SLAM
前言
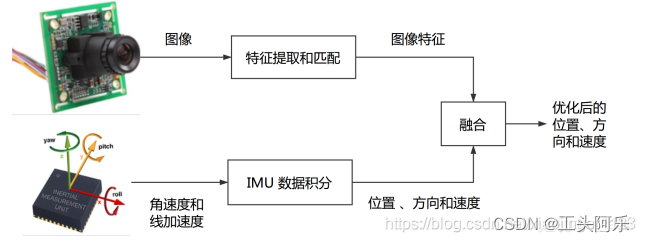
VIO(visual-inertial odometry)即视觉惯性里程计,有时也叫视觉惯性系统(VINS,visual-inertial system),是融合相机和IMU数据实现SLAM的算法,根据融合框架的区别又分为紧耦合和松耦合,松耦合中视觉运动估计和惯导运动估计系统是两个独立的模块,将每个模块的输出结果进行融合,而紧耦合则是使用两个传感器的原始数据共同估计一组变量,传感器噪声也是相互影响的,紧耦合算法上比较复杂,但充分利用了传感器数据,可以实现更好的效果,是目前研究的重点。
IMU与视觉比较

相机和IMU融合有很好的互补性。首先通过将IMU 估计的位姿序列和相机估计的位姿序列对齐可以估计出相机轨迹的真实尺度,而且IMU 可以很好地预测出图像帧的位姿以及上一时刻特征点在下帧图像的位置,提高特征跟踪算法匹配速度和应对快速旋转的算法鲁棒性,最后IMU 中加速度计提供的重力向量可以将估计的位置转为实际导航需要的世界坐标系中。
【利用视觉信息估计IMU的零偏,减少IMU由零偏导致的发散和累积误差;利用IMU为视觉提供快速运动时的定位。
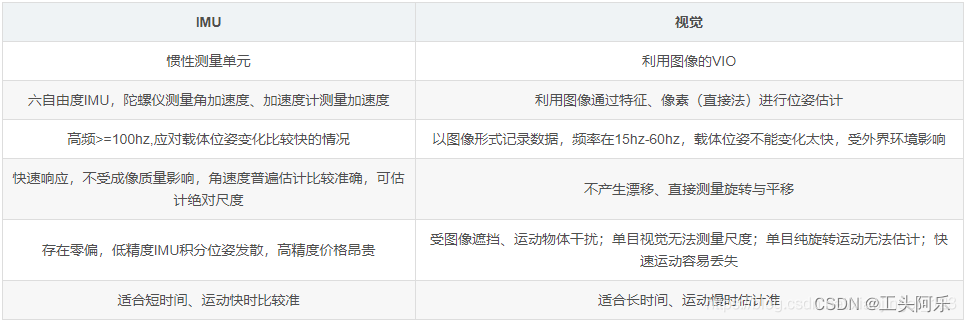
IMU: IMU虽然可以测得角速度和加速度,但这些量都存在明显的漂移(Drift),使得积分两次得到的位姿数据非常不可靠。好比说,我们将IMU放在桌上不动,用它的读数积分得到的位姿也会漂出十万八千里。但是,对于短时间内的快速运动,IMU能够提供一些较好的估计。这正是相机的弱点。当运动过快时,(卷帘快门的)相机会出现运动模糊,或者两帧之间重叠区域太少以至于无法进行特征匹配,所以纯视觉SLAM非常害怕快速的运动。现在与未来使在相机数据无效的那段时间内,我们还能保持一个较好的位姿估计,这是纯视觉SLAM无法做到的。
