
文章链接: https://github.com/JierunChen/FasterNet.
1.文章简介
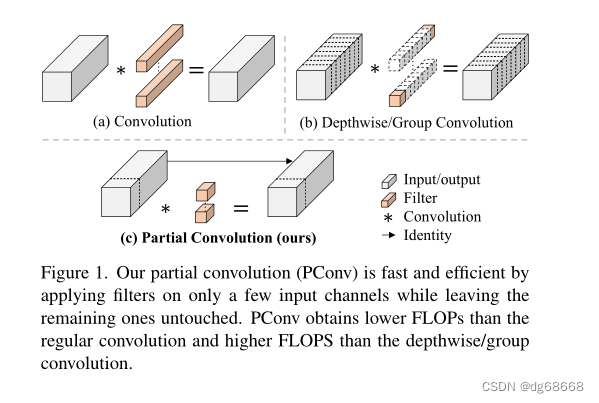
为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOP)的数量上。然而,我们观察到FLOP的这种减少不一定会导致延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。为了实现更快的网络,我们重新访问了流行的运算符,并证明了如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,我们提出了一种新的部分卷积(PConv),通过同时减少冗余计算和内存访问,可以更有效地提取空间特征。基于我们的PConv,我们进一步提出FasterNet,这是一个新的神经网络家族,它在广泛的设备上实现了比其他网络高得多的运行速度,而不影响各种视觉任务的准确性。例如,在ImageNet1k上,我们的小型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileVitXXS快3.1倍、3.1倍和2.5倍,同时准确度提高2.9%。我们的大型FasterNet-L实现了令人印象深刻的83.5%的顶级精度,与新兴的Swin-B不相上下,同时GPU上的推理吞吐量提高了49%,CPU上的计算时间也节省了42%。