沐神版《动手学深度学习》学习笔记,记录学习过程,详细的内容请大家购买书籍查阅。
b站视频链接
开源教程链接
沐神Transformer论文逐段精读【论文精读】
Transformer

Transformer的论文:Attention Is All You Need!

Transformer的模型架构
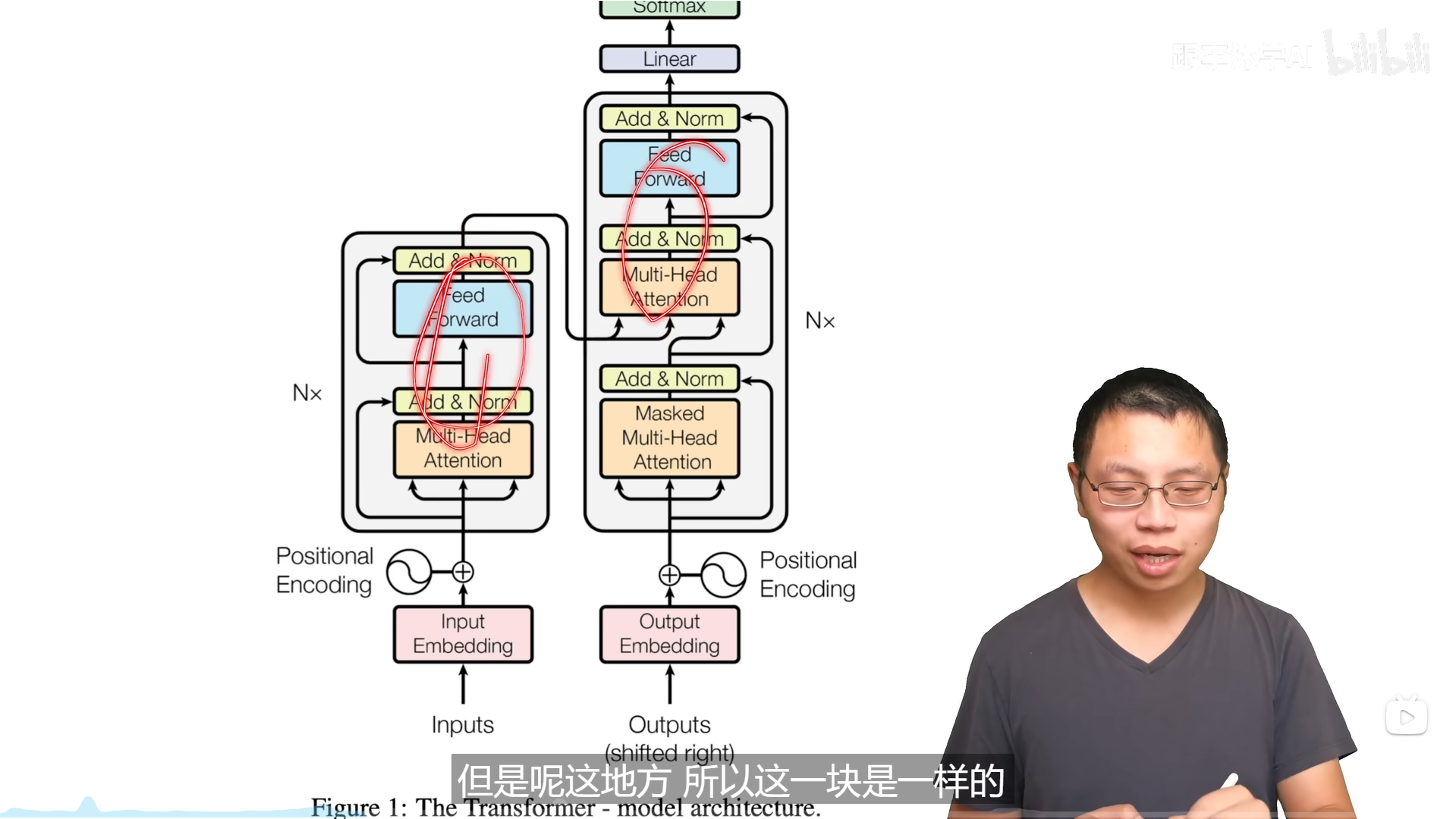
编码器和解码器中的一部分是相同的,解码器多出了Masked的多头注意力。