相机: 相比于IMU,相机数据基本不会有漂移。如果相机放在原地固定不动,那么(在静态场景下)视觉SLAM的位姿估计也是固定不动的。所以,相机数据可以有效地估计并修正IMU读数中的漂移,使得在慢速运动后的位姿估计依然有效。
当图像发生变化时,本质上我们没法知道是相机自身发生了运动,还是外界条件发生了变化,所以纯视觉SLAM难以处理动态的障碍物。而IMU能够感受到自己的运动信息,从某种程度上减轻动态物体的影响。
总而言之,我们看到IMU为快速运动提供了较好的解决方式,而相机又能在慢速运动下解决IMU的漂移问题——在这个意义下,它们二者是互补的】。
单目视觉缺陷:
单目视觉 SLAM 算法存在一些本身框架无法克服的缺陷,首先是尺度的问题 ,单目 SLAM 处理的图像帧丢失了环境的深度信息,即使通过对极约束和三角化恢复了空间路标点的三维信息,但是这个过程的深度恢复的刻度是任意的,并不是实际的物理尺度,导致的结果就是单目SLAM 估计出的运动轨迹即使形状吻合但是尺寸大小却不是实际轨迹尺寸;由于基于视觉特征点进行三角化的精度和帧间位移是有关系的,当相机进行近似旋转运动的时候,三角化算法会退化导致特征点跟踪丢失,同时视觉 SLAM 一般采取第一帧作为世界坐标系,这样估计出的位姿是相对于第一帧图像的位姿,而不是相对于地球水平面 (世界坐标系) 的位姿,后者却是导航中真正需要的位姿,换言之,视觉方法估计的位姿不能和重力方向对齐。重力向量构建了视觉坐标系和世界坐标系的联系
融合IMU优势:
