


CoroutineScope - 协程作用域
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}-
顶级作用域 没有父协程的协程所在的作用域为顶级作用域。
-
协同作用域 协程中启动新的协程,新协程为所在协程的 子协程,这种情况下, 子协程所在的作用域默认为协同作用域。此时 子协程抛出的未捕获异常,都将传递给父协程处理,父协程同时也会被取消。
-
主从作用域 与协同作用域在协程的父子关系上一致,区别在于, 处于该作用域下的协程出现未捕获的异常时,不会将异常向上传递给父协程。
-
父协程被取消,则所有子协程均被取消。由于协同作用域和主从作用域中都存在父子协程关系,因此此条规则都适用。
-
父协程需要等待子协程执行完毕之后才会最终进入完成状态,不管父协程自身的协程体是否已经执行完。
-
子协程会继承父协程的协程上下文中的元素, 如果自身有相同key的成员,则覆盖对应的key,覆盖的效果仅限自身范围内有效。




使用协程作用域来创建协程
-
GlobeScope:全局范围,不会自动结束执行。
-
MainScope:主线程的作用域,全局范围
-
lifecycleScope:生命周期范围,用于activity等有生命周期的组件,在Desroyed的时候会自动结束。
-
viewModeScope:ViewModel范围,用于ViewModel中,在ViewModel被回收时会自动结束
如何使用 coroutineScope 启动协程
-
调用 xxxScope.launch{...} 启动一个协程块, launch方法启动的协程不会将结果返回给调用方。任何被视为“一劳永逸”的工作都可以使用 launch来启动。
-
在 xxxScope {...} 中调用 async{...} 创建一个子协程, async会返回一个 Deferred对象,随后可以调用 Deferred对象的 await()方法来启动该协程。
-
withContext(){...} 一个 suspend方法,在给定的上下文中执行并返回结果,它的目的不在于启动子协程,主要用于 线程切换,将长耗时操作从UI线程切走,完事再切回来。用它执行的挂起块中的上下文是当前协程的上下文和由它执行的上下文的合并结果。
-
coroutineScope{...} 一个 suspend方法,创建一个新的作用域,并在该作用域内执行指定代码块,它并不启动协程。其存在的目的是进行符合结构化并发的并行分解。
-
runBlocking{...} 创建一个协程,并阻塞当前线程,直到协程执行完毕。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
...省略
}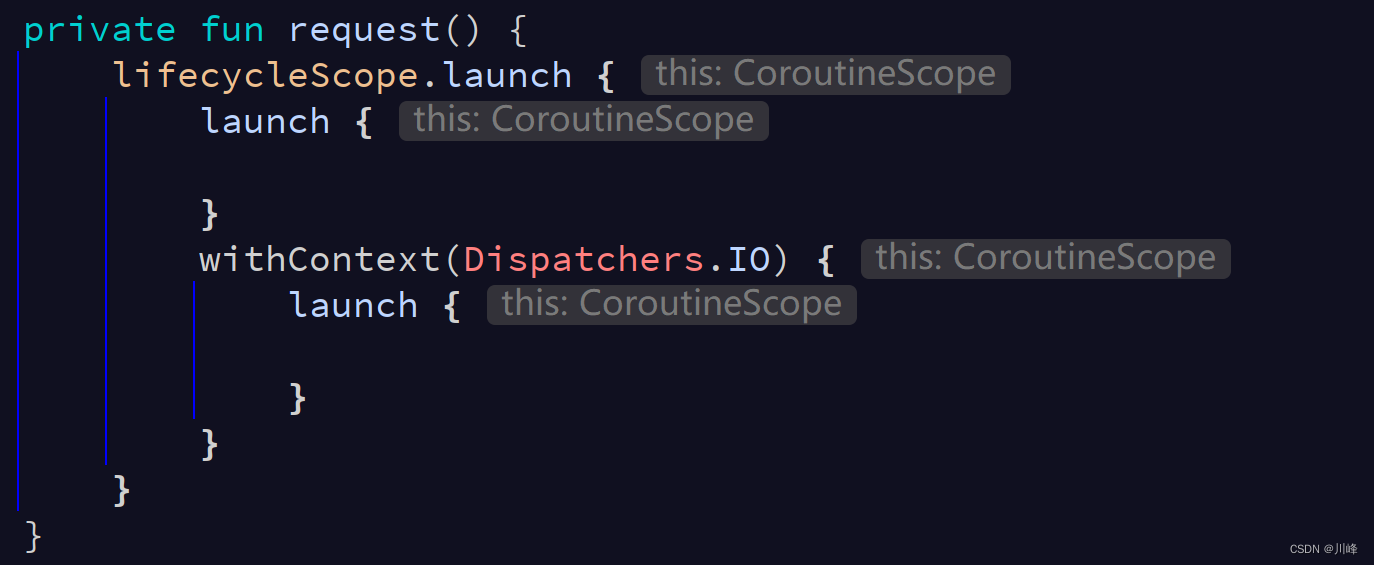
coroutineScope & supervisorScope
private fun request() {
lifecycleScope.launch {
coroutineScope { // 协同作用域,抛出未捕获异常时会取消父协程
launch { }
}
supervisorScope { // 主从作用域,抛出未捕获异常时不会取消父协程
launch { }
}
}
}注意这两个函数的作用只是定义了2个作用域而已,如果想要启动新的子协程请在里面调用launch。如果需要异步请使用async。
-
supervisorScope 表示 主从作用域,会继承父协程的上下文,它的特点就是子协程的异常不会影响父协程,内部的 子协程挂掉 不会影响外部的父协程和兄弟协程的继续运行,它就像一道防火墙,隔离了异常,保证程序健壮,但是如果外部协程挂掉还是可以取消子协程的,即 单向传播。它的设计应用场景多用于 子协程为独立对等的任务实体的时候,比如一个下载器,每一个子协程都是一个下载任务,当一个下载任务异常时,它不应该影响其他的下载任务。
-
coroutineScope 表示 协同作用域, 内部的协程 出现异常 会向外部传播,子协程未捕获的异常会向上传递给父协程, 子协程 可以挂掉外部协程 , 外部协程挂掉也会挂掉子协程,即 双向传播 。 任何一个子协程异常退出,会导致整体的退出。

还可以进行一些简单的封装,比如我们可以定义一个 suspend 方法,内部返回一个 coroutineScope 作用域对象来执行一个传入的协程代码块:
private suspend fun saveLocal(coroutineBlock: (suspend CoroutineScope.() -> String)? = null): String? {
return coroutineScope {
// 以下几种写法等价,都是执行block代码块
// coroutineBlock!!.invoke(this)
// coroutineBlock?.invoke(this)
// if (coroutineBlock != null) {
// coroutineBlock.invoke(this)
// }
coroutineBlock?.let { block ->
block()
}
}
}MainScope().launch {
println("执行在一个协程中...")
val result = saveLocal {
async(Dispatchers.IO) {
"123456"
}.await()
}
