1. 一维卷积
一维卷积的计算是源数据根据卷积核将每个元素周围的数值与卷积核加权乘积的总和;卷积核一般是奇数个;
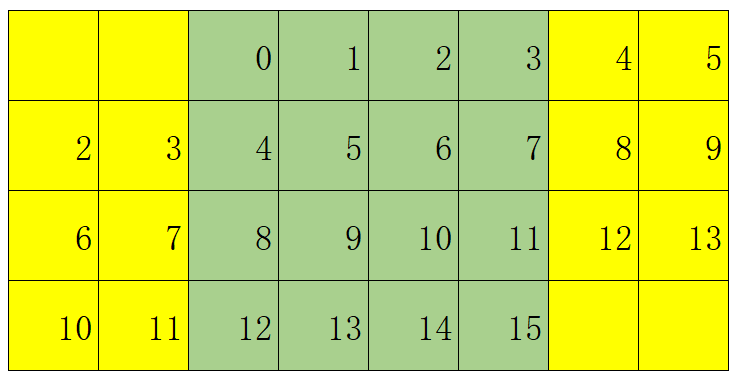
下图是还有16个元素的数组作为源数据,5个元素的卷积核;

计算卷积的过程如下图,每个节点与对应的卷积核进行重叠加权计算;在数组的边界位置时,卷积核会超出有效范围(边界判断),则对应位置数值为0;

设源数组为N,输出卷积数组为P,两个数组长度为size;
设卷积核数组为M,长度为size_kernel;
2. CPU代码实现:
void convolution_1D_basic_kernel(float* N, float* P, int size,
float* M, int size_kernel) {
int half_width_kernel = size_kernel / 2;
for (int i = 0; i < size; i++) {
float p_value = 0;
int begin_pos = i - half_width_kernel;
for (int j = begin_pos; j < begin_pos + size_kernel; j++) {
if (j >= 0 && j < size) {
p_value += N[j] * M[j - begin_pos];
}
}
P[i] = p_value;
}
}代码内容:
1. 计算卷积核的一半尺寸half_width_kernel,当前设置卷积核为5时,half_width_kernel为2;
2. 遍历整个源数组:
2.1 声明一个临时变量p_value用于存储每个数组与卷积核的加权值;
2.2 计算当前i位置的卷积计算的起始位置begin_pos为i - half_width_kernel;
2.3 从begin_pos开始,计算每个数值与卷积核的加权值,前提条件是必须在源数组的有效范围内[0,size);遍历个数为5个数;
2.4 计算结果写入对应的P[i]中;
3. GPU代码如下:
3.1 一般实现
__global__ void convolution_1D_basic_kernel(float* N, float* P, int size,
float* M, int size_kernel) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float p_value = 0;
int begin_pos = i - (size_kernel / 2);
for (int j = begin_pos; j < begin_pos + size_kernel; j++) {
if (j >= 0 && j < size) {
p_value += N[j] * M[j - begin_pos];
}
}
P[i] = p_value;
}假设grid只使用一维度,block使用一维度;即convolution_1D_basic_kernel<<<1,16>>>;
代码内容:
1.根据当前线程Id,以及线程块Id和线程块尺寸,计算当前线程在总的线程网格中的下标i;
2.当前线程只需要计算i对应的N[i]的卷积值;计算当前i位置的卷积计算的起始位置begin_pos为i - (size_kernel / 2);从begin_pos开始,遍历size_kernel个值的卷积总和;
注意:遍历下标需要在N的有效范围内;
3.将结果写入P[i]中;
不足:
1.会出现控制流多样性;由于边界计算的范围不同,if语句中将有不同的决策;
2.存储器带宽,从上面的代码可以看到时时刻刻在访问N数组,相等是从全局存储器获取数据,没有使用到常数存储器、共享存储器等等高速存储器;
3.2 使用常数存储器
卷积中的卷积核尺寸不大,卷积核内容在卷积计算中不变,每个线程都会访问卷积核;
卷积核可以而且应该使用常数存储器和高速缓存存储,可以改善计算中访问全局存储器次数,改善访问存储时延;
存储在常数存储器的变量必须是全局变量,声明位置在所有函数定义之外。使用关键字"__constant__",使用"cudaMemcpyToSymbol"将要放在常数存储器的数据拷贝到设备的常数存储器上;
#define MAX_MASK_WIDTH 10
__constant__ float M[MAX_MASK_WIDTH];与之前代码不同的是M不再是以参数形式传入kernel函数中;
__global__ void convolution_1D_basic_kernel(float* N, float* P, int size,
int size_kernel) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float p_value = 0;
int begin_pos = i - (size_kernel / 2);
for (int j = begin_pos; j < begin_pos + size_kernel; j++) {
if (j >= 0 && j < size) {
p_value += N[j] * M[j - begin_pos];
}
}
P[i] = p_value;
}3.3 使用块
3.1和3.2中的线程组成是一维的线程:
convolution_1D_basic_kernel<<<1,16>>>(N, P, size, size_kernel);在分块算法中,所有线程协作将输入元素加载到片上存储器,并在接下来使用这些元素时直接访问片上存储器;
实现将元素放到片上存储器最直接的方法是在计算之前将线程块所需要的输入数据全部加载到共享存储器中;
使用4个线程块,线程块中使用4个线程来计算一维卷积:
convolution_1D_basic_kernel<<<4,4>>>(N, P, size, size_kernel);一个线程块中有4个线程,如果仅仅将4个线程使用的元素加载片上存储器中,提升了访问速度,但是仍然存储线程束分化的问题;
要解决线程束分化的问题就需要多加载几个元素到片上存储器,其个数与卷积核的范围有关,就是"size_kernel/2*2",下图四行表示四个线程块计算需要的共享存储器存储的数据内容;其黄色部分为当前线程计算额外需要的元素(边缘元素),绿色部分为当前线程各自对应的中心元素(内部元素);
每块分块的共享存储大小应可以存储左侧边缘元素、中间的内部元素以及右侧边缘数据;以下图为例,每块的共享存储个数为左侧边缘元素(size_kernel/2==2)个、中间的内部元素(线程数4)个和右侧边缘数据(size_kernel/2==2)个,共8个;
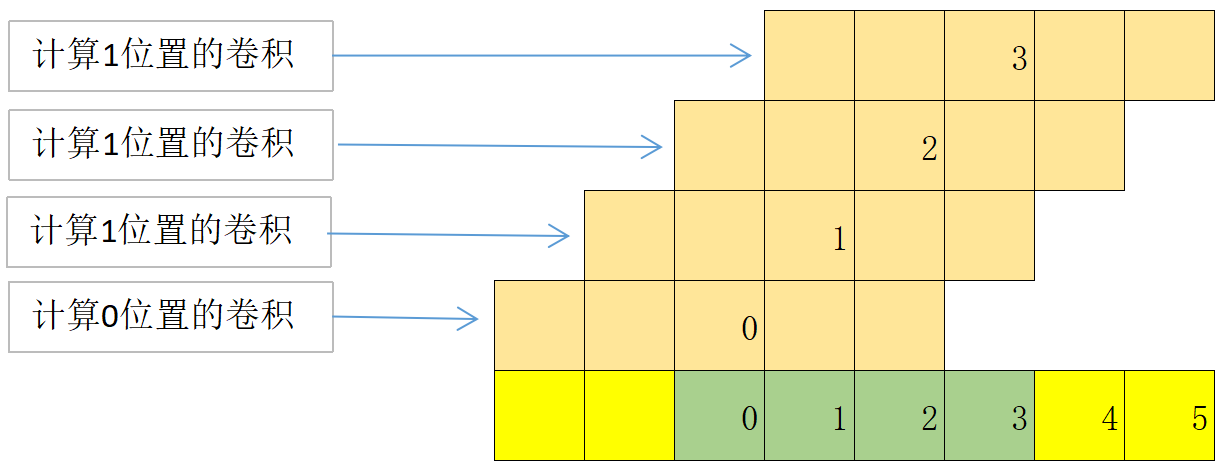
这样在每个线程计算时,可以从共享存储器的开始位置计算,如下图;省略了边界条件的判断;
下图是根据线程2和3计算左侧的边缘元素(下标0和1),根据线程号0和1计算右侧的边缘元素(下标6和7);
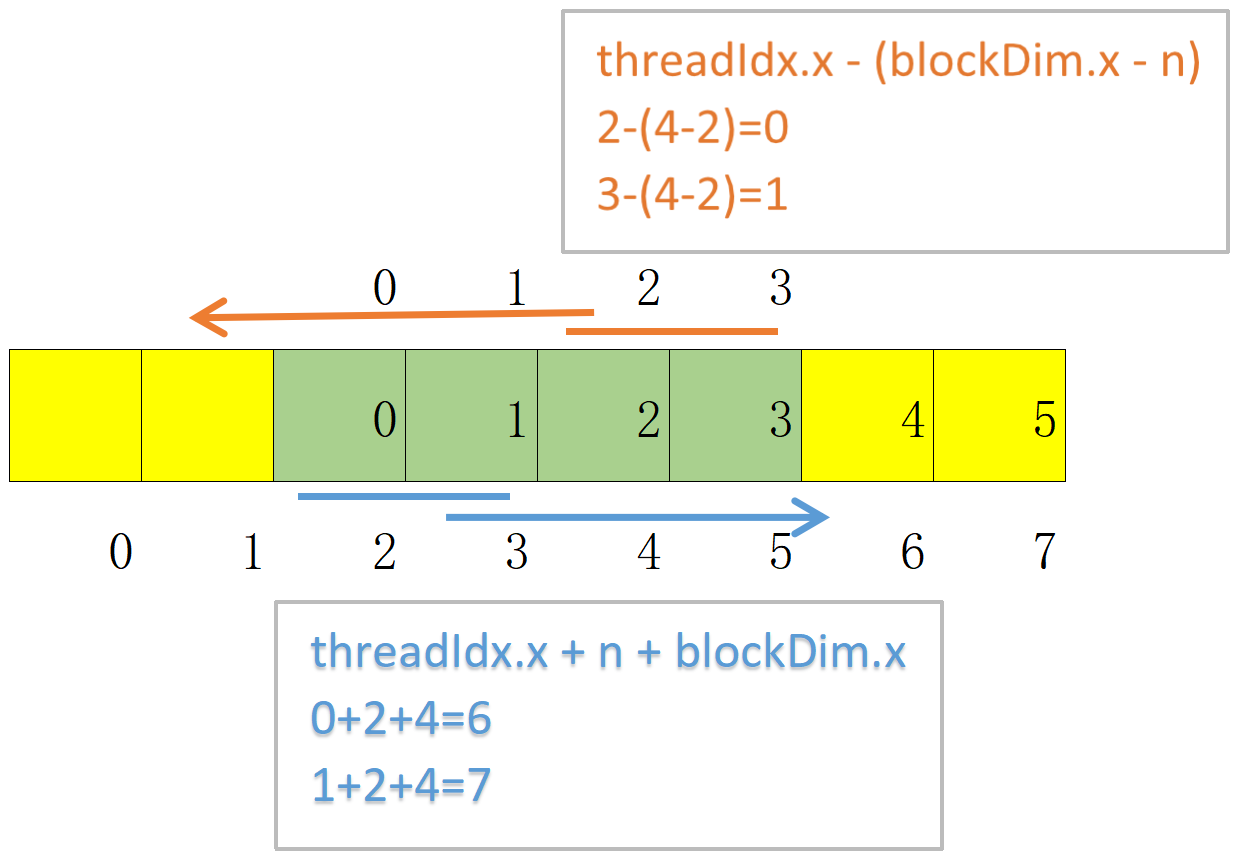
加载左侧边缘元素
int halo_index_left = (blockIdx.x - 1) * blockDim.x + threadIdx.x;
if (threadIdx.x >= blockDim.x - n){
N_ds[threadIdx.x - (blockDim.x - n)] =
(halo_index_left < 0) ? 0 : N[halo_index_left];
}计算当前线程块需要的元素的起始位置halo_index_left(为上一线程块内的内部元素,所以使用了blockIdx.x - 1),此时n为size_kernl / 2,使用n个线程加载左侧的n个边缘元素;
加载内部元素
N_ds[n + threadIdx.x] = N[blockIdx.x * blockDim.x + threadIdx.x];加载右侧边缘元素
int halo_index_right = (blockIdx.x + 1) * blockDim.x + threadIdx.x;
if (threadIdx.x < n){
N_ds[n + blockDim.x + threadIdx.x] =
(halo_index_right >= size) ? 0 : N[halo_index_right];
}详细代码如下:
__global__ void convolution_1D_basic_kernel(float* N, float* P, int size,
int size_kernel) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
__shared__ float N_ds[TILE_SIZE + MAX_MASK_WIDTH - 1];
int n = size_kernel / 2;
int halo_index_left = (blockIdx.x - 1) * blockDim.x + threadIdx.x;
if (threadIdx.x >= blockDim.x - n){
N_ds[threadIdx.x - (blockDim.x - n)] =
(halo_index_left < 0) ? 0 : N[halo_index_left];
}
N_ds[n + threadIdx.x] = N[blockIdx.x * blockDim.x + threadIdx.x];
int halo_index_right = (blockIdx.x + 1) * blockDim.x + threadIdx.x;
if (threadIdx.x < n){
N_ds[n + blockDim.x + threadIdx.x] =
(halo_index_right >= size) ? 0 : N[halo_index_right];
}
__syncthreads();
float p_value = 0;
for (int j = 0; j < size_kernel; j++) {
p_value += N[threadIdx.x + j] * M[j];
}
P[i] = p_value;
}通过引进额外的复杂性减少了对数组N的DRAM的访问次数;最终目标是提高算术运算和访存之间的比率,使获得的性能不再受限于或部分受限于DRAM的带宽;
3.4 使用另外一种共享块
共享存储块内只存储内部元素,边缘元素直接访问全局存储器,由于卷积核尺寸比较小,比内部元素的数量要少很多,代码会比较简单;
__global__ void convolution_1D_basic_kernel(float *N, float *P,
int Mask_Width, int Width){
int i = blockIdx.x * blockDim.x + threadIdx.x;
__shared__ float N_ds[TILE_SIZE];
N_ds[threadIdx.x] = N[i];
__syncthreads();
int this_tile_start_point = blockIdx.x + blockDim.x;
int next_tile_start_point = (blockIdx.x + 1) * blockDim.x;
int N_start_point = i - (Mask_Width / 2);
float Pvalue = 0;
for (int j = 0; j < Mask_Width; j++) {
int N_index = N_start_point + j;
if (N_index >= 0 && N_index < Width) {
if (N_index >= this_tile_start_point
&& N_index < next_tile_start_point) {
Pvalue += N_ds[threadIdx.x + j - (Mask_Width/2)]*M[j];
} else {
Pvalue += N[N_index] * M[j];
}
}
}
P[i] = Pvalue;
}参考资料
CUDA 3D convolution - ijpq - 博客园overview https://www.cnblogs.com/ijpq/p/15405106.html
https://www.cnblogs.com/ijpq/p/15405106.html