1 Introduction
2 Address Translation on Modern Chips
3 L1 TLBs
3.1 Separate I and D TLBs
3.2 Separate L1 TLBs for Different Page Sizes
4 L2 TLBs
Access time
Hit rate
Multiple page size support
Inclusive, mostly-inclusive, or exclusive designs
Implications of inclusive/exclusive hierarchies on translation coherence
5 Multiple Page Size Support
Hash-rehashing
Skewing
6 Page Table Walks
Software approaches
Translation storage buffers
Pors and cons
Hardware approaches
Pros and cons
7 Memory Management Unit Caches
Paging structure caches
Translation path caches
Design comparison
8 MMU Integration: Putting Everything Together
1 Load/store queue to TLB
2 TLB hierarchy to cache hierarchy
3 Page table walker to MMU caches and cache hierarchy
4 Faults
5 Memory replay
Post TLB miss
Post page fault
9 Translation Prefetching
Cache-line prefetching
Sequential prefetching
Arbitrary stride prefetching
Markov perfetching
Recency-based prefetching
10 Replay Prefetching
11 Translation Contiguity
OS-generated translation contiguity
Coalescing
Complete sub-blocking
Partial sub-blocking
Integrating contiguity optimizations in the MMU
12 Conclusion
- Shared address translation structures
- TLB speculation
- Part-of-memory TLB optimizations
- Direct segment, range optimizations, superpages
- Software optimizations
- Energy-efficient address translation
- Translation coherence
- Virtualization [3, 15, 29, 37, 68, 93]
- Accelerators [7, 8, 29, 39, o69, 70, 72, 81, 87, 94], near-memory accelerators [71], and more [33]
- Memory protection
1 Introduction
地址转化硬件是为了优化性能和最小化能源损耗。
tradeoff:地址转化与虚拟内存相平衡。虚拟内存简化程序编程,增加了程序的可移植性。
2 Address Translation on Modern Chips
- Conventional Address Translation
x86-64中PTE为8Bytes
TLB miss谁处理?答:触发操作系统的中断,OS的中断处理程序walk page table - Modern Address Translation
主要组件- L1 TLB, Separate L1 TLBs for instructions and data. 针对不同page size划分独立的tlb,很难设计一个组相联的L1 TLB来支持多种page sizes。
L1 tlb是指令和数据分离的,但是L2 tlb是不区分指令和数据的 - L2 TLB, Unified L2 TLBs, that can cache translations for instructions and data 现代处理器的L2 TLB有一些会支持有限page sizes集合。例如AMD x86-64的L2 tlb支持4kb和2MB page,但不支持1GB。另外L2 tlb是core私有的。
- PTWs, that are used to handle TLB misses without invoking the OS. 有了ptw,tlb miss后就不需要OS来遍历pt了,减少了开销。另外,硬件PTW有两个优化:1、pt walk 与 处理器的指令执行重叠;2、并发服务多个tlb miss
- MMU caches, 加速tlb miss处理。mmu cache比较新,针对x86和arm风格的page table。因为这些系统中,页表事通过前向映射的多级基数树(forward-mapped multi-level radix trees)来实现的,而不是线性的page table。MMU caches store page translations from non-leaf entries of these page tables are used to accelerate page table walks
- Nested TLBs 专门用于支持基于虚拟机的云环境。该方向比较偏虚拟化,推荐论文[15, 20, 93].
- Hardware cahces caches ptes. SPARC架构使用TSBs来帮助缓存pte
- L1 TLB, Separate L1 TLBs for instructions and data. 针对不同page size划分独立的tlb,很难设计一个组相联的L1 TLB来支持多种page sizes。

3 L1 TLBs
3.1 Separate I and D TLBs
指令和数据分开的原因:
- 在一个始终周期内,现代的超标量无序的pipelines可能需要并发的指令和数据的地址转换。指令和数据tlb分开的话可以减少tlb竞争而引发的pipeline危险。
- 指令和数据的局部性不同。指令的tlb miss对性能有害
- 另外,供应商在支持并发多线程(或超线程)的时候,可以为iTLB和dTLB使用不同的策略。由于指令引用对整体性能很重要,因此处理器供应商通常为different simultaneous hardware threads的iTLB实现静态分区。例如,考虑Intel的Skylake架构,当启用双向超线程时,128条目的L1 iTLBs静态地跨两个线程分区。在这种情况下,每个线程保证有64条指令TLB条目,防止在动态分区方案中,如果一个线程的指令占用比另一个线程更大,就会出现公平性问题。相反,dtlb通常在并发硬件线程或超线程之间动态分区
3.2 Separate L1 TLBs for Different Page Sizes
L1 TLB需要快速且高效。因为它位于关键路径,且它占cpu能耗的15%。
因此L1 LTB通常使用组相联RAM或者CAM,而不是全相联。
但是,组相联与多种size的大页面一起使用会出现问题。
会出现先有鸡还是先有蛋的问题,因为页面大小通常在地址转换之后才知道。为了解决这个问题,供应商就针对不同的page size实施单独的L1 TLB。
TLB miss触发pagetable walk,找到translation后,MMU中的硬件将识别页面大小,然后将该translation放到对应的L1 TLB中。
4 L2 TLBs
L2 TLB一般是每个核私有的,虽然目前有研究在探索L2 TLB在内核之间共享的好处。
- Access time
equal to the sum of the traversal time of the interconnect between the L1 and L2 TLBs and the access time of the RAM/CAM array used to physically realize the L2 TLB
一般来说,L2 tlb越大,互联的遍历和阵列的访问时间越久。例如,intel一般有8-10 cycle latencies。像传统的cache,TLBs can be banked to partly reduce RAM/CAM access latency. - Hit rate
L2 tlb的替换策略要更复杂一些。 - Multiple page size support
在5节详细介绍 - Inclusive, mostly-inclusive, or exclusive designs
包容性、大部分包容或者排他性,也就是指,L2 tlb是否应该包含L1 TLB,一般是有三种策略:
1、最常用的,是mostly inclusive,大部分L1 TLB的条目会出现在L2 TLB中,但是不能保证所有都在。具体操作是,当L1 L2 tlb miss后,查到的translation entry会填充到L1和L2 TLB中。然后,每个tlb的垃圾回收独立发生。也就是说,translation可以从L2 tlb中逐出,而保留在L1 TLB中。
2、strict inclusive 在这种模式下,L2中的entry被驱逐时,会发一个反向无效消息给L1 TLB.
3、exclusive 独占策略
权衡。如果L2 TLB受到area或者power的限制,独占策略会更好。如果L1和L2 tlb之间的互连带宽是有限的,那么一种没有反向无效消息开销的mostly inclusive方法可能是最合适的。如果关注的是一致性开销是主要问题,那么strictly inclusive可能更合适。理由如下一点所述 - Implications of inclusive/exclusive hierarchies on translation coherence 包容性/排他性等级制度对翻译一致性的影响 strictly inclusive可以减少coherence messages,因为L2 TLB可以作为L1 TLB的相干滤波器(coherence
filter),也就是说,可以先查找L2 TLB,如果L2 TLB hit,然后再去查L1 TLB,否则就无需查找L1 TLB了。这种设计,介绍了互联网络带宽。
习题
TLB为了维持相关性具体会做什么。有两种方式,在x86-64架构,cpu 1会通过inter-processor interrupts来调用其它cpu上的操作系统例程(OS routines),然后cpu0 2 3会切换上下文来执行os代码,os将执行invlpg特权指令,来使得tlb copy失效。在arm风格的架构中,cpu1会执行tlbi指令,将向其它core发送广播信息,使得其它core失效tlb-驻留。当然,这些需要使用缓存一致性协议,比如MESI、MOESI等
5 Multiple Page Size Support
虽然L2 TLB的很多策略也可以用到L1 TLB上,但是由于L1 TLB的访问时间要求使得这些方法不行。
Hash-rehashing
易于实现,Intel的Skylake/Broadwell有很大可能是使用的这种策略。但是它的缺点是,如果要确认TLB miss,需要很久的时间,然后有一些方法来解决这个问题:
1、Page size prediction 可以从编码的内存指令中提取位,比如使用与基址寄存器相对应的区域rs…。不管用那种预测器,都需要消耗面积和功率,需要进行权衡。
2、Parallel lookup
3、Parallel page table walks
Skewing
歪斜TLB来源于歪斜Cache,基本思想是改变TLB中set的概念。
暂时先略过
6 Page Table Walks
一开始alpha系统采用硬件管理的translation walk,后来sparc和arm使用软件walk,最后供应商再次采用了硬件翻译walk。
Software approaches
TSBs(Translation storage buffers)被用来加速软件地址翻译。TSB是一个软件cache(通常是直接映射的),存储了pagetable常用的的部分。如果在TSB中命中,就可以直接返回,而不需要遍历四级页表。虽然TSB大小可以动态变换,但实际的TSB一般都是固定大小的。
pom-tlb的那篇论文中的pom-tlb和TSB很相似,他们都把页表放到了内存中,但是POM-TLB是硬件管理的,而TSB是软件管理的
Managing status bits:虽然地址翻译主要是用来virtual-to-physical的,但是也有很多状态位,如果访问一个没有权限的地址(protection bit),会出现protection fault。除此之外还有access 和 dirty bits,来维护热度信息。
Pors and cons 正方和反方
Hardware approaches
实现了一个硬件PTWs。它主要由两部分组成:1、状态机,用来理解体系结构支持的页表组织。2、PTW buffer,一个寄存器集合,用来保存未完成的tlb miss信息。类似于cache中的MSHR寄存器
PTW概念上不难理解,但是设计上有一些复杂性:1、Microcode injection 微码注入 看不懂 2、Managing status bits 好像意思是理论上只有OS可以清楚这些状态位?然后和内存一致性有关?3、Concurrent page table walks across cores:多个core可以同时遍历页表,
Pros and cons
两个缺点:1、面积和能耗、在最近研究中发现这个不是特别严重;2、由于PTW的状态机固定,所以页表格式也被固定了。
优点:消除了OS上下文切换,以及:1、Overlapping TLB misses with useful work: 大致就是对乱序处理器的支持;2、Concurrently handling multiple misses
Hybrid approaches
armv7+linux中,使用了混合页表,linux维护两个页表,一个软件管理的页表,一个硬件管理的页表(MMU也可以访问)。tlb miss时,硬件ptw回启动,但是ptws不能设置dirty和access位,只有当软件页表被标记为writable和dirty时,硬件可以有权模拟dirty位。(没看太懂)。好处是,tlb miss时可以由硬件快速处理,同时操作系统可以维护access/dirty状态位,可以更好地跟踪页面热度。
课后习题
关于虚拟化
7 Memory Management Unit Caches
MMU cache或者prefix caches被用来减少页表遍历延迟。
MMU的设计方法:1、类似于传统数据cache,每个entry存储一个页表entry,并使用内存驻留页表(memory-resident page table)中相应位置的物理地址进行标记。例如amd的ptw。2、intel 按部分虚拟地址进行索引,称为分页结构缓存(paging structure caches)
page walk caches 用页表中的pa做tag。(Each entry in a page walk cache is tagged with the physical address in the page table.),x86-64的L1 entry没有被缓存到page walk cache中,因为他们被缓存到了TLB中(不太懂)
1、Unified page walk caches 将所有upper page table levels的pte都放在一起
2、Split page walk caches 针对不同level的pte,单独存放
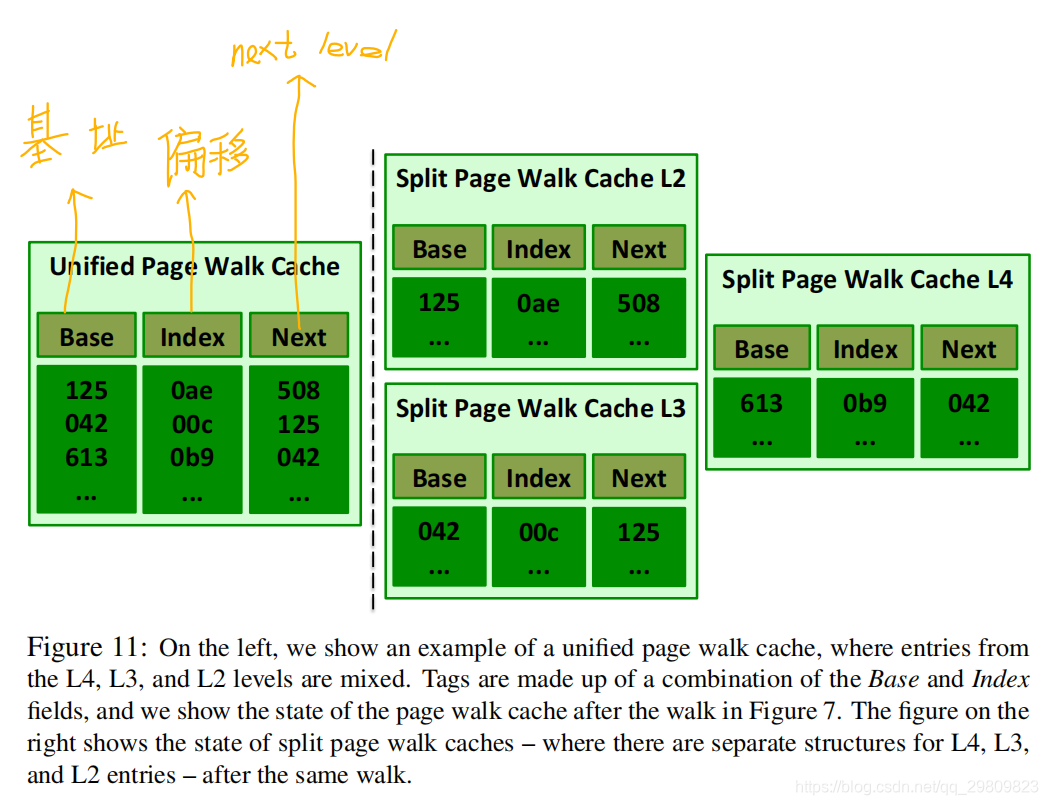
Paging structure caches 用虚拟地址做tag。可以并发地进行L4,L3,L2地查找,因为我们一开始就得到了所有索引地址。
1、Unified paging structure caches
按最长前缀匹配,如下图左,0b9的next level时042,0b9 00c的next是125
2、Split paging structure caches

Translation path caches 感觉时为了减少空间,如下图,按最长前缀匹配。

Design comparison
1、Indexing:通过va或者pa做tag。如page walk caches使用pa,优点:本质类似于传统cache,但因为专注于上层页表项,所以易于设计。缺点:需要多次查找翻译,不能并发查询。
2、Coverage:具体说不清
8 MMU Integration: Putting Everything Together
为了便于讨论,假设an MMU that integrates with a virtually-indexed, physically-tagged L1 cache, and the use of hardware PTWs.
1 Load/store queue to TLB
cpu把读写请求插入load/store队列是第一次与地址翻译硬件进行交互。商业并未披露过多这方面的信息,作者是根据已有资料进行合理推测。
预测和消除歧义。预测阶段
2 TLB hierarchy to cache hierarchy
3 Page table walker to MMU caches and cache hierarchy
4 Faults
5 Memory replay
Post TLB miss
Post page fault
9 Translation Prefetching
Cache-line prefetching
Sequential prefetching
Arbitrary stride prefetching
Markov perfetching
Recency-based prefetching
10 Replay Prefetching
11 Translation Contiguity
OS-generated translation contiguity
Coalescing
Complete sub-blocking
Partial sub-blocking
Integrating contiguity optimizations in the MMU
12 Conclusion
- Shared address translation structures
- TLB speculation
- Part-of-memory TLB optimizations
- Direct segment, range optimizations, superpages
- Software optimizations
- Energy-efficient address translation
- Translation coherence
- Virtualization [3, 15, 29, 37, 68, 93]
- Accelerators [7, 8, 29, 39, o69, 70, 72, 81, 87, 94], near-memory accelerators [71], and more [33]
- Memory protection