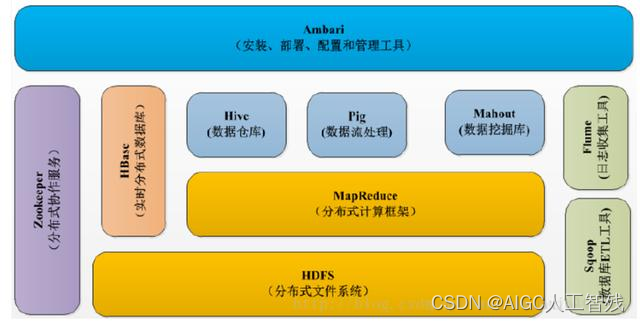
1、 Hadoop概念
Hadoop是Apache下面一个开源分布式计算框架,它具有分布式计算框架、可靠性和可拓展性等优点。它能够处理存储在计算机集群上的大规模数据集;方便拓展,从单个服务器扩展到千台计算机,并且每台都能提供本地计算和存储;不依靠硬件来提供可用性,而是通过软件层面处理和解决故障。
Hadoop一般用于搭建大型数据仓库和PB级数据的存储、处理、分析和统计等业务。
2、 Hadoop核心组件
Hadoop的核心组件主要有以下几个:
- Hadoop Common:主要用来协调其他Hadoop组件的工具;
- Hadoop Distributed File System(HDFS):分布式文件系统;
- Hadoop MapReduce:分布式计算框架;
- Hadoop YARN:Yet Another Resource Negotiator资源调度系统。
3、分布式文件系统HDFS
HDFS是运行在通用硬件上的分布式文件系统,它具有高度容错性,适合部署在廉价的机器上;它能够提供高吞吐量的数据访问,非常适合大规模数据集的应用;而且它还容易扩展,为用户提供不错的性能。
HDFS架构
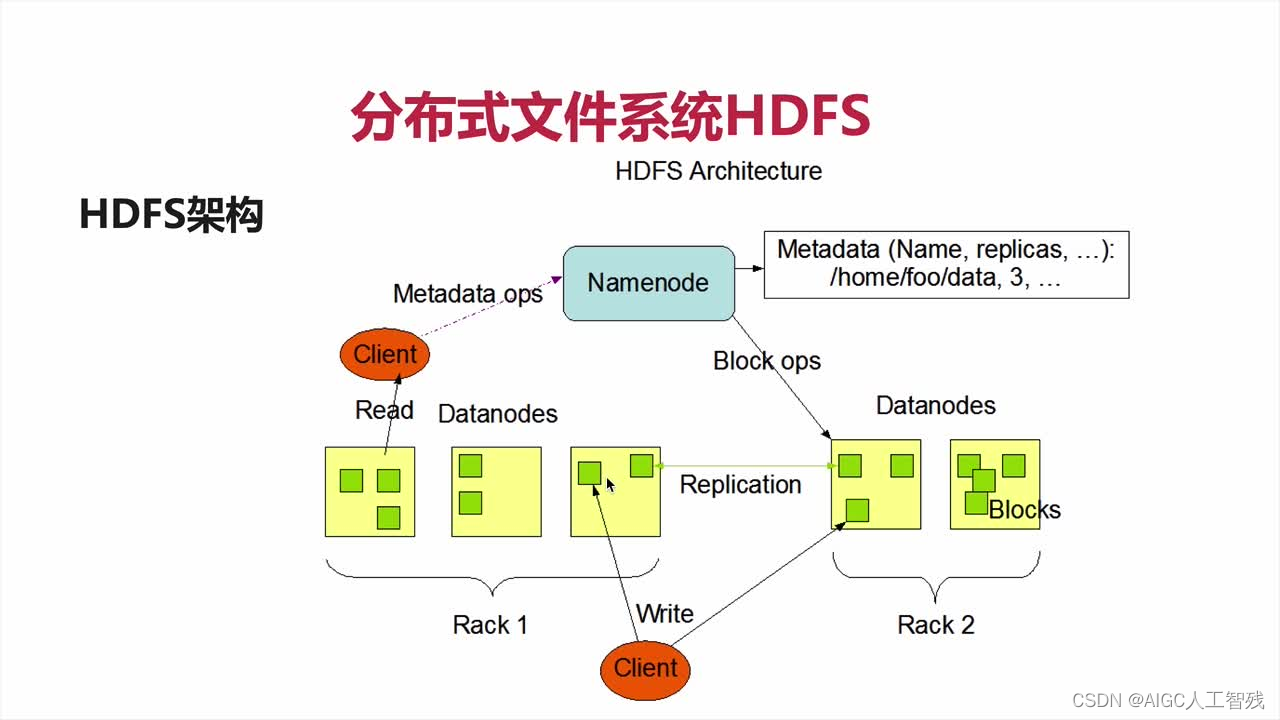
如上图所示,HDFS的架构分为以下几点:
- 1个NameNode(Master)带DataNode(Slaves)模式;
- 1个文件会被拆分为多个Blocks;
- NameNode(NN)负责客户端请求的响应、元数据MetaData的管理和DataNode的健康状况检测。
- MetaData元数据包含文件的名称、副本系数和Block存放的DN
- 健康状况以10分钟为间隔汇报一次,没有收到则认为DN死掉。
- DataNode(DN)负责存储文件对应的Block,并且定期向NN发送心跳信息,汇报自身及其Block的状况信息。
- 分布式集群的NN和DN可以部署在不同的机器上。
HDFS写流程:
- 客户端想NN发送写文件请求;
- NN检测文件是否已经存在,检测权限问题;没问题后返回可写的DN列表;
- 客户端将文件按照128M切分文件,将DN返回的列表和数据一同发送给第一个DN节点,之后客户端与多个DN构成一个pipeline管道,客户端之向第一个DN写数据,数据的复制则在DN内部通过pipeline进行传递;
- 每个DN写完一个Block后返回确认信息;
- 所有数据写完后,发送完成信号给NN。
HDFS读流程:
- 客户端想NN发送读文件请求,将文件名发给NN;
- NN返回该文件的BlockID列表以及对应的DN地址;
- 客户端从列表中第一个DN开始读取数据。
HDFS实现高可用:
- 数据存储故障容错:磁盘介质导致的数据错乱时,对存储在DataNode上数据进行存储校验和CheckSum;读取数据时,发现校验不正确会抛出异常并从其他DN读取备份数据。
- 磁盘故障容错:DN监测本机的某磁盘损坏时,会将改磁盘上的所有BlockID报告给NN,NN监测数据在哪里DN有备份,然后通知对应的DN复制数据到其他服务器上。
