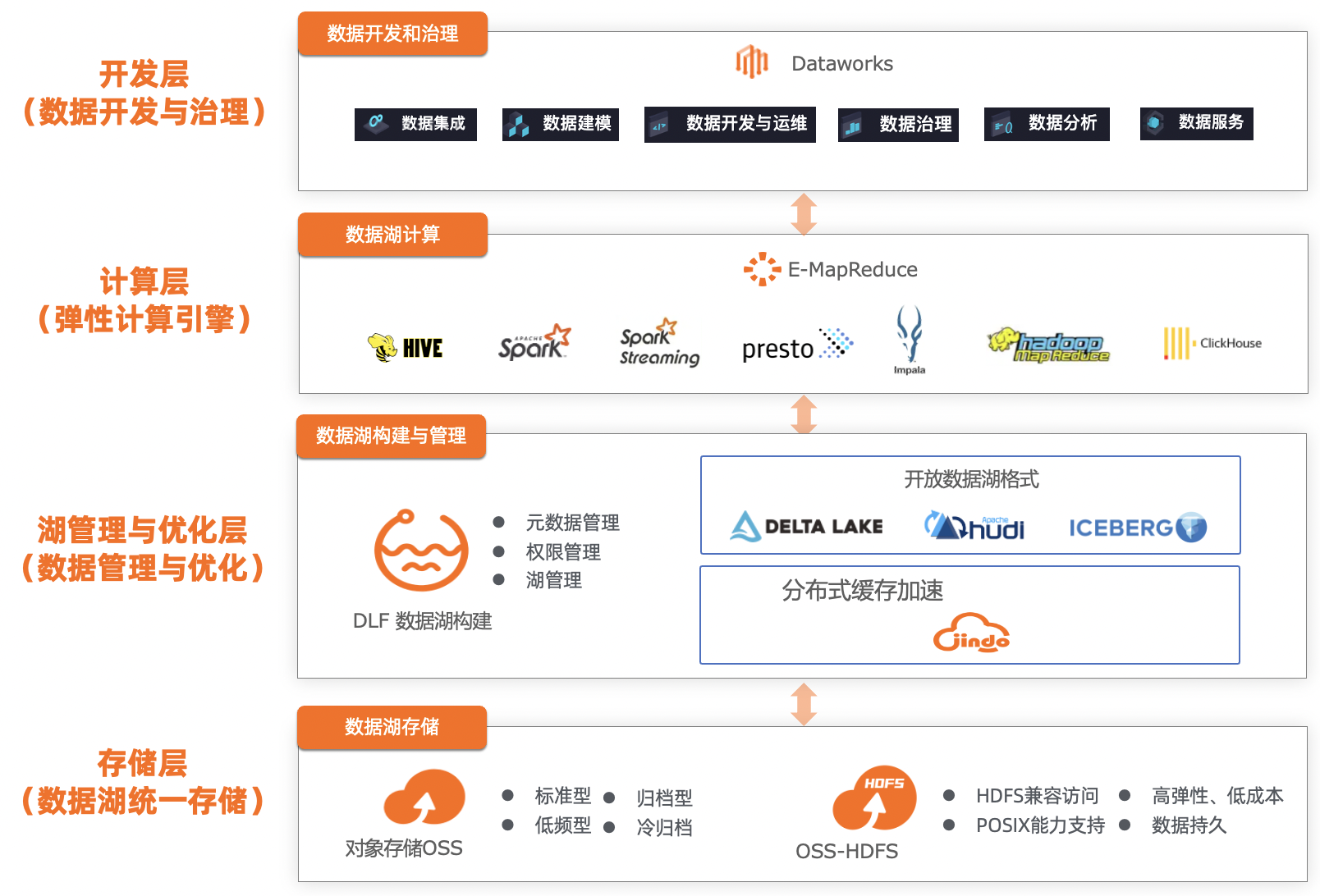
简介: 阿里云全链路数据湖开发治理解决方案能力持续升级,发布2.0版本。解决方案包含开源大数据平台E-MapReduce(EMR) , 一站式大数据数据开发治理平台DataWorks ,数据湖构建DLF,对象存储OSS等核心产品。支持EMR新版数据湖DataLake集群(on ECS)、自定义集群(on ECS)、Spark集群(on ACK)三种形态,对接阿里云一站式大数据开发治理平台DataWorks,沉淀阿里巴巴十多年大数据建设方法论,为客户完成从入湖、建模、开发、调度、治理、安全等全链路数据湖开发治理能力,帮助客户提升数据的应用效率。
阿里云全链路数据湖开发治理解决方案能力持续升级,发布2.0版本。解决方案包含开源大数据平台E-MapReduce(EMR) , 一站式大数据数据开发治理平台DataWorks ,数据湖构建DLF,对象存储OSS等核心产品。
