目录
1.前言
C# 程序在 CLR(Common Language Runtime)上运行时,内存被逻辑地划分为两个主要部分:栈和堆。除了栈和堆之外,CLR 还维护了其他一些内存区域,例如静态存储区域(Static Storage Area)、常量存储区域(Constant Storage Area)等。这些内存区域都有各自的特点和用途,可以帮助我们更好地管理程序内存和资源的使用。
在 C# 程序运行时,栈和堆是其基本元素,它们组成了程序的运行环境,对程序的性能和稳定性有着重要的影响。理解和掌握栈和堆的概念和使用方法,是开发高质量 C# 程序的关键。
2.堆和栈的概念:
2.1. 堆的概念:
堆是一块动态分配的内存区域,用于存储程序运行时需要的数据。当声明一个对象或变量时,它们被分配到堆上,并返回其引用(即指向该对象或变量在堆中存储位置的指针)。堆中的对象或变量可以通过其引用来访问和修改。
2.2栈的概念:
栈是一种基于后进先出(Last In First Out,LIFO)原则的内存区域。栈存储几种类型的数据:某些类型变量的值、程序当前的执行环境、传递给方法的参数。当程序调用一个方法时,该方法的参数、返回地址和局部变量等数据会被压入栈中。当方法执行结束时,这些数据会从栈中弹出。
栈的特点:(1)数据只能从栈的顶端插入和删除。(2)把数据放到栈顶称为入栈。(3)从栈顶删除数据称为出栈。
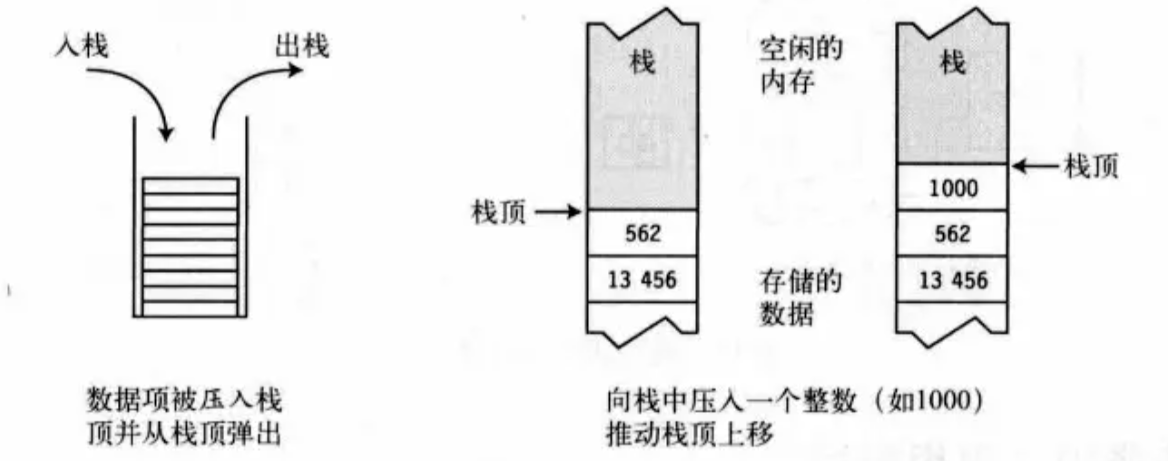
3.堆和栈的区别:
3.1 堆和栈空间分配区别:
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
3.2 堆栈缓存方式区别:
堆(数据结构):是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
栈(数据结构):使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
3.3内存使用区别:
栈(数据结构):大小通常比较有限,不能在栈上存储过多的数据
堆(数据结构):大小可以根据实际需要进行动态扩展,但是过多地使用堆可能会影响程序性能和稳定性。
3.4 堆栈数据结构区别:
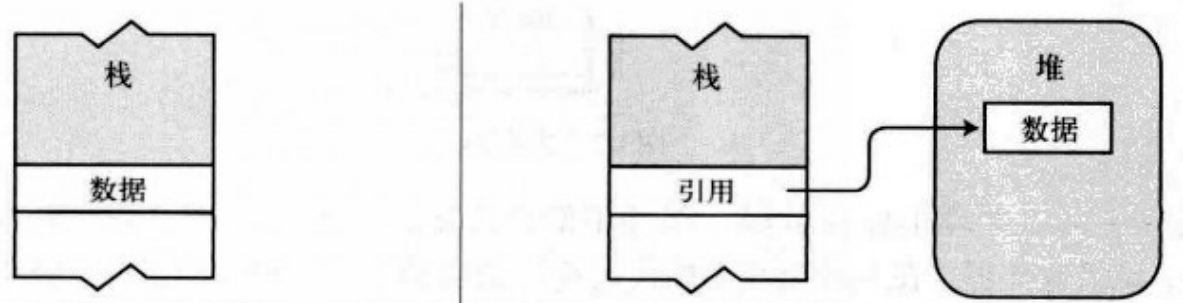
堆(数据结构):引用类型数据通常存储在堆上,引用类型需要两段内存,第一段存储实际的数据,它总是位于堆中。第二段是一个引用,指向数据在堆中的存放位置。当我们使用引用类型赋值的时候,其实是赋值的引用类型的引用。 如果数组是一个值类型的数组,那么数组中直接存储值,如果是一个引用类型的数组(数组中存储的是引用类型),那么数组中存储的是引用(内存地址)。
栈(数据结构):值类型数据通常存储在栈上,例如整数、浮点数、枚举等。值类型只需要一段单独的内存,用于存储实际的数据。
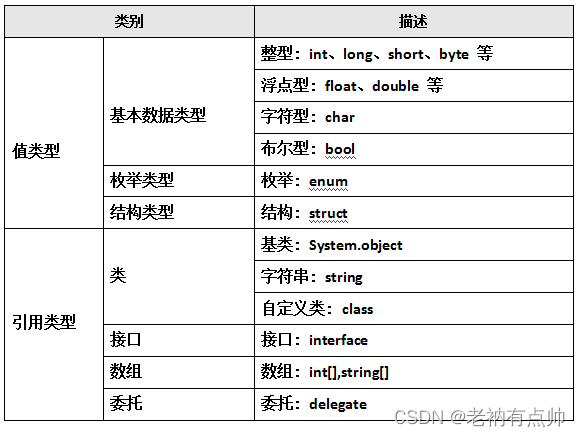
C#常用数据类型如下图所示:
4. 实现堆栈数据结构:
实现堆栈数据结构的常见方式有以下两种:
4.1 数组实现堆栈:
数组实现堆栈是最简单的方法之一。可以使用一个数组来存储堆栈中的元素,然后通过指针来跟踪堆栈顶部。在入栈操作时,只需将元素添加到数组的末尾,并将指针向上移动一位。在出栈操作时,只需从数组的末尾删除元素,并将指针向下移动一位。
public class SeqStack<T> : IStack<T>
{
/// <summary>
/// 顺序栈容量
/// </summary>
private int maxsize;
/// <summary>
/// 数组 用于存储顺序栈中的数据元素
/// </summary>
public T[] data;
/// <summary>
/// 指示顺序栈的栈顶
/// </summary>
private int top;
/// <summary>
/// 容量属性
/// </summary>
public int Maxsize
{
get { return maxsize; }
set { maxsize = value; }
}
/// <summary>
/// 栈顶属性
/// </summary>
public int Top
{
get { return top; }
}
/// <summary>
/// 初始化栈