- DN故障容错:一般通过心跳与NN保持通讯,如果超过10分钟未发送心跳,则NN会认为DN已经挂掉,NN会查找该DN上的数据块,这些数据块在其他服务器的存储情况,然后从其他DN上复制数据备份。
- NN故障容错:有secondary NN,同时有Zookeeper进行配合,在Master节点中一个Slayer节点作为主节点的功能。
HDFS对应的优缺点:
优点:
硬件有容错性,数据有冗余;适合存储大文件;可以构建在廉价机器上;适合处理流式数据。
缺点:
小文件存储,大文件存储会导致存储不平衡;数据访问延迟问题。
4、资源管理系统YARN
全名Yet Another Resource Negotiator,是通用资源管理系统,为上层应用提供统一的资源管理和调度,为集群在利用率、资源统一管理和数据共享等方面带来巨大的好处。
YARN的架构和运行流程
- 资源管理器ResourceManager(RM):集群中只有一个RM,负责资源的统一管理和调度,处理客户端的请求;
- 节点管理器NodeManager(NM):集群中有多个,负责自己本身的节点资源管理和使用,定向汇报本节点的使用情况,接收处理RM的各种命令;
- ApplicationMaster(AM):每个应用程序对应一个,负责为应用程序向RM申请资源,分配给内部task,需要与NM进行通信,它也是运行在container里面;
- 容器Container:封装了CPU、Memory等资源的容器,是一个任务运行环境的抽象;