因为要有残差连接,所以要保证数据经过MLP后的维度与原来的维度是相同的,所以在模型中将输出维度都设置为512,这个设计影响了后面的BERT、GPT等工作,可调的参数就只有层数N和模型的输出维度。

如果在写文章时,相关部分有用到了别人的东西,最好在文章里讲一下它是什么东西,不能指望别人都知道所有的细节,能够从几句话讲清楚是不错的。
层归一化
Transformer中使用了Layer Norm,为什么我们在这些变长的应用里不使用Batch Norm,考虑一个最简单的二位输入:
LayerNorm是对样本做标准化,BatchNorm对特征做标准化。在序列不等的情况下使用BatchNorm容易使得方差和均值抖动,LayerNorm是每个样本自己做均值和方差,不需要存全局的信息,相对稳定。

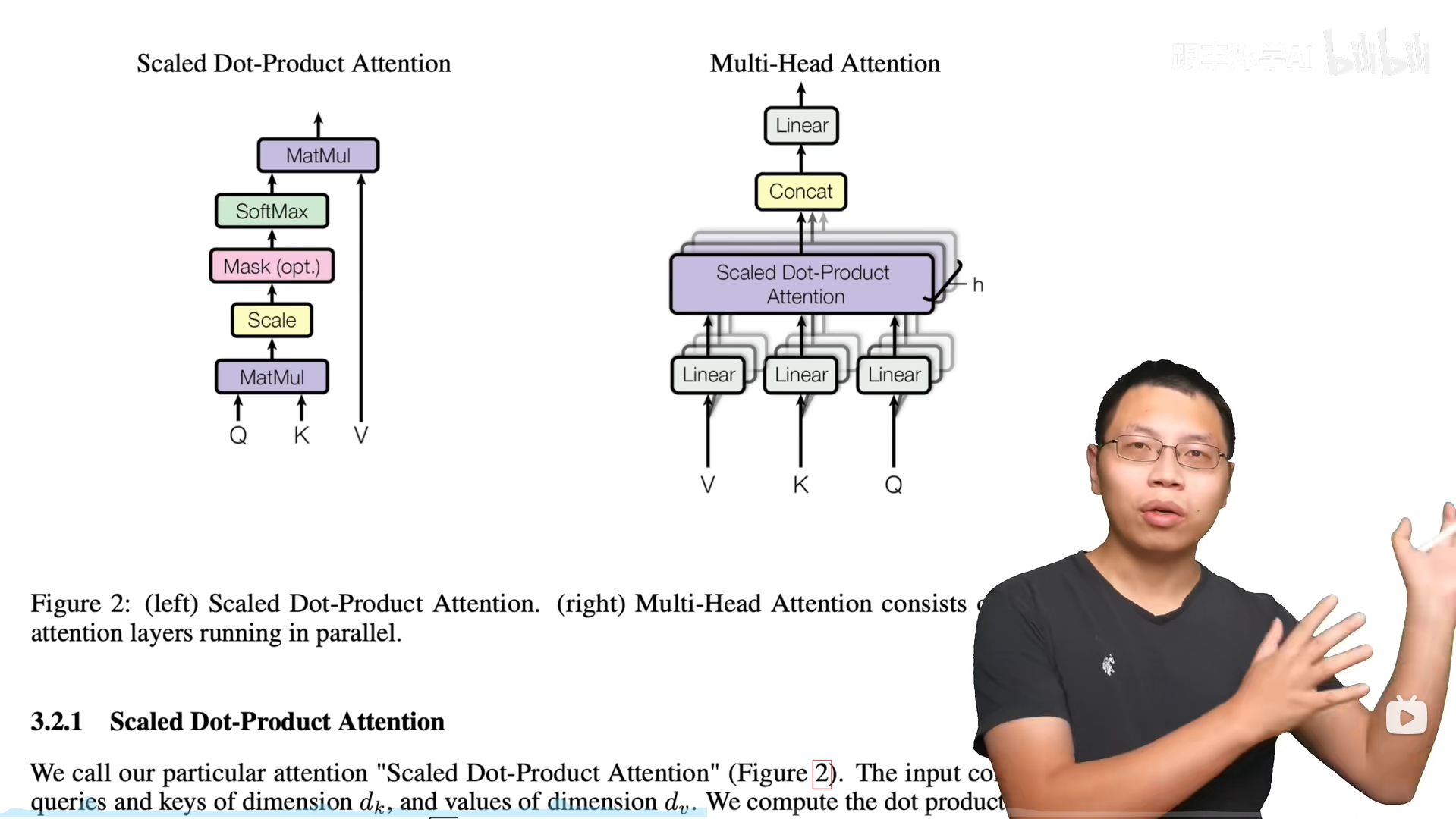
缩放点积注意力

带Mask的注意力计算
保证解码器在计算t时刻时,只能看到t-1时刻及以前的信息,具体实现是将对应信息变得很小,导致在计算注意力矩阵时这些值经过softmax后趋近于0。
