Thread VS Groutine
这里主要介绍一下Go的并发协程相比于传统的线程 的不同点:
创建时默认的stack大小
- JDK5 以后Java thread stack默认大小为
1M - C++ 的thread stack 默认大小为
8M - Grountine 的 Stack初始化大小为
2K
所以Grountine 大批量创建的时候速度会更快
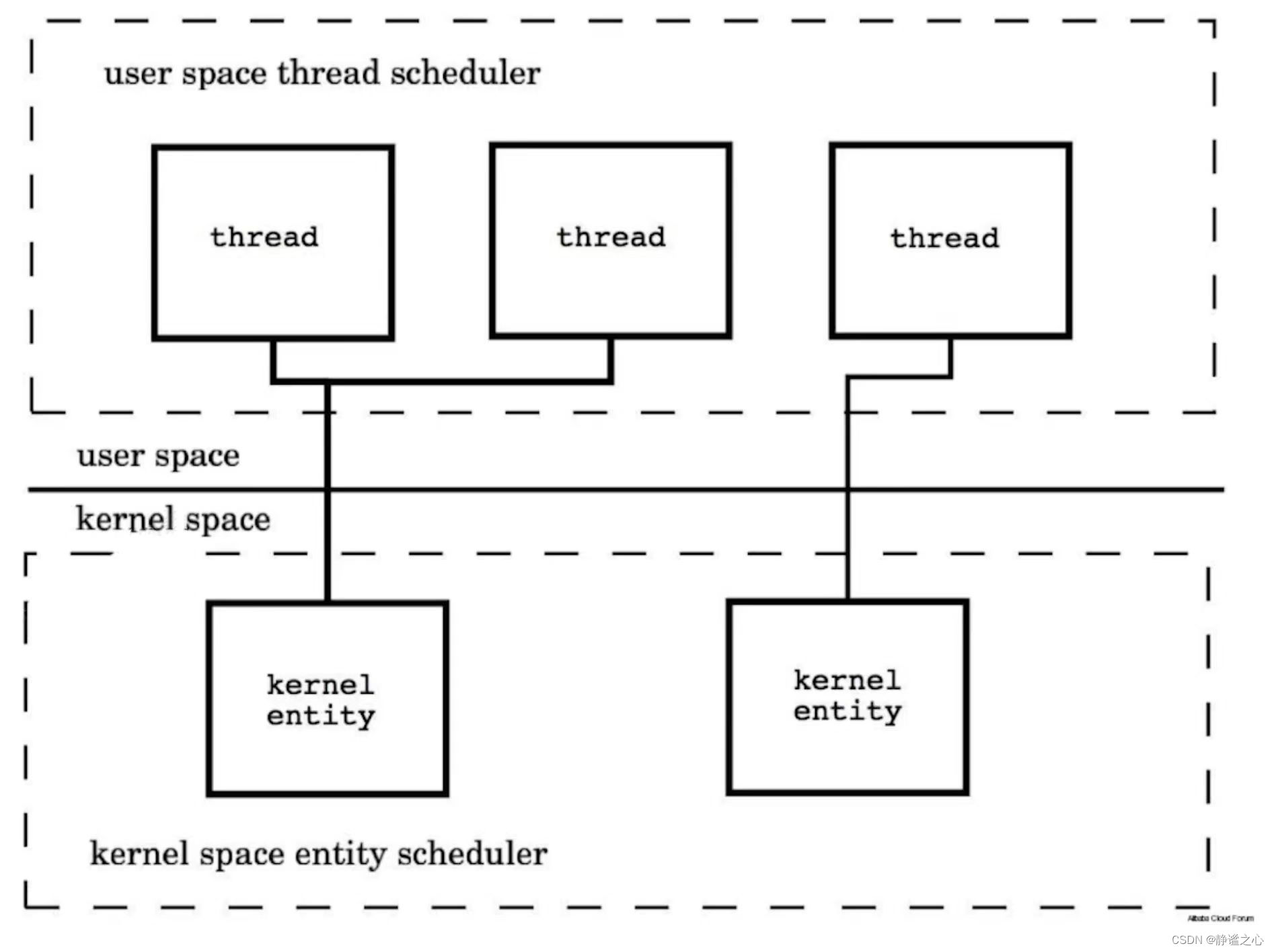
和 KSE(Kernel Schedule Entity即内核线程)的对应关系
-
Java Thread是
1:1 -
Groutine 是
M:N,多对多,如下图。
-
内核线程是由CPU直接调度,如果一个用户线程对应一个内核线程,调度效率来看肯定是快于多个用户线程对应一个内核线程的。
-
然而,实际的开发环境中一个用户线程对应一个内核线程 在 高并发场景下出现的频繁内核线程上下文切换(保留线程上下文,更新CPU内部各种寄存器)对系统性能的影响占主要部分。
-
而Go语言内部实现的线程调度器提供了多个用户线程和一个内核线程对应,这样在高并发场景能够有效降低线程间切换带来的性能消耗。
-
当然,如果如果仅仅只有几个或者十几个(小于CPU核数)用户线程的应用可能就体现不出Grountine的优势了。
Groutine 调度原理
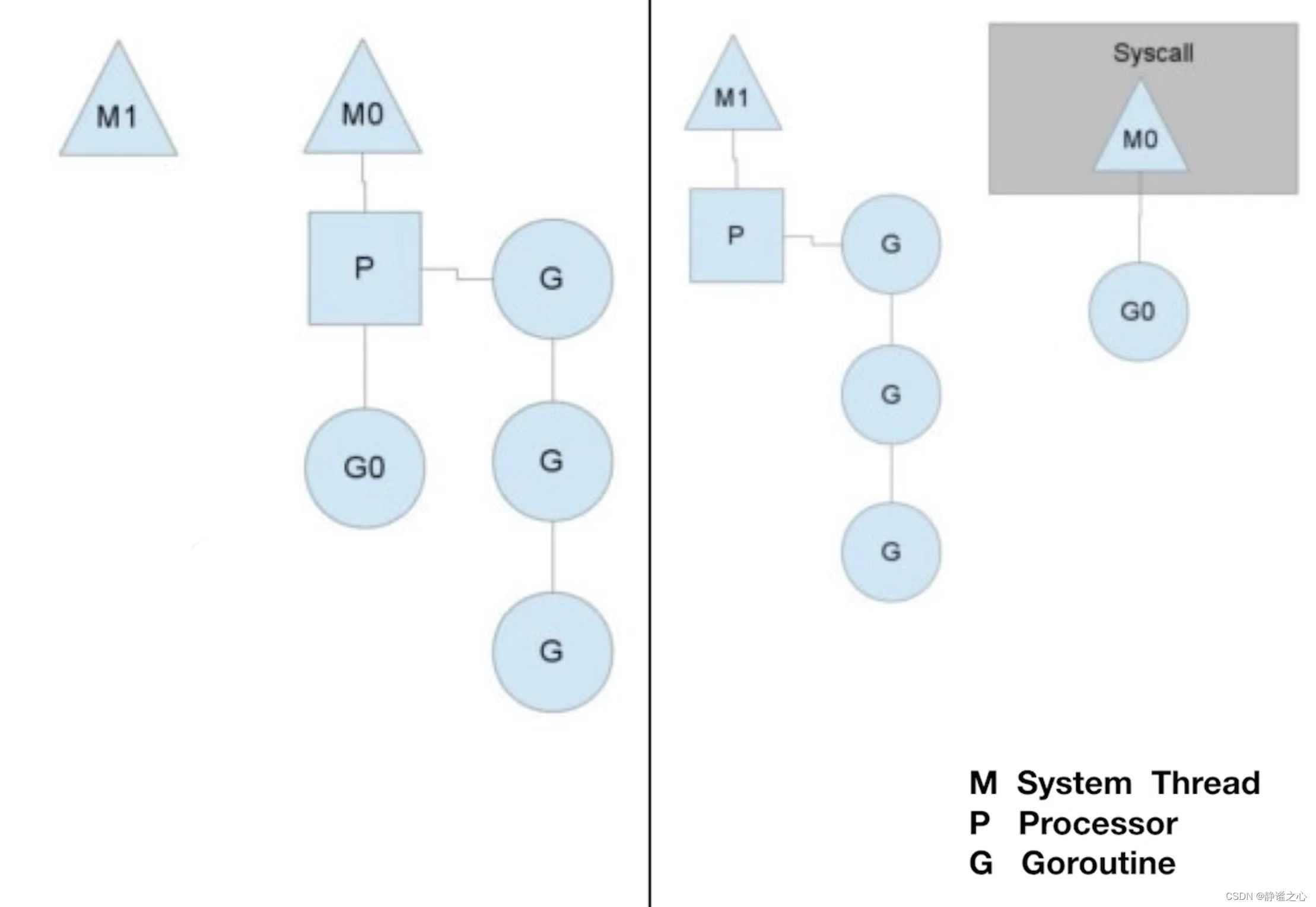
- M – System Thread 「系统线程」
- P – Processor 「Go 语言的协程处理器」
- G – Goroutine 「协程」
Processor 在不同的系统线程里,每个 Processor 都挂着一个准备运行的协程队列 G-G-G…… 有一个协程正在运行,协程队列依次运行。
Go 启动的时候,会有一个守护线程 G0,计数,会记录每个 Processor 运行完成的协程的数量,如果发现某一个 Processor 在一段时间内没有发生变化(阻塞),就会往这个协程的任务栈里面插入一个特殊的标记,当协程运行遇到非内联函数,就会读到这个标记,将自己中断下来,插到等待协程队列的队尾,切换到其他队列的队尾。
当某一个协程被系统通断了,比如 IO 需要等待的时候,Processor 会把自己加入到其他可使用的系统线程之中,继续执行其他的协程 Goroutine。当被中断的协程被唤醒,完成之后,会把自己加入到其他某一个 Processor 等待队列中,或全局等待队列当中。
当协程被中断的时候,它在寄存器中的运行状态,也会保存在协程对象中;当重新开始运行的时候,就会把运行状态写回寄存器。
举个小例子
import (
"fmt"
"testing"
"time"
)
func TestGroutine(t *testing.T) {
for i := 0; i < 10; i ++ {
// 方法一: 正确
go func(i int) {
// 启动 一个 go routine
fmt.Println(i)
}(i)
// 方法二:错误
// 如下代码是有问题的
// i 地址是被所有协程共享的,这个时候打印的结果
// 会受到其他协程的影响
// 想要保证代码的正确性,即每一个go routine打印
// 各自的i 值,需要利用如上启动go routine的代码,
// 进行值传递,从而让每个goroutine 独享各自的i的地址。
// go func() {
// fmt.Println(i)
// }()
}
time.Sleep(time.Millisecond*50)
}