- 应用程序Client:提交作业、查询作业进度和杀死作业等。
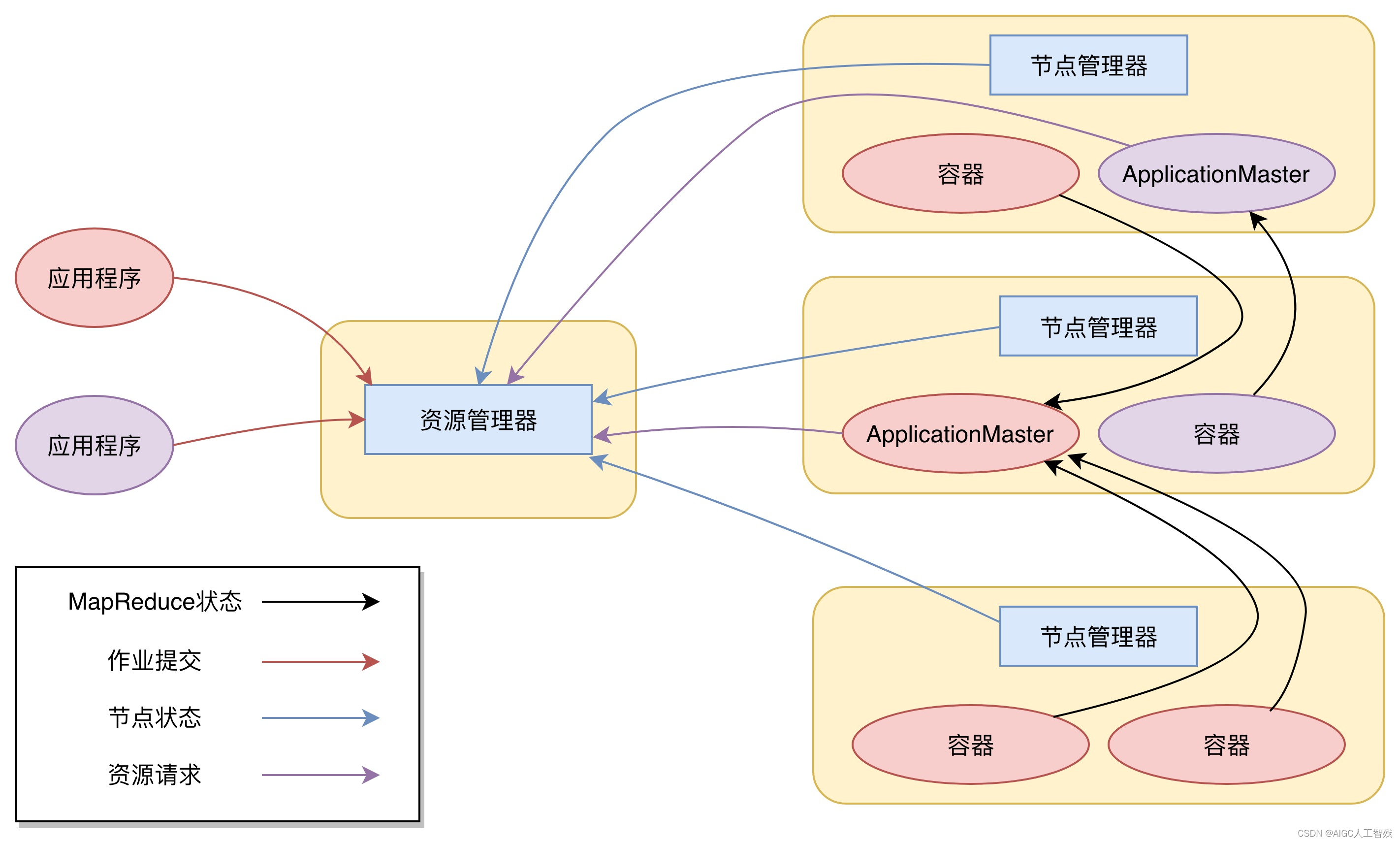
- 应用程序进行作业提交;
- RM和NM进行通信,根据资源,为用户程序分配第一个Container,并将AM分发到该容器上;
- 其中Container中创建AM;
- AM向RM注册进程,申请资源;
- AM拿到资源后,向NM申请启动Container,并将要执行的程序分发到NM上;
- Container启动后,执行对应的任务;
- 任务执行后,向AM返回结果;
- AM向RM请求killContainer。
5、分布式计算框架MapReduce
MapReduce分为Map和Reduce两个阶段,Map阶段是把复杂的问题分解为若干“简单的任务”,即分Tasks;Reduce阶段则是合并Tasks。
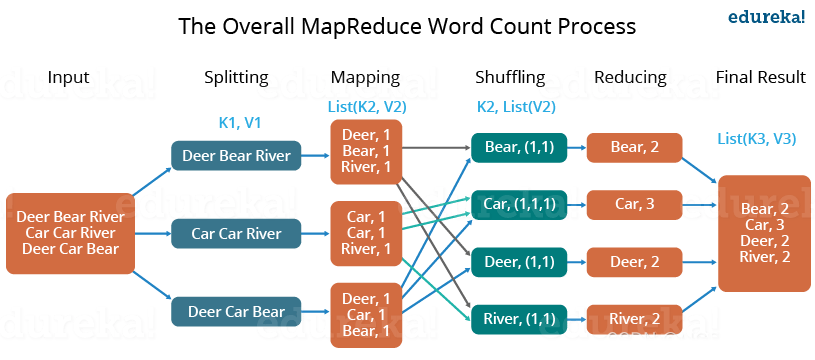
以MapReduce词频统计为例进行原理讲解。
- input输入数据;
- 然后对数据进行切分和格式化处理;
- Map会将前面切分的数据进行Map处理,输出对应的键值对数据;
- Shuffle会将相同的数据放在一起,并对数据进行排序处理;
- Reduce会将Map输出的数据进行hash统计计算;
- 最后格式化输出数据。
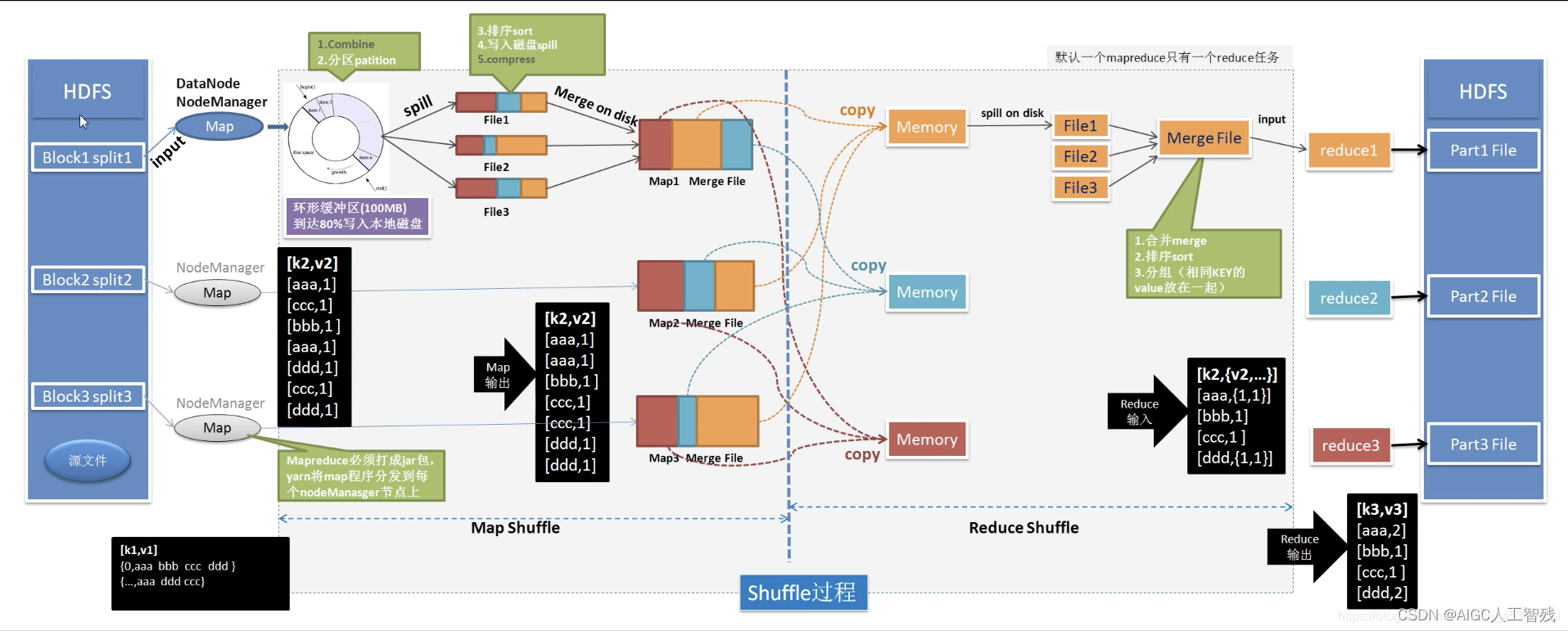
MapReduce架构
