Hive是一款基于Hadoop的数据仓库工具,它将SQL语句转化为MapReduce任务运行,方便不熟悉MapReduce的用户也能够很好的利用HQL处理和计算HDFS上的数据。Hive一般用来做离线数据分析,会比直接用MapReduce开发效率更高。
1、Hive框架
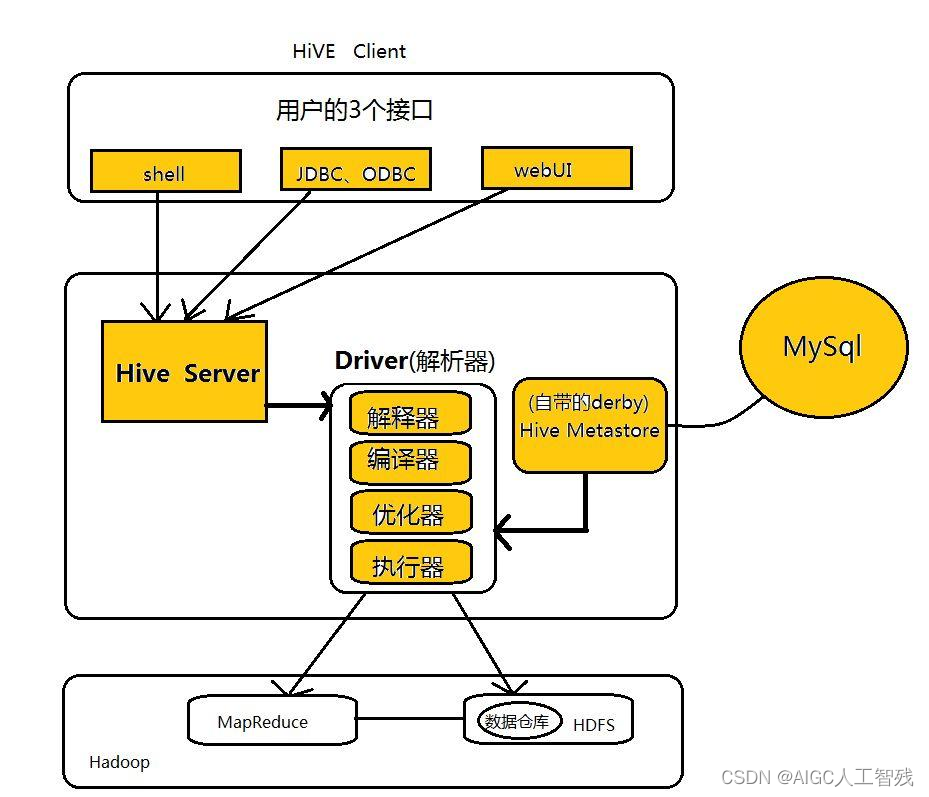
- 用户接口:shell、JDBC/ODBC和webUI
- 元数据存储:自带的derby,但一般会使用Mysql存储元数据。
元数据:表名称、列名、分区及其属性、表的属性和表数据所属的目录。
- 解析器:由解释器、编译器、优化器和执行器组成,完成HQL查询语句从语法分析、编译、优化以及查询计划的生成,生成的计划存储在HDFS中,由MapReduce调用。
Hive在启动前要先启动Hive的元数据服务。
2、Hive数据模型
Hive数据模型主要是两种:一种数据库、表和分区表表现形式是HDFS的文件夹;一种是数据,表现形式是HDFS的文件。具体如下:
- db:在 hdfs 中表现为 hive.metastore.warehouse.dir ⽬录下⼀个⽂件夹
- table:在 hdfs 中表现所属 db ⽬录下⼀个⽂件夹
- external table:数据存放位置可以在 hdfs任意指定路径
- partition:在 hdfs 中表现为 table ⽬录下的⼦⽬录
- bucket:在 hdfs 中表现为同⼀个表⽬录下根据 hash 散列之后的多个⽂件。
3、Hive启动
在已经安装好的Hadoop和Hive上面启动Hive,其中mysql作为元数据库,需要以下的步骤:
- 启动docker
service docker start
- 通过docker启动mysql
docker start mysql
- 启动hive的metastore元数据服务
hive --service metastore&
添加&可以后续继续输出
- 启动hive
hive
4、Hive基本操作
4.1 基础操作
创建数据库
CREATE DATABASE test;
显示数据库
SHOW DATABASES;
创建表
CREATE TABLE student(classNo string, stuNo string, score int) row format delimited fields terminated by ',';
将数据导入表中
load data local inpath '/root/tmp/student.txt'overwrite into table
student;
删除表
drop table student;
查看表的信息
desc formatted table_name;
查询和分组查询基本上跟mysql类似,这里不展开。
4.2 内部表和外部表
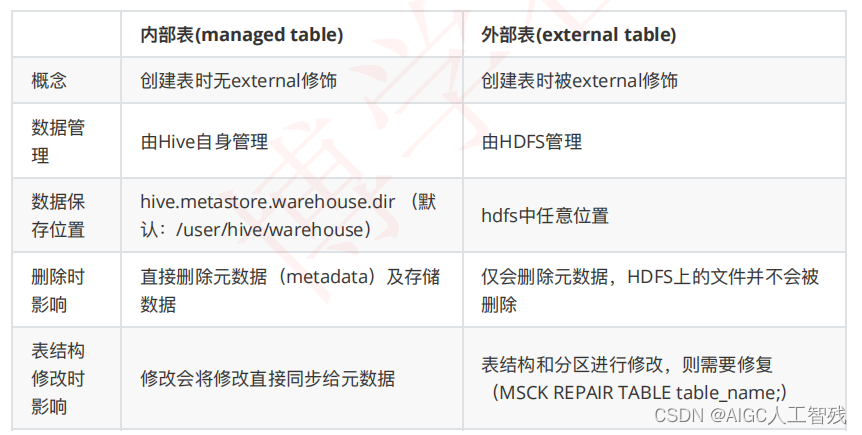
创建外部表
CREATE EXTERNAL TABLE student2 (classNo string, stuNo string, score int)
row format delimited fields terminated by ',' location '/root/tmp/student';
4.3 分区表
分区表就是在表⽂件夹下的⼦⽂件夹,通过分区表可以减少数据查询范围,提⾼查询效率。分区可以理解为分类,通过分类把不同类型的数据放到不同的⽬录下。
创建分区表
