前言: 在sklearn.preprocessing中存在OrdinalEncoder和OneHotEncoder类可以对离散特征进行连续编码与独热编码,但他们并没有区分离散与连续特征的功能,即只能先取出对应的特征后再分别进行编码然后再合并操作,在工程上还得对未知测试集进行同样操作,有点麻烦。
原数据:
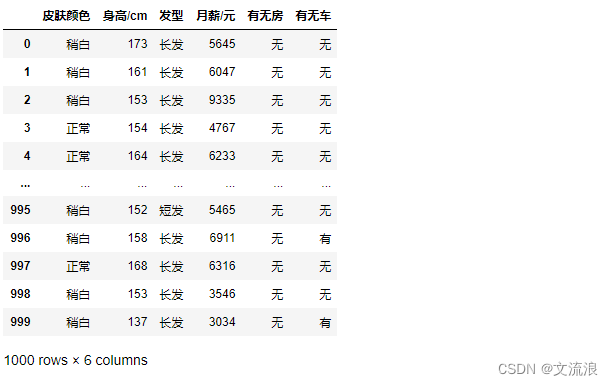
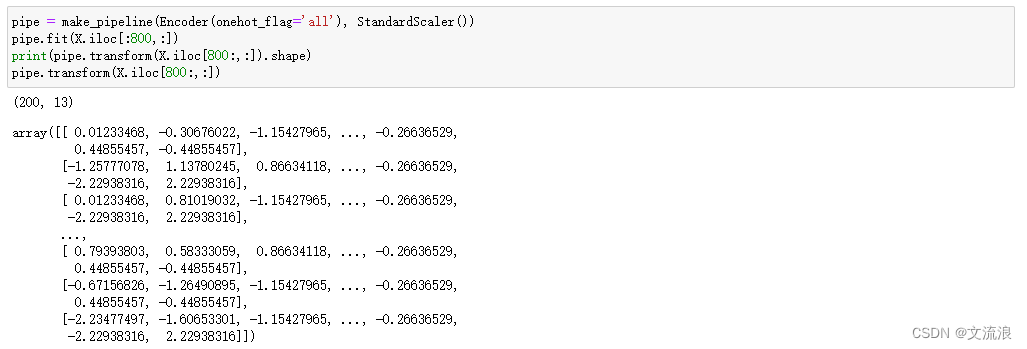
通过pandas.get_dummies得到的独热编码数据: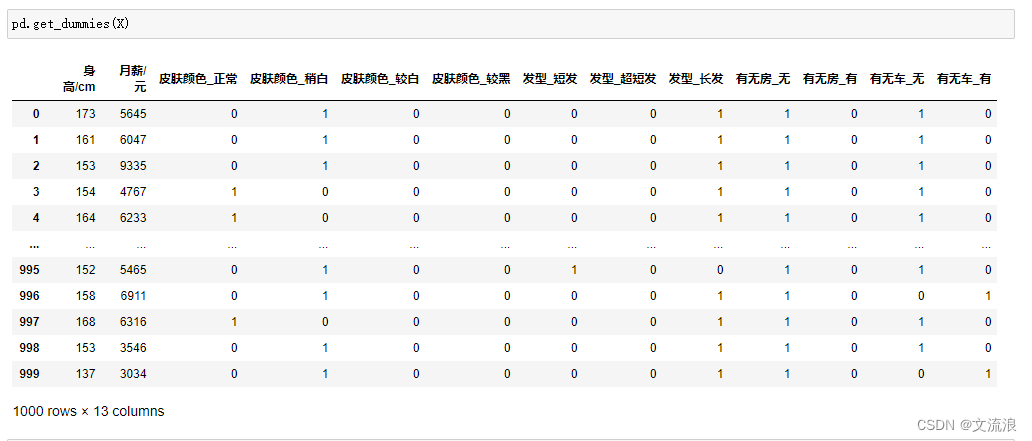
通过OneHotEncoder得到的独热编码数据,如下具有非常多的列,即其对连续型特征也进行了独热编码,这不是我们想要的,而提取出类别特征再编码再合并操作复杂,OrdinalEncoder也一样,会对浮点型数值特征也进行连续编码:

因此面对这个问题,我简单地做了个封装,结合这两种方式的特性,竟可以一键满足pd.get_dummies的效果又能进行fit以及transform操作,也能便捷的指定部分特征进行独热编码(避免某些类别很多的离散特征导致结果过于稀疏),并能像其他encoder类一样嵌入到pipeline流水线中,封装程序如下:
from sklearn.base import TransformerMixin,BaseEstimator
from sklearn.preprocessing import OneHotEncoder,OrdinalEncoder
class Encoder(TransformerMixin,BaseEstimator):
# 可以根据需求传入自定义设置的OneHotEncoder,也可以定义需要进行独热编码的特征列表
def __init__(self, onehotEncoder = None, ordinalEncoder = None, onehot_feas = [],onehot_flag = 'select'):
assert onehot_flag in ['select', 'all'],"onehot_flag must in ['select', 'all']"
# 指定为all则所有离散特征都进行独热编码
self.onehot_flag = onehot_flag
self.onehot = onehotEncoder if onehotEncoder else OneHotEncoder()
self.ordinal = ordinalEncoder if ordinalEncoder else OrdinalEncoder()
# 存储独热编码后的列名
self.columns = []
# 指定哪些特征进行独热编码,若为空,则所有离散特征都进行连续编码
self.onehot_feas = onehot_feas
self.ordinal_feas = []
self.num_fea, self.cat_fea = [], []
def fit(self,X):
self.columns = []
self.num_fea, self.cat_fea = self.num_cat_feaSelect(X)
if self.onehot_flag == 'all':
self.onehot_feas = self.cat_fea
# 取出需要进行独热编码的离散特征
onehot_data = X[self.onehot_feas]
# 不进行独热编码的离散特征进行连续编码
self.ordinal_feas = list(filter(lambda x: x not in self.onehot_feas, self.cat_fea))
# 取出需要连续编码的特征
ordinal_data = X[self.ordinal_feas]
self.onehot.fit(onehot_data)
self.ordinal.fit(ordinal_data)
# 获取独热编码的列名
for fea, oh_feas in zip(self.onehot_feas, self.onehot.categories_):
for oh_fea in oh_feas:
self.columns.append(fea + '_' + oh_fea)
return self
def transform(self, X):
# 取出需要进行独热编码的离散特征
onehot_data = X[self.onehot_feas]
# 取出需要连续编码的特征
ordinal_data = X[self.ordinal_feas]
# 取出其他特征,用于后续合并
order_data = X.drop(self.onehot_feas+self.ordinal_feas, axis = 1)
