稀疏正则化:从理论到实践的简要解析
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:稀疏正则化。
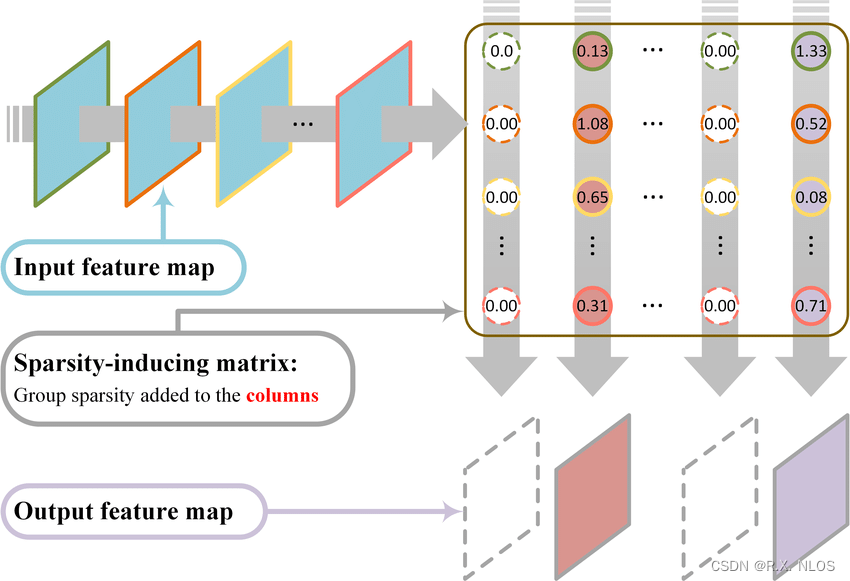
Group-sparsity regularization enforcement: (a) the columns of the… | Download Scientific Diagram
背景介绍
在机器学习和深度学习中,我们经常需要处理大量的数据。然而,数据的获取和处理往往需要大量的计算资源和时间。为了解决这个问题,我们引入了稀疏性的概念。稀疏性是指大部分输入数据为零或非常小,只有少数数据点的值较大。稀疏性在许多实际问题中都存在,例如在图像处理、文本挖掘等领域。
原理介绍和推导
稀疏正则化是一种优化技术,它通过在损失函数中添加一个正则项来鼓励模型的稀疏性。这个正则项通常与模型的权重有关,其目标是最小化模型的权重值,使得模型更加稀疏。
假设我们的模型是一个线性回归模型,其预测值为 y = w x + b y=wx+b y=wx+b,其中 w w w是权重, b b b是偏置。我们希望最小化的损失函数为:
L ( w , b ) = 1 2 m ∑ i = 1 m ( y i − ( w x + b ) ) 2 + λ ∑ j = 1 p ∣ w j ∣ L(w,b) = \frac{1}{2m}\sum_{i=1}^{m}(y_i-(wx+b))^2 + \lambda\sum_{j=1}^{p}|w_j| L(w,b)=2m1i=1∑m(yi−(wx+b))2+λj=1∑p∣wj∣
其中, m m m是样本数量, p p p是特征数量。第一部分是普通的平方误差损失,第二部分是正则项,它鼓励权重的绝对值之和小于一个常数 λ \lambda λ。
我们可以通过梯度下降法来求解这个优化问题。在每一步迭代中,我们首先计算损失函数关于权重的梯度,然后根据梯度更新权重。具体的更新公式为:
w i + 1 = w i − η ∂ L ∂ w i w_{i+1} = w_i - \eta\frac{\partial L}{\partial w_i} wi+1=wi−η∂wi∂L
b i + 1 = b i − η ∂ L ∂ b i b_{i+1} = b_i - \eta\frac{\partial L}{\partial b_i} bi+1=bi−η∂bi∂L
其中, η \eta η是学习率,决定了参数更新的速度。
研究现状
稀疏正则化已经在许多领域得到了广泛的应用。例如,
- 在图像处理中,
- 稀疏正则化可以有效地减少模型的复杂度
- 提高模型的泛化能力
- 在自然语言处理中,
- 稀疏正则化可以用于词嵌入的学习,提高模型的表达能力。
- 此外,稀疏正则化还在推荐系统、生物信息学等领域发挥了重要的作用。
然而,稀疏正则化也存在一些挑战。例如,如何选择合适的正则化参数 λ \lambda λ,如何设计有效的稀疏约束等。这些问题需要我们在实际应用中进行深入的研究。
挑战
尽管稀疏正则化已经取得了一些成果,但是仍然存在一些挑战。
- 首先,如何选择合适的正则化参数 λ \lambda λ 仍然是一个开放的问题。
- 不同的参数会导致模型的性能有很大的差异。
- 其次,如何设计有效的稀疏约束 也是一个挑战。
- 我们需要找到一种方法,既能保证模型的稀疏性,又能保持模型的有效性。
- 最后,如何处理大规模稀疏数据 也是一个重要的问题。
- 我们需要找到一种高效的方法,既能处理大规模的稀疏数据,又能保持模型的精度。
未来展望
尽管存在一些挑战,但是稀疏正则化的未来仍然充满了希望。随着深度学习的发展,我们有理由相信,稀疏正则化将在未来的机器学习和深度学习中发挥更大的作用。我们期待更多的研究者能够参与到稀疏正则化的研究中来,共同推动这个领域的发展。
代码示例
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的线性回归模型
model = nn.Linear(10, 1)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(100):
# 假设我们有一些输入数据x和目标数据y
x = torch.randn(100, 10)
y = torch.randn(100, 1)
# 前向传播
output = model(x)
loss = criterion(output, y)
# 反向传播和参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
以上就是关于稀疏正则化的全部内容。希望通过这篇文章,你能对稀疏正则有更深入的理解。