背景
本文基于
spark 3.1.1
delta 1.0.0
目前在我们公司遇到了一个任务写delta(主要是的upsert操作),写入的时间超过了6个小时,该spark主要的做的事情是:
- 一行数据变几百行
- 开窗函数去重
- 调用pivot函数 行列的转换,该转换以后会存在好多列存在null的情况,导致数据很稀疏
在通过对delta的upsert操作的分析,以及调优后,运行时间直接减少到1.2个小时
分析
上述delta的upsert的操作主要是通过Upsert into a table using merge
实现的,该操作的的具体实现,可以参考delta的MergeIntoCommand的run方法,该方法主要的运行计划如下:
SerializeFromObject [if (assertnotnull(input[0, org.apache.spark.sql.Row, true]).isNullAt) null else staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 0, id), StringType), true, false) AS id#5450,
+- MapPartitions org.apache.spark.sql.delta.commands.MergeIntoCommand$$Lambda$4784/570959825@527325c8, obj#5449: org.apache.spark.sql.Row
+- DeserializeToObject createexternalrow(id#686.toString, a#716.toString, b#718.toString, c#720.toString, d#722.toString, e#724.toString, f#726.toString, g#728.toString, realti
+- Join FullOuter, (id#686 = id#768)
:- Project [id#686, a#716, b#718, c#720, d#722, e#724, f#726, g#728, realtime_finish_albums#730, h#732, i#734, today_hot_inter
: +- Aggregate [id#686], [id#686, first(if ((column#687 <=> a)) value#688 else null, true) AS a#716, first(if ((column#687 <=> b)) value#688 else null, true) AS b#718, first(if ((column#687 <=> c)) value#688 else null,
: +- Project [id#686, column#687, value#688]
: +- Filter (isnotnull(rk#702) AND (rk#702 = 1))
: +- Window [row_number() windowspecdefinition(id#686, column#687, ts#689L DESC NULLS LAST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#702], [id#686, column#687], [ts#689L DESC NULLS LAST]
: +- Project [id#686, column#687, value#688, ts#689L]
! : +- SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, DeltaInfo, true])).id, true, false) AS id#686, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, k
: +- ExternalRDD [obj#685]
+- Project [id#768, baby_birthday#769, w#770, s#771, j#772, k#773, l#774, m#775, n#776, o#777, p#778, q#779, x#780, y#781, z#782, h_la