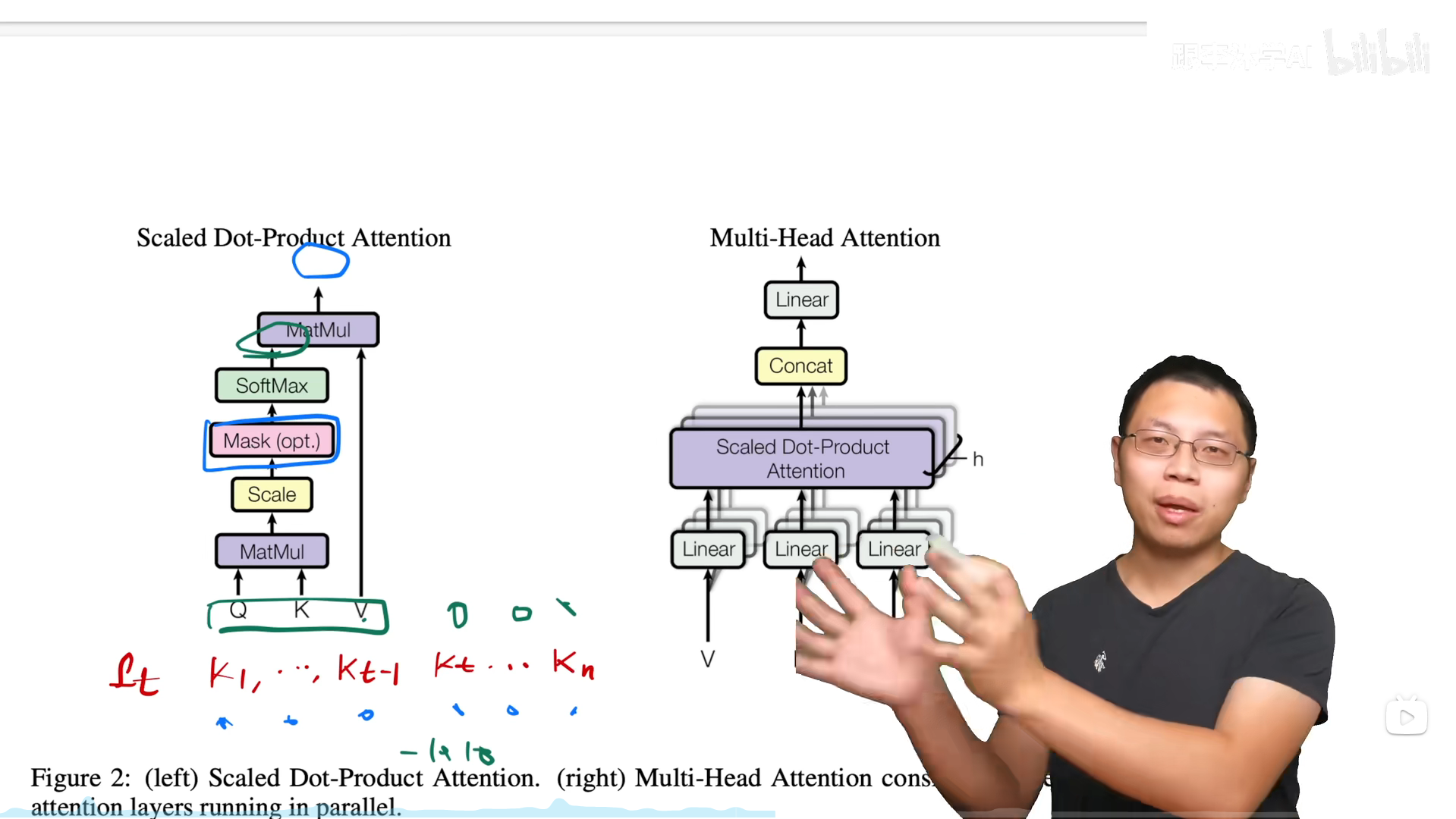
多头注意力
缩放点积注意力是没有学习参数的,所以先把V、K、Q投影到线性层,在经过多个注意力计算,最后再拼接在一起做一次投影,总的来说效果上比较像卷积的多通道。
Transformer选择8个头,每个头投影到512/8=64维度上。
Transformer中注意力的使用
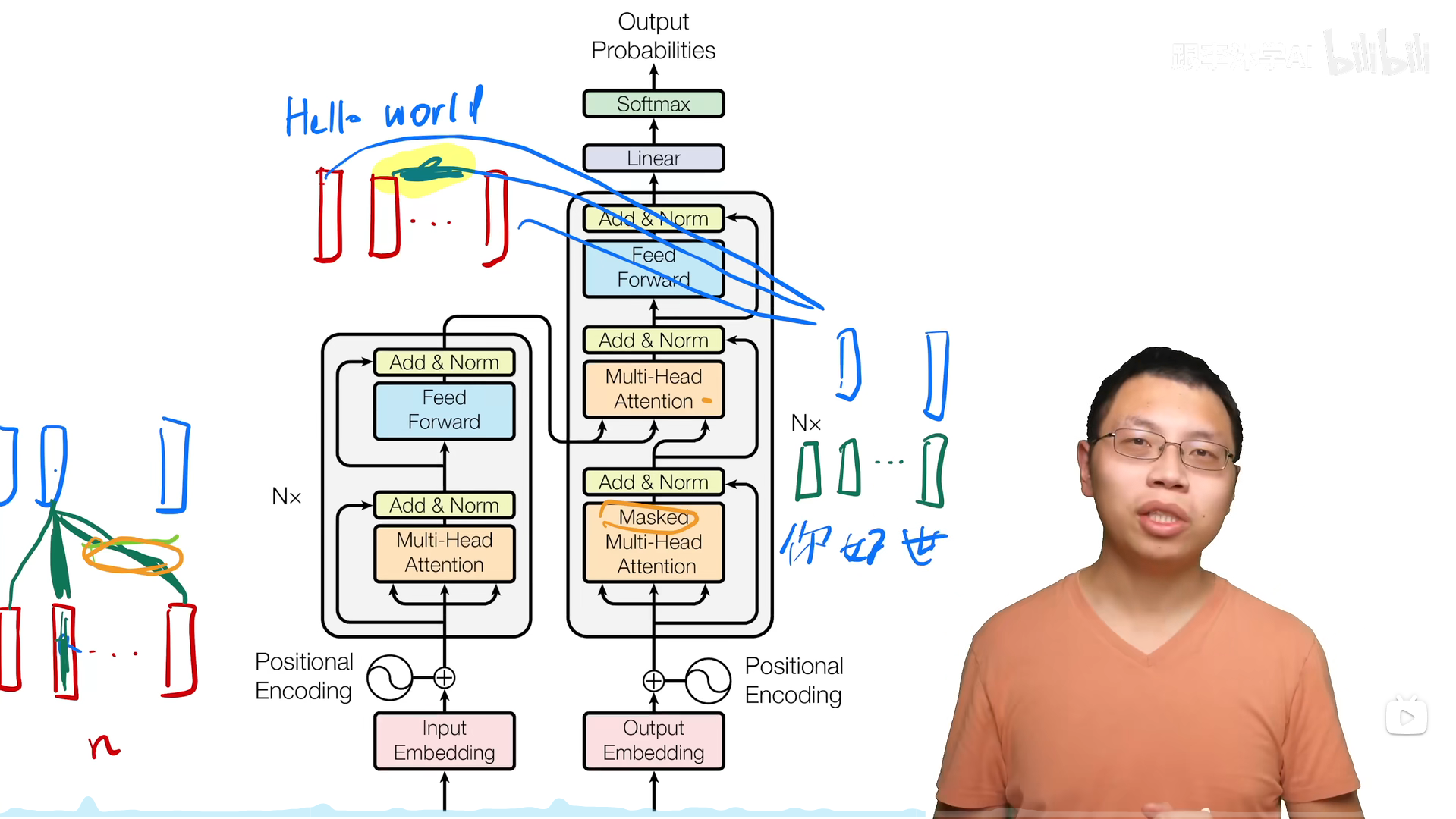
第三个多头注意力层是将编码器的输出作为Q和K,将解码器的输出作为V进行注意力计算。