println("一个协程执行完毕... result:$result")
}并行分解

例如,假设我们定义一个用于异步获取两个文档的 coroutineScope。通过对每个延迟引用调用 await(),我们可以保证这两项 async 操作在返回值之前完成:
suspend fun fetchTwoDocs() = coroutineScope {
val deferredOne = async { fetchDoc(1) }
val deferredTwo = async { fetchDoc(2) }
deferredOne.await()
deferredTwo.await()
}
假如像上面这样直接使用coroutineScope,那么async执行完成,coroutineScope中排在async之后的代码有可能被调度到某个子线程中执行,即上面的红色部分执行完后,蓝色部分可能运行在某个子线程中。如下图:

所以在Android中,最好是在lifecycleScope或viewModelScope中去使用async, 这样能保证async之后的代码仍然执行在主线程上。但是此时在lifecycleScope或viewModelScope中调用的async中的代码也会执行在主线程(虽然是异步的,但既然是主线程就会有IO太长阻塞主线程的风险),也就是说async默认跟父协程的调度器是一样的,因此,如果有需要,此时可以为async指定线程调度器。如下:

除了单独调用每个await方法,还可以对集合使用 awaitAll(),如以下示例所示:
suspend fun fetchTwoDocs() = // called on any Dispatcher (any thread, possibly Main)
coroutineScope {
val deferreds = listOf( // fetch two docs at the same time
async { fetchDoc(1) }, // async returns a result for the first doc
async { fetchDoc(2) } // async returns a result for the second doc
)
deferreds.awaitAll() // use awaitAll to wait for both network requests
}虽然 fetchTwoDocs() 使用 async 启动新协程,但该函数使用 awaitAll() 等待启动的协程完成后才会返回结果。 此外,coroutineScope 会捕获协程抛出的所有异常,并将其传送回调用方。
写法上需要注意的点:
suspend fun main() = runBlocking {
val times = measureTimeMillis {
// 这样写是串行执行,总耗时2s
val one = doOne()
val two = doTwo()
println("The result is ${one + two}")
}
println("cost time: ${times}ms")
}
suspend fun main() = runBlocking {
val times = measureTimeMillis {
// 这样写是并行执行,总耗时1s
val one = async { doOne() }
val two = async { doTwo() }
println("The result is ${one.await() + two.await()}")
}
println("cost time: ${times}ms")
}
suspend fun main() = runBlocking {
val times = measureTimeMillis {
// 但是这样写不是并行执行,总耗时2s
val one = async { doOne() }.await()
val two = async { doTwo() }.await()
println("The result is ${one + two}")
}
println("cost time: ${times}ms")
}
private suspend fun doOne(): Int {
delay(1000L)
return 13
}
private suspend fun doTwo(): Int {
delay(1000L)
return 14
}MainScope & GlobalScope
public object GlobalScope : CoroutineScope {
override val coroutineContext: CoroutineContext
get() = EmptyCoroutineContext
}public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)var mainScope= MainScope()
mainScope.launch {
println("执行在一个协程中...")
val result = saveLocal {
async(Dispatchers.IO) {
"123456"
}.await()
}
println("一个协程执行完毕... result:$result")
}
...