解决方案已支持EMR新版数据湖DataLake集群(on ECS)、自定义集群(on ECS)、Spark集群(on ACK)三种形态,对接阿里云一站式大数据开发治理平台DataWorks,沉淀阿里巴巴十多年大数据建设方法论,为客户完成从入湖、建模、开发、调度、治理、安全等全链路数据湖开发治理能力,帮助客户提升数据的应用效率。
重点能力升级
增强数据入湖能力
DataWorks 数据集成支持 MySQL 整库实时入湖 OSS(HUDI)、Kafka 实时入湖 OSS(HUDI)、MySQL 到 Hive 整库周期同步能力。
在 DataWorks 管控台选择进入数据集成
在页面直接点击“创建我的数据同步”

选择来源和去向类型就可以看到对应入湖能力
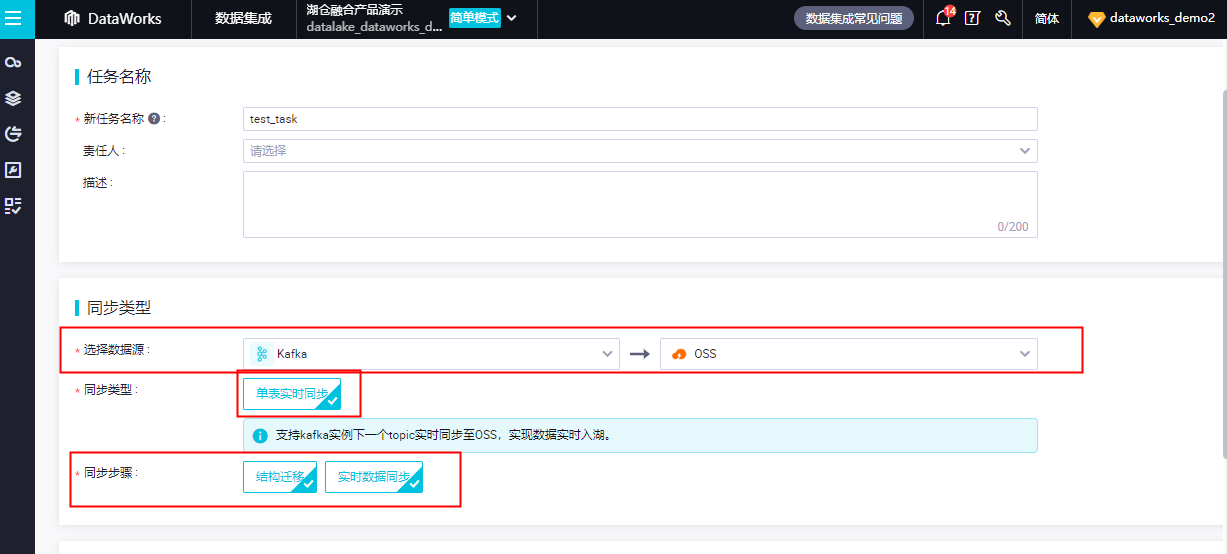
MySQL 整库实时入湖 OSS(Hudi)
支持元数据自动注册到阿里云DLF,方便用户进行湖管理;
支持 MySQL 实例级别的同步,即源端 MySQL 可以同时选择多个库;
支持按照正则表达式选定来源 MySQL 库和表;
支持自动加库加表,即 MySQL 侧增加库或表后,可以自动同步至 OSS,无需手工干预和操作。 
