概念区分
什么是关系型数据库
关系型数据库(Relational Database)是一种基于关系模型的数据库管理系统(DBMS)。在关系型数据库中,数据以表格的形式存储,表格由行和列组成,行表示数据记录,列表示数据字段。每个表格都有一个唯一的标识符,称为主键,用于唯一标识表中的每一行。
关系型数据库的核心概念包括:
-
表格(Table):数据以表格的形式组织,每个表格具有名称和一组定义了数据类型的列。表格表示实体(如人、物、事件等)以及实体之间的关系。
-
行(Row):表格中的每一行代表一个数据记录,包含了不同字段的数据值。
-
列(Column):表格中的每一列代表一个数据字段,定义了数据的类型和格式。
-
主键(Primary Key):每个表格都有一个主键,用于唯一标识表中的每一行。主键确保数据的唯一性和完整性。
-
外键(Foreign Key):外键用于在不同表格之间建立关联,表示表格之间的关系。外键通常引用其他表格的主键。
-
SQL(Structured Query Language):关系型数据库使用SQL来进行数据查询、插入、更新和删除操作。SQL是一种标准化的查询语言,用于与关系型数据库交互。
关系型数据库的一些常见示例包括:
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
- SQLite
关系型数据库以其结构化的数据模型和广泛的应用领域而闻名。它们适用于需要复杂数据关系和丰富查询的应用,如企业应用、金融系统、人力资源管理等。然而,随着数据的不断增长和应用场景的多样化,出现了许多其他类型的数据库,如NoSQL数据库,用于处理非结构化和半结构化数据,而且本文讲到的MongoDB就属于非关系型数据库,也是改文章的主角。
什么是非关系型数据库
非关系型数据库(NoSQL,Not Only SQL)是一类数据库管理系统(DBMS),与传统的关系型数据库相比,它们采用不同的数据模型和存储机制。非关系型数据库适用于处理大规模、高度分布式、非结构化或半结构化数据,以及需要更高的可扩展性和灵活性的应用场景。
非关系型数据库的主要特点包括:
-
数据模型多样性:非关系型数据库支持多种数据模型,例如键值对、文档、列族、图形等,以适应不同类型的数据。
-
分布式架构:许多非关系型数据库具有分布式架构,可以水平扩展,将数据分布在多台服务器上,以实现高可用性和更好的性能。
-
灵活的模式:非关系型数据库通常不需要严格的表结构定义,允许在数据存储过程中动态添加、修改字段,从而适应数据模式的变化。
-
高可扩展性:由于其分布式性质,非关系型数据库能够轻松地扩展以处理大量数据和高并发请求。
-
适应大数据:非关系型数据库通常用于存储和处理大规模的数据,如社交媒体数据、日志文件、传感器数据等。
常见的非关系型数据库类型包括:
-
键值存储(Key-Value Stores):数据以键值对的形式存储,适用于高速读写操作,如Redis、Amazon DynamoDB。
-
文档数据库(Document Stores):数据以类似JSON或XML格式的文档存储,适用于半结构化数据,如MongoDB、Couchbase。
-
列族数据库(Column Family Stores):数据以列族的形式存储,适用于大规模分布式数据,如Apache Cassandra、HBase。
-
图形数据库(Graph Databases):用于存储和查询图形数据,适用于复杂的数据关系,如Neo4j、Amazon Neptune。
-
时间序列数据库(Time Series Databases):专门用于存储时间序列数据,如传感器数据、日志数据等,如InfluxDB、OpenTSDB。
-
搜索引擎(Search Engines):用于全文搜索和数据分析,如Elasticsearch、Solr。
非关系型数据库在现代应用开发中变得越来越重要,特别是在大数据、云计算和分布式系统领域,此次之所以介绍MongoDB数据库,也是由于系统开发需求中要求对于聊天记录做到保存,鉴于数据量较大,所以考虑到了MongoDB架构。
主角MongoDB介绍
MongoDB是一种开源、面向文档的非关系型数据库管理系统(NoSQL DBMS),它以其灵活性、可扩展性和强大的查询能力而闻名。MongoDB的设计理念是为了满足现代应用中海量数据、高可用性和复杂数据模型的需求。以下是MongoDB的一些重要特点和概念:
-
文档数据库:MongoDB使用文档(Document)来表示数据,文档类似于JSON格式的数据结构,可以包含各种类型的数据,如字符串、数字、日期、数组和嵌套文档等。
-
面向文档:MongoDB是一种面向文档的数据库,每个文档都有一个唯一的标识符(通常称为_id),用于唯一标识文档。
-
高可扩展性:MongoDB支持水平扩展,可以通过分片(Sharding)将数据分布到多台服务器上,以实现更高的存储容量和性能。
-
动态模式:MongoDB不需要严格的表结构定义,文档可以自由添加和修改字段,适应数据模式的变化。
-
强大的查询语言:MongoDB支持丰富的查询语言,可以进行复杂的查询操作,包括过滤、排序、投影、聚合等。
-
索引支持:MongoDB支持各种类型的索引,包括单字段索引、复合索引、文本索引、地理空间索引等,以加速查询操作。
-
复制和高可用性:MongoDB支持数据的复制和自动故障转移,确保数据的高可用性和冗余。
-
数据存储:MongoDB将数据存储在集合(Collection)中,每个集合包含一组文档。集合类似于关系型数据库中的表格。
-
适用场景:MongoDB适用于需要存储和处理半结构化或非结构化数据的场景,如大数据、实时数据分析、内容管理系统、日志记录和用户个性化推荐等。
MongoDB安装介绍
Centos安装MongoDB
以下是在CentOS上安装MongoDB的详细步骤:
- 更新系统:
打开终端,并以root或具有sudo权限的用户身份登录,首先更新系统软件包以确保系统处于最新状态:
sudo yum update
- 添加MongoDB仓库:
MongoDB提供了官方的YUM仓库,可以使用以下步骤将其添加到您的系统中:
sudo vi /etc/yum.repos.d/mongodb-org.repo
在编辑器中,添加以下内容(保存并退出编辑器):
[mongodb-org-4.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc
- 安装MongoDB:
使用以下命令安装MongoDB软件包:
sudo yum install -y mongodb-org
- 启动MongoDB服务:
安装完成后,您可以启动MongoDB服务,并设置其开机自启动:
sudo systemctl start mongod
sudo systemctl enable mongod
- 验证MongoDB是否已正确启动:
运行以下命令来验证MongoDB是否已成功启动:
sudo systemctl status mongod
您应该看到MongoDB服务状态为"active (running)"。
- 连接到MongoDB Shell:
使用MongoDB Shell与数据库交互,运行以下命令:
mongo
这将连接到本地MongoDB服务器的Shell。
docker安装MongoDB
大家知道我的习惯,肯定少不了docker的安装方式啊
安装MongoDB并在Docker容器中运行它是一个方便的方式,让我们详细介绍一下如何在Docker中安装和运行MongoDB。
-
安装Docker:
如果您尚未安装Docker,请按照以下步骤在您的操作系统上安装Docker:
- 对于Linux用户,您可以根据您的发行版选择适当的安装方式,通常是使用包管理工具(如
apt或yum)来安装Docker。 - 对于Windows用户,您可以从Docker官方网站下载并运行安装程序。
- 对于macOS用户,您可以从Docker官方网站下载并运行Docker Desktop安装程序。
- 对于Linux用户,您可以根据您的发行版选择适当的安装方式,通常是使用包管理工具(如
-
拉取MongoDB镜像:
打开终端(或命令行界面)并执行以下命令,以从Docker Hub拉取MongoDB官方镜像:
docker pull mongo -
运行MongoDB容器:
使用以下命令来创建并运行MongoDB容器。这将创建一个名为"my-mongodb"的MongoDB容器,并将其绑定到主机的27017端口。可以根据需要自行调整容器名称和端口绑定。
docker run --name my-mongodb -p 27017:27017 -d mongo此命令将以后台模式运行MongoDB容器。要停止容器,可以使用
docker stop命令:docker stop my-mongodb要删除容器,可以使用
docker rm命令:docker rm my-mongodb -
连接到MongoDB容器:
要连接到运行中的MongoDB容器的Mongo shell,可以使用以下命令:
docker exec -it my-mongodb mongo这将进入Mongo shell,可以在其中执行MongoDB命令。
Win系统安装MongoDB
要在Windows系统上安装MongoDB,请按照以下步骤操作:
-
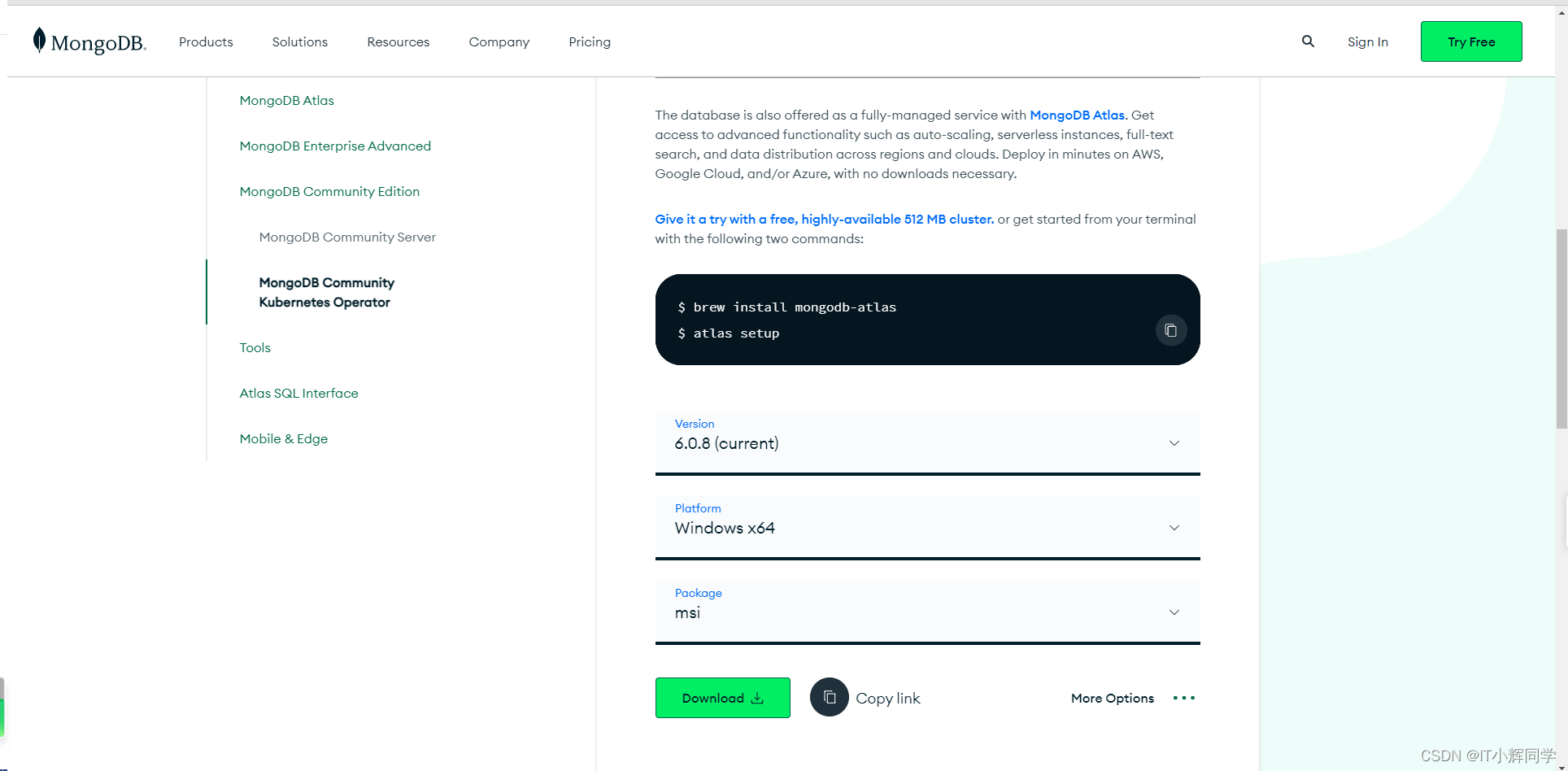
下载MongoDB安装包:
前往MongoDB官方网站(https://www.mongodb.com/try/download/community-kubernetes-operator)下载最新版本的MongoDB安装包。确保选择与您的操作系统相匹配的版本。
-
安装MongoDB:
双击下载的安装包,按照安装向导指示完成安装过程。您可以选择自定义安装选项,但对于大多数用户来说,使用默认选项即可。 -
配置MongoDB环境变量:
将MongoDB的安装路径添加到系统的环境变量中,以便在任何目录下都可以通过命令行访问MongoDB。将安装路径(默认为C:\Program Files\MongoDB\Server<版本号>\bin)添加到您的系统环境变量中的Path变量中。 -
创建数据目录:
在您选择的位置上创建一个数据目录,用于存储MongoDB的数据文件。例如,您可以在C:\data目录下创建一个名为db的文件夹。 -
配置MongoDB服务:
打开命令提示符(CMD)或PowerShell,并导航到MongoDB的安装目录(例如:C:\Program Files\MongoDB\Server<版本号>\bin)。运行以下命令来启动MongoDB服务器:
mongod --dbpath <数据目录路径>请将
<数据目录路径>替换为您在第4步中创建的数据目录的路径。 -
连接到MongoDB:
打开另一个命令提示符或PowerShell窗口,导航到MongoDB的安装目录(例如:C:\Program Files\MongoDB\Server<版本号>\bin)。运行以下命令来连接到MongoDB:
mongo
请注意,如果不按照如上步骤操作,而是直接在安装目录执行exe

那就需要再D盘根路径创建一个/data/db目录,否则会闪退!!!

MongoDB是默认没有写入环境变量的,大家需要自己配置,不再赘述!!!
MongoDB使用介绍
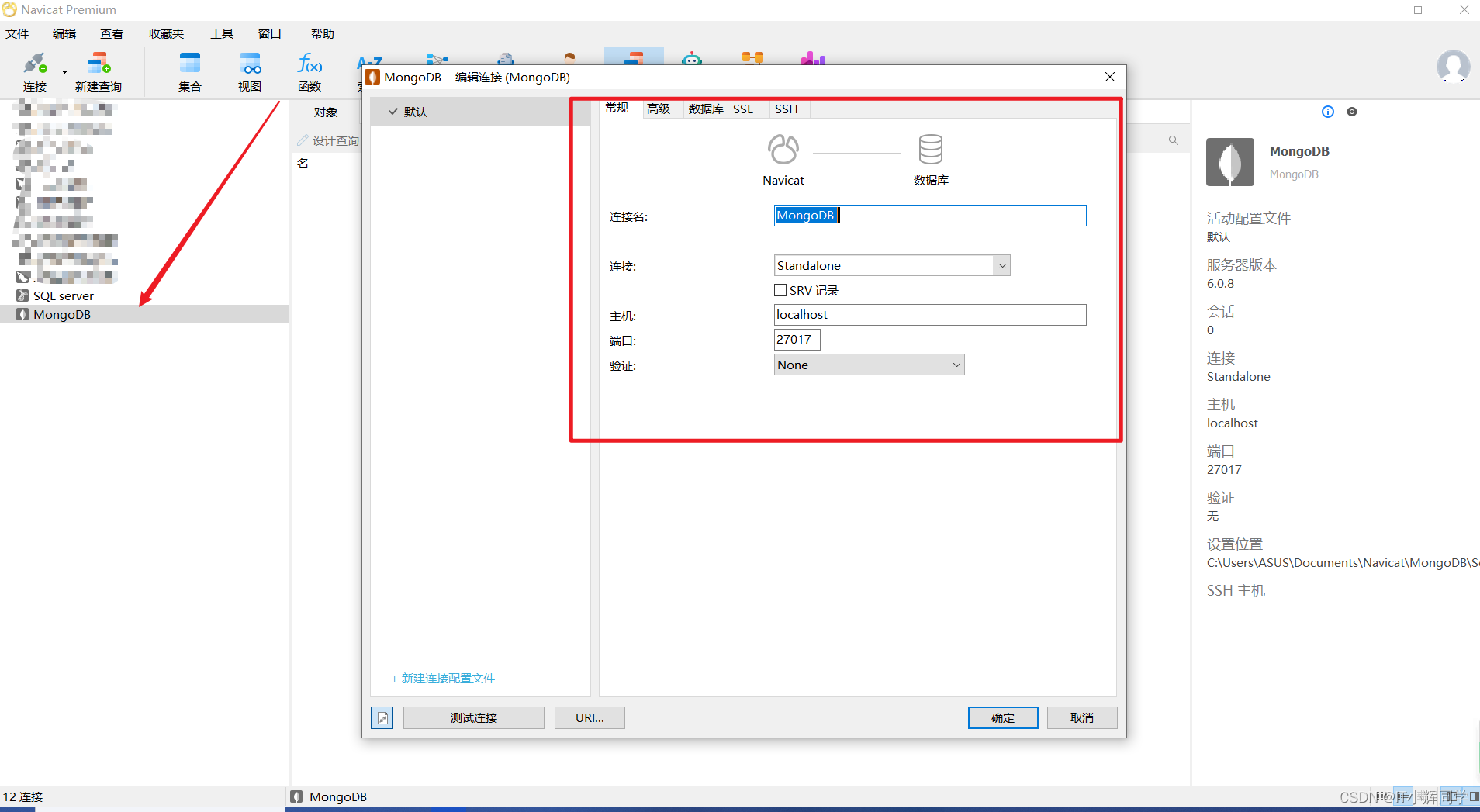
在MongoDB中,建立集合(类似于关系型数据库中的表)是动态的,因此无需像关系型数据库那样显式地定义表结构。只需插入文档(类似于关系型数据库中的记录),MongoDB将自动创建集合并根据文档的结构来定义字段。命令执行我们可以使用Navicat工具进行连接
以下是MongoDB中创建集合和插入文档的语法和示例:
简单使用
- 创建集合并插入文档:
// 使用insertOne插入文档并创建集合
db.collectionName.insertOne({
field1: "value1", field2: "value2", ... })
示例:
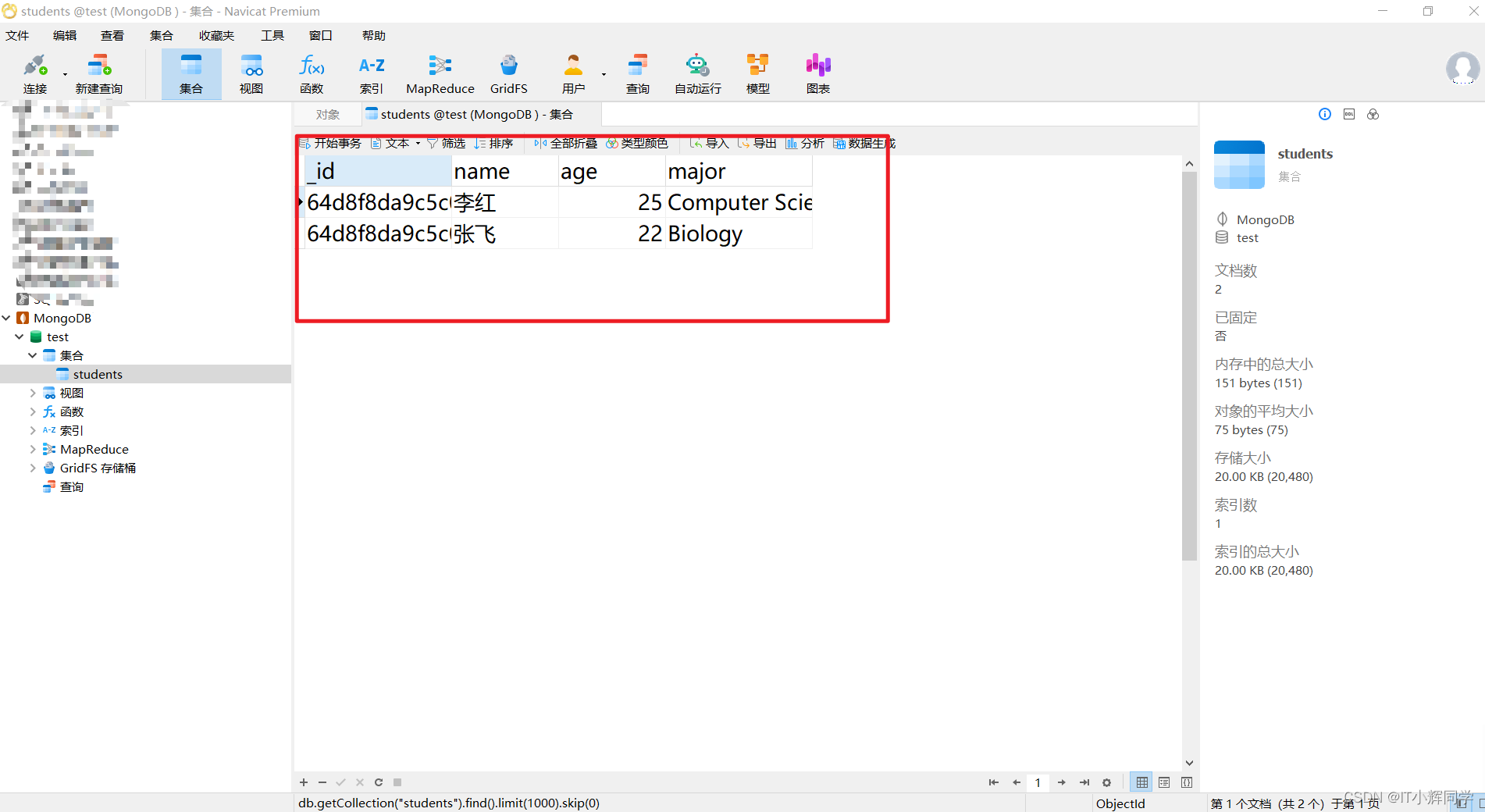
db.students.insertOne({
name: "李红", age: 25, major: "Computer Science" })
db.students.insertOne({
name: "张飞", age: 22, major: "Biology" })
- 查询集合中的文档:
// 查询集合中的所有文档
db.collectionName.find()
// 查询特定条件的文档
db.collectionName.find({
field: "value" })
示例:
// 查询所有学生
db.students.find()
// 查询年龄大于等于 25 岁的学生
db.students.find({
age: {
$gte: 25 } })
- 更新文档:
// 使用updateOne更新单个文档
db.collectionName.updateOne({
condition }, {
$set: {
field: "new value" } })
// 使用updateMany更新多个文档
db.collectionName.updateMany({
condition }, {
$set: {
field: "new value" } })
示例:
// 更新学生的专业
db.students.updateOne({
name: "张飞" }, {
$set: {
major: "Engineering" } })
- 删除文档:
// 使用deleteOne删除单个文档
db.collectionName.deleteOne({
condition })
// 使用deleteMany删除多个文档
db.collectionName.deleteMany({
condition })
示例:
// 删除专业为"Biology"的学生
db.students.deleteMany({
major: "Biology" })
我们再举一个例子,假设正在开发一个简单的博客平台,可以使用MongoDB来存储博客帖子和评论。在这个复杂业务的示例中,我们将涵盖以下方面:
- 创建集合和插入文档
- 查询和筛选数据
- 更新文档
- 使用索引
1. 创建集合和插入文档:
首先,我们创建一个集合来存储博客帖子,每个帖子包含标题、内容和发布日期:
// 创建博客集合并插入帖子文档
db.blogPosts.insertOne({
title: "MongoDB的相关介绍 ——IT小辉同学",
content: "MongoDB 是一个非关系型数据库",
publishDate: new Date("2023-08-01"),
comments: []
})
2. 查询和筛选数据:
现在,我们查询博客集合中的帖子并筛选出发布日期在特定范围内的帖子:
// 查询发布日期在特定范围内的帖子
db.blogPosts.find({
publishDate: {
$gte: new Date("2023-08-01"), $lt: new Date("2023-08-10") }
})
3. 更新文档:
假设一篇帖子收到了一条新评论,我们可以将评论添加到帖子的评论数组中:
// 更新帖子,添加新评论
db.blogPosts.updateOne(
{
title: "MongoDB的相关介绍,很有意思奥 ——IT小辉同学" },
{
$push: {
comments: {
author: "User123",
text: "MongoDB,我们一起学习!",
timestamp: new Date()
}
}
}
)
4. 使用索引:
为了提高查询性能,我们可以创建索引以加速某些查询操作。例如,为了加速根据标题搜索帖子的查询,我们可以创建标题字段的索引:
// 创建标题字段的索引
db.blogPosts.createIndex({
title: "text" })
这是一个简化的示例,展示了如何在MongoDB中处理博客帖子和评论的复杂业务场景。实际业务中可能还需要处理更多情况,如用户认证、数据验证、用户关系等。MongoDB的灵活性和功能可以适应各种复杂的业务需求。
请注意,MongoDB的语法使用了JSON,也就是我们Java常说的对象,因此数据和查询都是使用JSON的形式。
复杂语法
当您需要进行更复杂的增删改查操作时,MongoDB提供了丰富的查询、更新和聚合功能来满足您的需求。以下是更复杂的示例,涵盖了多条件查询、更新和聚合操作:
1. 多条件查询:
假设您要查询发布日期在特定范围内,同时标题包含特定关键词的帖子:
db.blogPosts.find({
publishDate: {
$gte: new Date("2023-08-01"), $lt: new Date("2023-08-10") },
title: {
$regex: "MongoDB" }
})
2. 多条件更新:
更新帖子的评论,将指定作者的所有评论中的文本替换为新文本:
db.blogPosts.updateMany(
{
"comments.author": "User123" },
{
$set: {
"comments.$[].text": "新文本" } }
)
3. 使用聚合:
聚合操作允许您进行数据处理和转换。假设您要计算每篇帖子的评论数量并按评论数量降序排序:
db.blogPosts.aggregate([
{
$project: {
title: 1,
numberOfComments: {
$size: "$comments" }
}
},
{
$sort: {
numberOfComments: -1 }
}
])
以上代码使用聚合管道,首先通过$project将每篇帖子的标题和评论数量提取出来,然后通过$sort按评论数量降序排序。
4. 删除多个文档:
假设您要删除评论数低于指定值的所有帖子:
db.blogPosts.deleteMany({
comments: {
$size: {
$lt: 5 } }
})
这将删除所有评论数少于5条的帖子。