整型与有符号整型的取值范围。
Go 采用 2 的补码(Two’s Complement)作为整型的比特位编码方法。因此,我们不能简单地将最高比特位看成负号,把其余比特位表示的值看成负号后面的数值。Go 的补码是通过原码逐位取反后再加 1 得到的。
平台相关整型
与平台无关整型对应的就是平台相关整型,它们的长度会根据运行平台的改变而改变。
Go 语言原生提供了三个平台相关整型,它们是 int、uint 与 uintptr。
由于这三个类型的长度是平台相关的,所以我们在编写有移植性要求的代码时,千万不要强依赖这些类型的长度。
如果不知道这三个类型在目标运行平台上的长度,可以通过 unsafe 包提供的 SizeOf 函数来获取。
整型的溢出问题
如果这个整型因为参与某个运算,导致结果超出了这个整型的值边界,我们就说发生了整型溢出的问题。
由于整型无法表示它溢出后的那个“结果”,所以出现溢出情况后,对应的整型变量的值依然会落到它的取值范围内,只是结果值与我们的预期不符,导致程序逻辑出错。
字面值与格式化输出
Go 语言在设计开始,就继承了 C 语言关于数值字面值(Number Literal)的语法形式。
早期 Go 版本支持十进制、八进制、十六进制的数值字面值形式。
Go 1.13 版本中,Go 又增加了对二进制字面值的支持和两种八进制字面值的形式。
为提升字面值的可读性,Go 1.13 版本还支持在字面值中增加数字分隔符“_”,分隔符可以用来将数字分组以提高可读性。
反过来,我们也可以通过标准库 fmt 包的格式化输出函数,将一个整型变量输出为不同进制的形式。
浮点型的二进制表示
Go 语言提供了 float32 与 float64 两种浮点类型 ,它们分别对应单精度与双精度浮点数值类型。
不过,Go 语言中没有提供 float 类型 。
换句话说,Go 提供的浮点类型都是平台无关的。
无论是 float32 还是 float64,它们的变量的默认值都为 0.0,不同的是它们占用的内存空间大小是不一样的,可以表示的浮点数的范围与精度也不同。
浮点数在内存中的二进制表示(Bit Representation)要比整型复杂得多:
浮点数在内存中的二进制表示分三个部分:符号位、阶码(即经过换算的指数),以及尾数。这样表示的一个浮点数,它的值等于: ( − 1 ) s ∗ 1. M ∗ 2 E − o f f s e t (-1)^s * 1.M * 2 ^{E-offset} ( − 1 ) s ∗ 1. M ∗ 2 E − o ff se t
当符号位为 1 时,浮点值为负值;
当符号位为 0 时,浮点值为正值。
公式中 offset 被称为阶码偏移值。
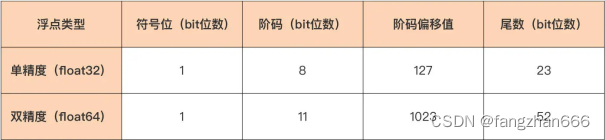
单精度(float32)与双精度(float64)浮点数在阶码和尾数上的不同:
单精度浮点类型(float32)为符号位分配了 1 个 bit,为阶码分配了 8 个 bit,剩下的 23 个 bit 分给了尾数。
而双精度浮点类型,除了符号位的长度与单精度一样之外,其余两个部分的长度都要远大于单精度浮点型,阶码可用的 bit 位数量为 11,尾数则更是拥有了 52 个 bit 位。
字面值与格式化输出
Go 提供两种复数类型,它们分别是 complex64 和 complex128,complex64 的实部与虚部都是 float32 类型,而 complex128 的实部与虚部都是 float64 类型。如果一个复数没有显示赋予类型,那么它的默认类型为 complex128。
关于复数字面值的表示,我们其实有三种方法:
在 Go 中,字符串类型为 string。
Go 语言通过 string 类型统一了对“字符串”的抽象。
这样无论是字符串常量、字符串变量或是代码中出现的字符串字面值,它们的类型都被统一设置为 string。