Kafka 实时入湖 OSS(Hudi)
支持 Kafka json 数据增量实时入湖,秒级延迟
支持在同步链路中对数据处理,包括数据过滤、脱敏、字符串替换、字段级别赋值等操作
支持根据 kafka json 数据 schema 变化,动态增加字段
支持对接阿里云DLF,入湖元数据自动注册,实时可查可管理
支持自定义 OSS 湖端存储路径
MySQL 整库离线同步至 Hive
MySQL 整实例级别离线同步至 Hive,支持配置周期调度,也可以在 DataStudio 中依赖此同步调度节点为上游,支持历史全量同步和离线增量同步

增强作业开发调度能力
支持 spark on ACK 集群调度
DataWorks 支持调度 spark-submit, spark-sql 类型作业到 EMR Spark 集群(on ACK), 用户可以利用 ACK 的弹性能力按需调整集群资源,实现和应用程序混部,使用同一套运维方案的同时,最大程度利用资源。对于原先在新版数据湖 DataLake 集群和自定义集群中运行的 Spark 任务,支持一键迁移到 ACK 集群,无需修改代码。
开发能力升级
支持空间内各模块设置 yarn 队列
随着越来越多的客户开始使用数据湖处理数据、分析数据,计算资源优先保障重要ETL任务产出成为了普遍诉求。DataWorks 支持为不同模块设置任务的 yarn 队列,包括数据分析、数据开发、运维等,保障不同场景的计算资源隔离需求。
支持工作空间级别 Spark Conf 设置
很多用户发现为每个 spark 作业设置 conf 是一件比较繁琐的事情。而集群往往多部门共享,在集群级别做 default 设置会影响到其他用户。DataWorks 在支持单任务设置 conf 的同时,提供工作空间级别设置 spark conf 的能力, 作用于空间下的所有 spark 任务。
支持数据分析下载最多500万条记录
支持管理员设置最大下载量,通过数据分析模块,最多支持500万行数据下载到本地。
增强数据治理能力
数据治理中心能力升级
支持基于数据湖架构的数据健康分评估
Dataworks 数据治理中心提供覆盖事前问题检测、事中问题拦截、事后问题发现的主动式数据治理能力。新增对 Dataworks 数据开发+DLF元数据管理用户,进行多维度数据健康分评估。