+- Relation[id#768,baby_birthday#769,w#770,s#771,j#772,k#773,l#774,m#775,n#776,o#777,p#778,q#779,x#780,y#781,z#782,h_last
对应的物理执行图为:
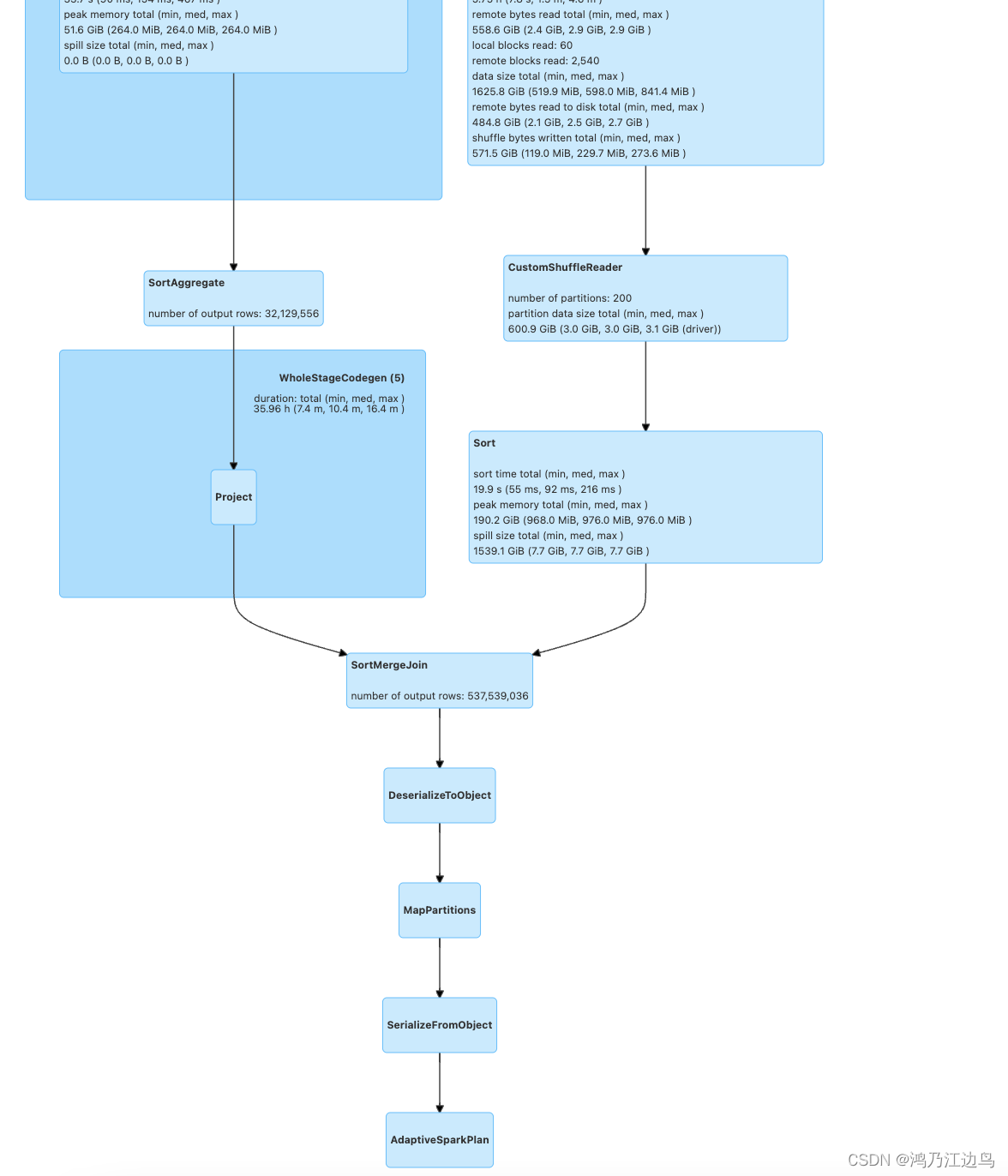
可以看到SerializeFromObject中会有很多staticinvoke的计划,该计划的代码如下:
case class StaticInvoke(
staticObject: Class[_],
dataType: DataType,
functionName: String,
arguments: Seq[Expression] = Nil,
propagateNull: Boolean = true,
returnNullable: Boolean = true) extends InvokeLike {
override def eval(input: InternalRow): Any = {
invoke(null, method, arguments, input, dataType)
}
def invoke(
obj: Any,
method: Method,
arguments: Seq[Expression],
input: InternalRow,
dataType: DataType): Any = {
val args = arguments.map(e => e.eval(input).asInstanceOf[Object])
if (needNullCheck && args.exists(_ == null)) {
// return null if one of arguments is null
null
} else {
val ret = method.invoke(obj, args: _*)
val boxedClass = ScalaReflection.typeBoxedJavaMapping.get(dataType)
if (boxedClass.isDefined) {
boxedClass.get.cast(ret)
} else {
ret
}
}
}
}
也就是说StaticInvoke最终会调用反射去获取字段,要知道反射是比较消耗时间的,要知道我们现在是有1000多个字段,如果每一行都会被反射1000次,再加上几十亿行的数据,这个计算速度肯定是比较慢的,而且为了达到更新的效果,我们还调用了coalease操作,这又增加了cpu的计算(1000多次)
这里关键的一点是:
// delta的MergeIntoCommand方法:
val outputDF =
Dataset.ofRows(spark, joinedPlan).mapPartitions(processor.processPartition)(outputRowEncoder)
mapPartitions的方法会构造一个:
DeserializeToObject
||
\/
MapPartitions
||
\/
SerializeFromObject
的计划,而这种用到的输入反序列化和输出序列化的分别用的是Schema为joinedPlan.schema的RowEncoder和 Schema为delta schema的RowEncoder,
而输出的schema是structstring:string的数据结构,所以调用序列化的方式为通过反射实现。
这种DeserializeToObject和SerializeFromObject的操作是为了在ROW和InternalRow做转换操作
优化
所以我们从以下两个方面进行优化:
- merge into update的时候,会把所有字段(1000多个字段),做 coalease 操作,增加了cpu的消耗。
改成只更新有更新的字段,主要是调用pivot的重载函数
这里让spark自行推断schema,之后在update的时候只set该schema的字段,其他的字段不变def pivot(pivotColumn: String): RelationalGroupedDataset = pivot(Column(pivotColumn)) - 写入delta的时候 SerializeFromObject 涉及到 staticinvoke 的操作(这里会用反射进行调用,比较耗时)
分拆成多个表,这样每个表相对于原表只有很少的一部分的字段,这样每一行数据的反射调用就少了很多 - 如果可以更改字段类型,更改为原子类型,这样就不会用反射的方式进行调用