目录
LRU是
Least Recently Used的缩写,译为最近最少使用。它的理论基础是
时间局部性:“最近使用的数据会在未来一段时期内仍然被使用,已经很久没有使用的数据大概率在未来很长一段时间仍然不会被使用”。
题目介绍
146. LRU 缓存 - 力扣(LeetCode)
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。 实现 LRUCache 类:
- LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
题目分析
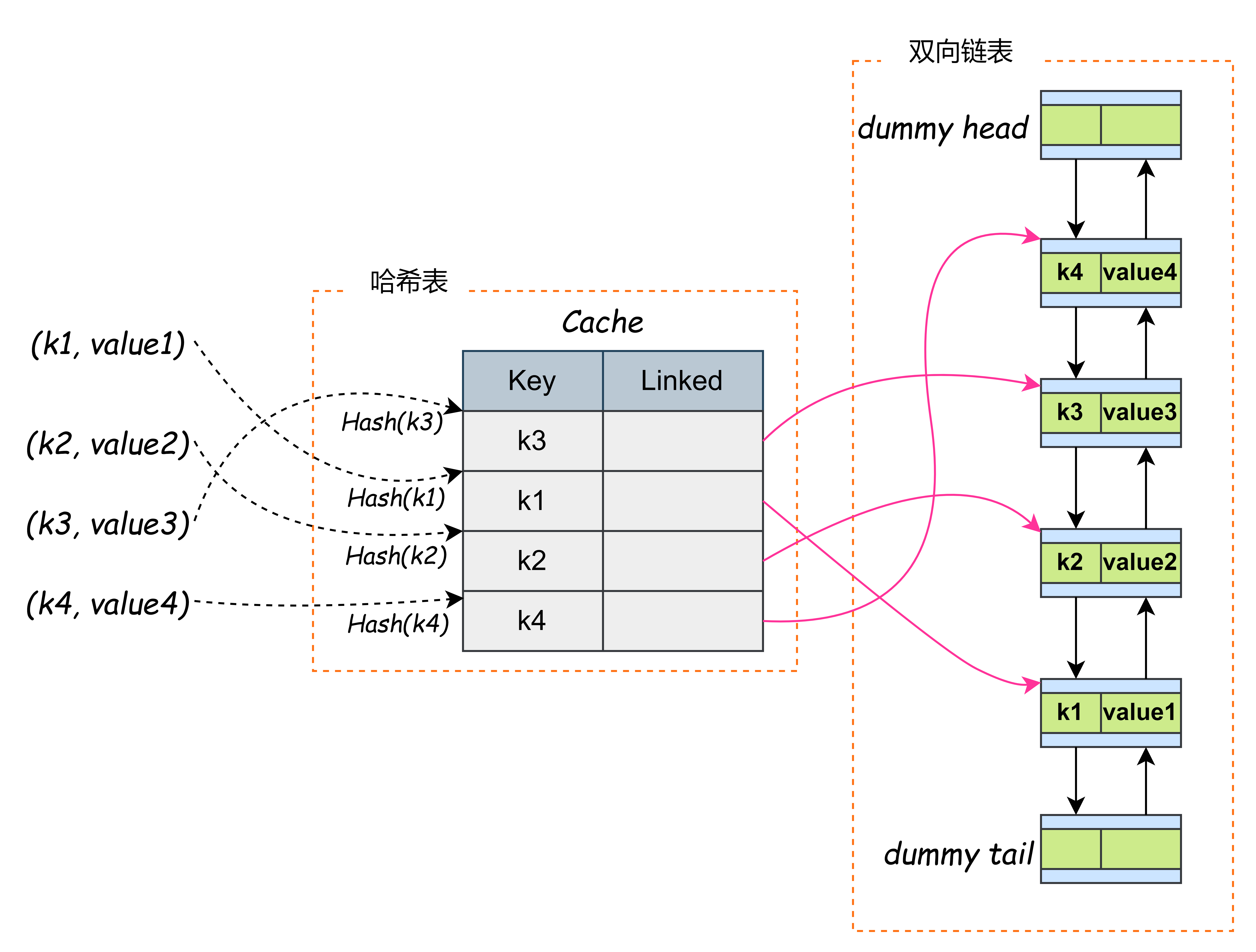
理想的LRU应该可以在O(1)的时间内读取一条数据或更新一条数据,即函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。很容易想到哈希表。根据数据的key可以很容易在o(1)时间复杂度内达到读写速度。除此之外,如果只用哈希表,那么确定哪一条数据的访问时间最早,这需要遍历所有表才能找到,因此,需要维护一个按访问时间排序,又能在o(1)时间复杂度内访问最近使用元素(插入最近访问的),最晚使用元素(删除最不常访问的),删除一个元素(快速删除节点)。基于此,考虑使用哈希表+双向链表实现来实现。其逻辑结构图如下所示:

这里简单说明一下,Cache表示的是一张哈希表(HashMap),通过缓存数据的键映射到其在双向链表中的位置。而双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
注意:在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
基于该结构,其数据结构实现如下:
public class LRUCache {
// 双向链表的节点元素
class DLinkedNode {
int key; // 关键字
int value; // 对应的值
