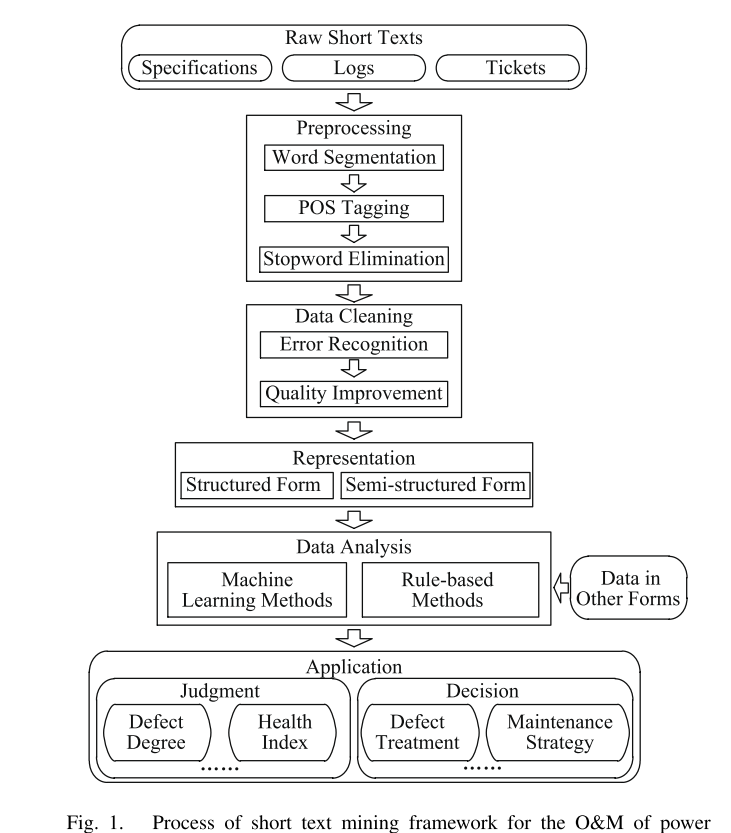
电力设备运维过程中的短文本挖掘框架
-
预处理 首先,与一般的自然语言处理任务类似,对日志、票据和规范中的短文本进行预处理。
- 分词 是对中文文本进行预处理的一个必要的基本步骤。在英语文本中,两个单词之间有一个空格用来分隔,所以这一步通常被跳过。
- POS标记 对每个单词的词性(POS,part-of-speech)进行标记,这可能有利于后续的分析。
- 停止词消除 对于除统计工作外的大多数文本挖掘任务来说,检查员名称、地点、变电站等停止词都是没有意义的,因此一般需要将它们从文本中删除。
-
数据清理 由于检验工程师的知识和经验有限,除了规范中的简短文本外,日志和标签中可能存在信息遗漏、信息矛盾等错误。因此,为了保证短文本挖掘的可信度,需要将日志和票据中的文本数据分错误识别和质量改进两步进行清理。
- 错误识别
- **质量改进 **
-
Representation 表示模块将文本数据转换成计算机可以理解的形式。
- 结构化形式 传统的方法是用结构化的形式来表示短文本,通常是向量或矩阵。
- 半结构式 本文提出了一种基于知识图谱技术的短文本半结构化表示形式,将短文本转化为图形结构。
最后,结合其他形式的数据(如数值数据),结合电力设备运维的实际应用,对结构化或半结构化文本数据进行分析。
-
数据分析
- 机器学习 机器学习方法主要用于数据和结果之间的映射关系复杂和隐蔽的情况。
- 基于规则 对于某些可以确定映射关系的任务,基于规则的方法更合适,因为它们具有很强的可解释性。
最后,数据分析模块将输出与电力设备运维判断和决策相关的结果。
-
应用
- 判断
- 缺陷程度
- 健康指数
- 决策
- 缺陷处理
- 维护策略
- 判断
III. 短文本挖掘框架的具体设计
A. 预处理模块的具体设计
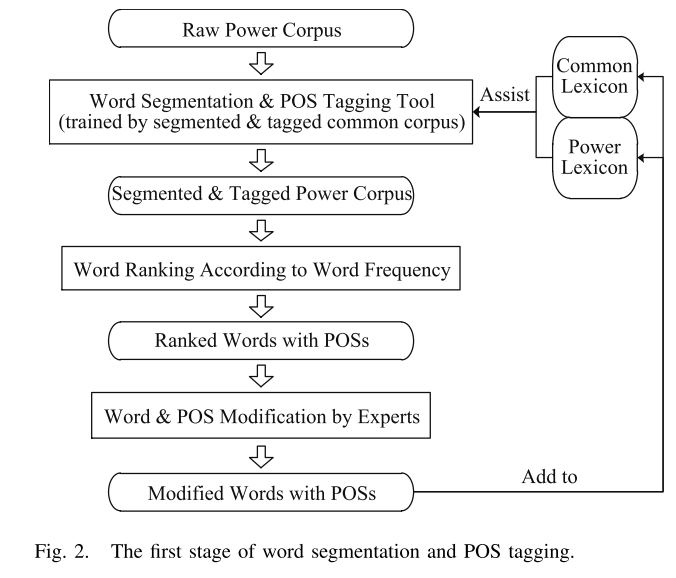
如图2所示,第一阶段是获取包含术语和习语的词汇,以及经过良好分割和标记的权力语料库。
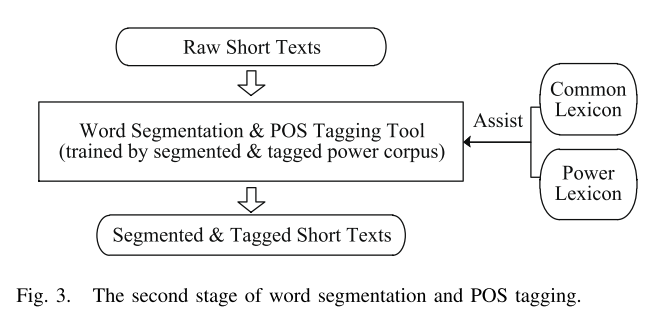
第二阶段如图3所示,对发送到预处理模块的原始短文本进行分割和标记。
B. 数据清洗模块的具体设计
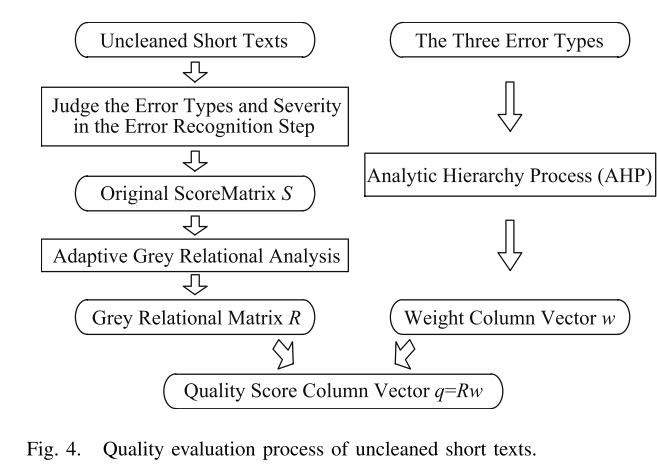
质量改进步骤中的关键参数和算法

C. 表示模块的具体设计
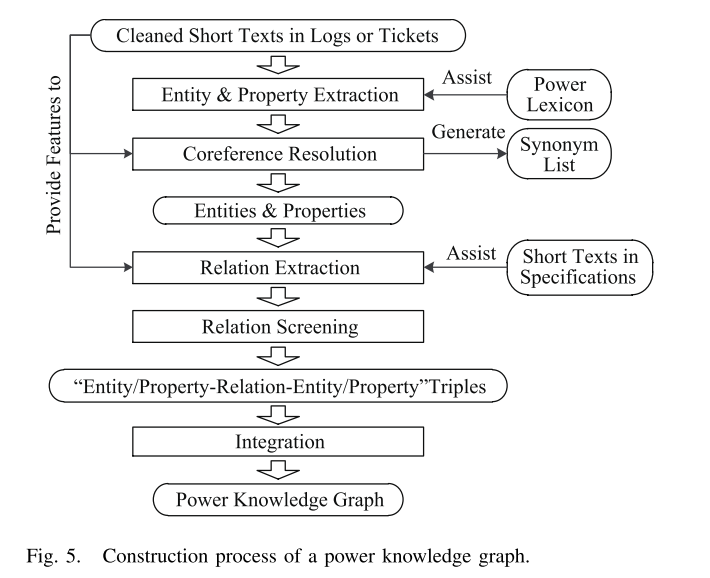

D. 数据分析模块的具体设计
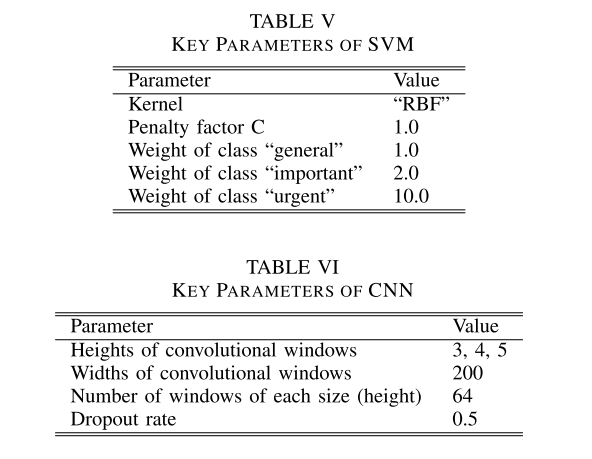
CNN的关键参数如表六所示
IV. 案例研究
A. 基于文本分类的缺陷程度判断
基于短文本挖掘框架,实验组1 (EG1)将文本表示为向量并应用SVM进行数据分析,实验组2 (EG2)将文本表示为矩阵并通过CNN对文本数据进行分析。
另外,为了与EG1进行比较,在对照组1 (CG1)中略过专门设计的数据清洗模块,在对照组2 (CG2)中略过专门设计的VSM在表示模块中的具体设计。
同样,为了与EG2进行比较,我们在对照组3 (CG3)和对照组4 (CG4)中分别跳过了专门设计的数据清洗模块和专门设计的数据分析模块中的CNN。实验过程中,记录机器学习分类器的训练时间和测试时间,分别反映数据分析模块离线和在线计算的效率。结果见表七。
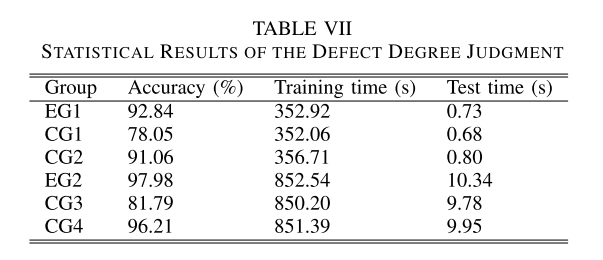
对比EG1和EG2,可以看出深度学习模型CNN比传统机器学习模型SVM准确率更高,但效率更低。深度学习模型有更多的参数,可以更有效地分析特征,但需要更多的时间。模型的选择会影响精度和效率,在实际应用中,精度和效率是具体设计的重要组成部分。
EG2的准确率高达97.98%,虽然花费了最多的训练和测试时间,但效率显著高于人工分类。因此,经过专门设计模块的短文本挖掘框架可以有效地指导判断,并在总体精度和效率上取得令人满意的结果。
B. 基于文本检索的缺陷处理决策
对于新的缺陷日志,如果可以检索到与新日志缺陷条件相同的已有缺陷日志,则可以参考之前的处理方法,做出新缺陷的处理决策。
在实践中,即使两个缺陷日志中的缺陷条件相同,由于不同工程师的知识和经验不同,对这两个日志的描述可能会有很大的不同。因此,文字相似性并不能很好地反映一致性,需要深入理解文本信息所包含的关系。针对这一问题,在表示模块中采用半结构化形式表示缺陷日志,以知识图谱的形式清晰地表达缺陷日志之间的关系。
电力知识图谱构建(主要是关系提取步骤)中的关键参数如表VIII所示,

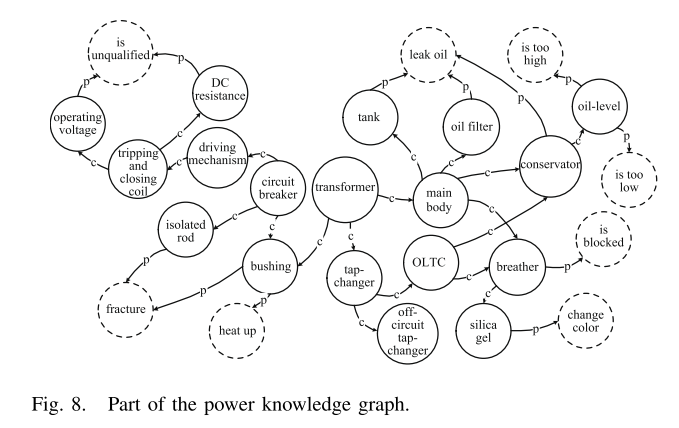
所构建的知识图包含2386个节点和2769条边,部分如图8所示。
缺陷日志检索的统计结果
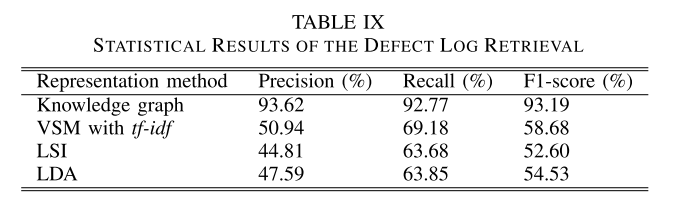
如表9所示,所提出的基于知识图的半结构化表示在三个指标中表现最好,这证明了表示模块的具体设计可以有效提高整体效果。知识图通过直接表示关系,实现知识推理,从而更深入地理解文本信息。为了给出更直观的解释,我们选择了表X中的两组缺陷日志进行说明。

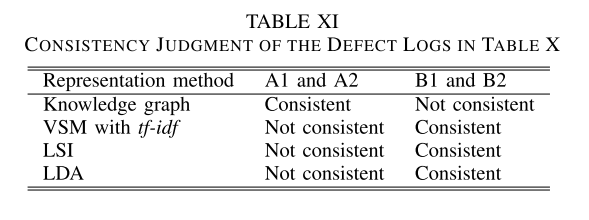
对于每一种表示方法,判断每一组中两个缺陷日志的一致性,结果如表XI所示。
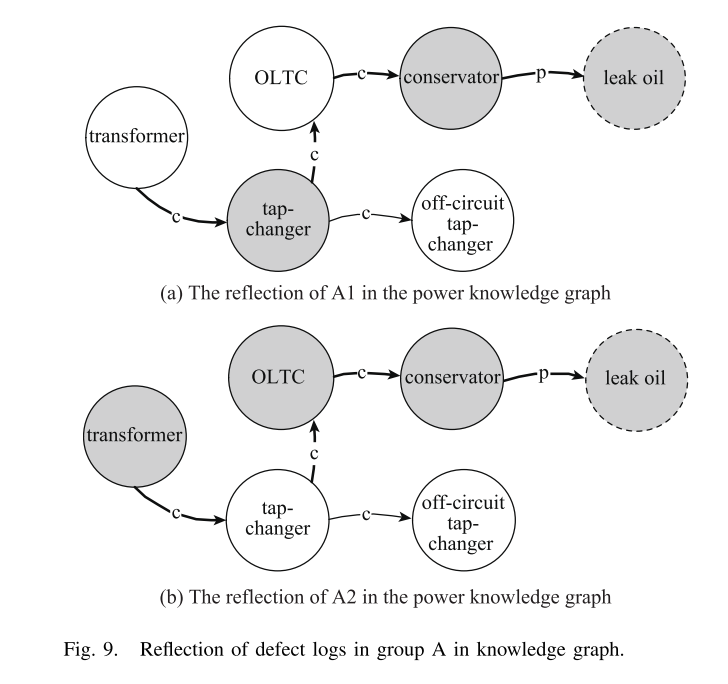
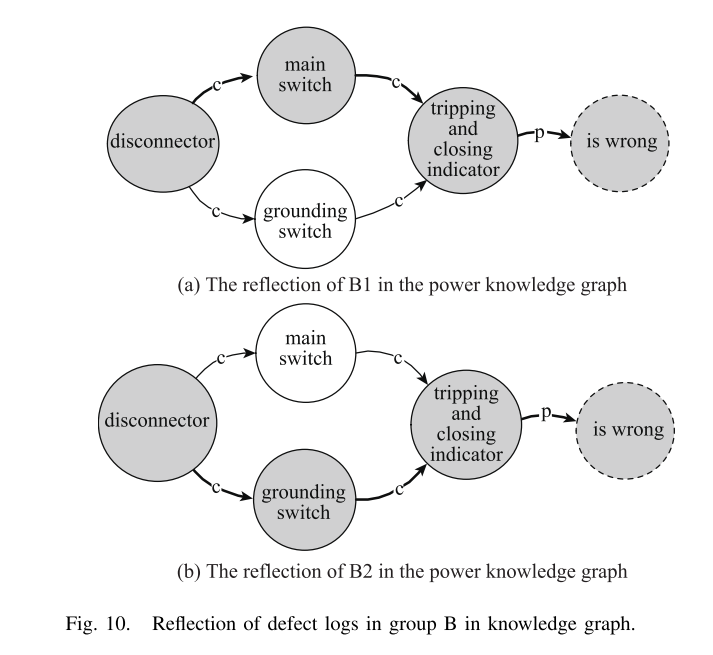
在表X中,A1和A2指的是相同的缺陷,但对缺陷设备和部件的描述有很大的不同。与A2相比,A1缺少缺陷设备“变压器”,并且没有说明元件“分接开关”的类型是有载还是离路。因此,基于结构化形式的三种表示方法无法识别A1和A2的一致性。然而,知识图模型可以通过节点的连接,推理出两个缺陷日志对应的路径是相同的,如图9所示,其中灰色节点为标记出的缺陷日志对应的节点,日志对应的路径用粗体边突出显示(下同)。
V. 结论
提出了一种适用于电力设备运维的文本挖掘框架。我们的主要创新是针对电力设备运维中短文本的特点,对框架的各个模块提出了具体的设计,使框架更适合电力行业的文本挖掘。通过两个与缺陷程度判断和缺陷处理决策相关的案例研究,论证了短文本挖掘框架对实际应用的指导作用。同时,两个案例研究的结果表明,对每个模块的具体设计对提高电力设备运维中短文本挖掘的整体性能是有益的。
在电力设备运维中,短文本挖掘研究的进一步完善主要有两个方面。一是通过句法分析等技术增强短文本挖掘框架的可解释性,使其能够以更接近人类思维的方式理解文本数据。二是构建考虑所有数据形式的通用数据融合模型,进一步提高精度,拓宽应用领域。这两个方面都将是我们未来研究的重要方向。