通过引入 IMU 信息可以很好地解决上述问题,首先通过将 IMU 估计的位姿序列和相机估计的位姿序列对齐可以估计出相机轨迹的真实尺度,而且 IMU 可以很好地预测出图像帧的位姿以及上一时刻特征点在下帧图像的位置,提高特征跟踪算法匹配速度和应对快速旋转的算法鲁棒性,最后 IMU 中加速度计提供的重力向量可以将估计的位置转为实际导航需要的世界坐标系中。同时,智能手机等移动终端对 MEMS 器件和摄像头的大量需求大大降低了两种传感器的价格成本;硬件实现上, MEMS 器件也可以直接嵌入到摄像头电路板上。综合以上,融合 IMU 和视觉信息的 VINS 算法可以很大程度地提高单目 SLAM 算法性能,是一种低成本高性能的导航方案。
相机-IMU标定
相机IMU标定的目的是获取两个传感器坐标系之间的空间关系和数据延迟,是VIO系统工作的前提工作。相机-IMU标定可以看成状态估计的逆过程,标定是通过标定板获取每个时刻的精确运动状态,计算出模型参数(坐标系间旋转位移、时间延迟、IMUbias),而运动估计则是在已知两个传感器坐标系间的模型参数,估计每个时刻的运动状态。
目前有现成的标定库可以使用(/kalibr/wiki/Camera-IMU-calibration ),此外,相机-IMU标定需要事先知道相机和IMU的内参;做SLAM中我们也经常需要对新的相机进行内参标定。推荐ROS自带相机标定工具,可以实现在线标定。
松耦合
将视觉传感器和 IMU分别计算得到的位姿直接进行融合,融合过程对二者本身不产生影响,作为后处理方式输出,一般通过 EKF 进行融合。
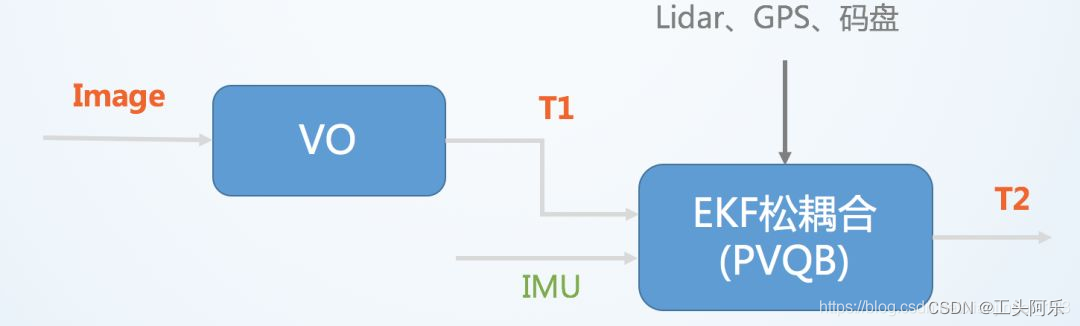
其中VO(visual odometry)指仅视觉的里程计,T表示位置和姿态。松耦合中视觉运动估计和惯导运动估计系统是两个独立的模块,将每个模块的输出结果进行融合。
紧耦合
将视觉传感器和 IMU 的状态通过一个优化滤波器合并在一起,紧耦合需要把图像特征加入到特征向量中,共同构建运动方程和观测方程,然后进行状态估计,最终得到位姿信息的过程,其融合过程本身会影响视觉和 IMU 中的参数(如 IMU 的零偏和视觉的尺度)。