override fun onDestroy() {
super.onDestroy()
mainScope.cancel()
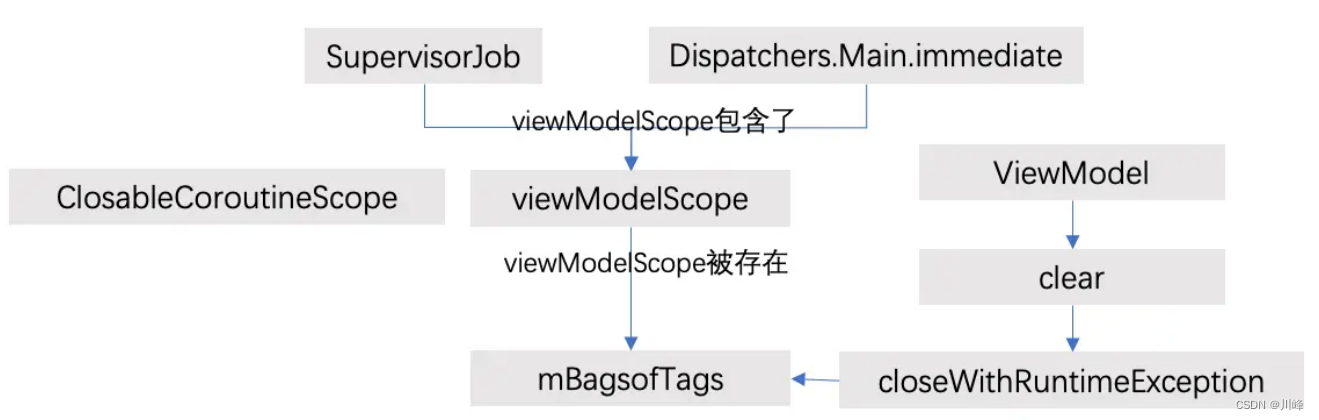
}ViewModelScope
private const val JOB_KEY = "androidx.lifecycle.ViewModelCoroutineScope.JOB_KEY"
val ViewModel.viewModelScope: CoroutineScope
get() {
val scope: CoroutineScope? = this.getTag(JOB_KEY)
if (scope != null) {
return scope
}
return setTagIfAbsent(JOB_KEY, CloseableCoroutineScope(SupervisorJob() + Dispatchers.Main.immediate))
}
internal class CloseableCoroutineScope(context: CoroutineContext) : Closeable, CoroutineScope {
override val coroutineContext: CoroutineContext = context
override fun close() {
coroutineContext.cancel()
}
}
lifecycleScope
public val LifecycleOwner.lifecycleScope: LifecycleCoroutineScope
get() = lifecycle.coroutineScope
public val Lifecycle.coroutineScope: LifecycleCoroutineScope
get() {
while (true) {
val existing = mInternalScopeRef.get() as LifecycleCoroutineScopeImpl?
if (existing != null) {
return existing
}
val newScope = LifecycleCoroutineScopeImpl(
this,
SupervisorJob() + Dispatchers.Main.immediate
)
if (mInternalScopeRef.compareAndSet(null, newScope)) {
newScope.register()
return newScope
}
}
}public fun launchWhenCreated(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenCreated(block)
}
public fun launchWhenStarted(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenStarted(block)
}
public fun launchWhenResumed(block: suspend CoroutineScope.() -> Unit): Job = launch {
lifecycle.whenResumed(block)
}自定义CoroutineScope
class ExampleClass {
// Job and Dispatcher are combined into a CoroutineContext which will be discussed shortly
val scope = CoroutineScope(Job() + Dispatchers.Main)
fun exampleMethod() {
// Starts a new coroutine within the scope
scope.launch {
fetchDocs() // New coroutine that can call suspend functions
}
}
fun cleanUp() {
// Cancel the scope to cancel ongoing coroutines work
scope.cancel()
}
}class CancelJobDialog() : DialogFragment(), CoroutineScope by MainScope() {
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?): View? {
dialog?.requestWindowFeature(Window.FEATURE_NO_TITLE)
dialog?.window?.setBackgroundDrawable(ColorDrawable(Color.TRANSPARENT))
return inflater.inflate(R.layout.dialog_cancel_job, container, false)
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
val mNoTv = view.findViewById<TextView>(R.id.btn_n)
val mYesTv = view.findViewById<TextView>(R.id.btn_p)
mNoTv.click { dismiss() }
mYesTv.click { doSth() }
}
private fun doSth() {
launch{
println("执行在另一个协程中...")
delay(1000L)
println("另一个协程执行完毕...")
}
dismiss()
}
override fun onDismiss(dialog: DialogInterface) {
cancel()
super.onDismiss(dialog)
}
}/**
* 自定义带协程作用域的弹窗
*/
abstract class CoroutineScopeCenterPopup(activity: FragmentActivity) : CenterPopupView(activity), CoroutineScope {
private lateinit var job: Job
private val exceptionHandler = CoroutineExceptionHandler { coroutineContext, throwable ->
println(throwable.message ?: "Unkown Error")
}
// 此协程作用域的自定义 CoroutineContext
override val coroutineContext: CoroutineContext
get() = Dispatchers.Main + job + CoroutineName("CenterPopupScope") + exceptionHandler
override fun onCreate() {
job = Job()
super.onCreate()
}
override fun onDismiss() {
job.cancel() // 关闭弹窗后,结束所有协程任务
println("关闭弹窗后,结束所有协程任务")
super.onDismiss()
}
}class InterviewAcceptPopup(private val mActivity: FragmentActivity) : CoroutineScopeCenterPopup(mActivity) {
override fun getImplLayoutId(): Int {
return R.layout.dialog_interview_accept
}
override fun onCreate() {
super.onCreate()
val btnYes = findViewById<TextView>(R.id.btn_y)
btnYes.click {
doSth()
}
}
private fun doSth() {
launch {
println("执行在协程中...")
delay(1000L)
println("执行完毕...")
dismiss()
}
}
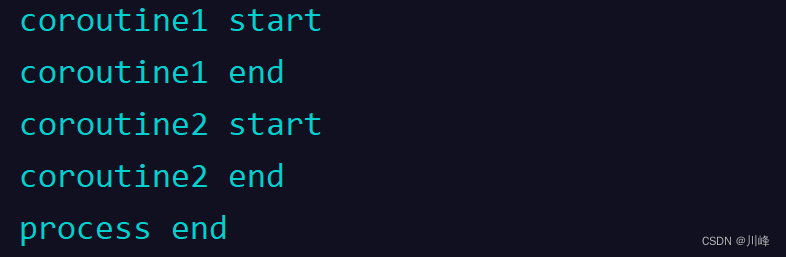
}runBlocking
fun main() {
runBlocking {
println("coroutine1 start")
delay(1000) //模拟耗时
println("coroutine1 end")
}
runBlocking {
println("coroutine2 start")
delay(2000) //模拟耗时
println("coroutine2 end")
}
println("process end")
}
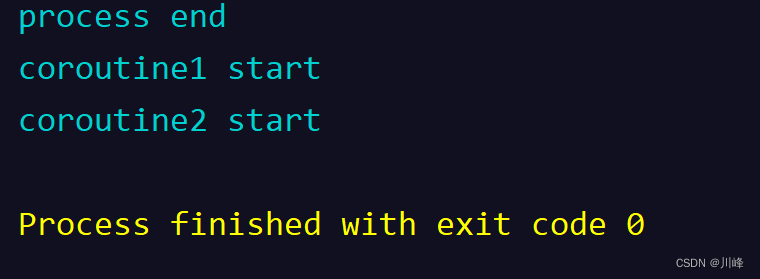
suspend fun main() {
GlobalScope.launch {
println("coroutine1 start")
delay(1000) //模拟耗时
println("coroutine1 end")
}
GlobalScope.launch {
println("coroutine2 start")
delay(2000) //模拟耗时
println("coroutine2 end")
}
println("process end")
}在suspend的main函数中执行结果如下:
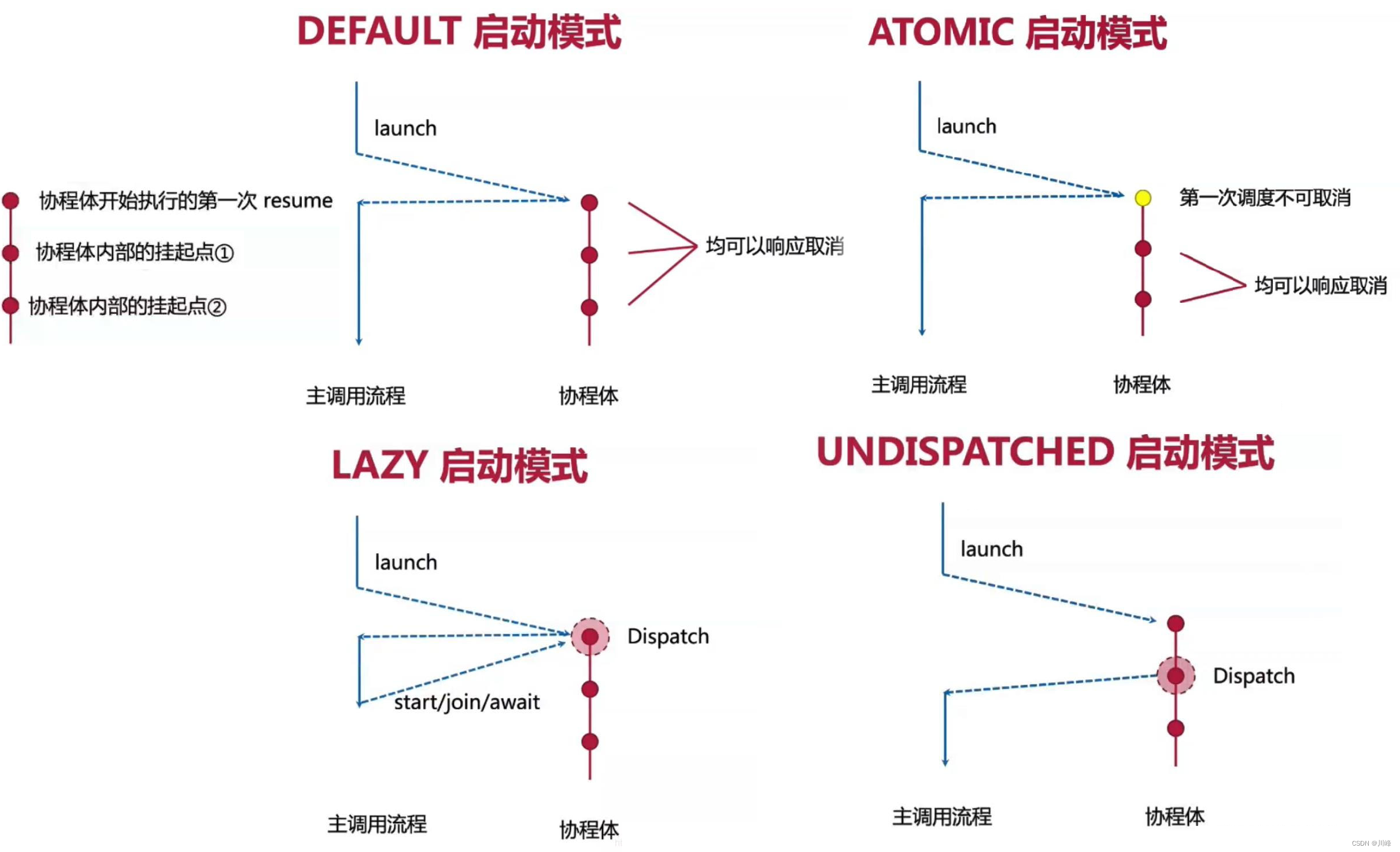
CoroutineStart - 协程启动模式

-
CoroutineStart.DEFAULT: 协程创建后,立即开始调度,但 有可能在执行前被取消。在调度前如果协程被取消,其将直接进入取消响应的状态。
-
CoroutineStart.ATOMIC : 协程创建后,立即开始调度, 协程执行到第一个挂起点之前不响应取消。其将调度和执行两个步骤合二为一,就像它的名字一样,其保证调度和执行是原子操作,因此协程也 一定会执行。
-
CoroutineStart.LAZY : 只要协程被需要时(主动调用该协程的 start、 join、 await等函数时 ), 才会开始调度,如果调度前就被取消,协程将直接进入异常结束状态。
-
CoroutineStart.UNDISPATCHED : 协程创建后,立即在当前线程中执行,直到遇到第一个真正挂起的点。是立即执行,因此协程 一定会执行。
协程调度器
-
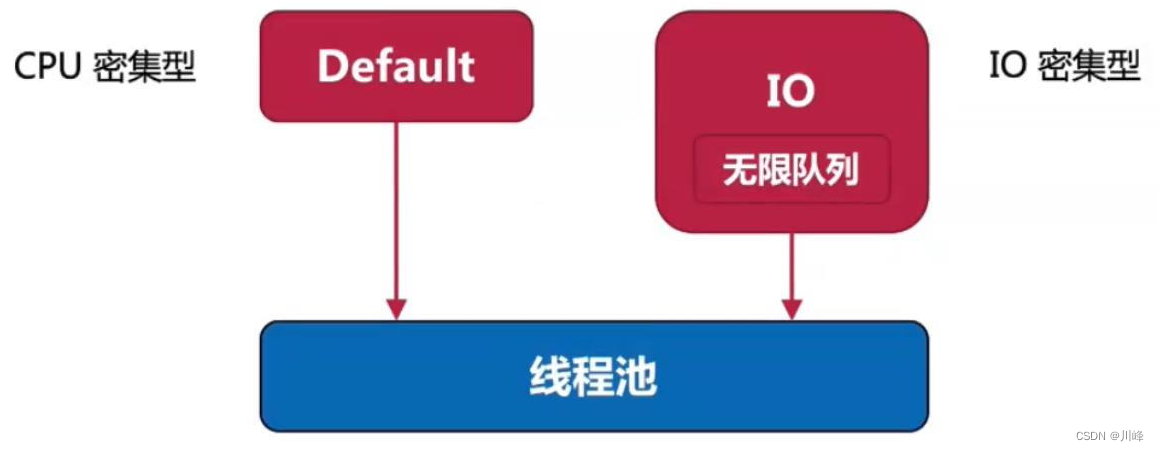
Default: 默认调度器 ,适合处理后台计算,其是一个 CPU 密集型任务调度器
-
IO: IO 调度器,适合执行 IO 相关操作,其是 IO 密集型任务调度器
-
Main: UI 调度器,根据平台不同会被初始化为对应的 UI 线程的调度器, 例如在Android 平台上它会将协程调度到 UI 事件循环中执行,即通常在 主线程上执行。
-
Unconfined:“无所谓“调度器,不要求协程执行在特定线程上。协程的调度器如果是 Unconfined, 那么它在挂起点恢复执行时会在恢复所在的线程上直接执行,当然, 如果嵌套创建以它为调度器的协程,那么这些协程会在启动时被调度到协程框架内部的事件循环上,以避免出现 StackOverflow。

自定义调度器

不过自己定义调度器的情况不多见,更常见的是将我们自己定义好的线程池转成调度器 ,如代码清单 6-4 所示。

使用扩展函数 asCoroutineDispatcher 就可以将 Executor 转为调度器,不过这个调度器需要在使用完毕后主动关闭,以免造成线程泄露。本例中,我们使用 use 在协程执行完成后主动关闭这个调度器。
private var mHandlerThread: HandlerThread? = HandlerThread("handle_thread")
private var mHandler: Handler? = mHandlerThread?.run {
start()
Handler(this.looper)
}
...