DLinkedNode prev; // 双向链表的前驱指针
DLinkedNode next; // 双向链表的后继指针
}
// 使用java自带的 HashMap 来模拟 Cache表
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size; // 目前缓存中有效数据的个数
private int capacity; // LRU缓存容量大小
private DLinkedNode head, tail; // 双向链表的头结点和尾结点
}
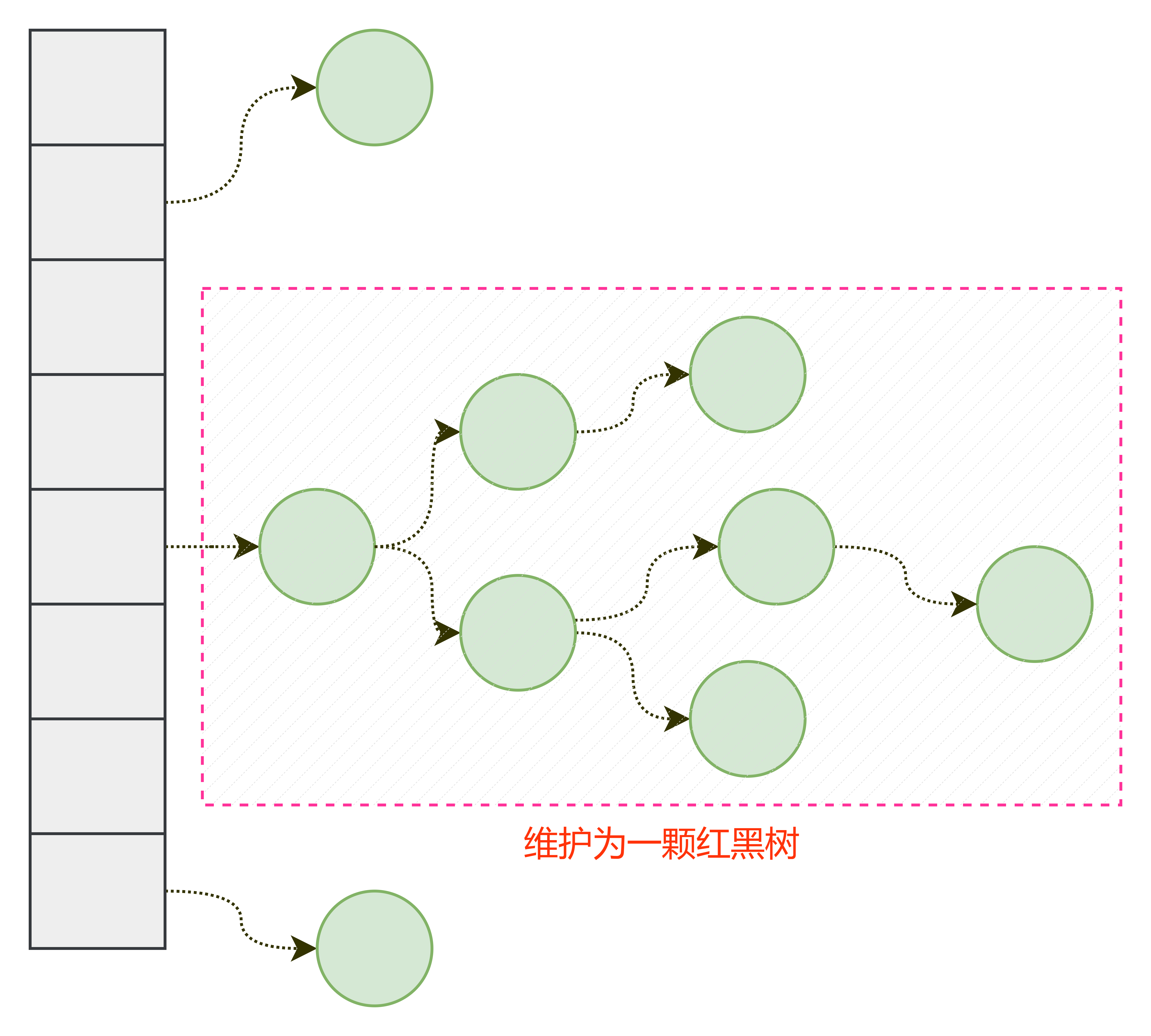
说明,这里是针对146. LRU 缓存 - 力扣所设计的结构,如果想使其更加广泛的使用,可以考虑使用范型。以及自己实现Cache的哈希表(数组+红黑树:通过链地址法解决冲突,并对链表进行红黑树优化,在
o(log(n))时间复杂度中找到元素)。
图解示例
基于上述数据结构,现在模拟一个容量大小为4的LRU缓存。针对不同情况有如下分析:
对于Cache表未满,且插入数据后未命中
在最开始,添加四个元素 (k1,value1), (k2,value2), (k3,value3), (k4,value4), 由于这四次插入时,Cache表未满,且计算hash值时没冲突情况。因此,其情况一致,这里以 put(k4, value4) 为例说明:首先判断目前缓存中有效数据未满,然后计算关键字k4的哈希值Hash(k4),发现未冲突,因此创建一个双向链表结点,将数据装入(key, value),然后找到双向链表的头指针head ,在头部添加该元素,并将Cache中Hash(k4)对应的指针域指向该元素结点。
在插入这四个元素以后,其结构中数据对应的逻辑结构如下:

对于Cache表已满,且插入数据后未命中