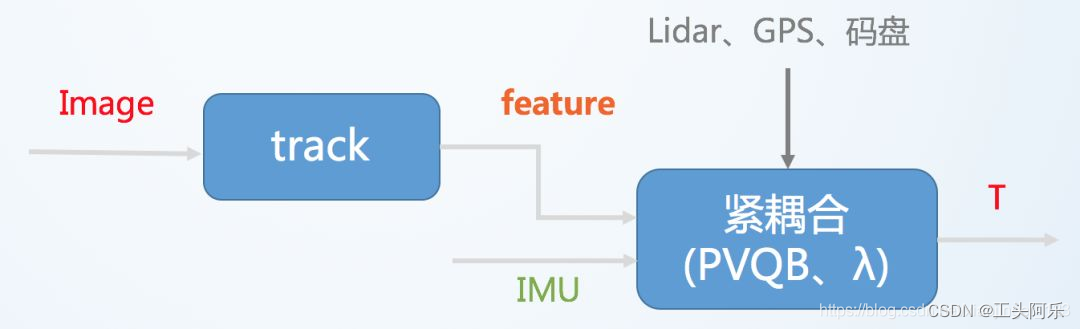
紧耦合则是使用两个传感器的原始数据共同估计一组变量,传感器噪声也是相互影响的。紧耦合算法比较复杂,但充分利用了传感器数据,可以实现更好的效果,是目前研究的重点。
开源框架
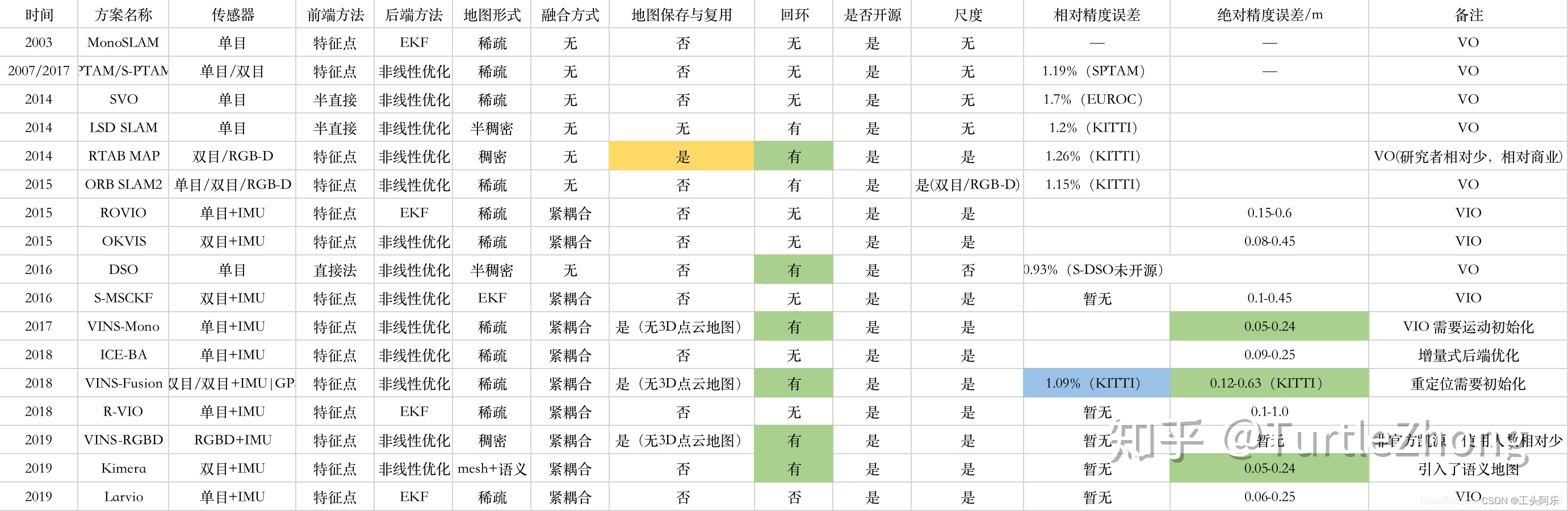
玩视觉slam的小伙伴想必都跑过各种vo,vio,slam系统,至少下面的一款你肯定玩过的ORB-SLAM,SVO,DSO,VINS-Mono,MSCKF,Kimera等等。下面先简单总结一下历年来slam系统的对比,对比如下表:
基于滤波的融合方案:
松耦合:苏黎世联邦理工学院(eth)的 SSF(融合IMU和单个视觉传感器)和 MSF(融合IMU和多个位置传感器);
紧耦合:比较经典的算法是MSCKF,ROVIO;
基于优化的融合方案:
松耦合: 基于松耦合优化的工作不多。 Gabe Sibley在IROS2016的一篇文章《Inertial Aided Dense & Semi-Dense Methods for Robust Direct Visual Odometry》提到了这个方法。简单来说就是把VO计算的位姿变换添加到IMU的优化框架里面。
紧耦合:OKVIS(多目+IMU)、 VINS-Mono、VINS-Fusion、VI-ORB;
算法实现流程:
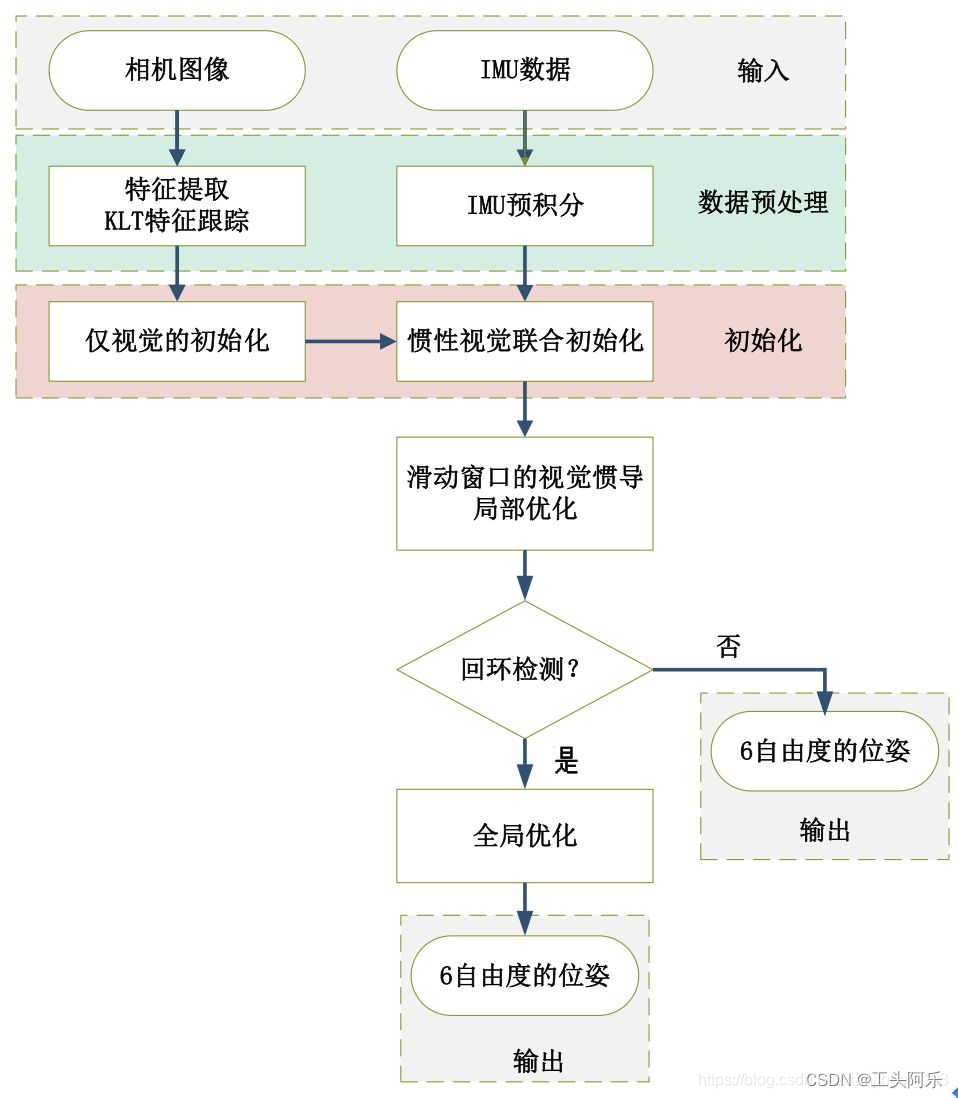
整个流程图可以分解为五部分:数据预处理、初始化、局部非线性优化、回环检测和全局优化。
各个模块的主要作用是:
