一、说明
这里说的 ControlNet不是工业控制的控制网络,而是深度学习的神经网络植入某些控制环节,它是 2023 年 ML 领域最大的成功案例之一。这是一种简单,可解释的方式来对扩散模型的输出施加影响的模型。
二、ControlNet 是什么?
ControlNet 是 2023 年 ML 领域最大的成功案例之一。该项目在GitHub上获得了21,000+星,在CVPR风靡一时 - 这是有充分理由的:这是一种简单,可解释的方式来对扩散模型的输出施加影响。
与其在同一个提示符上一遍又一遍地运行相同的扩散模型,希望得到合理的结果,不如通过输入图引导模型。因此,ControlNet厚颜无耻的标语是:“让我们控制扩散模型!有独特的 ControlNet 模型可以通过 Canny 边缘贴图、分割掩码、姿势关键点甚至涂鸦来“控制”输出。

通过带有提示“”的涂鸦地图控制稳定的扩散。图片来自 ControlNet 1.0 GitHub 存储库。
使ControlNet如此受欢迎的功能之一是它的可访问性。在千亿参数基础模型的时代,ControlNet 模型只有 1.45GB(与底层扩散模型大小相同)。在像 GPT-3.5 这样的模型以数十万甚至数百万美元的成本在数万个 GPU 上进行训练的时候,ControlNet 模型可以在短短 600 个 GPU 小时内在家中在单个 GPU 上进行训练!换句话说,您可以训练自己的 ControlNet 模型。
尽管ControlNet 1.0取得了巨大的成功,但该模型还是遇到了一些相当不幸的错误。下面是一个示例:

控制网 1.0 的故障模式图示。左:输入图像。右:具有高控制网“权重”的输出,导致颜色过饱和。
虽然对于大多数输入,模型产生了令人惊叹的逼真图像,但在某些情况下,例如上面的场景,模型的输出明显过饱和。
当 ControlNet 的创建者 Lvmin Zhang发布 ControlNet 1.1 并解决这些问题时,变化是如此之大,以至于他创建了一个全新的 GitHub 存储库!

控制网 1.1 中的问题解决。左:与上图相同的基本图像。右:输入与上述过饱和的 ControlNet 1.0 情况相同的提示和元数据时的输出。
最疯狂的部分:模型架构没有变化。
发生了什么变化?数据质量!
事实证明,用于训练ControlNet 1.0的数据存在一些阴险的缺陷,包括一群灰度的人以某种方式被复制了数千次。ControlNet 1.1 存储库明确提到了这个问题和其他问题。
教训:
数据至高无上。最先进的性能高质量数据。
在这篇博文中,我将向您展示如何清理和管理高质量的数据,以便您可以训练自己的最先进的 ControlNet 模型。
可以在此处找到遵循和管理您自己的图像标题数据集所需的所有代码。
如果你急切,你可以直接跳到亮点:
三、设置
清理和管理这些数据所需的唯一库是pandas(用于表格数据)和FiftyOne(用于非结构化图像数据):
pip install pandas fiftyone此外,您将需要hashlib来执行辅助函数,并且您可能希望tqdm在下载图像时跟踪进度。
您可以导入所有必需的模块,如下所示:
import hashlib
import pandas as pd
from tqdm.notebook import tqdm
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.brain as fob
from fiftyone import ViewField as F四、选择数据集
根据介绍 ControlNet 的论文,将条件控制添加到文本到图像扩散模型 (CVPR 2023),最初的 ControlNet 模型是在“来自互联网的 3M 图像标题对”上进行训练的。
不幸的是,Lvmin 等人没有确切地透露他们使用的数据:
“鉴于目前研究界以外的复杂情况,我们避免透露有关数据的更多细节。尽管如此,研究人员可能会看看每个人都知道的数据集项目。- 张璐璐
话虽如此,他们透露的信息与谷歌的概念字幕数据集密切相关:一个“由~3.3M图像组成并带有字幕注释”的数据集。无论这是否是 ControlNet 团队用于训练其模型的数据集,概念标题都将为我们提供说明性示例,并且数据集 - 如果清理得当 - 应该允许从头开始训练 ControlNet 模型。
五、下载数据集
谷歌提出的数据集下载过程太麻烦了,不符合我的口味:首先,你需要下载一个制表符分隔的变量()文件,其中包含标题和可以找到相应图像的URL,然后你需要从他们的URL下载图像。幸运的是,我已经编写了这段代码,所以您不必这样做。.tsv
通过点击 Google 概念字幕网页底部的“下载”按钮或点击此链接下载文件。tsv
我们可以以类似于 的方式将文件加载为 pandas,通过传入以指定分隔符是一个制表符。tsvDataFramecsvsep=\t
df = pd.read_csv("Train_GCC-training.tsv", sep='\t') 给出描述性名称的列:DataFrame
df.columns =['caption', 'url']然后对每个条目的 url 进行哈希处理以生成唯一的 ID:
def hash_url(url):
return hashlib.md5(url.encode()).hexdigest()[:12]
df['url_hash'] = df['url'].apply(hash_url)看起来像这样:DataFrame
caption url url_hash
0 sierra looked stunning in this top and this sk... http://78.media.tumblr.com/3b133294bdc7c7784b7... e7023a8dfcd2
1 young confused girl standing in front of a war... https://media.gettyimages.com/photos/young-con... 92679c323fc6
2 interior design of modern living room with fir... https://thumb1.shutterstock.com/display_pic_wi... 74c4fa5539f4
3 cybernetic scene isolated on white background . https://thumb1.shutterstock.com/display_pic_wi... f1ea388e05e1
4 gangsta rap artist attends sports team vs play... https://media.gettyimages.com/photos/jayz-atte... 9a6f8026f593
... ... ... ...
3318327 the teams line up for a photo after kick - off https://i0.wp.com/i.dailymail.co.uk/i/pix/2015... 6aec77a477f9
3318328 stickers given to delegates at the convention . http://cdn.radioiowa.com/wp-content/uploads/20... 7d42aea90652
3318329 this is my very favourite design that i recent... https://i.pinimg.com/736x/96/f0/77/96f07728efe... f6dd151121c0
3318330 man driving a car through the mountains https://www.quickenloans.com/blog/wp-content/u... ee4244df5c55
3318331 a longtail boat with a flag goes by spectacula... http://l7.alamy.com/zooms/338c4740f7b2480dbb72... 7625946297b7我们将使用这些 ID 来指定图像的下载位置(文件路径),以便我们可以将标题与相应的图像相关联。
如果我们想批量下载图像,我们可以这样做,如下所示:
def download_batch(df, batch_size=10000, start_index=0):
batch = df.iloc[start_index:start_index+batch_size]
for j in tqdm(range(batch_size)):
url, uh = batch.iloc[j][['url', 'url_hash']]
!curl -s --connect-timeout 3 --max-time 3 "{url}" -o images/{uh}.jpg 在这里,我们将图像从 下载到 文件夹 ,文件名由我们上面生成的 url 哈希指定。我们用于执行下载操作,并为尝试下载每个图像所花费的时间设置限制,因为某些链接不再有效。batch_sizestart_indeximagescurl
要下载总共的映像,请运行以下命令:num_images
def download_images(df, batch_size=10000, num_images = 100000):
for i in range(num_images//batch_size):
download_batch(df, batch_size=batch_size, start_index=i*batch_size)六、加载和可视化数据
将图像下载到文件夹中后,我们可以将图像及其标题加载为 FiftyOne:imagesDataset
dataset = fo.Dataset(name="gcc", persistent=True)
dataset.add_sample_field("caption", fo.StringField)
samples = []
for i in tqdm(range(num_images)):
caption, uh = df.iloc[i]['caption'], df.iloc[i]['url_hash']
filepath = f"images/{uh}.jpg"
sample = fo.Sample(
filepath=filepath,
caption=caption
)
samples.append(sample)
dataset.add_samples(samples) 此代码创建一个名为“gcc”的“gcc”,该代码持久化到底层数据库,然后遍历熊猫的第一行,创建具有适当文件路径和标题的 。Datasetnum_imagesDataFrameSample
在本演练中,我下载了大约 310,000 张图像。
在检查新的计算机视觉数据集时,我们应该采取的第一步是将其可视化!我们可以通过启动 FiftyOne 应用程序来做到这一点:
session = fo.launch_app(dataset)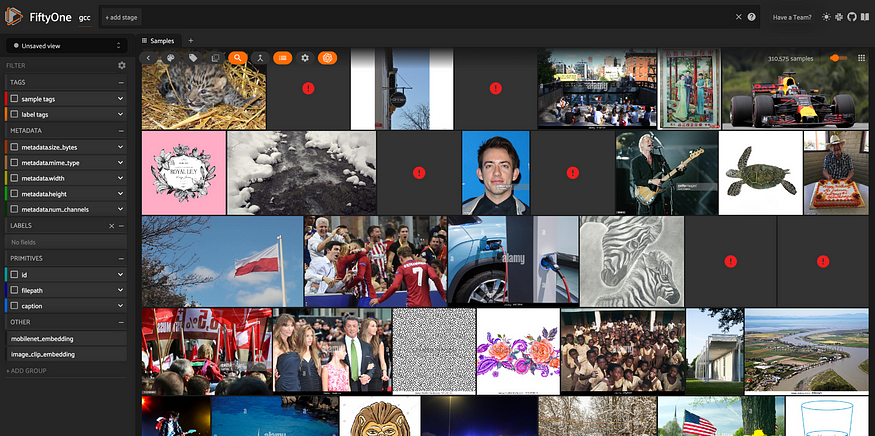
所有 310,000+ 张图片都来自 Google 的概念字幕数据集,在 FiftyOne 应用程序中可视化。
七、删除损坏的样本
当我们查看数据时,我们可以立即看到某些图像无效。这可能是由于链接不再有效、下载过程中中断或完全其他一些问题。
幸运的是,我们可以轻松过滤掉这些无效图像。在 FiftyOne 中,该方法为每个样本计算特定于媒体类型的元数据。对于基于图像的示例,这包括图像宽度、高度和大小(以字节为单位)。compute_metadata()
当媒体文件不存在或损坏时,元数据将保留为空。因此,我们可以通过运行和匹配元数据存在的样本来过滤掉损坏的图像:compute_metadata()
dataset.compute_metadata()
## view containing only valid images
view = dataset.exists("metadata")
session = fo.launch_app(view)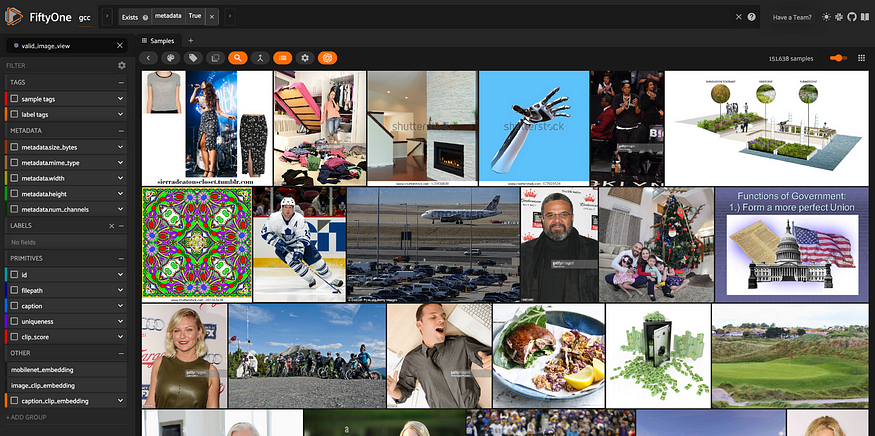
仅包含未损坏的图像及其元数据的数据集视图。
八、按纵横比筛选
我们可能想要采取的下一步是过滤掉具有异常纵横比的样本。如果我们的目标是控制扩散模型的输出,我们可能只处理一定范围内合理纵横比的图像。
我们可以使用 五十一的 ,它允许我们将任意表达式应用于样本的属性,然后基于这些属性进行过滤。例如,如果我们想丢弃所有在任一维度上比在另一个维度中大两倍以上的图像,我们可以使用以下代码来实现:ViewField
from fiftyone import ViewField as F
long_filter = F("metadata.width") > 2*F("metadata.height")
tall_filter = F("metadata.height") > 2*F("metadata.width")
aspect_ratio_filter = (~long_filter) & (~tall_filter)
view = valid_image_view.match(aspect_ratio_filter)为了清楚起见,丢弃的样本如下所示:
bad_aspect_view = valid_image_view.match(~aspect_ratio_filter)
session = fo.launch_app(bad_aspect_view)
包含具有非典型纵横比的图像的视图,我们将其从训练数据中删除。
如果您愿意,您可以使用或多或少严格的纵横比滤镜!
九、按分辨率筛选
同样,我们可能希望删除低分辨率图像。我们希望生成令人惊叹的逼真图像,因此在训练数据中包含低分辨率图像是没有意义的。
此筛选器类似于纵横比筛选器。如果我们选择 300 像素作为允许的最低宽度和高度,则过滤器采用以下形式:
hires_filter = (F("metadata.width") > 300) & (F("metadata.height") > 300)
view = good_aspect_view.match(hires_filter)再一次,您可以选择您喜欢的任何阈值。为清楚起见,以下是丢弃图像的代表性视图:
lowres_view = good_aspect_view.match(~hires_filter)
session = fo.launch_app(lowres_view)
包含小图像和低分辨率图像的视图,这些图像将从训练数据中移除。
十、确保调色板
查看低分辨率图像,我们也可能会被提醒,我们数据集中的某些图像是灰度的。我们可能希望生成尽可能生动的图像,因此我们应该丢弃黑白图像。
在 FiftyOne 中,图像元数据中记录的属性之一是通道数:彩色图像有三个通道 (RGB),而灰度图像只有一个通道。删除灰度图像就像匹配具有三个通道的图像一样简单!
## color images to keep
view = view.match(F("metadata.num_channels") == 3)
## gray images to discard
gray_view = view.match(F("metadata.num_channels") == 1)
session = fo.launch_app(gray_view)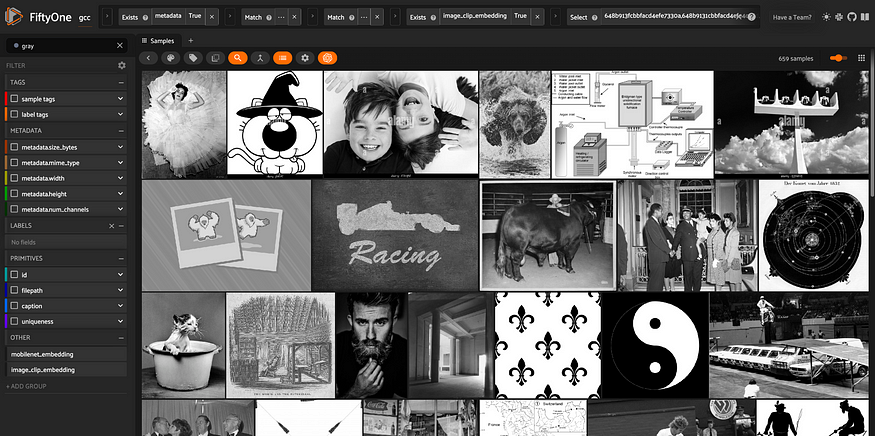
由灰度图像组成的数据集视图,随后从训练数据中删除这些图像。
十一、对数据集进行重复数据删除
我们在数据管理任务中的下一个任务是删除重复的图像。当图像在训练数据集中完全或近似复制时,生成的模型可能会被这一小组过度表示的样本所偏向——更不用说增加的训练成本了。
我们可以通过使用模型为图像生成嵌入来找到数据集中的近似重复项(我们将使用 CLIP 模型进行说明):
## load CLIP model from the FiftyOne Model Zoo
model = foz.load_zoo_model("clip-vit-base32-torch")
## Compute embeddings and store them in embeddings_field
view.compute_embeddings(
model,
embeddings_field = "image_clip_embedding"
)然后我们基于这些嵌入创建一个相似性索引:
results = fob.compute_similarity(view, embeddings="image_clip_embedding")最后,我们可以设置一个数字阈值,此时我们将考虑图像近似重复(这里我们选择 0.3),并且每组近似重复项只保留一名代表:
results.find_duplicates(thresh=0.3)
# view the duplicates, paired up
dup_view = results.duplicates_view()
session = fo.launch_app(dup_view, auto = False)
View 包含我们数据集中的精确和近似重复项。为了对数据进行重复数据删除,我们从每组近似重复图像以及所有高度独特的图像中获取一张具有代表性的图像。
十二、验证图像标题对齐
好的,现在你很幸运,因为我们把最酷的步骤留到了最后!
谷歌的概念字幕数据集由来自互联网的图像-字幕对组成。更准确地说,“原始描述是从与 Web 图像关联的替代文本 HTML 属性中收获的”。作为初始传递,这很棒,但其中肯定会有一些低质量的字幕。
我们可能无法确保所有字幕都能完美地描述其图像,但我们当然可以过滤掉一些对齐不良的图像字幕对!
我们将使用 CLIPScore 来做到这一点,这是一个“图像字幕的无参考评估指标”。换句话说,您只需要图像和标题。CLIPScore很容易实现。首先,我们使用 Scipy 余弦距离法定义一个余弦相似函数:
from scipy.spatial.distance import cosine as cosine_distance
def cosine(vector1, vector2):
return 1. - cosine_distance(vector1, vector2) 然后我们定义一个函数,它接受一个,并计算存储在样本上的图像嵌入和标题嵌入之间的 CLIPScore:Sample
def compute_clip_score(sample):
image_embedding = sample["image_clip_embedding"]
caption_embedding = sample["caption_clip_embedding"]
return max(100.*cosine(image_embedding, caption_embedding), 0.)从本质上讲,此表达式只是将分数下限为零。缩放因子 100 与 PyTorch 使用的比例相同。
然后,我们可以计算 CLIPScore——我们衡量图像和标题之间对齐度的度量——方法是将字段添加到我们的数据集并迭代我们的样本:
dataset.add_sample_field("caption_clip_embedding", fo.VectorField)
dataset.add_sample_field("clip_score", fo.FloatField)
for sample in view.iter_samples(autosave=True, progress=True):
sample["caption_clip_embedding"] = model.embed_prompt(sample["caption"])
sample["clip_score"] = compute_clip_score(sample)
view.save()如果我们想查看“最不对齐”的样本,我们可以按“clip_score”排序。
## 100 least aligned samples
least_aligned_view = view.sort_by("clip_score")[:100]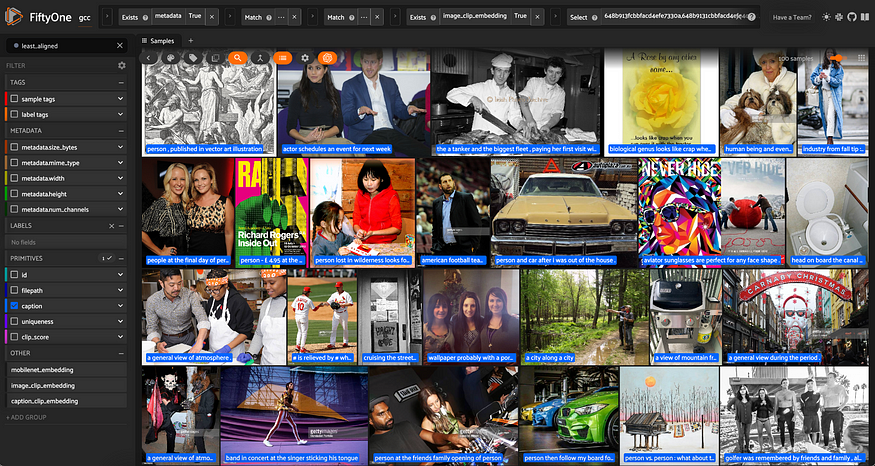
显示图像标题对齐方式最低的示例的数据集视图。标题显示在图像上。
要查看最对齐的样本,我们可以做同样的事情,但传入:reverse=True
## 100 most aligned samples
most_aligned_view = view.sort_by("clip_score", reverse=True)[:100]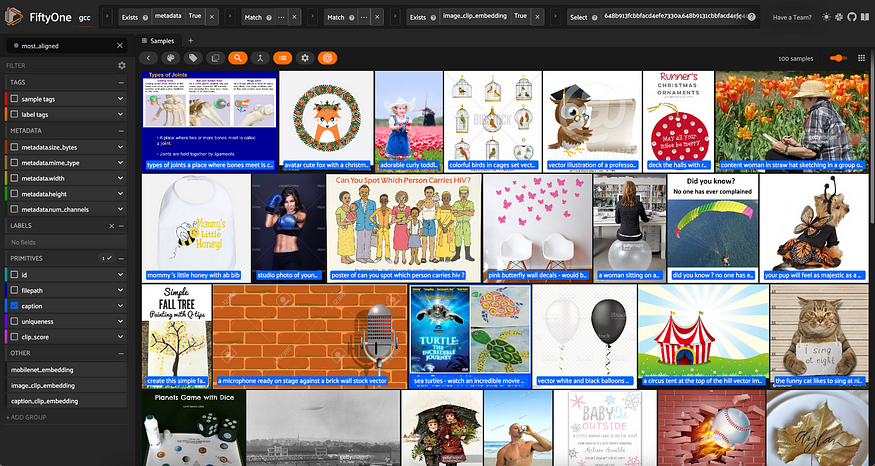
显示具有最高图像标题对齐方式的示例的数据集视图。标题显示在图像上。
然后,我们可以设置 CLIPScore 阈值,具体取决于我们要求图像标题对的对齐程度。按照我的口味,21.8 的阈值似乎足够了:
view = view.match(F("clip_score") > 21.8)
gcc_clean = view.clone(name = "gcc_clean", persistent=True) 第二行将视图克隆为名为“gcc_clean”的新持久。Dataset
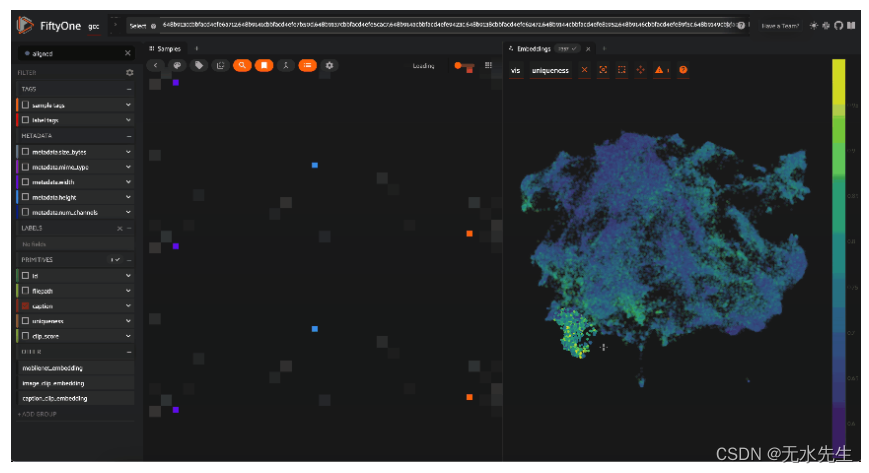
十三、结论
经过数据清理和整理,我们将一个相对平庸的初始数据集(超过 310,000 个样本)变成了包含 83,181 个样本的高质量数据集。我们的劳动成果是这样的:
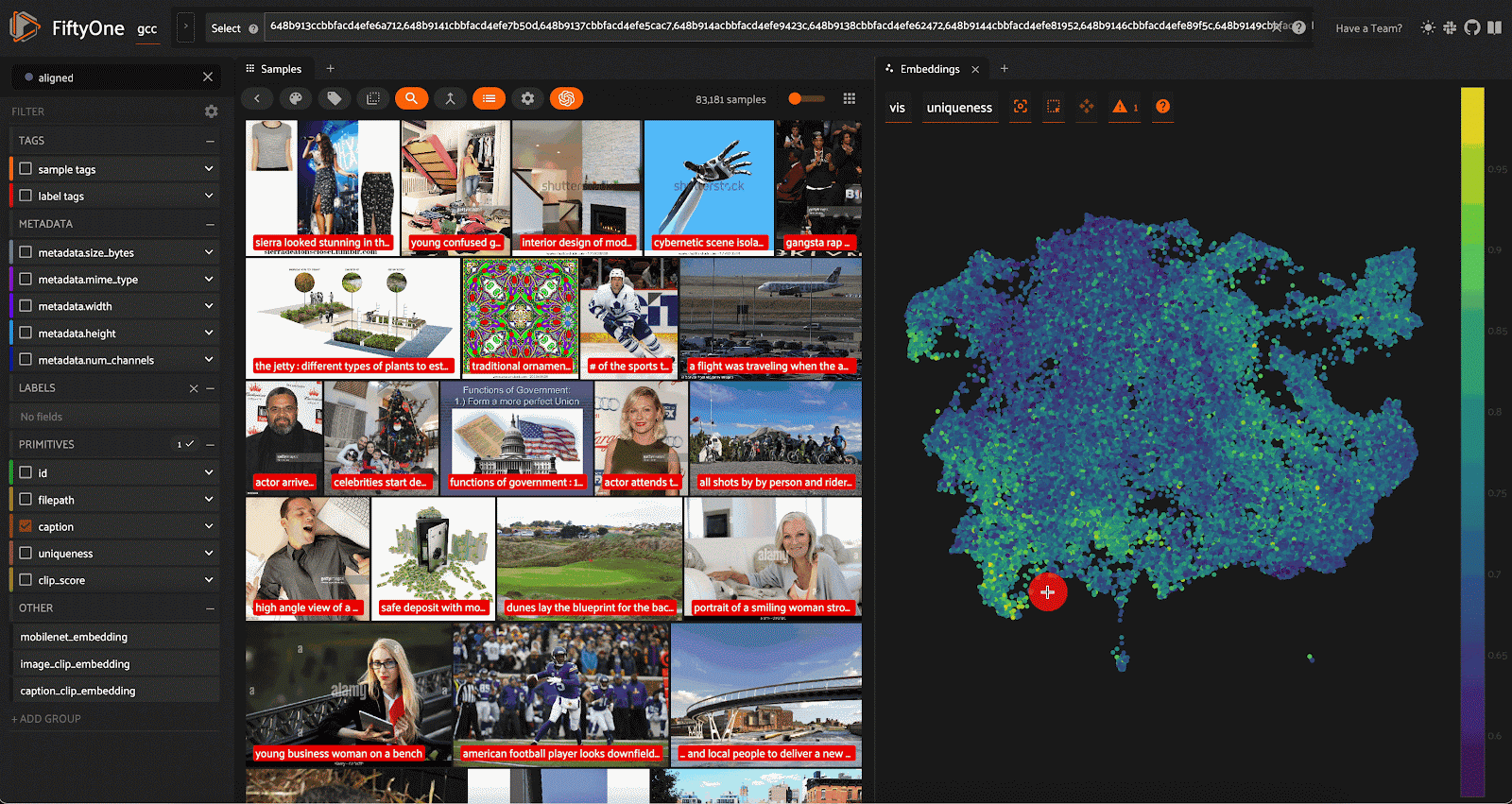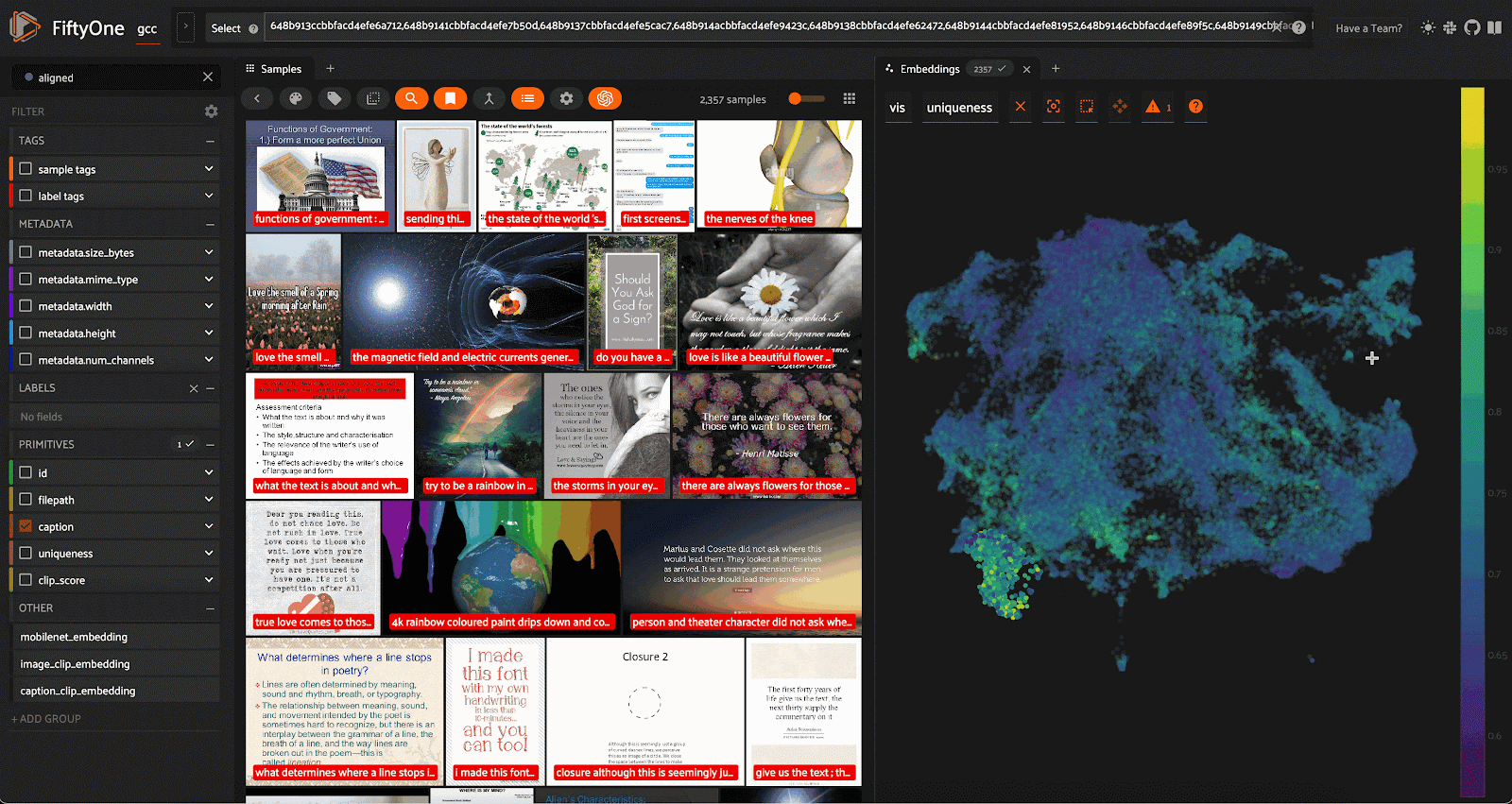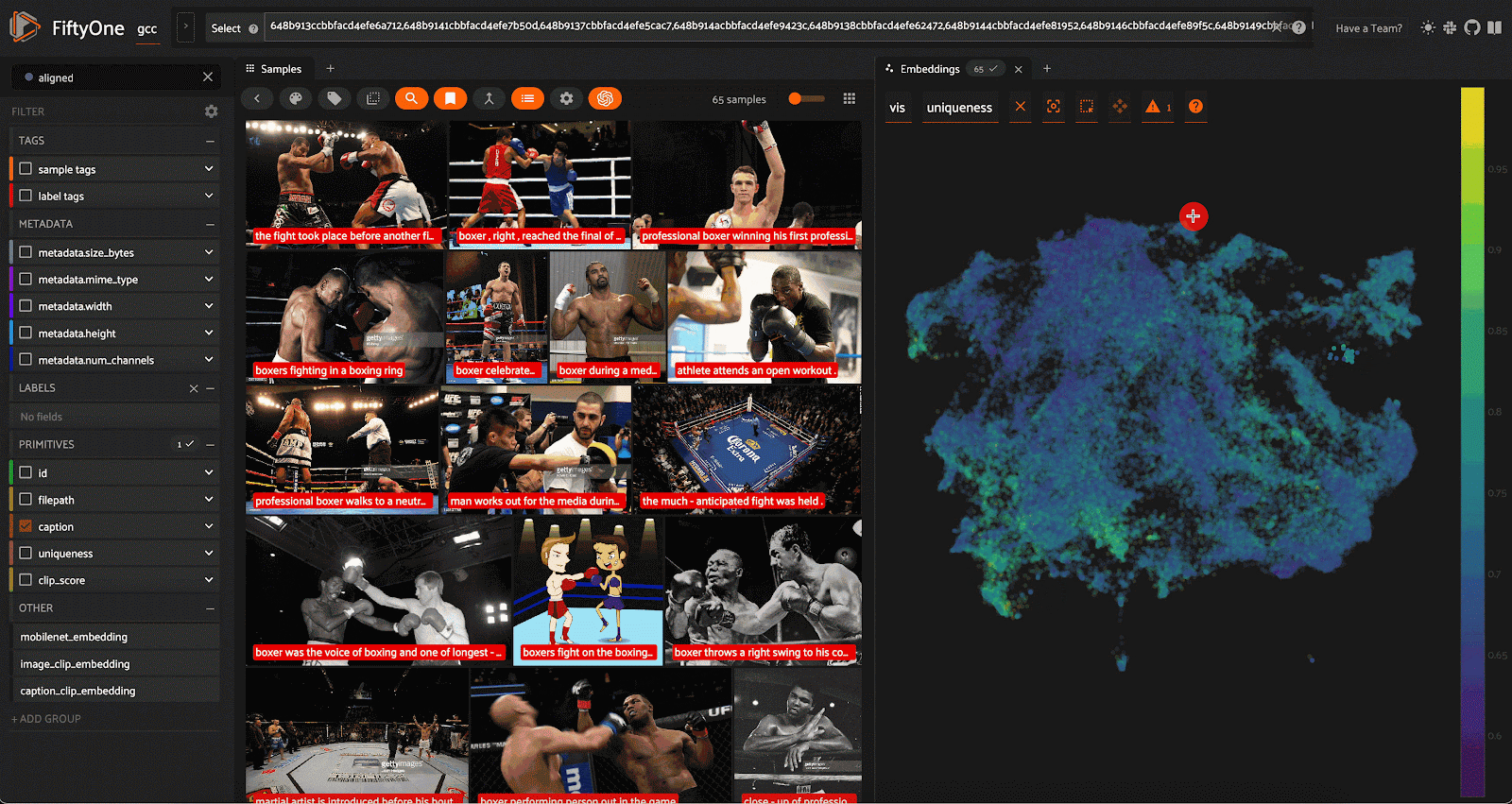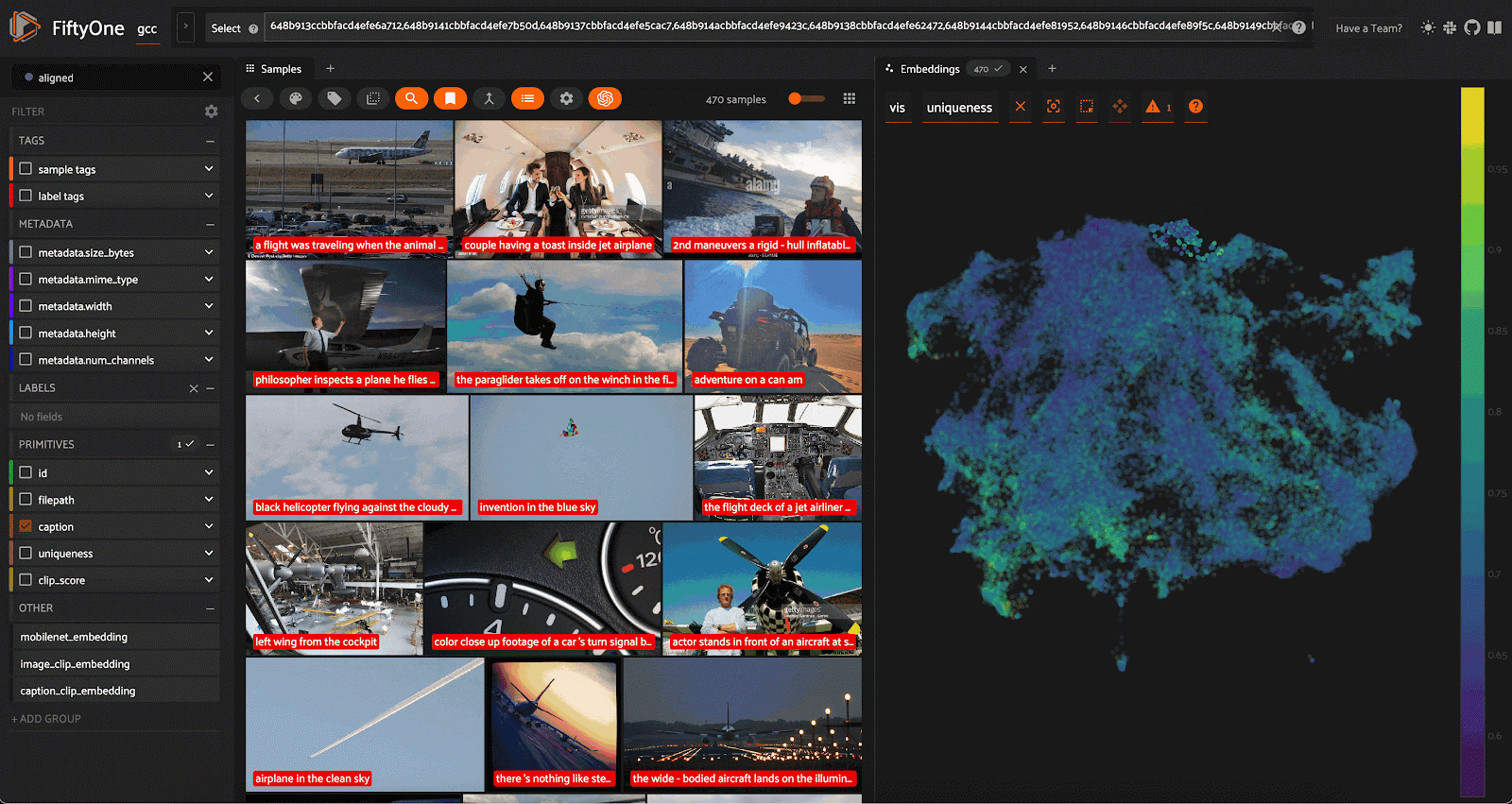
最终视图显示从 Google 概念字幕数据集中清理和精选选择的示例。
我们当然没有创建一个完美的数据集——一个完美的数据集不存在。我们所做的是解决困扰ControlNet 1.0的所有数据质量问题,再加上一些问题,只是为了更好地衡量。
现在,您已准备好训练自己的最先进的 ControlNet 模型!
注意:这篇文章改编自我上周在CVPR上展示的Flash会议!