create table employee (name string,salary bigint) partitioned by (date1
string) row
format delimited fields terminated by ',' lines terminated by '\n' stored
as textfile;
查看分区表
show partitions employee;
添加分区表
alter table employee add if not exists partition(date1='2018-12-01');
加载数据到分区表
load data local inpath '/root/tmp/employee.txt' into table employee
partition(date1='2018-12-01');
动态分区
即在写⼊数据时⾃动创建分区(包括⽬录结构),创建分区表的格式是一样的,在导入数据时有所区别,我们要先设置动态分区参数。
动态分区参数
set hive.exec.dynamic.partition.mode=nonstrict;
导入数据
insert into table employee2 partition(date1)
select name,salary,date1 from employee;
4.4 Hive函数
Hive的内置函数跟sql的内置函数是差不多的,包括四种类型的运算符:
关系运算符
算术运算符
逻辑运算符
复杂运算;
内置函数:
简单函数: ⽇期函数 字符串函数 类型转换
统计函数:sum avg distinct
集合函数:size array_contains
show functions 显示所有函数;
desc function 函数名;
desc function extended 函数名;
自定义函数
UDF: ⽤户⾃定义函数(user-defined function)相当于mapper,对每⼀条输⼊数据,映射为⼀条输出数据。
UDAF: ⽤户⾃定义聚合函数 (user-defined aggregation function)相当于reducer,做聚合操作,把⼀组输⼊数据映射为⼀条(或多条)输出数据。
运行别人写好的UDF示例:
在hdfs中创建 /user/hive/lib⽬录
hadoop fs -mkdir /user/hive/lib
把 hive⽬录下 lib/hive-contrib-2.3.4.jar 放到hdfs中
hadoop fs -put hive-contrib-2.3.4.jar /user/hive/lib/
把集群中jar包的位置添加到hive中
hive> add jar hdfs:///user/hive/lib/hive-contrib-2.3.4.jar ;
在hive中创建临时UDF
hive> CREATE TEMPORARY FUNCTION row_sequence as
'org.apache.hadoop.hive.contrib.udf.UDFRowSequence'
在之前的案例中使⽤临时⾃定义函数(函数功能: 添加⾃增⻓的⾏号)
hive>Select row_sequence(),* from employee;
创建⾮临时⾃定义函数
hive>CREATE FUNCTION row_sequence as
'org.apache.hadoop.hive.contrib.udf.UDFRowSequence'
using jar 'hdfs:///user/hive/lib/hive-contrib-2.3.4.jar';