图像和IMU数据预处理:对于图像,提取特征点,利用KLT金字塔进行光流跟踪,为后面仅视觉初始化求解相机位姿做准备。对于IMU,将IMU数据进行预积分,得到当前时刻的位姿、速度、旋转角,同时计算在后端优化中将要用到的相邻帧间的预积分增量,及预积分的协方差矩阵和雅可比矩阵。
初始化:初始化中,首先进行仅视觉的初始化,解算出相机的相对位姿;然后再与IMU预积分进行对齐求解初始化参数。
局部非线性优化:对应流程图中滑动窗口的视觉惯导非线性优化,即将视觉约束、IMU约束放在一个大目标函数中进行优化,这里的局部优化也就是只优化当前帧及之前的n帧的窗口中的变量,局部非线性优化输出较为精确的位姿。
回环检测:回环检测是将前面检测的图像关键帧保存起来,当再回到原来经过的同一个地方,通过特征点的匹配关系,判断是否已经来过这里。前面提到的关键帧就是筛选出来的能够记下但又避免冗余的相机帧(关键帧的选择标准是当前帧和上一帧之间的位移超过一定阈值或匹配的特征点数小于一定阈值)。
全局优化:全局优化是在发生回环检测时,利用相机约束和IMU约束,再加上回环检测的约束,进行非线性优化。全局优化在局部优化的基础上进行,输出更为精确的位姿。
补充
看到一些总结很好,故进行以下补充:
VIO引出原因:
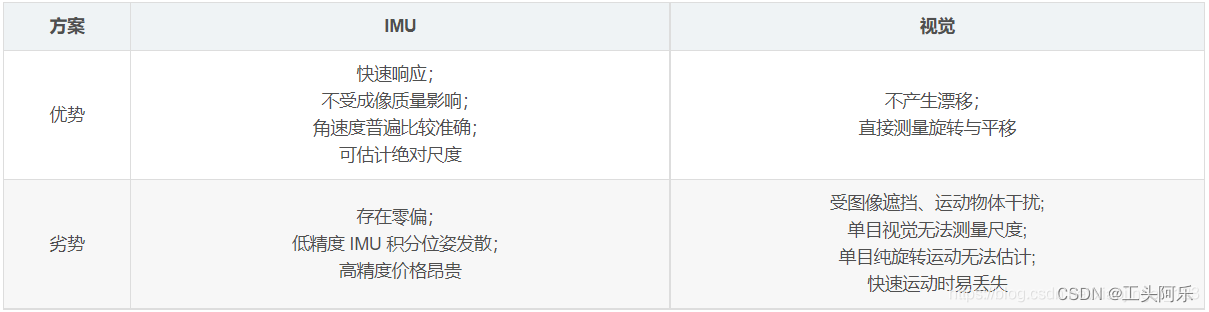
1)单纯视觉:缺点: 尺度不确定性、单目纯旋转无法估计、快速运动易丢失、受图像遮挡运动物体干扰。
优点:不产生漂移、直接测量旋转与平移。
2)单纯IMU:缺点:零偏导致漂移、低精度IMU积分位姿发散
优点:快速响应、可估计绝对尺度、角速度估计准确。
3)结合视觉+IMU:可用视觉弥补IMU的零偏,减少IMU由于零偏导致的发散和累计误差,IMU可为视觉提供快速响应的定位。
融合方案:
松耦合:将 IMU 定位与视觉的位姿直接后处理融合,融合过程对二者本身不产生影响,典型方案为卡尔曼滤波器
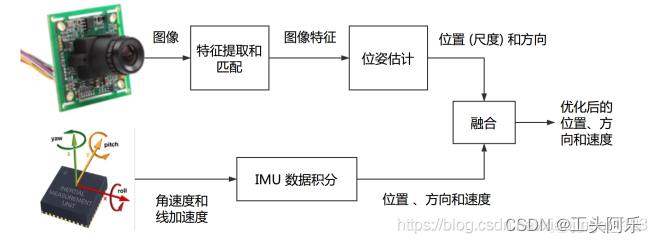
