首先mysql结构图:
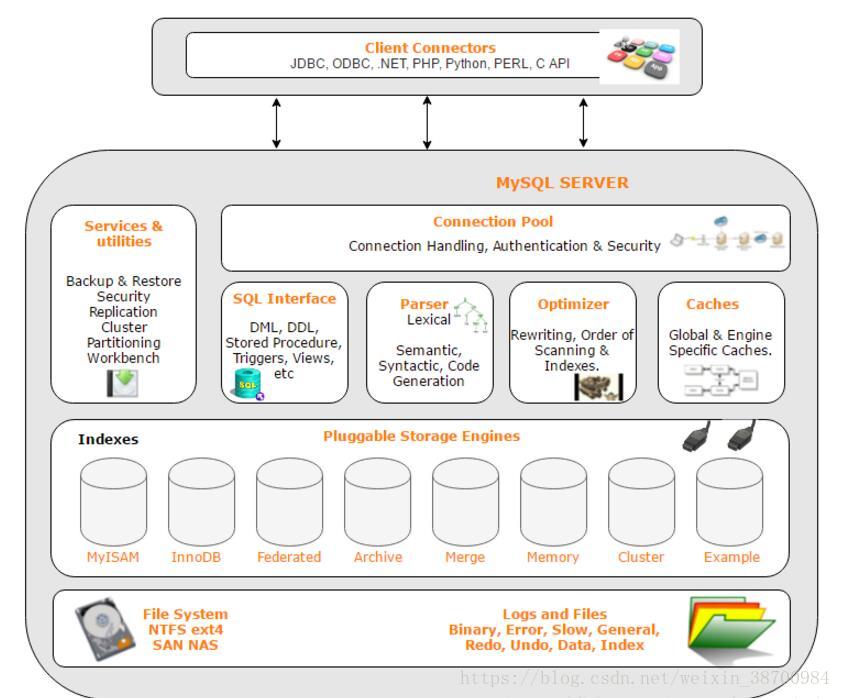
连接层、服务层、引擎层、存储层
Connectors指的是不同语言中与SQL的交互接口,例如适用于Java的JDBC,.Netframework的ODBC。
Management Serveices & Utilities:系统管理和控制工具集合,例如备份还原,安全复制等功能。
Connection Pool:连接池,用于管理缓冲用户连接,线程处理等需要缓存的需求。
SQL Interface:SQL接口,用于接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface。
Parser:解析器,用于SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
Optimizer:查询优化器,用于SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
Cache和Buffer:查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等。

Engine:存储引擎,存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。Mysql的存储引擎是插件式的。它根据MySql提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)。现在有很多种存储引擎,各个存储引擎的优势各不一样,最常用的MyISAM,InnoDB,BDB
SQL执行顺序: from on join where group by having select distinct union order by
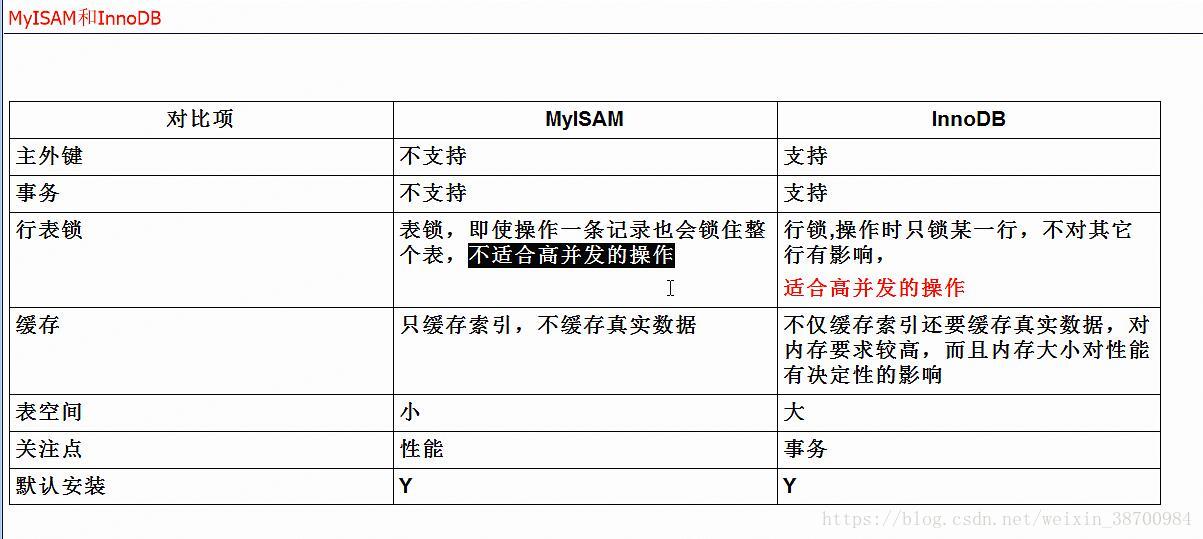
MyISAM,InnoDB区别:
一、慢查询的开启与捕获
log_output 参数是指定日志的存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。
SHOW GLOBAL VARIABLES LIKE '%slow_query_log%' //查看是否开启
SHOW GLOBAL VARIABLES LIKE '%long_query_time%' //查看查询慢阙值时间
SHOW GLOBAL STATUS LIKE '%slow_query%' //查看慢查询的所有sql条数
SHOW VARIABLES LIKE '%log_queries_not_using_indexes%' //查看sql未使用索引的查询