string 类型的数据是不可变的,提高了字符串的并发安全性和存储利用率。
Go 字符串的组成
Go 语言中的字符串值也是一个可空的字节序列,字节序列中的字节个数称为该字符串的长度。一个个的字节只是孤立数据,不表意。
字符串是由一个可空的字符序列构成。
rune 类型与字符字面值
Go 使用 rune 这个类型来表示一个 Unicode 码点。rune 本质上是 int32 类型的别名类型,它与 int32 类型是完全等价的。 一个 rune 实例就是一个 Unicode 字符,一个 Go 字符串也可以被视为 rune 实例的集合。我们可以通过字符字面值来初始化一个 rune 变量。
在 Go 中,字符字面值有多种表示法,最常见的是通过单引号括起的字符字面值。
我们还可以使用 Unicode 专用的转义字符\u 或\U 作为前缀,来表示一个 Unicode 字符。
由于表示码点的 rune 本质上就是一个整型数,所以我们还可用整型值来直接作为字符字面值给 rune 变量赋值。
字符串字面值
字符串是字符的集合,我们需要把表示单个字符的单引号,换为表示多个字符组成的字符串的双引号。
string 类型其实是一个“描述符”,它本身并不真正存储字符串数据,而仅是由一个指向底层存储的指针和字符串的长度字段组成的。 我们直接将 string 类型通过函数 / 方法参数传入也不会带来太多的开销。因为传入的仅仅是一个“描述符”,而不是真正的字符串数据。
Go 字符串类型的常见操作
下标
字符迭代
Go 有两种迭代形式:常规 for 迭代与 for range 迭代。
通过这两种形式的迭代对字符串进行操作得到的结果是不同的。
通过常规 for 迭代对字符串进行的操作是一种字节视角的迭代,每轮迭代得到的的结果都是组成字符串内容的一个字节,以及该字节所在的下标值,这也等价于对字符串底层数组的迭代。
通过 for range 迭代,我们每轮迭代得到的是字符串中 Unicode 字符的码点值,以及该字符在字符串中的偏移值。
我们可以通过这样的迭代,获取字符串中的字符个数,而通过 Go 提供的内置函数 len,我们只能获取字符串内容的长度(字节个数)。
获取字符串中字符个数更专业的方法,是调用标准库 UTF-8 包中的 RuneCountInString 函数。
字符串连接
Go 原生支持通过 +/+= 操作符进行字符串连接。
虽然通过 +/+= 进行字符串连接的开发体验是最好的,但连接性能就未必是最快的了。
除了这个方法外,Go 还提供了 strings.Builder、strings.Join、fmt.Sprintf 等函数来进行字符串连接操作 。
字符串比较
Go 字符串类型支持各种比较关系操作符,包括 = =、!= 、>=、<=、> 和 <。
在字符串的比较上,Go 采用字典序的比较策略,分别从每个字符串的起始处,开始逐个字节地对两个字符串类型变量进行比较。
当两个字符串之间出现了第一个不相同的元素,比较就结束了,这两个元素的比较结果就会做为串最终的比较结果。
如果出现两个字符串长度不同的情况,长度比较小的字符串会用空元素补齐,空元素比其他非空元素都小。
鉴于 Go string 类型是不可变的,所以说如果两个字符串的长度不相同,那么我们不需要比较具体字符串数据,也可以断定两个字符串是不同的。但是如果两个字符串长度相同,就要进一步判断,数据指针是否指向同一块底层存储数据。如果还相同,那么我们可以说两个字符串是等价的,如果不同,那就还需要进一步去比对实际的数据内容。
字符串转换
Go 支持字符串与字节切片、字符串与 rune 切片的双向转换,并且这种转换无需调用任何函数,只需使用显式类型转换就可以了。
转载自 blog.csdn.net/fangzhan666/article/details/132343891