causallm不适用于上下文学习
原创 森本悟 无数据不智能 2023-08-16 23:42 发表于广东
概述
该文研究的背景是在上下文学习中,基于Transformer的prefixLM模型在性能上优于使用自回归注意力机制的causalLM模型。
过去的方法中,主要使用的是causalLM模型,其采用自回归的注意力机制,限制了上下文样本之间的相互关注。由于这种限制,限制了模型的能力。因此,自然而然地提出了prefixLM模型,允许上下文样本之间进行全局的注意力。这种方法在直觉上是合理的,并在实证研究中取得了良好的表现。
本文采用理论分析的方法,通过对prefixLM和causalLM在特定参数构建下的收敛行为进行分析。研究结果表明,虽然两种语言模型的收敛速率是线性的,但是prefixLM模型收敛到线性回归的最优解,而causalLM模型的收敛动态遵循在线梯度下降算法的特性,即使样本数量无限增长,也不能保证最优性。为了补充理论分析,本文通过在合成和真实任务上进行实验,使用不同类型的transformers验证了prefixLM模型在各种设置下都 consistently underperforms causalLM模型。
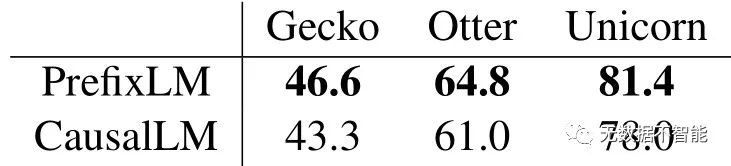
文中对合成和真实任务进行了实验,通过性能对比验证了causalLM模型在所有设置中均低于prefixLM模型的性能。这些实验结果支持了他们的研究目标。
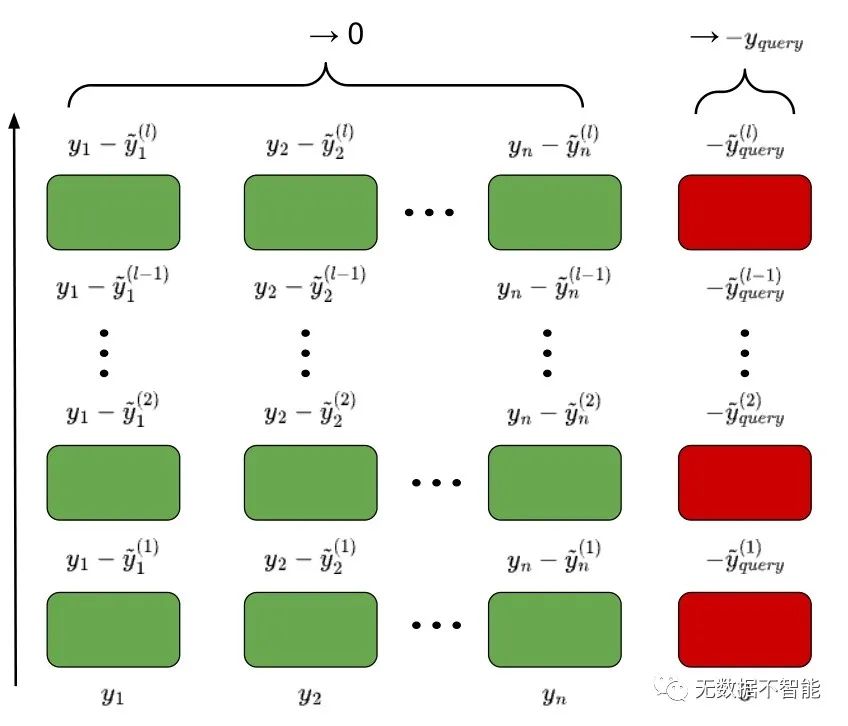
重要问题探讨
1. 为什么使用prefixLM而不是causalLM会在上下文学习中表现更好? 根据文中的实证研究,prefixLM能够实现上下文样本之间的全连接,而causalLM则使用自回归注意力限制了样本与未来样本的联系。通过允许上下文样本之间的全连接,prefixLM能够更好地利用上下文信息,从而在上下文学习中表现更好。
2. prefixLM和causalLM收敛性质有何区别? 通过理论分析,文章发现在特定参数构造下,prefixLM和causalLM都以线性速率收敛到它们的稳定点。然而,prefixLM会收敛到线性回归的最优解,而causalLM的收敛动态则遵循在线梯度下降算法的特性,即使样本数量无限增长也不能保证达到最优解。
3. 为什么使用大规模数据预训练可以实现模型的上下文学习能力? 大规模数据预训练能够让Transformer模型从海量数据中学习到更丰富的语义和语法规律,从而在推断阶段通过摄取少量标记示例(前缀)并计算查询示例的预测结果来解决新任务。这种能力被称为上下文学习(ICL),它超越了传统的机器学习应用,并为模型赋予了灵活应对新任务的能力。
4. 为什么auto-regressive masks对整个序列进行限制效果不好? 实证研究发现,将自回归掩码应用于整个序列会限制模型在处理长序列时的能力,过于严格的自回归限制导致模型难以充分利用上下文信息。为了解决这个问题,研究者提出了prefixLM模型,允许前缀示例内的全连接,从而使模型能够更好地利用上下文信息并提升性能。
5. 文章中提到的实证实验的结果是否支持了理论架构的解释? 是的,文章通过在合成和真实任务上进行实验验证了causalLM和prefixLM的表现。实验结果一致地表明,无论在哪种设置下,causalLM的表现都不如prefixLM。这与文中提出的理论解释相符合,证明了prefixLM在上下文学习中的优越性。
论文链接:https://arxiv.org/abs/2308.06912.pdf