/// </summary>
/// <param name="size"></param>
public SeqStack(int size)
{
data = new T[size];
maxsize = size;
top = -1;
}
/// <summary>
/// 入栈操作
/// </summary>
/// <param name="item"></param>
public void Push(T item)
{
if (IsFull())
{
Console.WriteLine("Stack is full");
return;
}
data[++top] = item;
}
/// <summary>
/// 出栈操作
/// </summary>
/// <returns></returns>
public T Pop()
{
T tmp = default(T);
if (IsEmpty())
{
Console.WriteLine("Stack is empty");
return tmp;
}
tmp = data[top];
--top;
return tmp;
}
/// <summary>
/// 获取栈顶数据元素,但不弹出元素
/// </summary>
/// <returns></returns>
public T GetTop()
{
if (IsEmpty())
{
Console.WriteLine("Stack is empty");
return default(T);
}
return data[top];
}
/// <summary>
/// 获取栈的长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return top+1;
}
/// <summary>
/// 清空顺序栈
/// </summary>
public void Clear()
{
top = -1;
}
/// <summary>
/// 判断顺序栈是否为空
/// </summary>
/// <returns></returns>
public bool IsEmpty()
{
if(top == -1)
{
return true;
}
return false;
}
/// <summary>
/// 判断顺序栈是否已满
/// </summary>
/// <returns></returns>
public bool IsFull()
{
if(top == maxsize - 1)
{
return true;
}
return false;
}
}4.2 链表实现堆栈:
链表实现堆栈是另一种常见的方法。在链表实现中,每个节点包含一个元素和一个指向下一个节点的指针。使用一个指针来跟踪堆栈顶部,并将新元素作为新节点插入到链表的开头。在出栈操作时,只需删除链表的第一个节点并将其指针指向下一个节点。
public class LinkStack<T> : IStack<T>
{
/// <summary>
/// 栈顶指示器
/// </summary>
private StackNode<T> top;
/// <summary>
/// 栈中元素的个数
/// </summary>
private int size;
/// <summary>
/// 栈顶指示器属性
/// </summary>
public StackNode<T> Top
{
get { return top; }
set { top = value; }
}
/// <summary>
/// 元素个数属性
/// </summary>
public int Size
{
get
{
return size;
}
set
{
size = value;
}
}
/// <summary>
/// 初始化链栈
/// </summary>
public LinkStack()
{
top = null;
size = 0;
}
/// <summary>
/// 入栈操作
/// </summary>
/// <param name="item"></param>
public void Push(T item)
{
StackNode<T> q = new StackNode<T>(item);
if (top == null)