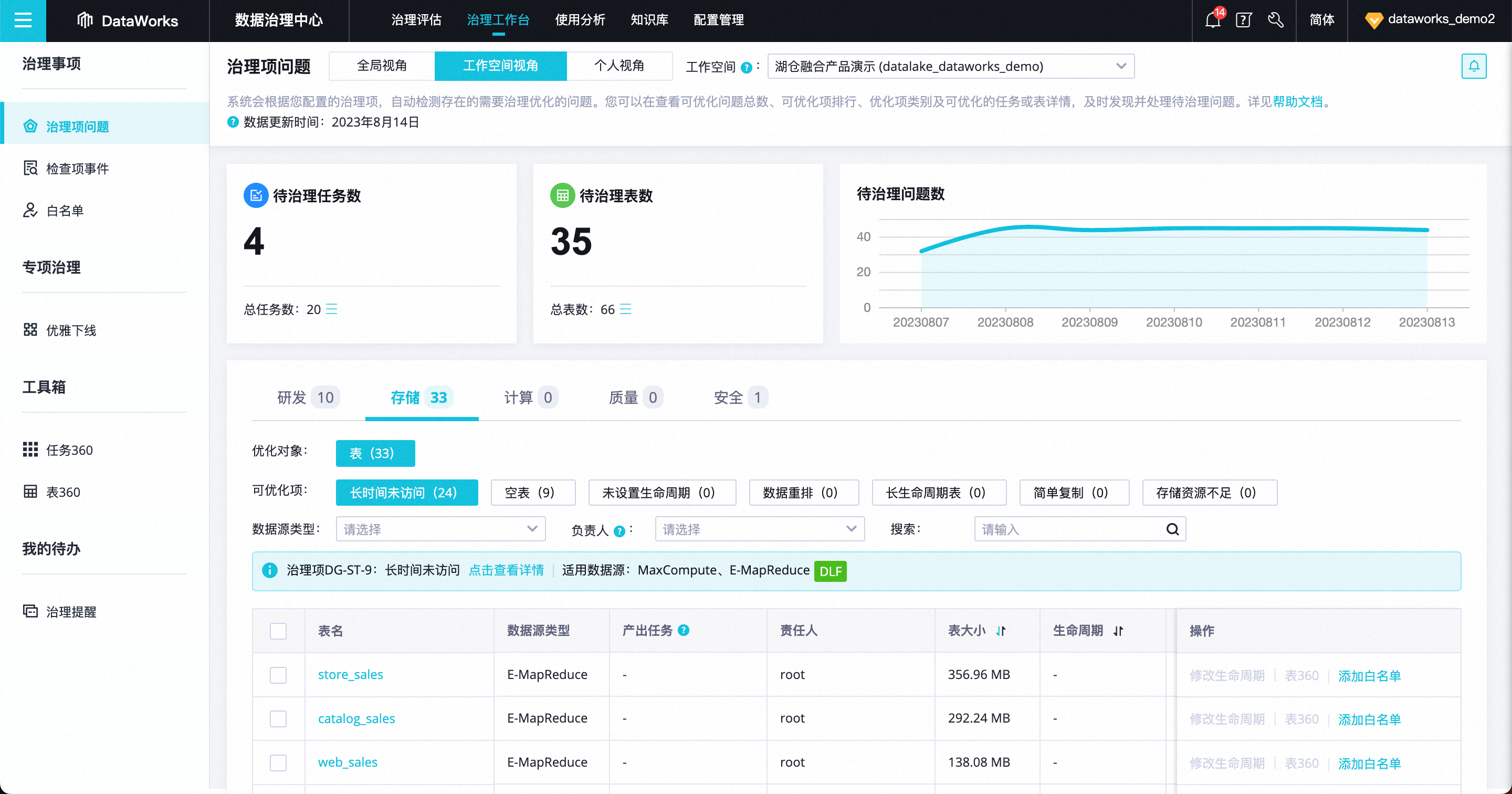
支持基于研发/存储维度的数据治理问题识别
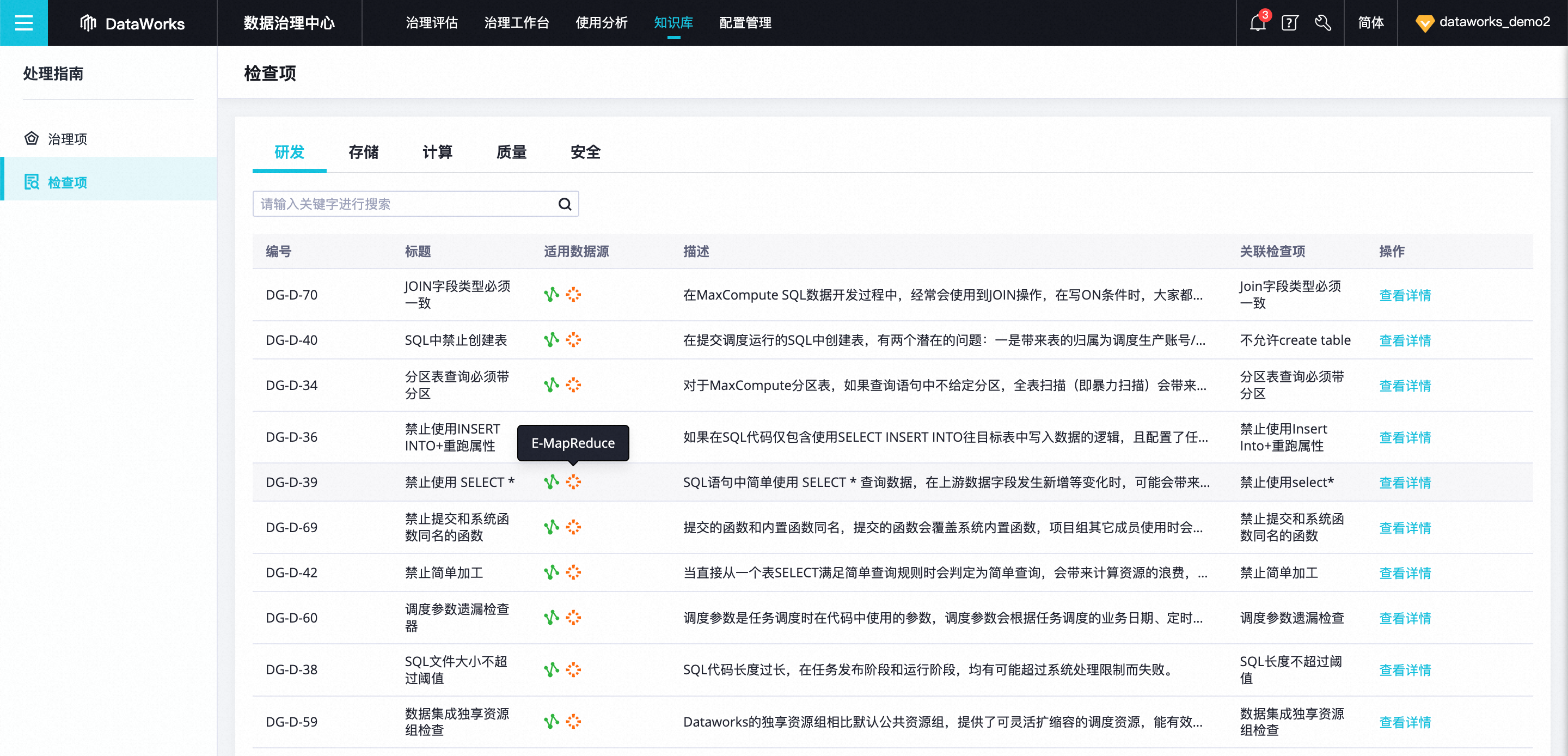
面向 E-MapReduce 用户可支持数据规范治理场景,内置研发、存储、安全维度的十余类内置治理项及知识库,可面向 Dataworks EMR 研发过程中的数据任务及存储问题,进行基于治理项规则的自动问题发现,推动负责人进行问题的及时治理。
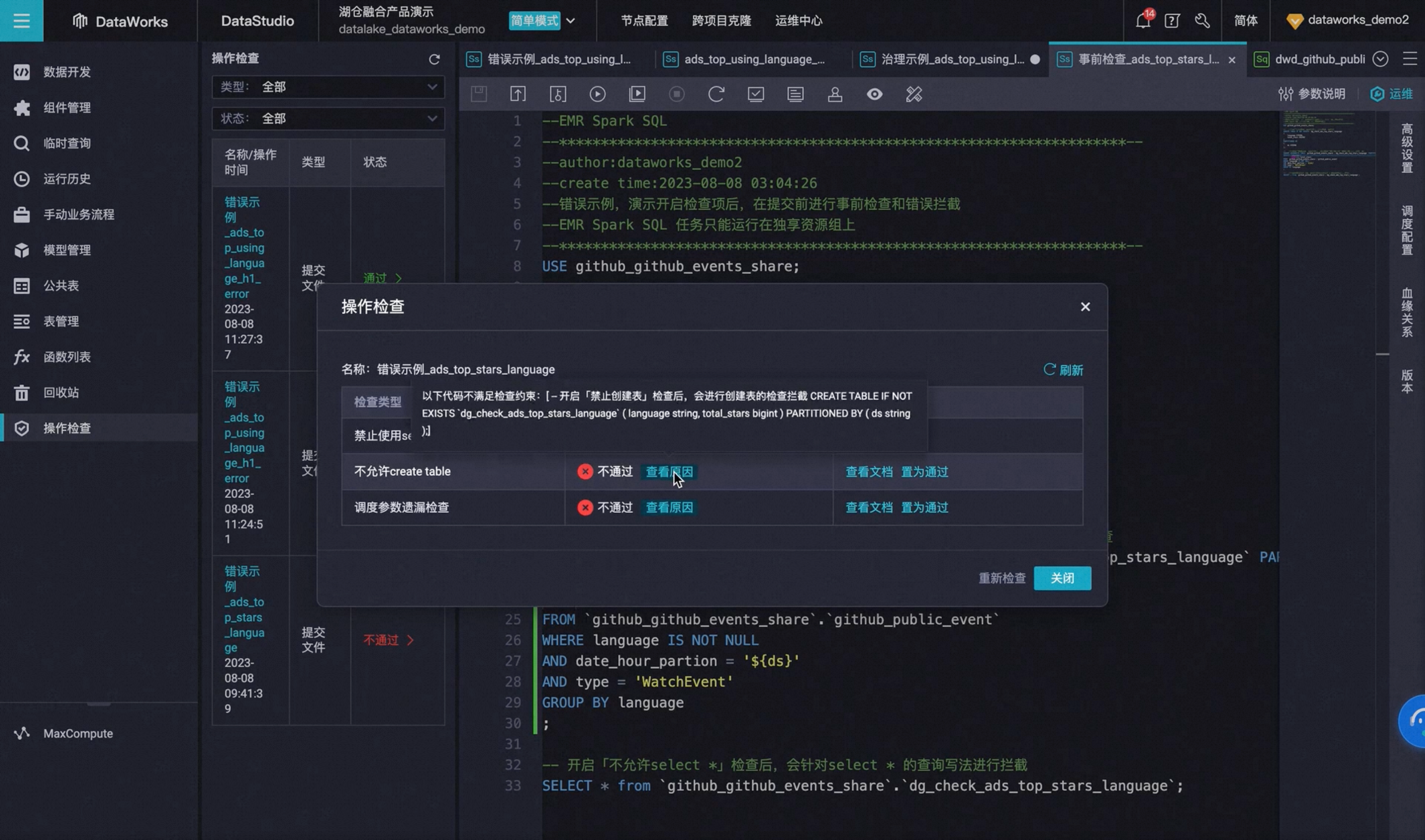
数据治理中心支持基于 EMR Hive/Spark SQL 任务的事前主动治理
Dataworks 数据治理中心新增10种内置数据检查项,可针对 Dataworks 数据研发侧的 Hive SQL 及 Spark SQL 任务,针对提交、发布环节,进行数据问题的检查和自动拦截,进行事前问题预防。
钉钉扫码入群,体验dataworks on emr 数据湖治理并获得首月开通优惠大礼包