SET GLOBAL slow_query_log=1 //开启慢查询日志,mysql默认是关闭的,用到的时候再打开,用完及时关闭。
SET GLOBAL long_query_time=2 //设置sql执行大于2秒为慢查询日志
SET GLOBAL log_queries_not_using_indexes=1 //设置是否打印未使用索引的sql
slow_query_log_file = /mysqldata/log/slow-query.log // 慢查询日志存放路径 默认为 hostname-slow.log
log_output='FILE'
利用mysqldumpslow日志分析工具
mysqldumpslow -help
s:表示按照何种方式排序
c:访问次数
l:锁定时间
r:返回记录
t:即将返回前面多少条数
al:平均锁定时间
ar:平均返回记录条数
at:平均查询时间
g:后边搭配一个正则表达式,大小写不敏感
例子:
得到返回记录集最多的10条sql
mysqldumoslow -s r -t 10 /mysqldata/log/slow-query.log
得到访问次数最多的10条sql
mysqldumoslow -s c -t 10 /mysqldata/log/slow-query.log
得到按照时间 排序的前10条里面包含有左连接的查询语句
mysqldumoslow -s t -t 10 -g "left join" /mysqldata/log/slow-query.log
另外使用这些命令时结合| 和more使用,否则可能出现爆屏情况。
mysqldumoslow -s r -t 10 /mysqldata/log/slow-query.log | more
二、explan+慢SQL分析
explan+sql 能够分析出:
1、表的读取顺序 2、数据读取操作的操作类型 3、哪些所以可以被使用 4、哪些索引实际被使用 5、表之间的引用
6、每张表有多少行被优化器查询

id:table的读取顺。从高到低依次读取。
select_type:查询的类型 SIMPLE 简单查询 SUBQUERY 子查询 PRIMARY UNION 等等
table:查询的表
type : 分析sql性能的重要参数。性能优越性依次为 system>const>eq_ref>ref>range>index>all。
possibe_keys :可能用到的key
key:实际用到的key
ref : 查询索引用到的值
rows : 该表多少行被优化器查询
extra : 存储一些重要的信息。Using filesort 文件排序(一般order by.会遇到需优化),Using temporary(会自动创建临时表,必须优化), Using index(用到了索引。说明这个sql性能良好),Using join buffer(多个join下会存在,用多了查询缓存).......
sql语句编写规则:
1、全值匹配
2、最佳左前缀法则:如果索引了多个列,查询应该从索引的最左前列开始且不跳过索引中的列
3、不在索引上做任何操作(计算、函数、类型转换等),会导致索引失效而转向全表扫描
4、存储引擎不能使用索引范围条件右边的列
5、尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select*
6、mysql在使用不等于(!= 或者 <>)的时候会使索引失效,导致全表扫描
7、is null,is not null 也无法使用索引
8、like 以通配符开头 (‘%aaa’)mysql索引会失效导致全表扫描。不是这种 like 'aaa%'
9、字符串不加单引号索引也会失效
10、少用or,用它来连接时会使索引失效。可以用 union
11、提高order by 速度。尝试提高 sort_buffer_size,提高 max_length_for_sort_data

12、小表驱动大表及小的数据集驱动大的数据集。比如 left join 应该在右表建索引等等,也就是说最外层的查询应该是小表。
select *from A where id in ( select id from B )
等价于: for select id from B
for select * from A where A.id = B.id
当B表数据集必须小于A表数据集时,用in优于exists
select *from A where id exists ( select 1 from B where B.id = A.id)
等价于: for select id from A
for select * from B where B.id = A.id
当A表数据集必须小于B表数据集时,用exists优于in
注意:A表和B表的id字段应建立索引。三、show profile
1、首先确认,现在mysql版本是否支持
2、开启此功能,默认是关闭的,使用前需先开启
show variables like 'profiling'
set profiling =on
3、运行sql
4、查看结果,show profile
5、诊断sql、show profile cpu,block io for query 上一步前面的问题sql数字号码
show profile 参数:
ALL 显示所有开销信息
BLOCK IO 显示快IO相关开销
CONTEXT SWITCHES 上线文切换相关开销
CPU 显示cpu相关开销
IPC 显示发送和接收消息相关开销信息
MEMORY 显示内存相关开销信息
PAGE FAULTS 显示页面错误相关开销信息
SOURCE 显示和 Source_function ,Source_file,Source_line相关开销信息
SWAPS 显示交换次数相关开销信息
6、诊断表中出现 converting HEAP to MyISAM (查询结果太大、内存放不下),creating tmp table 创建临时表(1、需要拷贝数据用到了cup、用完以后还需要删除临时表)、coping to tmp table on disk (把内存中临时表的数据复制到硬盘上)、locked。group by 容易产生临时表,用时最好先order by。