Collectors中的方法:
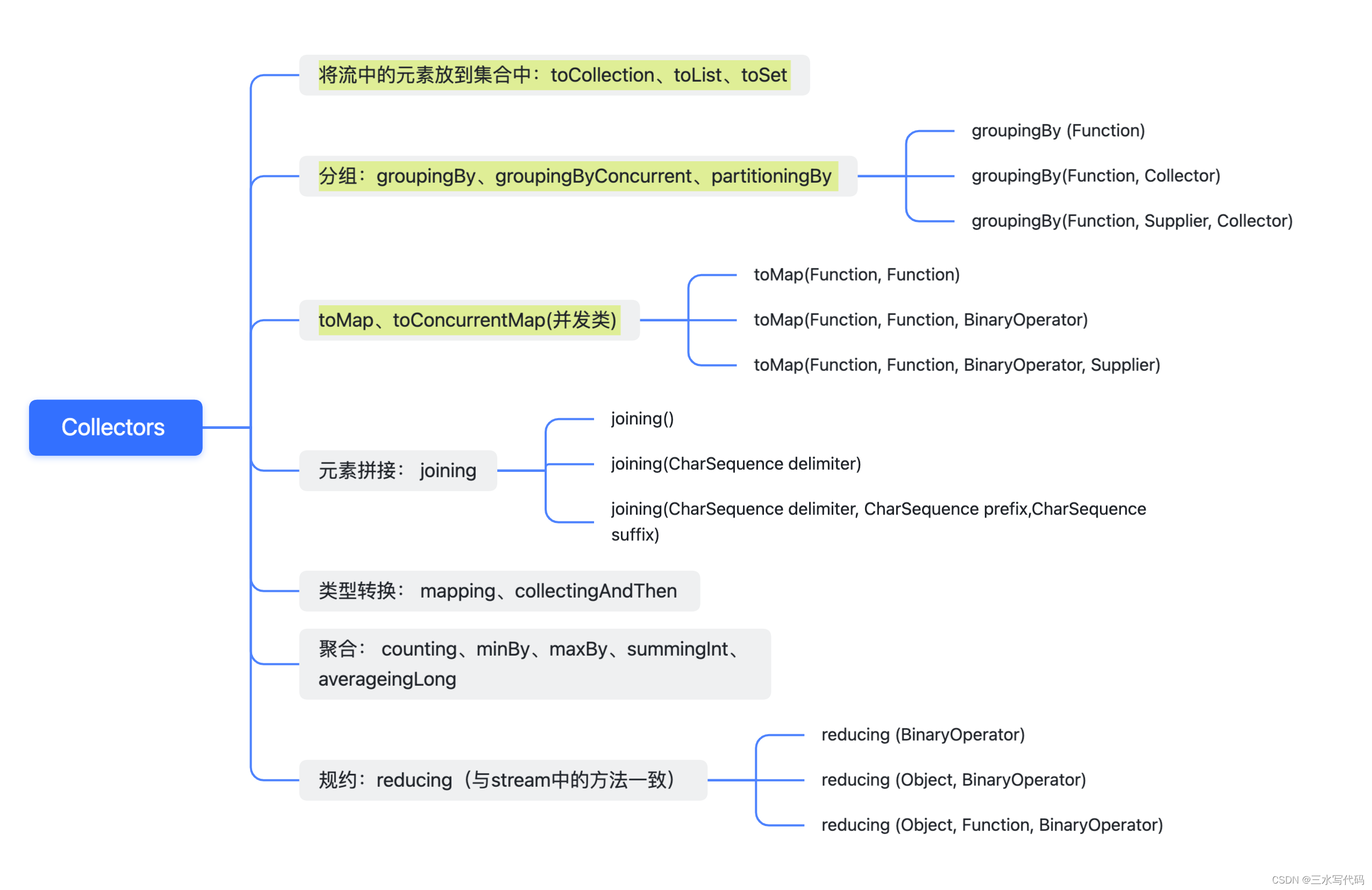
其中我们常用的是前三个:将流中的元素放到集合中、分组、toMap。 下面我们逐个介绍这些方法的使用.
基础类: Student
public class Student {
private Integer id;
private String name;
private String className;
private Double score;
private Long timeStamp;
}1、将流中的元素放到集合中:
1.1 toCollection(Supplier<C> collectionFactory) :
public static <T, C extends Collection<T>> Collector<T, ?, C> toCollection(Supplier<C> collectionFactory) {
return new CollectorImpl<>(collectionFactory, Collection<T>::add,
(r1, r2) -> { r1.addAll(r2); return r1; },
CH_ID);
}示例:
List<Student> studentList = new ArrayList<>();
LinkedList<Integer> collect = studentList.stream().map(Student::getId).collect(Collectors.toCollection(LinkedList::new));
1.2 toList() 、toSet() :
直接上示例:
List<Integer> list = studentList.stream().map(Student::getId).collect(Collectors.toList());
Set<String> nameSet = studentList.stream().map(Student::getName).collect(Collectors.toSet());2、分组
2.1 groupingBy 它有三个重载方法:
public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function classifier) {
return groupingBy(classifier, toList());
}
public static <T, K, A, D> Collector<T, ?, Map<K, D>> groupingBy(Function classifier, Collector downstream) {
return groupingBy(classifier, HashMap::new, downstream);
}
public static <T, K, D, A, M extends Map<K, D>> Collector<T, ?, M> groupingBy(Function classifier, Supplier mapFactory, Collector downstream) {
......
}第一个方法只需一个分组参数classifier,内部自动将结果保存到一个map中,每个map的键为 ‘?’ 类型(即classifier的结果类型),值为一个list,这个list中保存在属于这个组的元素。 但是它实际是调用了第二个方法-- Collector 默认为list。而第二个方法实际是调用第三个方法,默认Map的生成方式为HashMap。 第三个方法才是真实完整的分组逻辑处理。
示例:
Stream<Student> stream = studentList.stream();
Map<Double, List<Student>> m1 = stream.collect(Collectors.groupingBy(Student::getScore));
Map<Double, Set<Student>> m2 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.toSet()));
Map<Double, Set<Student>> m3 = stream.collect(Collectors.groupingBy(Student::getScore,TreeMap::new, Collectors.toSet()));
2.2 groupingByConcurrent
返回一个并发Collector收集器对T类型的输入元素执行"group by"操作, 也有三个重载的方法, 其使用与groupingBy 基本相同。
2.3 partitioningBy
该方法将流中的元素按照给定的校验规则的结果分为两个部分,放到一个map中返回,map的键是Boolean类型,值为元素的集合
两个重载的方法:
public static <T> Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());
}
public static <T, D, A> Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,
Collector<? super T, A, D> downstream) {
......
}从上面的重载方法中可以看出,partitioningBy 与 groupingBy 类似, 只不过partitioningBy 生成的map的key的类型限制只能是Boolean类型。
示例:
Stream<Student> stream = studentList.stream();
Map<Boolean, List<Student>> m4 = stream.collect(Collectors.partitioningBy(stu -> stu.getScore() > 60));
Map<Boolean, Set<Student>> m5 = stream.collect(Collectors.partitioningBy(stu -> stu.getScore() > 60, Collectors.toSet()));
3、toMap
toMap方法是根据给定的键生成器和值生成器生成的键和值保存到一个map中返回,键和值的生成都依赖于元素,可以指定出现重复键时的处理方案和保存结果的map。
toMap也有三个重载的方法:
public static <T, K, U> Collector<T, ?, Map<K,U>> toMap(Function keyMapper,Function valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
public static <T, K, U> Collector<T, ?, Map<K,U>> toMap(Function keyMapper,Function valueMapper,BinaryOperator mergeFunction) {
return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
}
public static <T, K, U, M extends Map<K, U>> Collector<T, ?, M> toMap(Function keyMapper,Function valueMapper,BinaryOperator mergeFunction,Supplier mapSupplier){
......
}三个重载的方法,最终都是调用第三个方法来实现, 第一个方法中默认指定了key重复的处理方式和map的生成方式; 而第二个方法默认指定了map的生成方式,用户可以自定义key重复的处理方式。
示例:
Map<Integer, Student> map1 = stream.collect(Collectors.toMap(Student::getId, v->v));
Map<Integer, String> map2 = stream.collect(Collectors.toMap(Student::getId, Student::getName, (a, b)->a));
Map<Integer, String> map3 = stream.collect(Collectors.toMap(Student::getId, Student::getName, (a, b)->a, HashMap::new));
toConcurrentMap的使用与toMap基本一致, 只不过toConcurrentMap 用于处理并发请求,它生成的map是 ConcurrentHashMap
4、元素拼接joining
三个重载方法:
- joining() : 没有分隔符和前后缀,直接拼接
- joining(CharSequence delimiter) : 指定元素间的分隔符
- joining(CharSequence delimiter,CharSequence prefix, CharSequence suffix): 指定分隔符和整个字符串的前后缀。
Stream<String> stream = Stream.of("1", "2", "3", "4", "5", "6");
String s = stream.collect(Collectors.joining(",", "prefix", "suffix"));
joining 之前,Stream 必须是Stream<String> 类型
5、类型转换
mapping:这个映射是首先对流中的每个元素进行映射,即类型转换,然后再将新元素以给定的Collector进行归纳。 类似与Stream的map方法。
collectingAndThen:在归纳动作结束之后,对归纳的结果进行再处理。
Stream<Student> stream = studentList.stream();
List<Integer> idList = stream.collect(Collectors.mapping(Student::getId, Collectors.toList()));
Integer size = stream.collect(Collectors.collectingAndThen(Collectors.mapping(Student::getId, Collectors.toList()), o -> o.size()));
6、聚合
- counting: 同 stream.count()
- minBy: 同stream.min()
- maxBy: 同stream.max()
- summingInt:
- summingLong:
- summingDouble:
- averagingInt:
- averagingLong:
- averagingDouble:
Long count = stream.collect(Collectors.counting());
stream.count();
stream.collect(Collectors.minBy((a,b)-> a.getId() - b.getId()));
stream.min(Comparator.comparingInt(Student::getId));
stream.collect(Collectors.summarizingInt(Student::getId));
stream.collect(Collectors.summarizingLong(Student::getTimeStamp));
stream.collect(Collectors.averagingDouble(Student::getScore));7、reducing
reducing方法有三个重载方法,其实是和Stream里的三个reduce方法对应的,二者是可以替换使用的,作用完全一致,也是对流中的元素做统计归纳作用。
public static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op) {
......
}
public static <T> Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op) {
......
}
public static <T, U> Collector<T, ?, U> reducing(U identity,Function mapper, BinaryOperator<U> op) {
......
}示例:
List<String> list2 = Arrays.asList("123","456","789","qaz","wsx","edc");
Optional<Integer> optional = list2.stream().map(String::length).collect(Collectors.reducing(Integer::sum));
Integer sum1 = list2.stream().map(String::length).collect(Collectors.reducing(0, Integer::sum));
Integer sum2 = list2.stream().limit(4).collect(Collectors.reducing(0, String::length, Integer::sum));
扩展:
实际运用中,可能会用到比较复杂的 groupingBy、mapping、toMap 嵌套、组合使用,进行多级分组处理数据。如:
Stream<Student> stream = studentList.stream();
// 根据score分组,并提取ID作为集合元素
Map<Double, List<Integer>> map1 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.mapping(Student::getId, Collectors.toList())));
// 根据score分组, 并将ID和name组成map作为元素
Map<Double, Map<Integer, String>> map2 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.toMap(Student::getId, Student::getName)));
// 先根据score分组,再根据name进行二次分组
Map<Double, Map<String, List<Student>>> map3 = stream.collect(Collectors.groupingBy(Student::getScore, Collectors.groupingBy(Student::getName)));
当然也可以根据我们想要的条件,设置分组的组合条件,只需要替换 Student::getScore ,换成我们想要的条件即可, 如:
Map<String, List<Integer>> map3 = stream.collect(Collectors.groupingBy(stu -> {
if (stu.getScore() > 60) {
return "PASS";
} else {
return "FAIL";
}
}, Collectors.mapping(Student::getId, Collectors.toList())));
按照这种思路,我们可以随意处理stream中的元素成我们想要的结果数据。