目录
Python 的简介与特点
Python支持多种编程风格
Python 支持面向过程的编程风格 . 如果你熟悉 C 语言 , 那么完全可以像写 C 一样写 PythonPython 支持面向对象的编程风格 . 数字 , 字符串 , 函数 , 模块 ... 都是 " 对象 ".Python 支持函数式编程 . 其实这世界上只有两种编程语言 , C 类语言 , Lisp 类语言 . Python 也支持函数式编程.
解释运行
Python 是一种解释型的编程语言 . 和 C/C++ 不同 , 不是先将源代码文件转化成可执行文件 , 再执行 ; 而是直接由 Python解释器一行一行的读取源代码, 每读一行就执行一行 . 但严格意义上讲, Python 算是一种 " 半编译 , 半解释 " 型的语言 . 一方面 , Python 解释器会按行读取源代码文件 , 然后会先将源代码转为供Python 解释器直接执行的 " 字节码 ". 然后再执行字节码 . 例如, 我们执行一个 .py 文件之后 , 会生成一个同名的 .pyc 文件 . 这个 .pyc 文件就是 Python 解释器生成的字节码文件 . 如果已经存在了.pyc 文件 , 那么就不需要再 " 翻译 " 一次了 , 这样也提高了执行效率
跨平台
Python 是基于 Python 的解释器来进行执行 . 只要某个操作系统 / 平台上能运行 Python 解释器 , 就可以完美的运行Python 的源代码 . 主流的 Windows, Linux, Mac 等操作系统上都能够很好的支持 Python
可扩展强
Python 可以很容易的调用 C/C++ 语言 . 如果觉得哪里的逻辑性能不满足要求 , 可以用 C/C++ 重构这部分模块 , 用 Python调用.
可嵌入
Python 的代码也可以很容易的嵌入到 C/C++ 中执行
丰富的库
君子性非异也 , 善假于物也 .Python 标准库已经非常丰富强大 , 同时也有非常庞大的第三方库 . 几乎可以是上天入地 , 心随我意~
Python版本选择
Python当前主要有两个大版本分支:
Python2: 最新版本是 Python2.7.14Python3: 最新版本是 Python3.6.2Python3 虽然是 Python2 的升级版 , 但是很多语法并不兼容!关于兼容性:C++ 能非常好的兼容 C 语言 (C 语言写的代码可以直接使用 C++ 编译器进行编译 ), 但是也意味着 C++ 背负着很多C 语言的历史包袱 .但是 Python3 和 Python2 很多地方不兼容 (Python2 写的代码 , 不能很顺利的在 Python3 的解释器上执行 ).这样意味着很多已经用 Python2 写好的代码不会很顺利的升级到 Python3.但是这样也意味着 Python3 可以不用背负历史包袱 , 大刀阔斧的把一些不合理的地方修改掉 .官方的说法是 , Python2 最多维护到 2020 年便停止更新 .但是有些企业中到的 Python 版本也是 Python2.7 甚至是 Python2.6( 幸好 , Python2.7 和 2.6 差别不大 ).本主要学习的是Python3版本的内容
Python开发环境搭建
Windows/Linux: VSCode + Python 插件 ( 推荐 )Windows/Linux: PyCharm ( 推荐 )认识Python解释器
直接在命令行中敲 python 就进入了 Python 解释器 . 这时候我们看到了一个 Python 的 shell.首先 , 我们可以将这个解释器当做一个基本的计算器 .当然 , 也可以执行任意的合法 Python 语句按 ctrl + d 退出 python shell.虽然我们可以通过 Python shell 来执行一些 python 语句 , 但是更多的是将 Python 代码写到一个 .py 后缀的文件中 , 通过Python 解释器解释这个 .py 文件来执行代码
快速入门
变量和赋值
Python 中的变量不需要声明 , 直接定义即可 . 会在初始化的时候决定变量的 " 类型 "使用 = 来进行初始化和赋值操作>>> counter = 0>>> miles = 1000.0>>> name = 'Bob'>>> kilometers = 1.609 * milesPython中不支持 ++/-- 这样的操作, 只能写成>>> n += 1动态类型
同一个变量 , 可以赋值成不同的类型的值>>> a = 100>>> print a100>>> a = 'hehe'>>> print ahehe变量命名规则
变量名必须是字母 , 数字 , 下划线 . 但是不能用数字开头 ( 规则和 C 语言一样 ).变量名大小写敏感 , case 和 Case 是两个不同的变量 .认识 "数字"
Python 没有 int, float, 这样的关键字 , 但是实际上数字的类型是区分 "int" "float" 这样的类型的 . 使用内建函数 type 可以查看变量的类型 .>>> a = 1>>> type(a)<type 'int'>>>> a = 1.0>>> type(a)<type 'float'>Python 中的数字变量的取值范围 , 并没有限制 ( 完全取决于你机器的内存多大 ), 而不是像 C 语言中 int 用 4 个字节表示.Python 中还有一种 "复数" 类型 . 和数学中的 " 复数 " 是相同的概念>>> a = 10 + 5j>>> print(a)(10+5j)认识 "字符串"
Python 中可以使用 单引号 ('), 双引号 ("), 三引号 ('''/""") 来表示字符串 . 这三种字符串的区别 , 我们后面再讨论.>>> a = 'hehe'>>> b = "hehe">>> c = '''hehe'''这样的好处是如果字符串中包含了 " 这样的字符 , 就不用蹩脚的进行转义>>> a = 'My name is "tangzhong"'>>> print aMy name is "tangzhong"但是有些不可见字符 , 仍然得进行转义 , 使用 \ 进行转义 . 比如换行符 \n>>> a = 'My name is \n "tangzhong"'>>> print(a)My name is使用索引操作符 [] 或者切片操作符 [:] 来获取子字符串(切片操作是一个前闭后开区间).字符串的索引规则是: 第一个字符索引是0, 最后一个字符索引是-1(可以理解成len-1).>>> pystr = 'hehe'>>> pystr[0]'h'>>> pystr[-1]'e'>>> pystr[1:3]'eh'>>> pystr[1:-1]'eh'>>> pystr[1:]'ehe'>>> pystr[:2]'he'>>> pystr[:]'hehe'+ 用于字符串连接运算 , * 用于字符串重复>>> a = 'hehe'>>> b = 'haha'>>> c = a + b>>> print(c)hehehaha>>> d = a * 4>>> print(d)hehehehehehehehe>>> e = a * bTraceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: can't multiply sequence by non-int of type 'str'Python没有 "字符类型" 这样的概念. 单个字符也是字符串>>> a = 'hehe'>>> type(a[0])<type 'str'>用内建函数 len 获取字符串长度>>> a = 'hehe'>>> print(len(a))4格式化字符串 , 可以使用 % 这样的方式进行格式化的替换 .>>> a = 100>>> pystr = "a = %d">>> result = pystr % a>>> print(result)a = 100可以简化的写成如下方式>>>print("a = %d" % a)a = 100认识 "布尔类型"
>>> a = True>>> print aTrue>>> print(type(a))<type 'bool'>布尔类型的变量 , 也是一种特殊的整数类型 . 在和整数进行运算时 , True 被当做 1, False 被当做 0输入输出
print 函数将结果输出到标准输出 ( 显示器 ) 上 .input 函数从标准输入中获取用户输入>>> name = input('Enter name:')Enter name:aaa>>> print(name)aaainput 返回的结果只是一个字符串 . 如果需要获得一个数字 , 需要使用 int 函数把字符串转换成数字 .>>> num = input('Enter num:')Enter num:100>>> print(num + 1)Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: cannot concatenate 'str' and 'int' objects>>> print int(num) + 1101注释
Python 中使用 # 作为单行注释 . # 后面的内容都是注释的内容a = 1.0 # define aprint(type(a))使用中文注释时 , 要小心 ~~ 直接使用可能会运行报错 (Python3 目前已经没有这个问题了 , Python2 要注意)Python 的源代码默认只支持 ASCII, 所以如果要包含中文 , 需要在代码文件最开头的地方注明 # - * - coding: UTF- 8 - *-操作符
