背景
在Spark中python和jvm的通信杂谈–ArrowConverter中,我们提到Spark 3.4.x中是Client和Server之间的数据传输是采用Arrow IPC的,那具体是怎么实现的呢?
分析
直接上代码ClientE2ETestSuite
test("createDataFrame from complex type schema") {
val schema = new StructType()
.add(
"c1",
new StructType()
.add("c1-1", StringType)
.add("c1-2", StringType))
val data = Seq(Row(Row(null, "a2")), Row(Row("b1", "b2")), Row(null))
val result = spark.createDataFrame(data.asJava, schema).collect()
assert(result === data)
}
- 涉及到Client和Server交互的语句就是val result = spark.createDataFrame(data.asJava, schema).collect(),
其中createDataFrame如下:
def createDataFrame(rows: java.util.List[Row], schema: StructType): DataFrame = {
createDataset(RowEncoder.encoderFor(schema), rows.iterator().asScala).toDF()
}
...
def toDF(): DataFrame = new Dataset(sparkSession, plan, UnboundRowEncoder)
createDataFrame就是把data转换为Arrow IPC Stream,具体的方法为:
ConvertToArrow
def apply[T](
encoder: AgnosticEncoder[T],
data: Iterator[T],
timeZoneId: String,
bufferAllocator: BufferAllocator): ByteString = {
val arrowSchema = ArrowUtils.toArrowSchema(encoder.schema, timeZoneId)
val root = VectorSchemaRoot.create(arrowSchema, bufferAllocator)
val writer: ArrowWriter = ArrowWriter.create(root)
val unloader = new VectorUnloader(root)
val bytes = ByteString.newOutput()
val channel = new WriteChannel(Channels.newChannel(bytes))
try {
// Convert and write the data to the vector root.
val serializer = ExpressionEncoder(encoder).createSerializer()
data.foreach(o => writer.write(serializer(o)))
writer.finish()
// Write the IPC Stream
MessageSerializer.serialize(channel, root.getSchema)
val batch = unloader.getRecordBatch
try MessageSerializer.serialize(channel, batch)
finally {
batch.close()
}
ArrowStreamWriter.writeEndOfStream(channel, IpcOption.DEFAULT)
// Done
bytes.toByteString
} finally {
root.close()
}
}
这里的逻辑就是转换为Arrow IPC格式的字节流
注意这里涉及到的DataFrame,Dataset不是sql/core下的数据类型,而是connector/client下的新的数据结构。
这里的collect方法如下:
def collect(): Array[T] = withResult { result =>
result.toArray
}
...
private[sql] def withResult[E](f: SparkResult[T] => E): E = {
val result = collectResult()
try f(result)
finally {
result.close()
}
}
...
def collectResult(): SparkResult[T] = sparkSession.execute(plan, encoder)
- 其中withResult中下的collectResult是向Server端执行Plan,并返回结果
- toArray如下:
def toArray: Array[T] = { val result = encoder.clsTag.newArray(length) val rows = iterator var i = 0 while (rows.hasNext) { result(i) = rows.next() assert(i < numRecords) i += 1 } result }- 其中iterator就是调用processResponses方法,该processResponses方法就是把Arrow序列字节流转换为ColumnarBatch[Array[ArrowColumnVector]],和ArrowConverters.fromBatchIterator一样。
- 剩下的result(i)=rows.next就是迭代返回数据
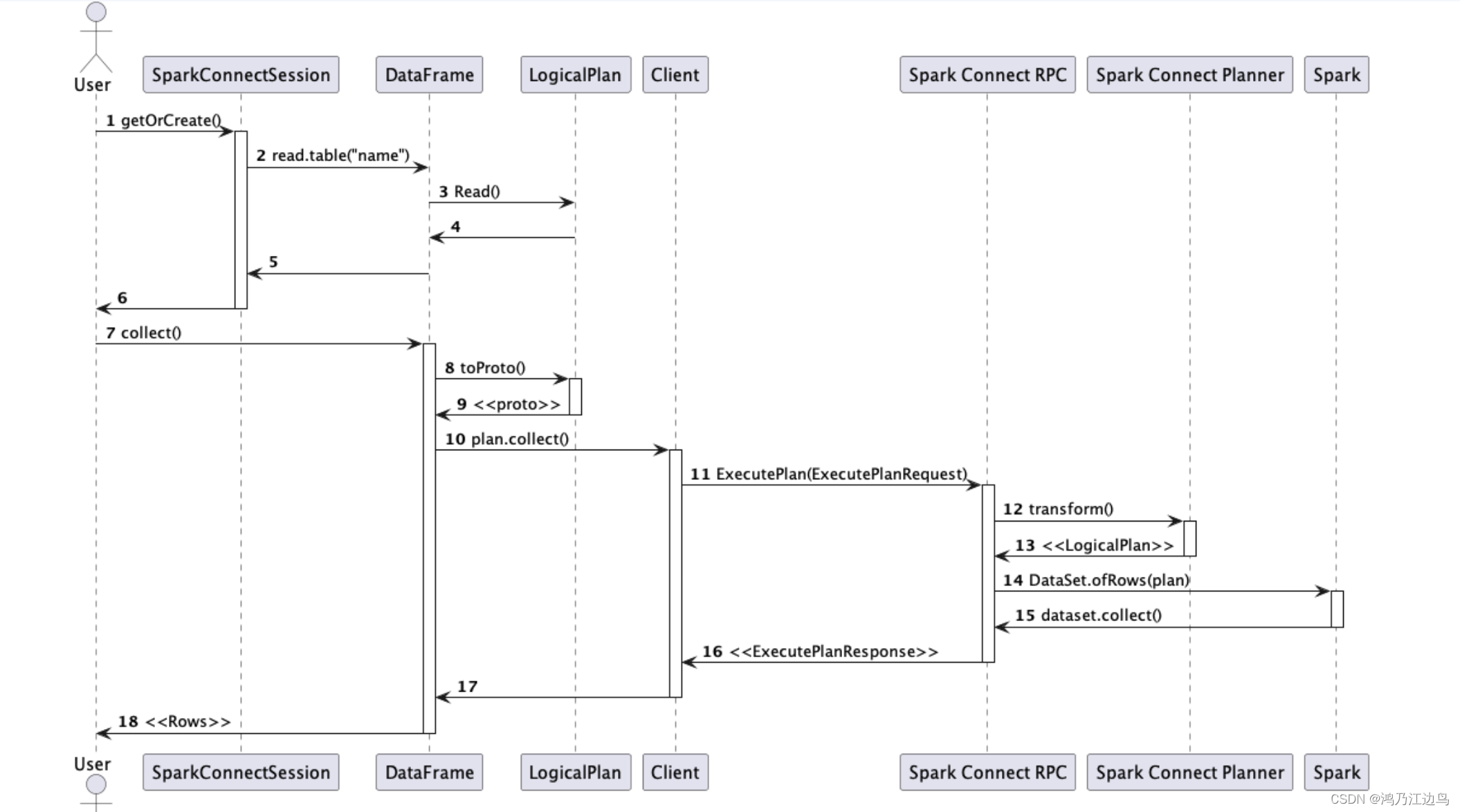
整体的更加可以参考High-Level-Design Spark Connect中的交互图: