一 基本介绍
在我们目前的开发中,微服务架构体系使用是很普遍的,如果让前端直接访问各个微服务系统,那么对于微服务的治理将会很不方便,如果使用nginx进行路由转发,一些复杂的业务校验是没办法实现的。所以我们就要引入网关的概念,将一些公共的请求校验,响应处理以及流控规则整合在网关层,会使得我们的服务治理变得简单方便,无需去关注每个微服务,只需要去关注网关即可。
目前常见的网关有以下几种,我们进行一下对比:
Zuul 1.x:它是基于Servlet框架构架,也就造成了一个线程处理一次连接请求,这种方式存在一些问题,例如:内部延迟严重,设备故障较多情况下会引起存活的链接增多和线程增加的情况。
Zuul 2.x:是对zuul 1.x的优化,是在2019年5月份进行的发布,采用了Netty实现异步非阻塞变成模型,解决了1.x中存在的问题。每个CPU核一个线程处理所有的请求和响应,请求和响应的生命周期是通过事件和回调处理的。
nginx+lua:使用nginx的反向代理和负载均衡可以实现入口的统一以及服务的高可用,使用lua脚本可以实现简单的逻辑处理,但是它没办法融入到现有的spring cloud体系中,也没办法实现一些复杂的业务逻辑。例如,整合nacos,sentinel等组件,无法进行登录校验等等。
Gateway:gateway是在Zuul 1.x的时期出现,它的目的就是取代Zuul,因为Zuul 1.x存在的一些问题无法满足spring cloud架构的要求,因此就诞生了Gateway。它的底层也是使用Netty实现,它的性能是Zuul 1.x的1.6倍,内置了很多功能,例如转发,监控等。
Gateway使用中会涉及到以下几个重要的信息,是通过这些信息完成路由转发,业务逻辑处理:
id:每个路由的唯一性标识
uri:网关接收到请求以后转发到的实际地址;
order:用于多个路由之间的顺序,数值越小,顺序越前;
predicate:断言,作用是进行条件匹配,只有断言匹配通过以后,才会进行路由转发;
filter:过滤器,用于对请求或者响应数据进行处理,例如鉴权,报文转换等;
Gateway的一次请求执行流程如下:1.Gateway server接收到请求; 2.请求会被HttpWebHandllerAdapter进行提取组装网关上下文; 3.然后网关的上下文会传递到DispatcherHandler,它负责将请求分发给RoutePredicateHandlerMapping;4.RoutePredicateHandlerMapping进行路由查找,然后判断是否符合断言条件;5.如果断言判断成功,则由FilteringWebHandler创建过滤链并调用;6.请求会经过PreFilter->微服务->PostFilter,最终进行返回。执行流程图如下:

接下来我们看一下使用网关时的微服务架构图,只是一个简化的,实际场景会更加复杂:

二 Gateway使用
1 基本使用
在使用gateway之前,我们需要先搭建一个spring cloud架构的微服务,我这里使用了nacos作为注册中心,本文只对gateway进行介绍。先创建一个普通spring boot项目,然后引入以下依赖:
在dependencyManagement中引入以下依赖:
<dependencyManagement>
<dependencies>
<!-- alibaba的相关组件 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- cloud原生的相关组件 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>这里需要注意版本的对应关系,其中alibaba对应的版本可以去nacos的文章中查看,cloud原生的对应版本从这里进行查看:spring cloud与spring boot版本对应
然后再引入以下依赖,就可以使用GateWay的基本功能:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>引入上述依赖以后,我们接下来修改配置文件,这里是最基本的配置,后面我们会具体介绍里面的详细配置:
spring:
cloud:
gateway:
routes:
- id: gateway-test #路由Id,可以自己随意命名,只要保证id唯一即可
uri: http://ip:port/ #转发到的具体地址
predicates: # 断言
- Path=/self/** #断言规则,这里是路径匹配规则,**代表的是任意字符。
2 负载均衡
在目前的微服务架构中,每个微服务都会部署多个节点,那么网关时如何实现路由的呢?Gateway实现路由的方式有两种,一种是自动实现,一种是手动实现。
因为这里要进行负载,这里我们通过配合nacos进行使用,在实际的生产环境,都会搭配注册/发现中心进行使用。我们先将nacos的对应依赖引入,详见我以前的nacos系列文章,然后再配置文件中添加nacos的注册信息。
接下来我们先看自动实现的方式,需要在配置文件中进行以下配置:
spring:
cloud:
# nacos注册与发现的相关配置
nacos:
discovery:
server-addr: 127.0.0.1:8848
gateway:
discovery:
locator:
enabled: true #开启自动路由功能,默认为false自动实现就是将上面的自动路由配置打开,然后结合nacos进行使用,在我们往nacos中进行注册的时候,都会注册一个${application.name},自动实现就是通过这个值进行处理,假如我们现在有一个请求要转发到${application.name}为gateway-client的服务中心,现在gateway-client服务节点有两个,接口地址为/self/test,那么我们直接访问http://{网关地址}/gateway-client/self/test,这样就会通过网关访问到gateway-client的服务上,并且自动实现负载均衡。但是这种方式有一个问题就是会将服务名称暴露在请求路径上面,所以我们一般不会使用这种方式。
第二种,手动实现,首先我们还是先来看配置文件:
spring:
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
gateway:
routes:
- id: gateway-client #路由Id,保证唯一性
uri: lb://gateway-client # 跳转服务地址,通过注册中心匹配服务,并实现负载均衡
predicates: #断言
- Path=/self/** 这种方式,需要我们在配置文件的uri位置不再配置http地址,而是采用lb://{调用服务在nacos中的注册名称},这样当我们访问http://{网关地址}/self/test的时候,路由就会转发到我们对应的微服务上并且实现负载均衡。这里有一点需要注意,如果配置了路由规则,那么路由规则的优先级大于自动路由。
3 断言
在上面介绍基本概念的时候提到过断言,他是用来进行判断转发的,只有断言校验通过,才能路由到对应的地址。在Gateway中一共有十二种断言,接下来我们通过以下的一段配置文件对这十二种断言进行说明。
spring:
cloud:
gateway:
routes:
- id: nacos-client #路由Id,保证唯一性
uri: lb://nacos-client # 跳转服务地址,通过注册中心匹配服务,并实现负载均衡
predicates: #断言
# 第一种,访问路径匹配,这是最基本的一种匹配方式,只要访问的路径能够匹配上,则进行路由转发
- Path=/self/**
# 第二种,在指定时间之前访问才能通过,如果超出指定时间,则无法访问,值为具体的时间
# 第三种,After代表在指定时间之后才能访问,使用方式和Before一样
# 第四种,Between标识在指定时间段之内才能访问,开始时间与结束时间之间使用“,”分割
- Before=2022-08-04T20:20:40.675+08:00[Asia/Shanghai]
# 第五种,Cookie匹配,他后面需要匹配两个参数,使用“,”分割,第一个参数cookie中的一个那么,第二个参数使用正则表达式,代表的是这个name对应的值应该满足的规则
# 下面这个规则代表的意思是,cookie中字段name对应的值必须是字母
- Cookie=name,[a-z]+
# 第六种,请求头匹配,它后面也是需要配置两个参数,使用“,”分割,第一个参数是请求头中一个字段名,第二个参数使用正则表达式,表示这个字段的值应该满足的规则
# 下面这个规则代表的是,请求头中X-Request-Id的值为数字
- Header=X-Request-Id,\d+
# 第七种,请求来源,限制调用改接口的host必须满足的要求
- Host=**.mashibing.com
# 第八种,接口调用方式,允许配置多个,使用“,”分割,下面代表的GET/POST请求
- Method=GET,POST #匹配get请求或者post请求
# 第九种,请求参数的匹配,后面的值可以配置必须的参数名称和一个可选的该参数值的正则匹配规则
#如果只配置一个参数,则代表请求参数中中必须要包含,配置两个参数,代表的是必须包含该参数,并且该参数的值必须符合对应的规则
- Query=id,*
# 第十种,匹配指定的ip或者ip段
- RemoteAddr=127.0.0.1/24
# 第十一种,权重匹配,单独说明
# 第十二种,根据http中中请求头中的X-Forwarded-For进行匹配
- XForwardedRemoteAddr=127.0.0.1/24
下面单独添加权重的说明
spring:
cloud:
gateway:
# 第十种,权重配置,代表的80%的请求转发到https://www.high.com,20%的请求转发到https:///www.low.com
routes:
- id: weight_high
uri: https://www.high.com
predicates:
- Weight=group1, 8
- id: weight_low
uri: https:///www.low.com
predicates:
- Weight=group1, 2有的同学可能会有疑问,如果针对cookie的转发要匹配多个值该怎么办呢?我们可以配置多个cookie断言来实现。如果在前面介绍基础概念的时候我们提到过断言链的概念,断言链中的每个节点都是一个断言规则,在这个断言链执行的时候,会校验每个断言规则,只有都校验通过,才会进行路由转发的。上面的这些断言规则来源于官网,有兴趣的同学可以去官网进行进一步学习:gateway断言使用
4 过滤器
Gateway中的过滤器的生命周期有两种,请求前以及请求后,因此我们可以对请求数据进行处理,也可以对响应数据进行处理。Gateway本身自带41中过滤器,其中32种单一过滤器(GatewayFilte)以及9种全局过滤器(GlobalFilter)。
我们接下来以一种内置过滤器来介绍它的使用方式,感兴趣的同学可以去官网了解剩下过滤器的使用规则,GatewayFilter,GlobalFilter
自带过滤器我们可以直接通过配置文件的方式进行使用,在这里使用的是StripPrefix,它属于GatewayFilter,我们看一下配置文件:
spring:
cloud:
gateway:
routes:
- id: nacos-client #路由Id,保证唯一性
uri: lb://nacos-client # 跳转服务地址,通过注册中心匹配服务,并实现负载均衡
predicates: #断言
- Path=/self/** #访问路径
filters:
# 这个过滤器代表的是,在进行路由转发的时候,去除掉访问地址中指定位置,这个位置使用/进行的分割
# 以http://127.0.0.1:9007/self/client/test,下面的意思就是将client去除,最终的访问地址为http://127.0.0.1:9007/self/test
- StripPrefix=2当然,如果Gateway只有这32中过滤器的话,他肯定无法满足我们的要求,我们在前面说过,Gateway可以实现一些服务公共的处理,例如鉴权,报文转换等。这些就是通过自定义过滤器实现的。那么接下来,我们就介绍一下自定义过滤器的编写。
@Component
// 新建一个自定义filter,它需要实现两个接口
// Ordered接口的功能是用来定义该过滤器的优先级
// GlobalFilter的功能是来编写我们具体的业务逻辑
public class SelfFilter implements Ordered, GlobalFilter {
// 具体的业务逻辑编写,这里采用伪代码的方式编写
// exchange,通过这个参数我们可以获取到请求参数以及响应参数
// chain过滤器链,将自定义过滤器添加到这个链中,以及执行过滤器链中其它的过滤器
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.通过exchange获取请求数据,可以对请求数据进行报文转换或者鉴权操作
// 如果处理失败,直接返回,并且直接退出,不再执行其它过滤器
// 2.通过exchange获取响应数据,对响应数据进行数据处理
// 3.执行下一个过滤器
return chain.filter(exchange);
}
// 数值越小,加载的优先级越高
@Override
public int getOrder() {
return 0;
}
}在上面我们介绍了网关的使用,我们是通过配置文件的方式来配置路由规则,除了配置文件以外,我们还可以使用编码的方式进行路由规则的配置,但是这种方式是不推荐的。原因是,如果是通过写代码的方式,那么路由规则与项目的耦合就会很严重,如果修改路由规则就需要修改代码并且进行发版。如果我们采用配置文件的方式,我们完全可以利用配置中心的动态刷新功能,将路由规则配置到配置中心中,然后当需要修改路由规则的时候,通过配置中心修改,这样就无须发版了。所以大家就简单了解一下还有这种方式即可
@Configuration
public class GatewayConfig {
@Bean
// 构建路由规则
public RouteLocator selfLocator(RouteLocatorBuilder routeLocatorBuilder){
// 构建routes
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
// 构建具体路由,
routes.route("gateway-client", r -> r.path("/self/**").uri("lb://")).build();
// 返回所有的路由规则
return routes.build();
}
}三 gateway整合sentinel
在以前的文章中,我们介绍过sentinel,它是用来进行服务治理,可以对服务进行限流降级,在当前的微服务架构中,我们可以对每个微服务进行单独的sentinel配置,但是这种方式,会让我们的sentinel配置过于分散,不便于管理,当然对于一些特殊的接口我们还需要配置在微服务上,录入feign接口,但是大部分接口是直接面向前端页面的,前端页面的请求都会统一打在网关上面,然后再路由到对应微服务的接口上面,针对这种接口,我们完全可以在gateway进行限流降级,那么接下来,我们就介绍gateway如何整合sentinel来实现通过网关进行限流降级。关于sentinel的集成可以参考我以前的文章,这里就不进行讲解了。我们直接来介绍网关如何使用sentinel。需要注意的是,在sentinel 1.6.0以后才支持对网关的限流。
首先我们需要引入以下依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-sentinel-gateway</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-spring-cloud-gateway-adapter</artifactId>
</dependency>接下来我们启动网关服务,看一下网关的sentinel控制台和普通服务的控制台有什么区别,以及如何使用。
下面这张图是网关的sentinel控制台,可以和sentinel使用时,其它普通项目的控制台进行比较
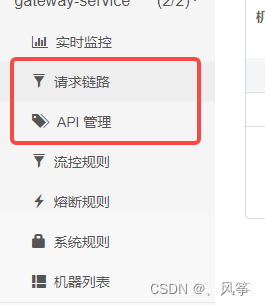
我们会发现,gateway的sentinel控制台中,有两个功能是普通项目没有的,即请求链路和API管理。
gateway网关的sentinel配置有两种方式,一种是routeId;一种是分组。那么接下来我们就分别进行讲解。
1 routeId限流方式
这种方式是最基本的一种网关限流方式,它的配置界面如下:
![]()
图中红框的位置,其实就是网关路由到的那个服务在nacos中的注册的名称。点击流控,会有以下弹窗
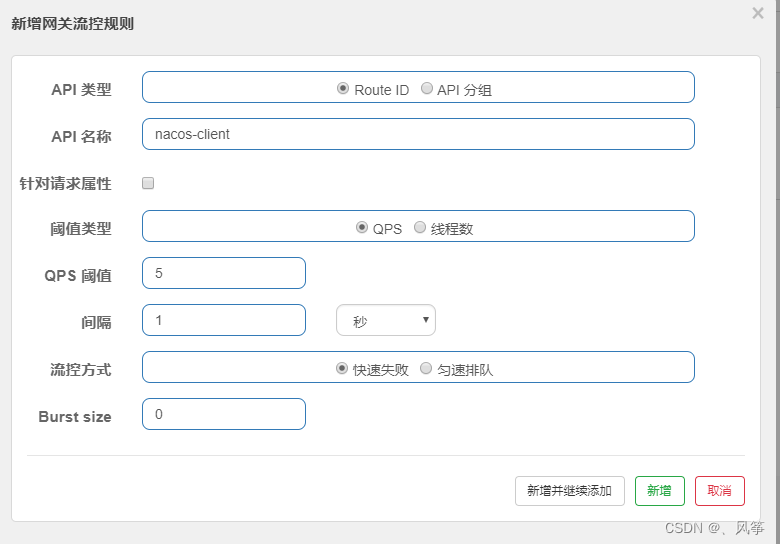
api名称我们无需改变,里面的字段和普通项目的控制台是基本一致的,只是多出来一个Burst size字段,他代表的含义是允许的阈值最大值。如果它的值小于阈值,那么他没有任何作用,只有当它的值大于阈值以后才会生效。例如qps阈值配置的是5,而Burst Size配置的是10,那么代表的就是qps在10以内就可以。
当我们使用这种方式配置以后,就代表这个服务的每个接口的qps阈值都是5。显然这种方式在生产环境中是不合适的,因为不同的接口它的访问量是不同的,如果我们统一处理,这是不友好,我们更倾向于能够精确的控制每个接口的访问量。那么这就涉及到另外一种配置方式。
2 分组限流配置
使用分组限流配置,我们需要先进入API管理,点击新增API分组:

API名称其实就是组名称,这里要求组名称具有唯一性。然后每个分组都有一个自己的分组规则。分组规则有以下三种:
精确:必须要与匹配串中的值进行精确匹配,才能进入该组中
前缀:必须要与匹配串中的值的前缀进行匹配,才能进入该组中
正则:必须要与匹配串中的值的正则表达式进行匹配,才能进入该组中
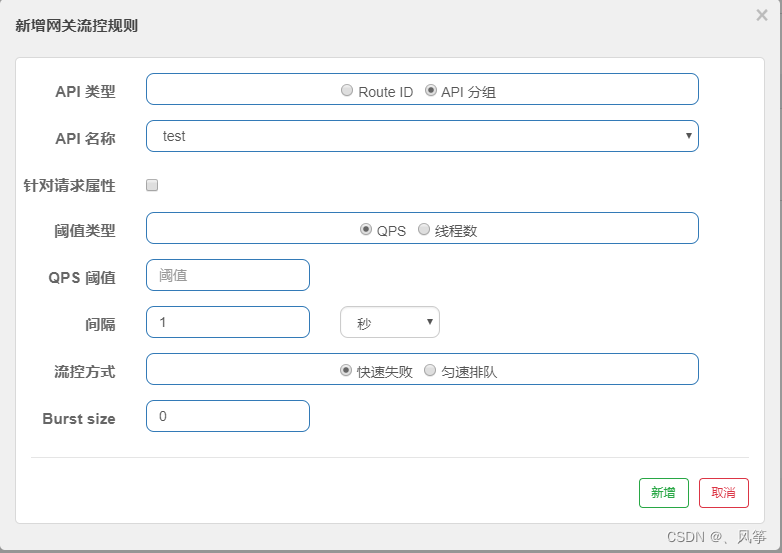
在API管理里面添加完对应的分组以后,我们进入到流控规则中,点击新增网关流控规则,里面选择API分组,然后选择对应的分组信息,进行限流规则限制即可。
关于sentinel的详细介绍,可以参考以前sentinel的相关文章。这里在生产环境进行使用时一般会搭配配置中心使用,在配置中心中配置限流规则,然后利用配置中心的动态刷新功能修改限流规则以及配置中心的限流规则持久化,防止重启以后流控规则小时。