{
top = q;
}
else
{
q.Next = top;
top = q;
}
++Size;
}
/// <summary>
/// 出栈操作
/// </summary>
/// <returns></returns>
public T Pop()
{
if (IsEmpty())
{
Console.WriteLine("Stack is empty");
return default(T);
}
StackNode<T> p = top;
top = top.Next;
--size;
return p.Data;
}
/// <summary>
/// 获取栈顶节点的值
/// </summary>
/// <returns></returns>
public T GetTop()
{
if (IsEmpty())
{
Console.WriteLine("Stack is empty");
return default(T);
}
return top.Data;
}
/// <summary>
/// 获取链栈的长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return size;
}
/// <summary>
/// 清空链栈
/// </summary>
public void Clear()
{
top = null;
size = 0;
}
/// <summary>
/// 判断链栈是否为空
/// </summary>
/// <returns></returns>
public bool IsEmpty()
{
if(top == null && size == 0)
{
return true;
}
return false;
}
}无论是数组实现还是链表实现,堆栈都遵循"后进先出"(LIFO)原则,即最后添加的元素是第一个被删除的元素。
5.堆栈的应用场景和算法:
堆栈是一种非常基础和重要的数据结构,它在计算机科学中有广泛的应用场景和算法。以下是几个常见的应用场景和算法:
-
表达式求值: 堆栈可以用于解析和求值数学表达式。将表达式转换为后缀表达式之后,可以使用堆栈来求值,并支持各种操作符优先级。
-
编译器实现: 许多编译器或解释器都使用堆栈来实现语法分析和代码生成阶段。
-
递归算法: 递归算法可以使用函数调用堆栈来实现。每次递归调用将创建一个新的堆栈帧,在递归返回时将其弹出。
-
网页浏览历史记录: 浏览器通常使用堆栈来跟踪用户访问的网页历史记录。每个新页面都被推入堆栈,通过“后退”功能可以从堆栈中弹出上一个页面。
-
括号匹配: 堆栈可以用于检查括号是否匹配。每当遇到左括号时,将其推入堆栈;每当遇到右括号时,将其与堆栈顶部的左括号进行匹配。
-
迷宫问题: 堆栈可以用于解决迷宫问题,在搜索过程中通过将当前位置和搜索路径推入堆栈,来回跟踪搜索状态。
在算法方面,常见的堆栈算法包括如下几种:
-
排序算法: 可以使用堆栈来实现快速排序、归并排序等基于分治的排序算法。
-
DFS(深度优先搜索): 深度优先搜索可以使用堆栈来实现。每次访问一个节点时,将其压入堆栈,并在处理完所有邻居节点后再弹出。
-
DP(动态规划): 在某些情况下,可以使用堆栈来实现动态规划算法的备忘录机制,以避免重复计算。
总之,堆栈是一种非常常用的数据结构,广泛应用于各种编程场景中。
6.堆栈与队列的比较:
堆栈(Stack)和队列(Queue)是两种最基本的数据结构之一,它们都用于存储一组元素,但在元素的添加、删除和访问方面具有不同的行为。
-
添加元素的顺序: 堆栈遵循“后进先出”(LIFO)的原则,即最后添加的元素是第一个被删除的元素。而队列遵循“先进先出”(FIFO)的原则,即最先添加的元素是第一个被删除的元素。
-
删除元素的方式: 在堆栈中,只有顶部的元素可以被删除或访问。而在队列中,除了队首元素外,其他元素也可以被删除或访问。
-
访问特定位置的元素: 在堆栈中,没有提供访问特定位置的元素的方法,只能通过弹出元素来访问堆栈中的所有元素。而在队列中,可以通过索引访问特定位置的元素。
-
应用场景: 堆栈常用于需要回溯(backtracking)的场景,例如在解析表达式、记忆搜索等算法中;而队列常用于实现缓冲区和调度器等场合。
总之,堆栈和队列各自具有不同的特点和应用场景,开发者需要根据具体需求选择合适的数据结构。