任务调度由YARN管理,Map和Reduce作为Task在容器里运行。
6、Hadoop生态系统
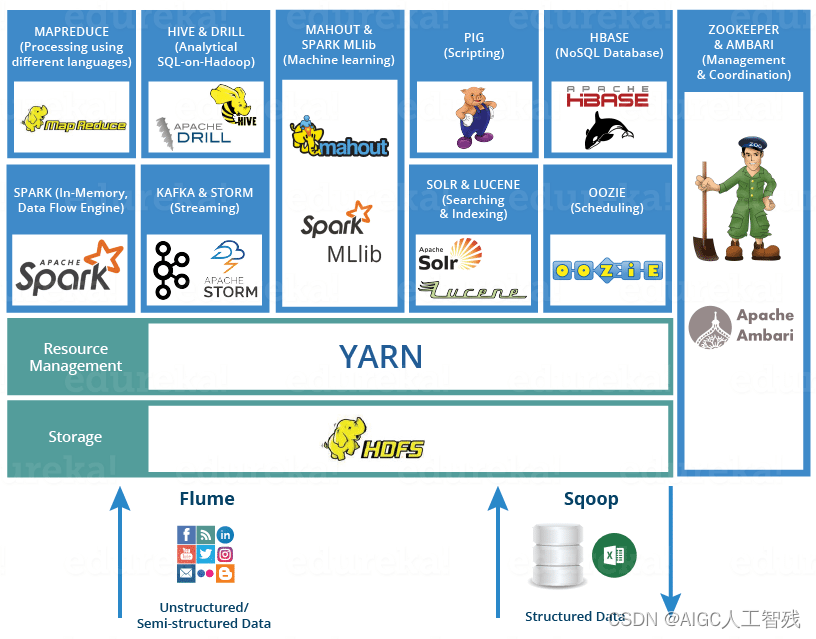
- Hive数据仓库
- R数据分析
- Mahout & Spark MLlib机器学习库
- Pig脚本语言
- Oozie工作流引擎,用于管理作业执行顺序
- Zookeeper管理和协调功能,主节点挂掉,选择从节点作为主节点功能
- Hbase海量数据的查询,相当于分布式文件系统中的数据库
- Kafka消息队列
- Storm分布式的流式计算框架
- Flink分布式的流式计算框架
- Spakr基于内存的分布式的计算框架
- Spark core
- Spark sql
- Spark streaming
- Spark ML
- Flueme日志收集框架
- Sqoop数据交换框架,关系型数据库和HDFS之间的数据交换。
7、Hadoop启动
- 启动HDFS
来到$HADOOP_HOME/sbin⽬录下,执⾏start-dfs.sh。
./start-dfs.sh
- 启动YARN
来到$HADOOP_HOME/sbin⽬录下,执⾏start-yarn.sh。
./start-yarn.sh
- 启动Hive
启动docker
service docker start
通过docker启动mysql
docker start mysql
启动hive的metastore元数据服务
hive --service metastore
启动hive
hive