前馈层有两层,第一层将维度扩展到2048,第二层再将维度缩放到512。
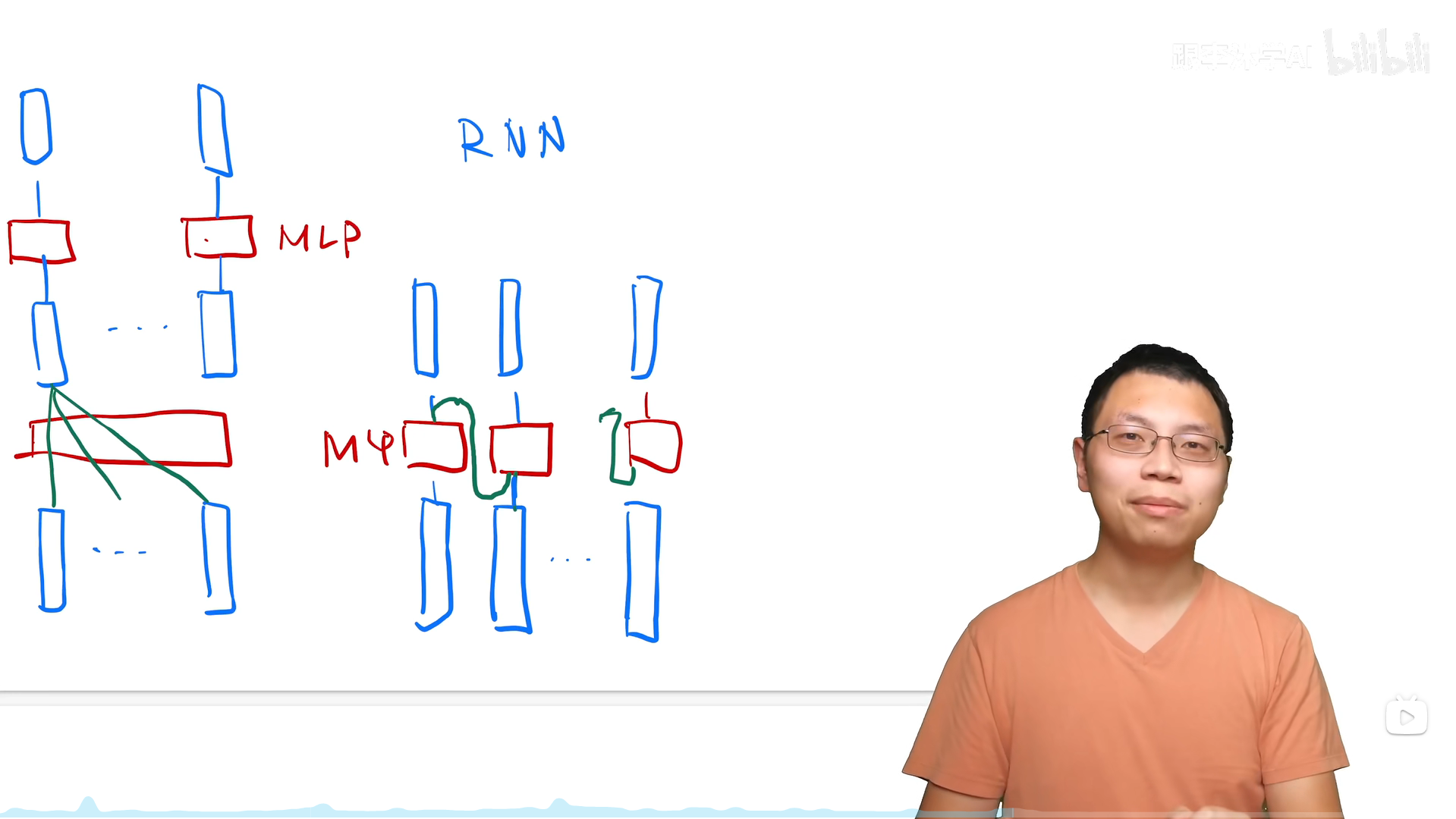
Attention和RNN的区别
attention就是将整个序列的全局信息抓取出来做一个汇聚,RNN把上一个时刻的信息传入下一个时刻作为输入的一部分,两个模型的不同之处就在于序列信息的传递。
位置编码
attention中不存在时序信息,所以在transformer的输入中加入时序信息(位置编码)。