Python 中支持 + - * / % 这样的操作符 . 并且它们的行为都和 C 语言一样 ./ 是 " 精确除法 ">>> a = 1>>> b = 2>>> print(a / b)0.5// 是 " 整除 ". 会对结果进行取整>>> a = 1>>> b = 2>>> print a // b0注意 Python2 中 / 是传统除法 , // 是地板除法 , 和 Python3 的语义截然不同** 表示乘方运算 ( 记得 Python 的数据无上限 )>>> a = 100>>> b = 100>>> print a ** b100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000Python 也支持标准的比较运算符 . > < >= <= == != 这些运算符的表达式的结果 , 是一个布尔值>>> 2 < 4True>>> 2 == 4False>>> 2 > 4False>>> 2 != 4TruePython 也支持逻辑运算符 . and or not>>> 2 < 4 and 2 == 4False>>> 2 > 4 or 2 < 4True>>> not 6.2 <= 6TruePython 中 , 3 < 4 < 5 等价于 3 < 4 and 4 < 5 这一点和其他大多数编程语言都不太一样 .运算符之间有高低优先级的区分 . 应该合理使用括号来增加代码的可读性 .字符串和字符串之间也可以使用运算符进行操作 , 例如前面使用 + 进行字符串连接>>> print 'haha' + 'hehe'hahahehe字符串之间可以使用 == != 来判定字符串的内容是否相同>>> 'haha' != 'hehe'True字符串之间也可以比较大小 . 这个大小的结果取决于字符串的 " 字典序 ">>> 'haha' < 'hehe'True
作用域和生命周期
Python 中 , def, class( 我们后面会讲 ), lamda( 我们后面会讲 ) 会改变变量的作用域if, else, elif, while, for, try/except( 我们后面会讲 ) 不会改变变量的作用域for i in range(0, 10):print(i)print(i) # 即使出了 for 循环语句块 , 变量 i 仍然能访问到 i 变量 .def func():x = 1print(x)print(x) # 出了 def 的函数语句块 , 就不再能访问到 x 变量了内建函数 globals() 返回了全局作用域下都有哪些变量 , 内建函数 locals() 返回了局部作用域下都有哪些变量a = 100def Func():x = 0print(globals())print(locals())print 'In Gloabl'print(globals())print(locals())print('In Func')Func()# 执行结果In Gloabl{'a': 100, '__builtins__': <module '__builtin__' (built-in)>, '__file__': 'test.py','__package__': None, 'Func': <function Func at 0x7f9085d5b9b0>, '__name__': '__main__','__doc__': None}{'a': 100, '__builtins__': <module '__builtin__' (built-in)>, '__file__': 'test.py','__package__': None, 'Func': <function Func at 0x7f9085d5b9b0>, '__name__': '__main__','__doc__': None}In Func{'a': 100, '__builtins__': <module '__builtin__' (built-in)>, '__file__': 'test.py','__package__': None, 'Func': <function Func at 0x7f9085d5b9b0>, '__name__': '__main__','__doc__': None}{'x': 0}关于 Python 的变量的生命周期 , 这个不需要程序猿操心 , Python 提供了垃圾回收机制自动识别一个变量的 生命周期是否走到尽头, 并自动释放空间 ( 详情我们稍后再讲 ).
Python关键字
目前我们接触了 while, if, else, for, continue, break, return 等关键字 , 其实还有很多其他的关键字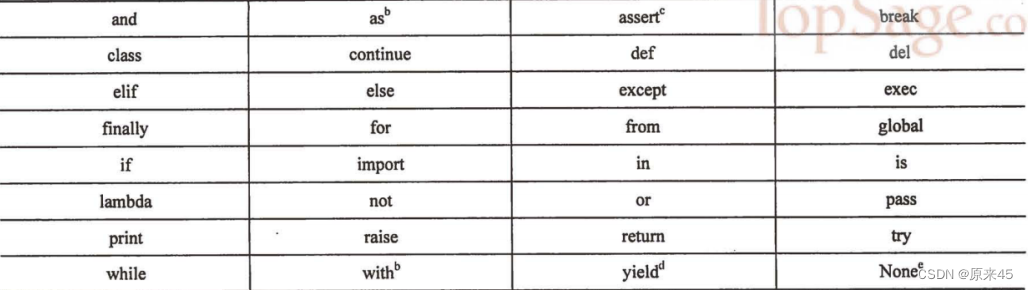
列表/元组/字典
列表和元组类似于C语言中的数组.
使用 [] 来表示列表 , 使用 () 来表示元组 .>>> alist = [1, 2, 3, 4]>>> alist[1, 2, 3, 4]>>> atuple = (1, 2, 3, 4)>>> atuple(1, 2, 3, 4)列表和元组能保存任意数量 , 任意类型的 Python 对象>>> a = [1, 'haha']>>> a[1, 'haha']可以使用下标来访问里面的元素 , 下标从 0 开始 . 最后一个下标为-1>>> a[0]1>>> a[1]'haha'>>> a[-1]'haha'可以使用 [:] 切片操作得到列表或元组的子集 . 这个动作和字符串操作是一样的>>> a[:][1, 'haha']列表和元组唯一的区别是, 列表中的元素可以修改, 但是元组中的元素不能修改>>> a = [1, 2, 3, 4]>>> a[0] = 100>>> a[100, 2, 3, 4]>>> a = (1, 2, 3, 4)>>> a[0] = 100Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: 'tuple' object does not support item assignment>>>字典是 Python 中的映射数据类型 . 存储键值对 (key-value).几乎所有类型的 Python 对象都可以用作键 . 不过一般还是数字和字符串最常用 .使用 {} 表示字典 .>>> a = { 'ip' : '127.0.0.1'} # 创建字典>>> a['ip'] # 取字典中的元素'127.0.0.1'>>> a['port'] = 80 # 插入新键值对>>> a{'ip': '127.0.0.1', 'port': 80}
理解 "引用"
Python 中可以用 id 这个内建函数 , 查看变量的 " 地址 ">>> a = 100>>> id(a)24187568>>> a = 200>>> id(a)24191144>>> b = a>>> id(b)24191144>>> b = 300>>> id(b)25094648给 a 重新赋值成 200, 相当于新创建了一个 200 这样的对象 , 然后将变量名 a 重新绑定到 200 这个对象上 .将 a 赋值给 b, 其实相当于又创建了一个变量名 b, 并将 b 这个名字和 200 这个对象绑定到一起 .再次修改 b 的值 , 可以看到其实是又创建了一个 300 这样的对象 , 将 b 绑定到 300 这个对象上 .像创建的 a, b 这样的变量名 , 其实只是一个对象的别名 . 或者叫做变量的 " 引用 "
代码块及缩进
Python 中使用缩进来表示代码块 . 相当于天然从语法的角度规定了代码风格 .Python 是独一无二的使用缩进而不是 {} 的 , 这就避免了一场党派之争 ~并不存在大括号 . 因此也就不需要考虑大括号放在哪里了
if语句
标准的 if 条件语句语法为如下 .如果表达式的值非 0 或者为布尔值 True, 则执行 do_something, 否则执行下一跳语句 .if expression1:do_something1elif expression2:do_something2else:do_something3Python 并不支持 switch/case 这样的语句 . 也没有必要支持 . 实际上 switch/case 语法并不优雅 .如果条件分支太多 , 可以考虑使用 " 表驱动 " 的方式来组织代码 . 具体可以参见 << 代码大全 >> 第 18 章 .
while循环
while 循环语句和 if 语句语法类似 . 只要表达式的值非 0 或者为 True, 就会循环执行 do_somethingwhile expression:do_something# 循环执行三次 printcounter = 0while counter < 3:print 'loop %d' % countercounter += 1
for循环
Python 中的 for 循环和传统的 for 循环不太一样 .for 循环接收可迭代对象 ( 序列或者迭代器 ) 作为参数 , 每次迭代其中的一个元素# 遍历字符串中的每一个字符a = 'hehe'for c in a:print c# 执行结果hehe# 遍历列表中的每一个元素a = [1, 2, 3, 4]for item in a:print item# 执行结果1z234# 遍历字典中的所有 key-valuea = {'ip':'192.168.1.1', 'port':80}for key in a:print key, a[key]# 执行结果ip 127.0.0.1port 80内建函数 range 能够生成一个数字组成的列表 , 方便进行 for 循环遍历# for 循环执行三次打印for i in range(0, 3):print 'loop %d' % i# 执行结果loop 0loop 1loop 2range 函数其实有三个参数 . 前两个参数分别表示了一个前闭后开的区间 . 第三个参数表示 step, 每次迭代的 步长# 遍历 [0, 100) 区间中的偶数for i in range(0, 100, 2):print i
break和continue
使用 break 语句跳出当前循环# 查找 [0, 100) 第一个 3 的倍数for i in range(0, 100):if i % 3 == 0:break使用 continue 语句 , 回到循环顶端 , 判定循环条件 ;循环条件满足 , 则执行下一次循环 ;
pass语句
有时候需要用到 空语句 这样的概念 , 什么都不做 . 由于没有 {} , 需要有一个专门的语句来占位 , 要不缩进就混乱了.if x % 2 == 0:passelse:do_something
列表解析
又到了见证奇迹的时刻了 . Python 语法的强大简洁 , 初展峥嵘使用 for 循环将生成的值放在一个列表中# 生成 [0, 4) 的数字的平方序列squared = [x ** 2 for x in range(4)]print squared# 执行结果[0, 1, 4, 9]这个过程还可以搭配使用 if 语句# 获取 [0, 8) 区间中的所有的奇数evens = [x for x in range(0, 8) if x % 2 == 1]print evens
函数
一些可以被重复使用的代码 , 可以提取出来放到函数中 .Python 使用 def 来定义一个函数 . 使用 return 来返回结果 .def Add(x, y):return x + yPython 使用 () 来调用函数print(Add(1, 2))理解 " 形参 " 和 " 实参 ": 形参相当于数学中 " 未知数 " 这样的概念 . 实参就是给未知数确定具体的数值 .Python 中没有 " 重载 " 这样的概念 . 相同名字的函数 , 后面的会覆盖前面的def Func():print('aaaa')def Func():print('bbbb')Func()# 执行结果bbbbPython 支持默认参数 . 函数的参数可以具备默认值def Func(debug=True):if debug:print('in debug mode')print 'done'Func()Func(False)Python解包(unpack)语法, 函数返回多个值def GetPoint():return 100, 200x, y = GetPoint()假如我只关注 y, 不想关注 x, 可以使用 _ 作为占位符_, y = GetPoint()函数也是 " 对象 ". 一个函数和一个数字 , 字符串一样 , 都可以定义 " 别名 " 来引用它 .def Func():print('aaa')func = Funcfunc()print type(func)# 执行结果aaa<type 'function'>函数既然是一个对象 , 那么也可以作为另外的一个函数的参数和返回值 . 具体细节我们后面再详细讨论 .
文件操作
使用内建函数 open 打开一个文件handle = open(file_name, access_mode='r')file_name 是文件的名字 . 可以是一个绝对路径 , 也可以是相对路径handle = open('text.txt', access_mode='r')# 或者handle = open('/home/tangzhong/text.txt', access_mode='r')access_mode 是文件的打开方式 . 选项有以下几种'r' : 只读'w' : 只写'a' : 追加写't' : 按文本方式读写'b' : 按二进制方式读写handle 是一个文件句柄 , 是一个可迭代的对象 . 可以直接使用 for 循环按行读取文件内容 .for line in handle:print linehandle 使用完毕 , 需要 close 掉 . 否则会引起资源泄露 ( 一个进程能打开的句柄数目是有限的 ).handle.close()个完整的例子 : 统计文本中的词频一个文本文件中 , 每一行是一个单词 . 可能有重复 . 统计每个单词出现的次数 .示例文件 :aaabbbcccaaabbcaaa代码实现如下 :handle = open('text.txt', mode='r')words = {}for word in handle:word = word[:-1] # 去掉末尾的 \nif word not in words: # 使用 in 关键字判定这个单词是否是字典的 key.words[word] = 1else:words[word] += 1;handle.close()print words
模块
当我们一个项目的代码量较大的时候 , 需要把代码放到多个不同的 .py 文件中可以通过 import 关键字 , 引用其他 .py 文件中的代码 .被引入的这个代码文件 , 就称之为 " 模块 ".被引入的文件 , 去掉 .py 后缀名 , 就是模块名例如 :# add.py 内容def Add(x, y):return x + y# test.py 内容 , 直接 import 模块名import addprint add.Add(1, 2)# test2.py 内容 , 只 import add 模块中 Add 这一个名字 .from add import Addprint Add(1, 2)# test3.py 内容 , import 模块名 , 并且给模块名取了一个别名 .import adda = addprint a.Add(1, 2)模块查找的顺序 , 先是查找当前目录 , 然后查找 Python 的安装目录 .import sysprint sys.path # 打印出了模块查找的路径
实用函数
前面我们接触到了一些非常有用的内建函数 . 这里我们小小的总结一下
特殊标识符
Python 使用下划线 (_) 作为变量的前缀和后缀 , 来表示特殊的标识符 ._xxx 表示一个 " 私有变量 ", 使用 from module import * 无法导入# add.pydef _Add(x, y):return x + y# test.pyfrom add import *_Add(1, 2)# 执行结果Traceback (most recent call last):File "test.py", line 3, in <module>_Add(1, 2)NameError: name '_Add' is not defined_xxx_ ( 前后一个下划线 ), __xxx__ ( 前后两个下划线 ) 一般是系统定义的名字 . 我们自己在给变量命名时要 避开这种风格. 防止和系统变量冲突 .
文档字符串
写注释对于提升程序的可读性有很大的帮助 .前面我们介绍了 # 来表示单行注释 .对于多行注释 , 我们可以使用 三引号 ('''/""") 在函数 / 类 开始位置 表示 . 这个东西也被称为 文档字符串def Add(x, y):'''define function for add two number'''return x + y
使用对象的 doc 属性就能看到这个帮助文档了 ( 别忘了 , 函数也是对象 )print(Add.__doc__)# 执行结果define function for add two num或者使用内建函数 help 也可以做到同样的效果help(Add)# 执行结果Add(x, y)define function for add two num文档字符串一定要放在函数 / 类的开始位置 . 否则就无法使用 __doc__ 或者 help 来访问了模块文档
不光一个函数 / 类可以有一个文档字符串 . 一个模块也同样可以# add.py'''define some function for add'''def Add(x, y):return x + y# test.pyimport addprint(add.__doc__)# 执行结果define some function for add
Unix起始行
对于 Linux 或者 Mac 这类的 Unix 类系统 , 可以给 Python 代码文件增加一个起始行 , 用来指定程序的执行方式#!/usr/bin/pythonprint('haha')保存上面的代码为 test.py. 给这个文件增加可执行权限 : chmod +x test.py然后就可以通过 ./test.py 的方式执行了 .