紧耦合:融合过程本身会影响视觉和 IMU 中的参数(如 IMU 的零偏和视觉的尺度)典型方案为 MSCKF 和非线性优化。
1、IMU虽然可以测得角速度和加速度,但这些量都存在明显的漂移(Drift),使得积分两次得到的位姿数据非常不可靠。好比说,我们将IMU放在桌上不动,用它的读数积分得到的位姿也会漂出十万八千里。但是,对于短时间内的快速运动,IMU能够提供一些较好的估计。这正是相机的弱点。当运动过快时,(卷帘快门的)相机会出现运动模糊,或者两帧之间重叠区域太少以至于无法进行特征匹配,所以纯视觉SLAM非常害怕快速的运动。而有了IMU,即370第14讲SLAM:现在与未来使在相机数据无效的那段时间内,我们还能保持一个较好的位姿估计,这是纯视觉SLAM无法做到的。
2、相比于IMU,相机数据基本不会有漂移。如果相机放在原地固定不动,那么(在静态场景下)视觉SLAM的位姿估计也是固定不动的。所以,相机数据可以有效地估计并修正IMU读数中的漂移,使得在慢速运动后的位姿估计依然有效。
3、当图像发生变化时,本质上我们没法知道是相机自身发生了运动,还是外界条件发生了变化,所以纯视觉SLAM难以处理动态的障碍物。而IMU能够感受到自己的运动信息,从某种程度上减轻动态物体的影响。
总而言之,我们看到IMU为快速运动提供了较好的解决方式,而相机又能在慢速运动下解决IMU的漂移问题——在这个意义下,它们二者是互补的。
整体上,视觉和 IMU 定位方案存在一定互补性质:
• IMU 适合计算短时间、快速的运动;
• 视觉适合计算长时间、慢速的运动。
视觉与IMU融合之后会弥补各自的劣势,可利用视觉定位信息来减少IMU由零偏导致的发散和累积误差;IMU可以为视觉提供快速运动时的定位,减少因为外界影响定位失败,同时有效解决单目尺度不可观测的问题