x_encoding = self.onehot.transform(onehot_data).toarray()
ordinal_data = pd.DataFrame(self.ordinal.transform(ordinal_data),columns = ordinal_data.columns,index= ordinal_data.index)
encoding = pd.DataFrame(x_encoding,columns = self.columns,index = onehot_data.index)
# 对未编码的连续型特征与独热编码后的特征进行合并
# print((order_data,ordinal_data, encoding))
return pd.concat((order_data,ordinal_data, encoding), axis = 1)
# 获取数值型特征与文本型离散特征
@classmethod
def num_cat_feaSelect(cls,data):
num_fea = []
cat_fea = []
for fea in data.columns:
num = 0
while pd.isnull(data[fea].values[num]):
num+=1
if isinstance(data[fea].values[num], str):
cat_fea.append(fea)
elif isinstance(data[fea].values[num], (np.int64,np.int32,np.int16,np.int8,np.float16,np.float32,np.float64)):
num_fea.append(fea)
return num_fea, cat_fea使用文档:
原数据:
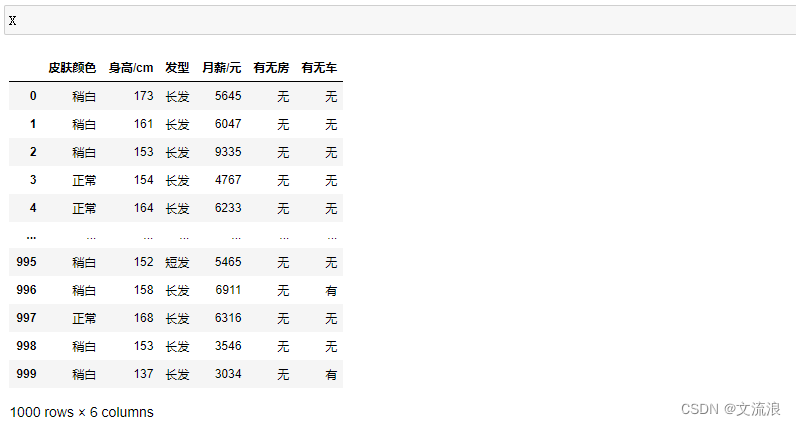
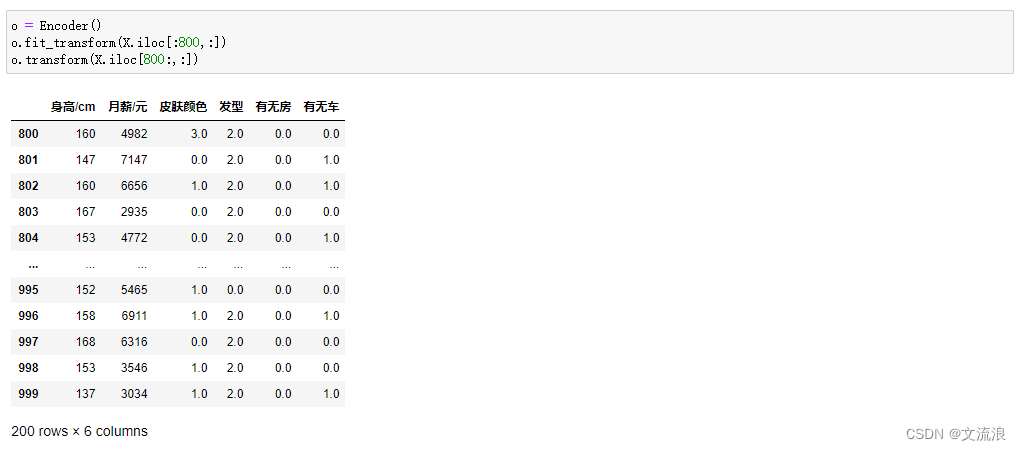
默认参数:只进行连续编码:
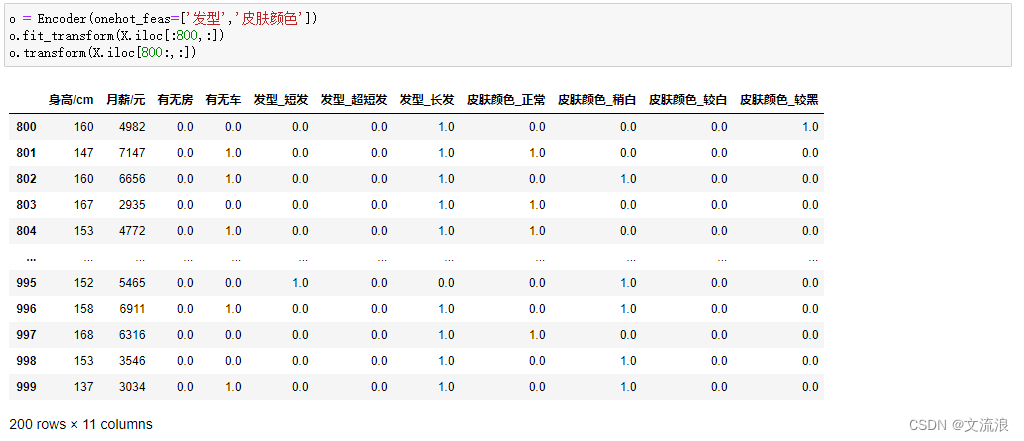
指定部分特征进行独热编码:
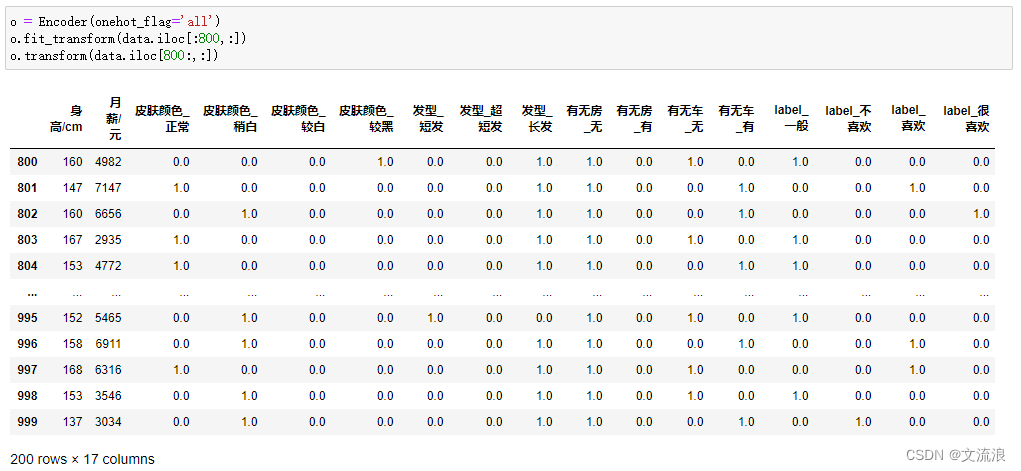
指定所有离散特征独热编码:指定onehot = 'all',则对所有离散特征进行独热编码
可以嵌入到流水线中对数据进行编码以及标准化等操作: