不知道大家有没有注意到,好多网站我们登录过后,在之后的某段时间内访问该网页时,不会给出请登录的提示,时间到期后就会提示请登录!这样在使用爬虫访问网页时还要登录,打乱我们的节奏,那么如何使用requests实现自动登录呢?
这时候就会联想到:当网站发现我们是爬虫时为了让我们的爬虫伪装成浏览器取访问网站,我们当时在爬虫如何应对网站的反爬机制?一文中提到如何查找user-agent对应的值。同样的,这时候我们需要找到键Cookie对应放入值。那么即使时间已经到期了,我们可以让代码替我们实现自动登录这个步骤然后获取网页源代码

requests自动登录原理:在发送请求的时候将登录信息也发送给服务器
第一步:人工在浏览器中打开网页完成登录
第二步:获取浏览器登录成功后的cookie
第三步:在请求的headers中添加cookie
注意: 每个网站可能会有很多cookie,我们要的是Request Headers中的cookie,而不是Response Headers中的cookie
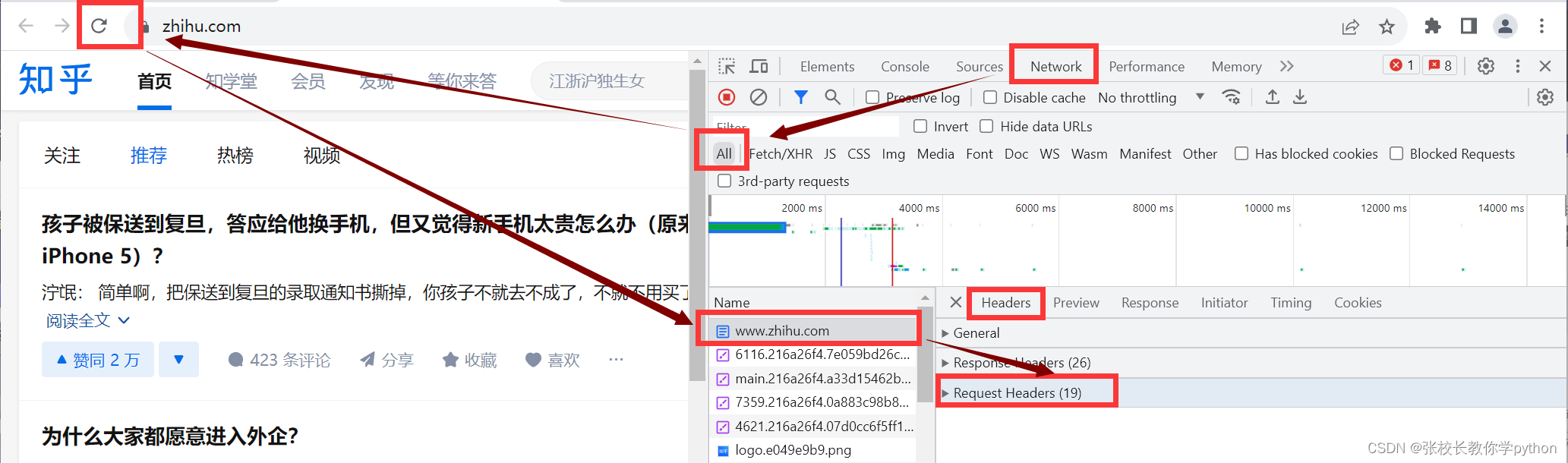
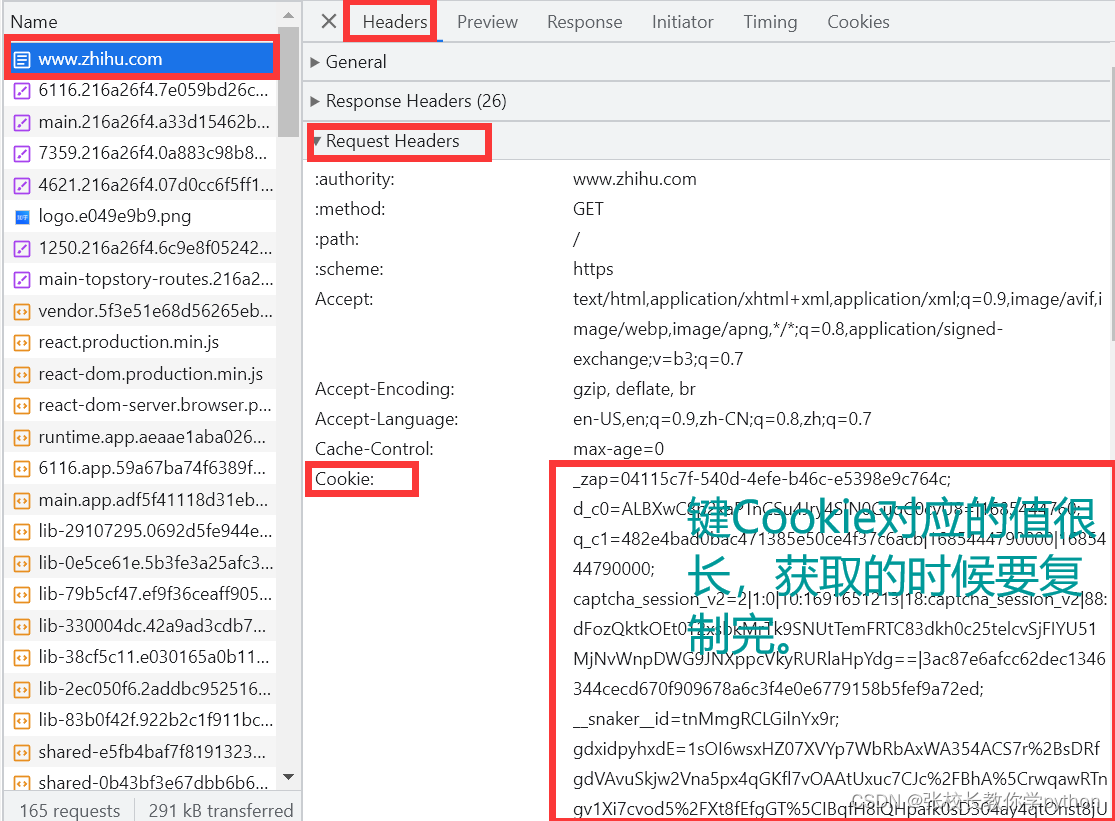
注意:键cookie是固定的,跟前面我们将爬虫伪装成浏览器时获取键user-agent对应的值一样;把值获取后两个键值对一同写入字典Headers中然后赋值给python内置的headers(也是固定的)中,这些固定语法不能改变。
import requests
# 向目标网站发送请求
url = 'https://www.zhihu.com/'
Headers = {
'cookie': '_zap=e68fb091-ad3c-4f93-aaa5-3cb8e44a9a92; d_c0=AODYStMrrhaPTlvcfmFVCztltt7TT4e6dMY=|1682425552; YD00517437729195%3AWM_TID=%2Fw2rAW%2F1bc5EEUQRFFfFboqUeESdv8UO; __snaker__id=VHc2QYrZj6d379F2; q_c1=8680cf29b93f49018441203a765964d4|1686278372000|1686278372000; _xsrf=fae4dbec-7c5a-4b3c-be0a-5f318cedfb10; gdxidpyhxdE=zjz01of9j86tPULz9%2BDaD06kGzhDblRolK7BrKpzk%2B8NjO4y59E162vc%2FRpL1I7LD3gSBy5lhicvGGpGTCn%5CQHwZcjMWsXdwJ299Q5diIdxGp%2FyVCHOeIoetERVrhHJUvyvVlIltzP8%5CtAOWRwOVuggudZQa0LXUlI9C3Cbewciyp%5C4T%3A1691650923028; YD00517437729195%3AWM_NI=N1C1wqYHU2fXpmstB8EFtmf7J8gy8gNzbNry8eM96QGb0hYVtidkTXDwX2LFHsplSk%2FtnxqDq68Rk1w67EhUmQ15sF1Xd4Qb1l2n2JukO9zKctuLWZfIISQdXiGlAHSCTHo%3D; YD00517437729195%3AWM_NIKE=9ca17ae2e6ffcda170e2e6ee85d533abeda39bf64186868aa7d54a969e9aadc574b6babdb4e639fc8e8f88f12af0fea7c3b92a8eef8dd2f67b9b989bd3e554b4b3bd95c134879abc8ee53d8ae8a99abb6d8ea6aeaff173fcbb83dab55b85be0089dc5eb8b7ac8cd75488a998d3cf4e8cadc08dd261edaca299f450b3eaf8b3ea3bb5eaf9a6eb5faf8fffd6f24ef388acd5d46af3b4fe8fb142b7b581daf941a1acbbadd652a69787b4d4709cb7898dc444919d9ca9ee37e2a3; captcha_session_v2=2|1:0|10:1691650047|18:captcha_session_v2|88:Z1U0SWQ3bHhSYU4yZjA1U3dqVEI2a09zcVRwRkJZQ1hzZ0djTVhMNWZkQnRiSE12dHg0WHVhQitlalVGbm1UdQ==|a6aec32bfadbb845cf07a2014fac05d80665a507ce5b6b54e55889f05f29958d; captcha_ticket_v2=2|1:0|10:1691650061|17:captcha_ticket_v2|704:eyJ2YWxpZGF0ZSI6IkNOMzFfLnNPSHpNRU9FMjl4cUVySGZPLkp6TnF2eGo4VXUtemsuRGtkX2NvOHp6dXpBX1Y4MVJYLTFrc28xb2lmc2w4YkxHZWRfSENRNl9YcGlpVHJnNFFWOUFkZE5leEJSZjBiUnE4TURsUEtBZ2pwNnc3SS1zek03ZWhMbmNOTUVtbDQ4YTRwMk02OTJHUEpTZkJFZldvYlFNRHRLb1VXRVBUZlFqZk8wZ0E0YVFUcDhMcTFFWk1NS3RpREsxMUE5b09YMGVmUnllWjlEbmc3azkuaWQ0SGlzOC51TmRmaGhrMG94VVFvV3IxeXNLN092eUE3Rkc0VGRMdGpBbi5PQXpaQWdXcjJ1dGZOY1RKUEVJeHZ2bjR6QWh4ZGFYd2cxUGRZekctcFQ4QzJNUVM0LUpTQ2VLa0xOdVg0UWxBTTV2Wkk0TDVUdXdaOUQwOWdZOEZqeC1QRS5ZTlFaUEQ1Qm5Dei1veXpaRDdfeFRDRmlvaUJRcExvYjJxakJ4bXBDZUhkX1FFdG9neEhhR0JGLXUtb0lFUTBmekhpTko0TDF6dWViRUhnYXY2dFhTR0JwMjU4R3hIMnp2NWpqLThxUm05d3NzUTBSZ0x6R2xueWZoYllXUGZQMGM4Znk3R1U5UTdocjRBRktJclhhQmpESUlsV1E1cEsxaWxxR2VYMyJ9|74bd64a8f77bb3a17015571a1cb76ce6cd740e5e264f3bf8aab46c1785f78c42; z_c0=2|1:0|10:1691650079|4:z_c0|92:Mi4xaW5CWUdRQUFBQUFBNE5oSzB5dXVGaVlBQUFCZ0FsVk5IOWJCWlFCelVLQ19VVU91LThOaEtrVjhHRHluNVBRb2dB|94c7ced0f6ca44537ff9d4fc41f23966d26f1b3173d67a3f469eff45b5228441; tst=r; SESSIONID=WG4zsbW44LZXHe6dSizfsKsCF6zCrd8aeRjDJClAn4T; KLBRSID=ca494ee5d16b14b649673c122ff27291|1691650098|1691650011',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
# 获取响应结果
response = requests.get('url', headers=Headers)
# print(response)
# 获取网页源代码
print(response.text)