当添加完 k1, k2, k3, k4 四个元素后,这时候通过 put(k5, value5)添加元素,发现超出 Cache 表的容量,但是计算哈希值后发现未冲突,因此还是创建一个双向链表结点,并将 k5 结点的数据输入,并在双向链表的头部添加该元素结点。由于添加 k5 结点后,容量超出了,因此通过删除双向链表的尾指针的前驱结点来保证最久未使用元素离开缓存。(这里有个点,就是对于Cache表的处理,由于是哈希表,且是通过链地址法来处理冲突的,因此可以删除hash表中元素。如果是其他方式得考虑如何删除哈希表中的元素)。其处理流程如下所示,其中标号表示执行顺序。

对于插入数据后未命中情况
当添加完 k1, k2, k3, k4 四个元素后,继续 put(k3, value3)添加元素(这里未必需要Cache满了):发现计算Hash(k3)能够找到 k3 在 Cache表中。因此对于Cache表不需要修改。而是将该Cache 表格中 k3 对应的在双向链表的结点移动到头部去。
基于上述三种情况分析可以得到结论:
- 每次添加元素到双向链表中的时候都是从头部进行添加
- 每次删除元素的时候都是从尾部进行删除
- 删除的时候同时需要从哈希表中删除对应的key
- 再次访问的元素,需要把元素移动到链表的头部
算法实现
主要用于实现三个方法:
LRUCache(int capacity):初始化一个容量大小为capacity的缓存器。int get(int key):如果关键字key存在于缓存中,则返回关键字的value,否则返回-1。void put(int key, int value):将key存入缓存中,并保持LRU的特性。
get操作
对于 get 操作,首先判断 key 是否存在:
- 如果
key不存在,则返回-1 - 如果
key存在,则key对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
public int get(int key) {
DLinkedNode node = cache.get(key); //从Cache中获取对应双向链表中的结点地址
// key不存在
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部,先删除:
node.prev.next = node.next;
node.next.prev = node.prev;
// 再插入到头部
node.next = head.next;
head.next.prev = node;
node.prev = head;
head.next = node;
return node.value;
}
put操作
- 如果
key不存在,使用key和value创建一个新的双向链表节点,并在双向链表的头部添加该节点,并将key和该节点的地址添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项; - 如果
key存在,则与get操作类似,先通过哈希表定位,再将对应的节点的值更新为value,并将该节点移到双向链表的头部。
public void put(int key, int value) {
DLinkedNode node = cache.get(key); //从Cache中获取对应双向链表中的结点地址
// 如果 key 不存在
if (node == null) {
// 创建一个新的双向链表节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
newNode.next = head.next;
head.next.prev = newNode;
newNode.prev = head;
head.next = newNode;
++size;//容量 + 1
// 如果超出容量,删除双向链表的尾部节点
if (size > capacity) {
DLinkedNode temp = tail.prev;
// 删除结点
temp.prev.next = tail;
tail.prev = temp.prev;
// 删除哈希表中对应的项
cache.remove(temp.key);
--size;
}
} else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
node.prev.next = node.next;
node.next.prev = node.prev;
// 再插入到头部
node.next = head.next;
head.next.prev = node;
node.prev = head;
head.next = node;
}
}
重构代码
根据官方解答,会发现其对一些简单操作进行了封装,也就是在 put 和 get 操作过程中,对双向链表的处理主要包括 删除结点,从头结点插入, 从尾结点删除, 移动结点到头结点中:
//删除结点
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
//从头结点插入
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
//从尾结点删除
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
//移动结点到头结点中
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
其对双向链表的操作逻辑如图所示:
删除结点:

从头结点插入:

从尾结点删除:
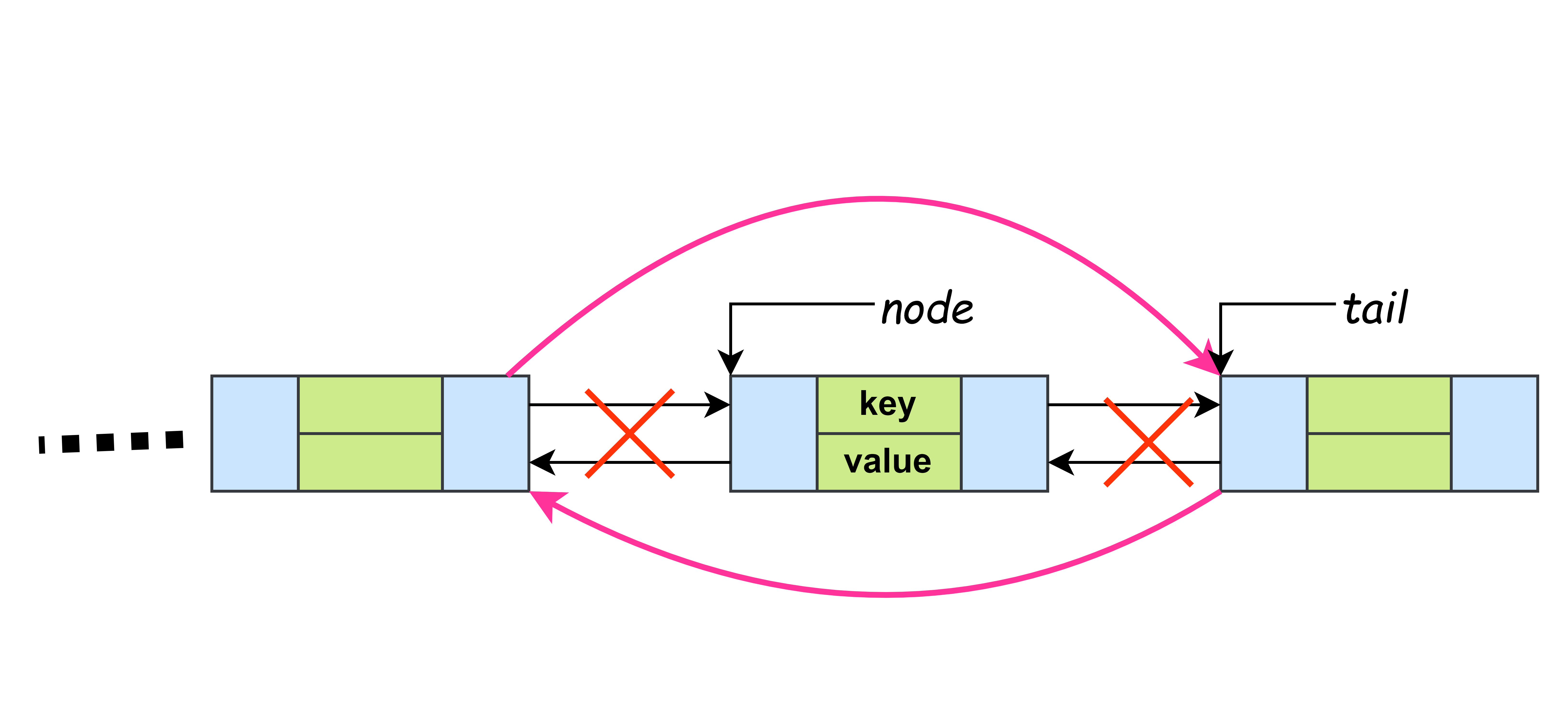
移动结点到头结点中:
HashMap扩展
在上述内容中,由于使用的是 java 自带的 HashMap 集合来实现的。所以对其进行一定的说明:在计算哈希值后,有一定概率会产生冲突,为此,可以通过链地址法来解决该冲突情况:对于冲突元素将其加入到对应维护的单链表中即可,如图:
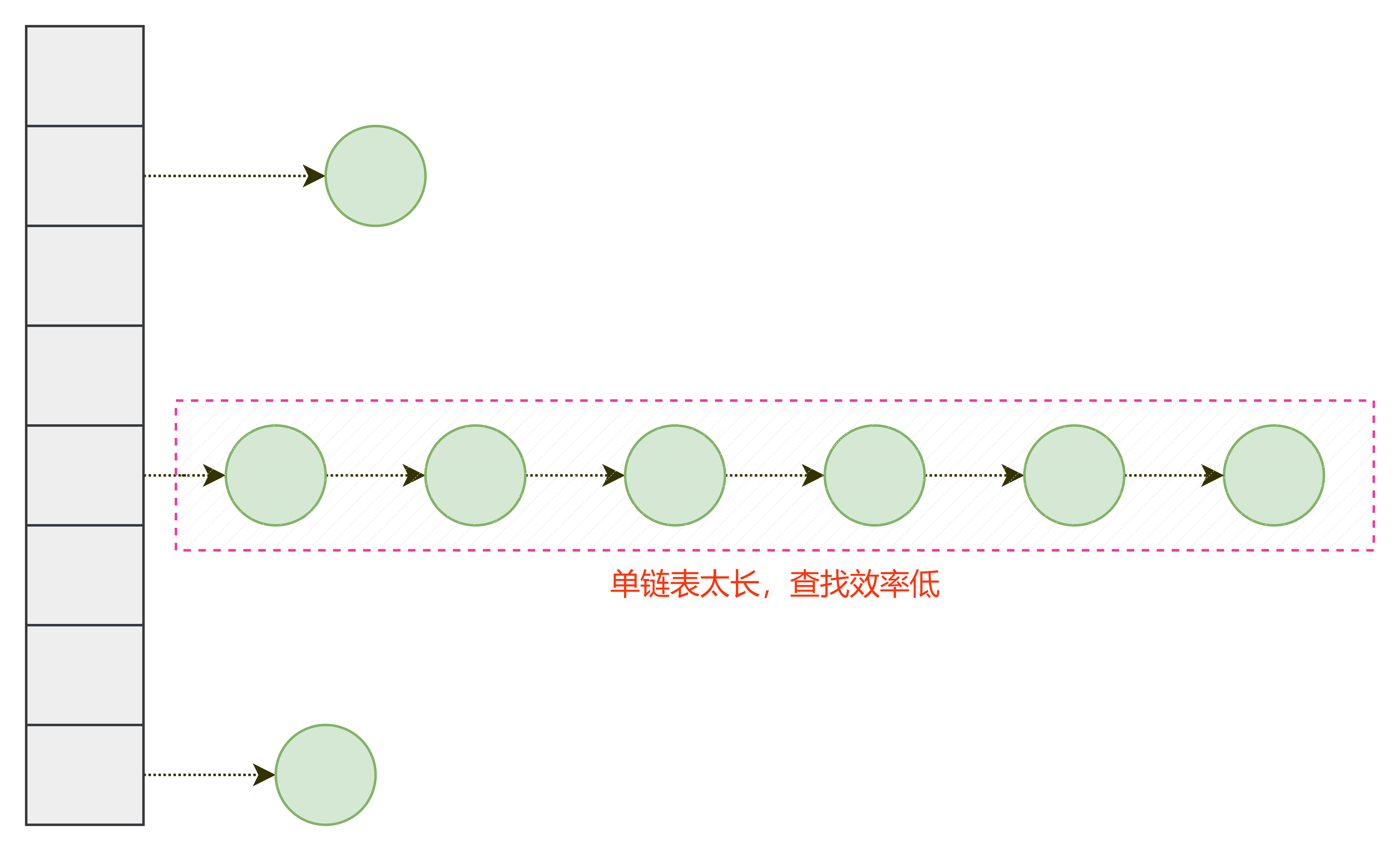
但是这样容易产生链表过长而导致其查找效率低下的情况,因此,可以将单链表维护为一个平衡二叉树(java中维护的是红黑树),这样能够在 o(lg(n)) 时间复杂度的情况下查找到该元素。即: