1 基本概念

2 Cache工作原理
在cache存储系统中,把cache和主存储器都划分成相同大小的块。
主存地址由块号B和块内地址W两部分组成,cache地址由块号b和块内地址w组成。
当CPU访问cache时,CPU送来主存地址,放到主存地址寄存器中,通过地址变换部件把主存地址中的块号B变换成cache的块号b,并放到cache地址寄存器中,同时将主存地址中的块内地址W直接作为cache的块内地址w装入cache地址寄存器中,如果变换成功(又叫cache命中),就用得到的cache地址去访问cache,从cache中取出数据送到CPU中;
如果变换不成功(cache不命中),则产生cache失效信息,并且用主存地址访问主存储器,从主存储器中读出一个字送往CPU,同时把包含该字在内的一整块数据都从主存储器读出来装入cache,这时,如果cache已经满了,则要采用某种cache替换策略把不常用的块先调出到主存储中相应的块中,以便腾出空间来存放新调入的块。
由于程序具有局部性特点,每次块失效时都把一块(由多个字组成)调入到cache中,能够提高cache的命中率。
3 Cache地址映射和变换方法
地址的映射和变换是密切相关的,采用什么样的地址映射方法就必然有与这种映射方法相对应的地址变换方法。
无论采用什么样的地址映射方式和地址变换方式,都要把主存和cache划分成同样大小的存储单位,每个存储单位成为“块”,在进行地址映射和变换时,都是以块为单位进行的。常用的映射方式和变换方式有以下3种:
- ■ 全相联映射方式
主存中任意一块可以映射到cache中的任意一块上。 - ■ 直接映射方式
主存中一块只能映射到cache中的一个特定块上,假定主存的块号为B,cache的块号为b,cache的总块数为Cb,则它们之间的映射关系可以用下面的公式表示:
b = B mode Cb - ■ 组相连映射方式
在这种相联的地址映射和变换方式中,把主存和cache按同样大小划分成组(set),每个组都由相同块数组成。
从主存的组到cache的组之间采用直接映射方式,在主存中的组与cache中的组之间建立好映射关系之后,在两个对应的组内部采用全相联的映射方式。
在ARM处理器中,主存与cache采用组相联地址映射和变换方式,如果cache的块大小为2L,则同一块中各地址的bit[31:L]是相同的。
如果cache中组的大小(每组中包含的块数)为2S,
则虚拟地址的bit[L+S-1:L]用于选择cache中的某个组,
而虚拟地址中其他位[31:L+S]包含了一些标志。
将cache每组中的块数称为组容量(set-associativity),当组容量等于cache中的总块数时,对应的映射方式为全相联映射方式;

当组容量等于1时,对应的映射方式为直接映射方式;
当组容量为其他值时,称为组相联映射方式。
在组相联映射方式中,cache的大小CACHE_SIZE(字节数)可以通过下面的公式来计算:
CACHE_SIZE = LINELEN*ASSOCIATIVITY*NSETS
其中,
- LINELEN为cache块(line)大小;
- ASSOCIATIVITY为组容量;
- NSETS为cache的组数。
4 Cache分类
根据不同的分类标准可以按以下3种方法对Cache进行分类。
- 1)数据cache和指令cache
- ● 指令cache:指令预取时使用的cache。
- ● 数据cache:数据读写时使用的cache。
如果一个存储系统中指令cache和数据cache是同一个cache,称系统使用了统一的cache。反之,如果是分开的,那么称系统使用了独立的cache;如果系统中只包含指令cache或者数据cache,那么在配制系统时可以作为独立的cache使用了。
使用独立的数据cache和指令cache,可以在同一个时钟周期中读取指令和数据,而不需要双端口的cache,但这时候要注意保证指令和数据的一致性。
-
2)写通(write-through)cache和写回(write-back)cache
-
● 写回cache
CPU在执行写操作时,被写的数据只写入cache,不写入主存,仅当需要替换时,才把已经修改的cache块写回到主存中,在采用这种更新算法的cache快表中,一般有一个修改位,当一块中的任何一个单元被修改时,这一块的修改位被设置为1,否则这一块的修改位仍保持为0;
在需要替换这一块时,如果对应的修改位为1,则必须先把这一块写到主存中去之后,才能调入新的块,否则,只要用新调入的块覆盖该块即可。 -
● 写通cache
CPU在执行写操作时,必须把数据同时写入cache和主存,这样,在cache的快表中就不需要“修改位”,
当某一块需要替换时,也不必把这一块写回到主存中,新调入的块可以立即把这一块覆盖掉。
-
写回cache和写通cache的优缺点比较如下表所示。

-
3)读时分配(read-allocate)cache和写时分配(write-allocate)cache
- ● 读时分配cache
当进行数据写操作时,如果cache没命中,只是简单地将数据写入主存中,主要在数据读取时,才进行cache内容预取。
- ● 写时分配cache
当进行数据写操作时,如果cache未命中,cache系统将会进行cache内容预取,从主存中将相应的块读取到cache中相应的位置,并执行写操作,把数据写入到cache中。对于写通类型的cache,数据将会同时写入到主存中,对于写回类型的cache,数据将在合适的时候写回到主存中。
由于写操作分配cache增加了cache内容预取的次数,增加了写操作的开销,但同时可能提高cache的命中率,因此这种技术对于系统整体性能的影响与程序中读操作和写操作的数量有关。
5 Cache替换算法
随机替换算法
通过一个伪随机数发生器产生一个伪随机数,用新块编号为该伪随机数的cache块替换掉。这种算法很简单且容易实现,但没有考虑程序的局部性特点,也没有利用历史上块地址流的分布情况,因而效果较差,同时这种算法不易预测最坏情况下cache的性能。
轮转替换算法
维护一个逻辑的计数器,利用该计数器依次选择将要被替换出去的cache块。这种算法容易预测在最坏情况下cache的性能。但在程序发生很小的变化时,可能造成cache平均性能的急剧变化,这是它的一个明显缺点。
6 Cache内容锁定
“锁定”在cache中的块在常规的cache替换操作中不会被替换,但当通过C7控制cache中特定的块时,比如使某特定的块无效时,这些被“锁定”在cache中的块也将受到相应的影响。
用LINELEN表示cache的块大小,用ASSOCIATIVITY表示每个cache组中的块数,用NSETS表示cache中的组数。
cache的“锁定”是以锁定块(lockdown block)为单位进行的。每个锁定块中包括cache中每个组中各一个块,这样cache中最多可有ASSOCIATIVITY个锁定块,编号为0~ASSOCIATIVITY-1。
其中编号为0的锁定块中包含cache组0中的0号块、组1中的0号块,一直到ASSOCIATIVITY-1中的0号块。
“N锁定块被锁定”是指编号为0~N-1的锁定块被锁定在cache中,
编号为N~ASSOCIATIVITY-1的锁定块可用于正常的cache替换操作。
实现N锁定块被锁定的操作步骤说明如下:
-
1)确保在整个锁定过程中不会发生异常中断,否则必须保证与该异常中断相关的代码和数据位于非缓冲(uncachable)的存储区域。
-
2)如果锁定的是指令cache或者统一的cache,必须保证锁定过程所执行的代码位于非缓冲的存储区域。
-
3)如果锁定的是数据cache或者统一的cache,必须保证锁定过程所涉及的数据位于非缓冲的存储区域。
-
4)确保将要被锁定的代码和数据位于缓冲(cachable)的存储区域。
-
5)确保将要被锁定的代码和数据尚未在cache中,可以通过使无效相应cache中的块达到这一目的。
-
6)对于I=0到N-1,重复执行下面的操作:
- a)Index=I写入CP15的C9寄存器,当使用B格式的锁定寄存器时,令L=1;
- b)在锁定块I中的各cache块内容从主存中预取到cache中,对于数据cache和统一cache可以使用LDR指令读取一个位于该块中的数据,将块预取到cache中;对于指令cache,通过操作CP15的C7寄存器,将相应的块预取到指令cache中。
-
7)将index=N写入CP15的C9寄存器,当使用B格式的锁定寄存器时,令L=0。解除N锁定块被锁定只须执行以下操作:将index=0写入CP15的C9寄存器,当使用B格式的锁定寄存器时,令L=0。
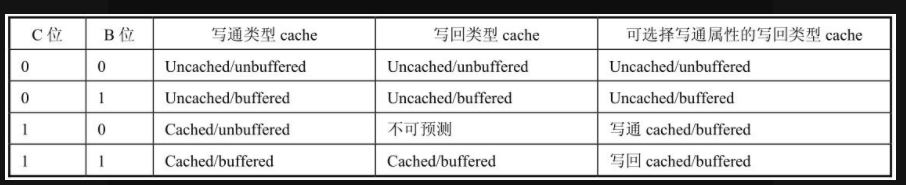
7 MMU映射描述符中B位和C位的含
8 Cache和Writer Buffer编程接口
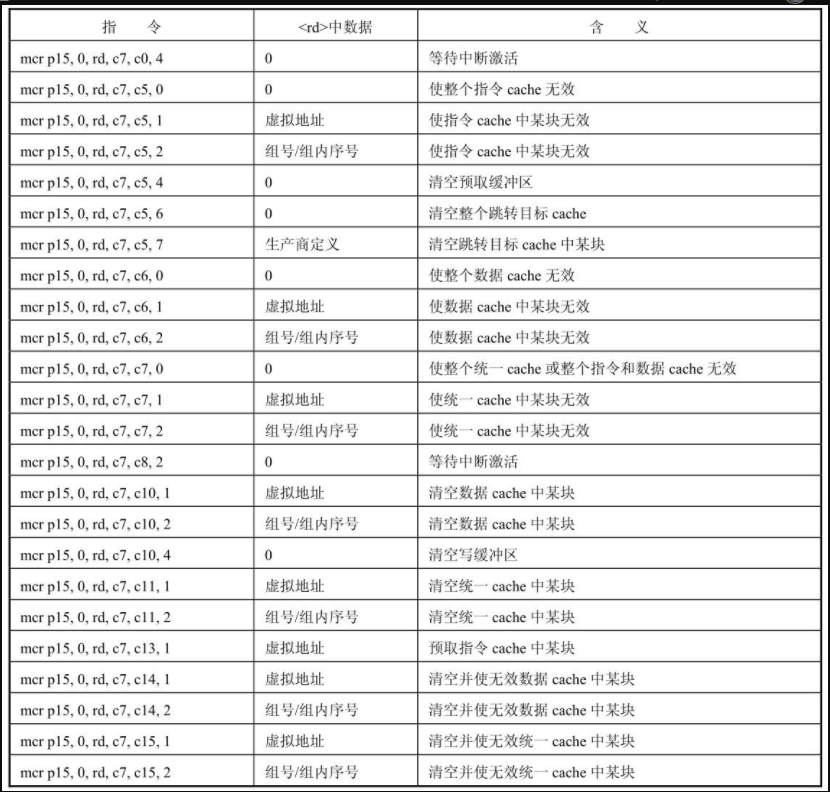
ARM处理器中的Cache和Write Buffer操作是通过写CP15的C7寄存器来实现的。访问CP15的C7寄存器的指令格式如下所示:
mcr p15, 0, <rd>, <c7>, crm, <opcode_2>
ARM处理器中的Cache和Write Buffer操作指令如下所示。
参考资料:
- 《嵌入式系统Linux内核开发实战》