GlobalScope.launch(mHandler.asCoroutineDispatcher("handle_thread")) {
println("执行在协程中...")
delay(1000L)
println("执行完毕...")
}withContext

class LoginRepository(...) {
...
suspend fun makeLoginRequest(
jsonBody: String
): Result<LoginResponse> {
// Move the execution of the coroutine to the I/O dispatcher
return withContext(Dispatchers.IO) {
// 网络请求阻塞代码
}
}
}class LoginViewModel(
private val loginRepository: LoginRepository
): ViewModel() {
fun login(username: String, token: String) {
// Create a new coroutine on the UI thread
viewModelScope.launch {
val jsonBody = "{ username: \"$username\", token: \"$token\"}"
// 调用挂起函数请求网络接口
val result = loginRepository.makeLoginRequest(jsonBody)
// 显示请求结果
when (result) {
is Result.Success<LoginResponse> -> // Happy path
else -> // Show error in UI
}
}
}
}withContext() 的效用
捕获协程中的异常
class LoginViewModel(
private val loginRepository: LoginRepository
) : ViewModel() {
fun login(username: String, token: String) {
viewModelScope.launch {
try {
loginRepository.login(username, token)
// Notify view user logged in successfully
} catch (exception: IOException) {
// Notify view login attempt failed
}
}
}
}通过launch方式启动的协程,异常应当在协程体内进行捕获,而通过async方式启动的协程,需要对await调用处进行捕获异常:
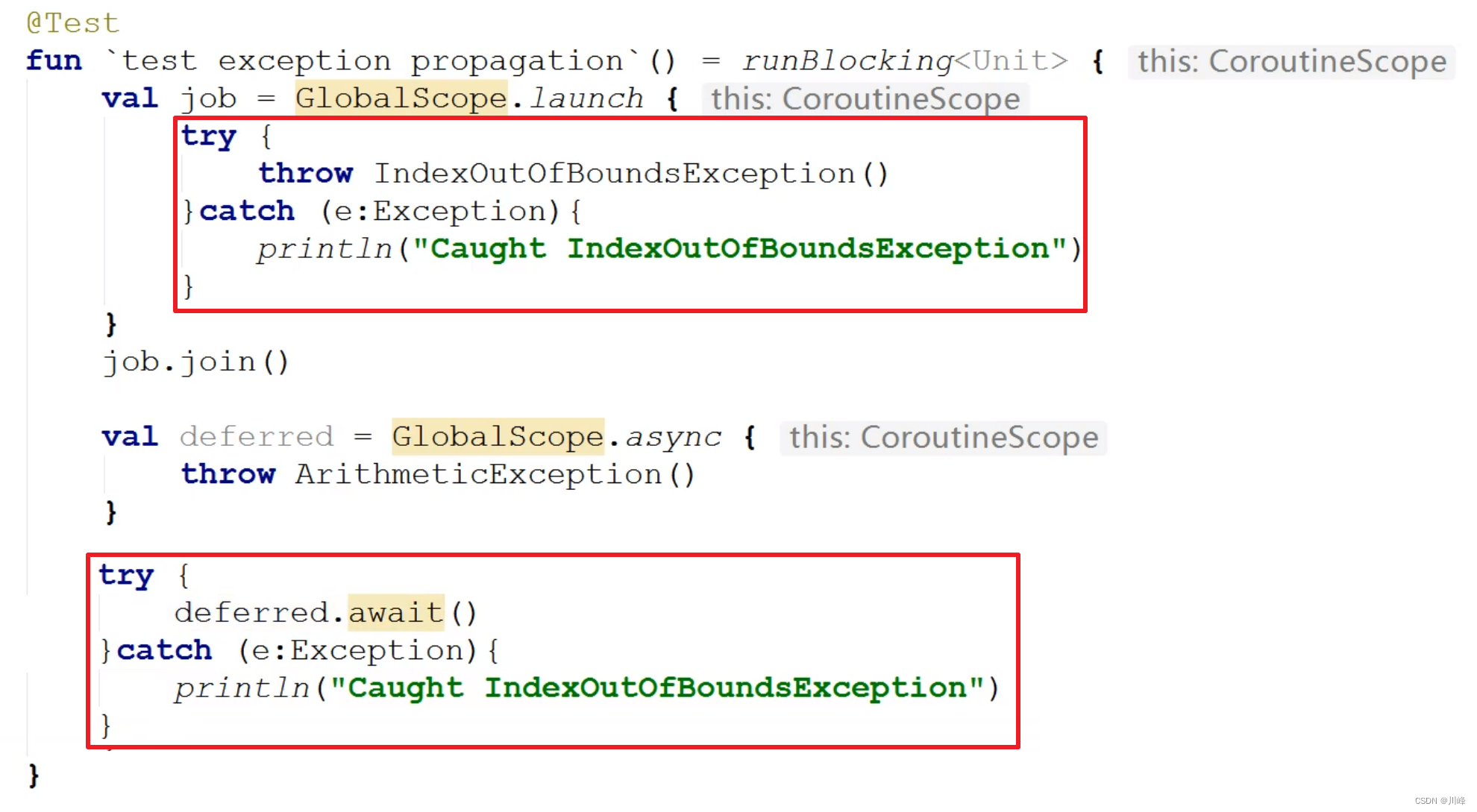

对于async创建的非根协程,仍然会将异常向上抛出,如下代码会导致应用Crash:
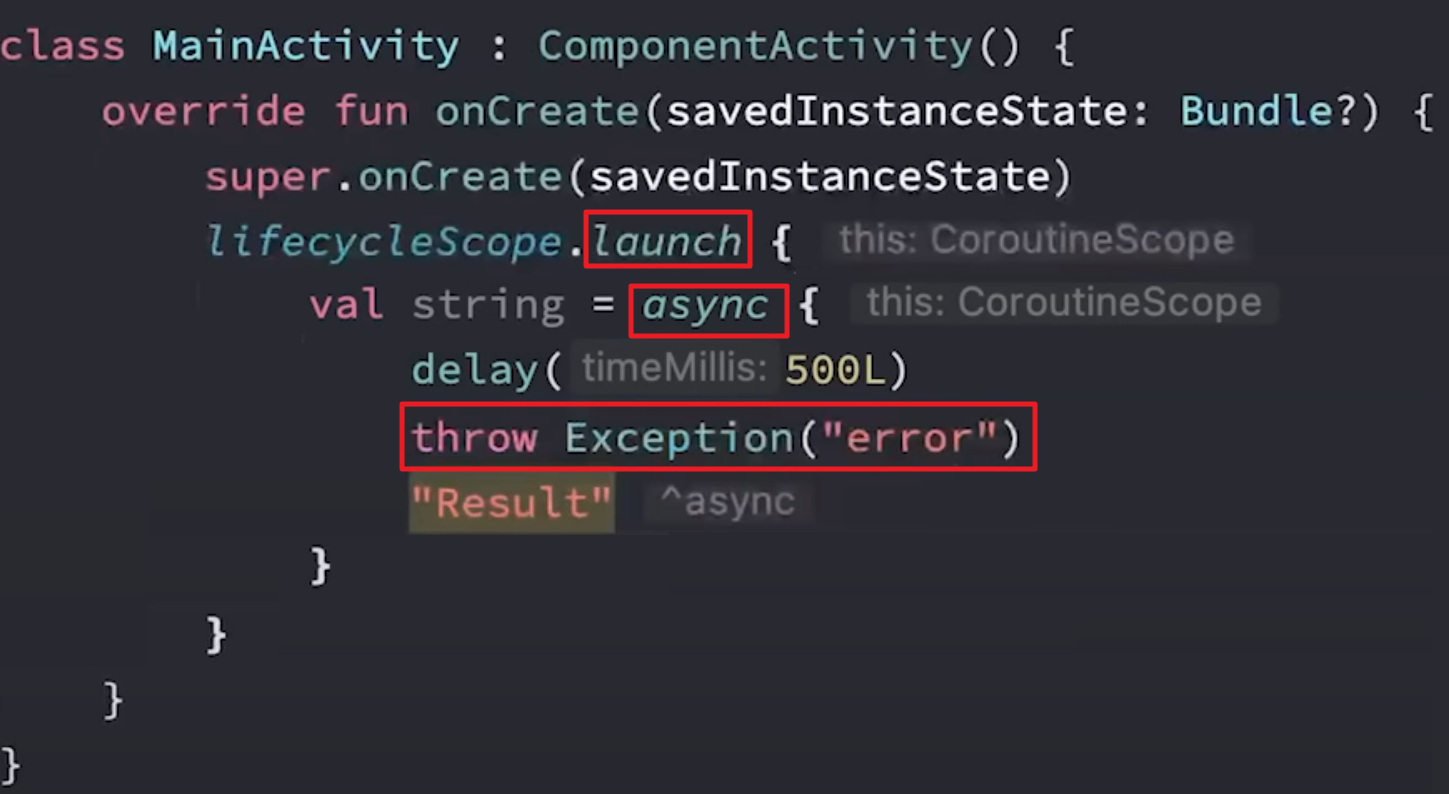
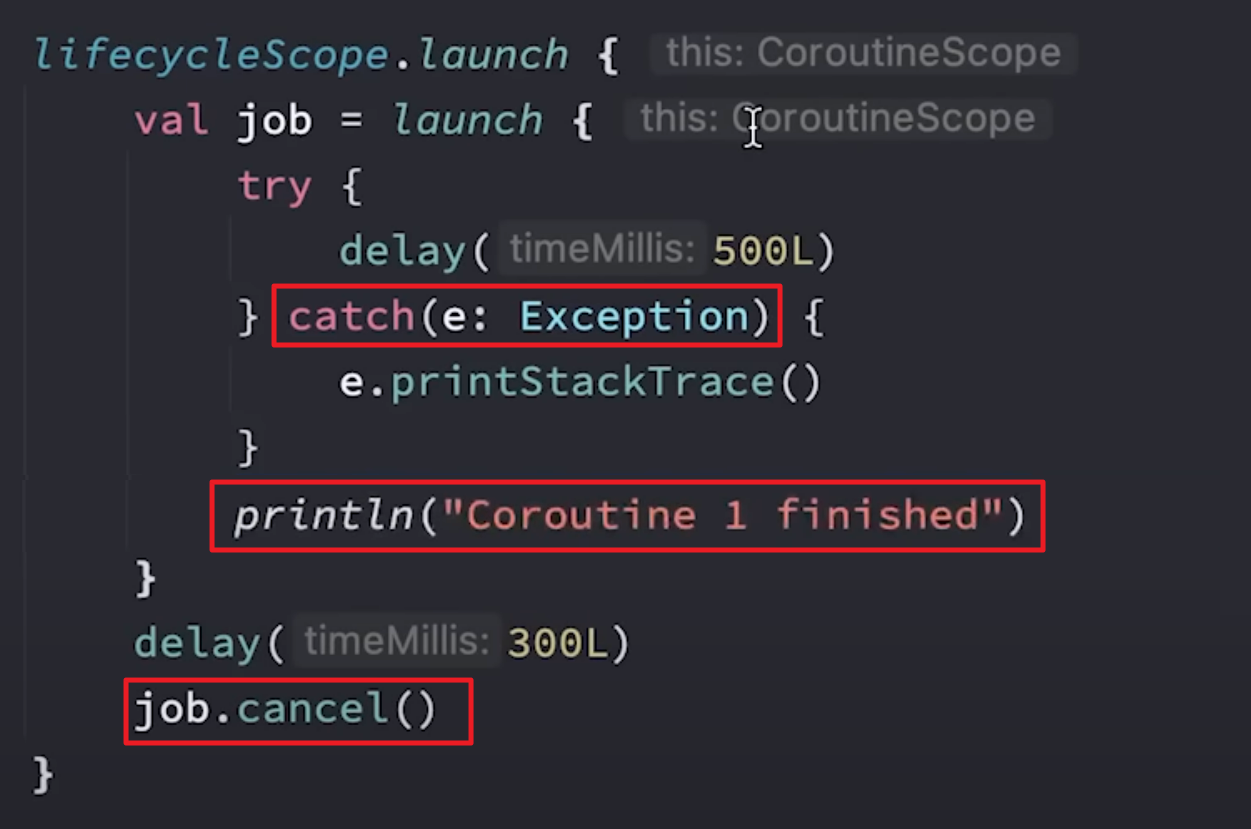
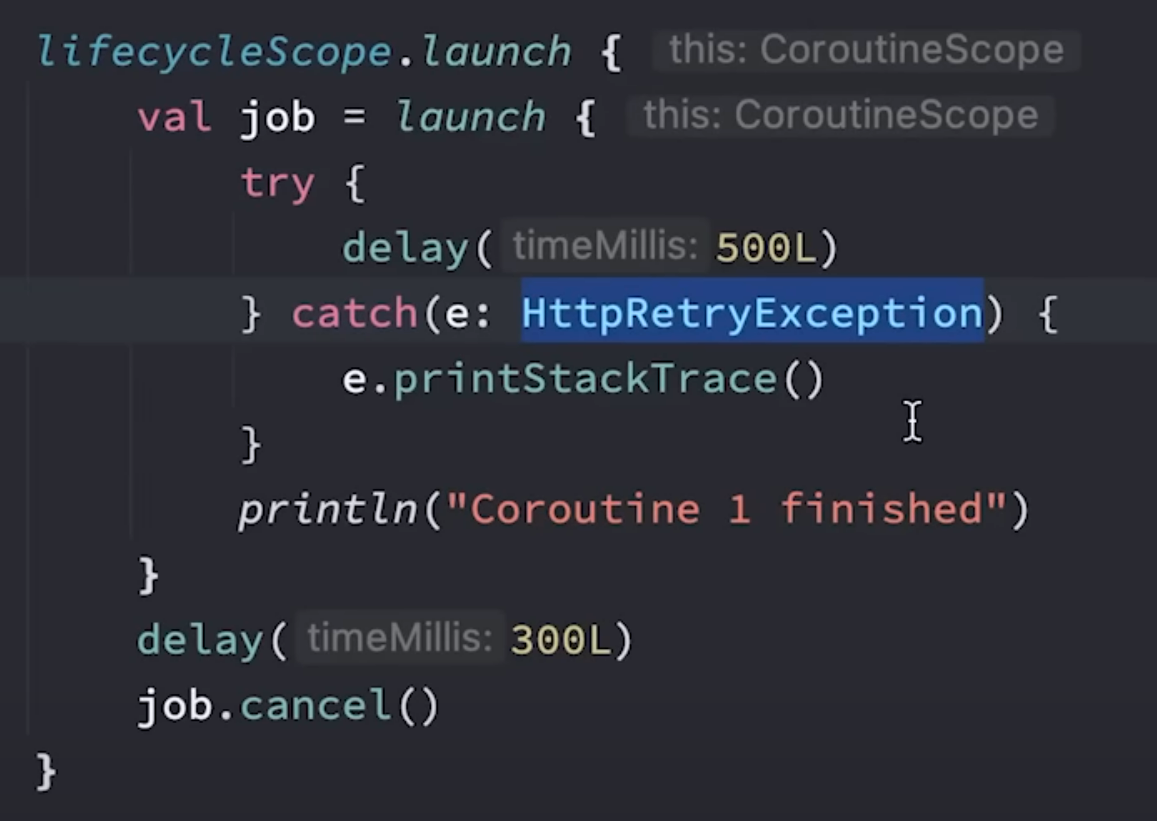
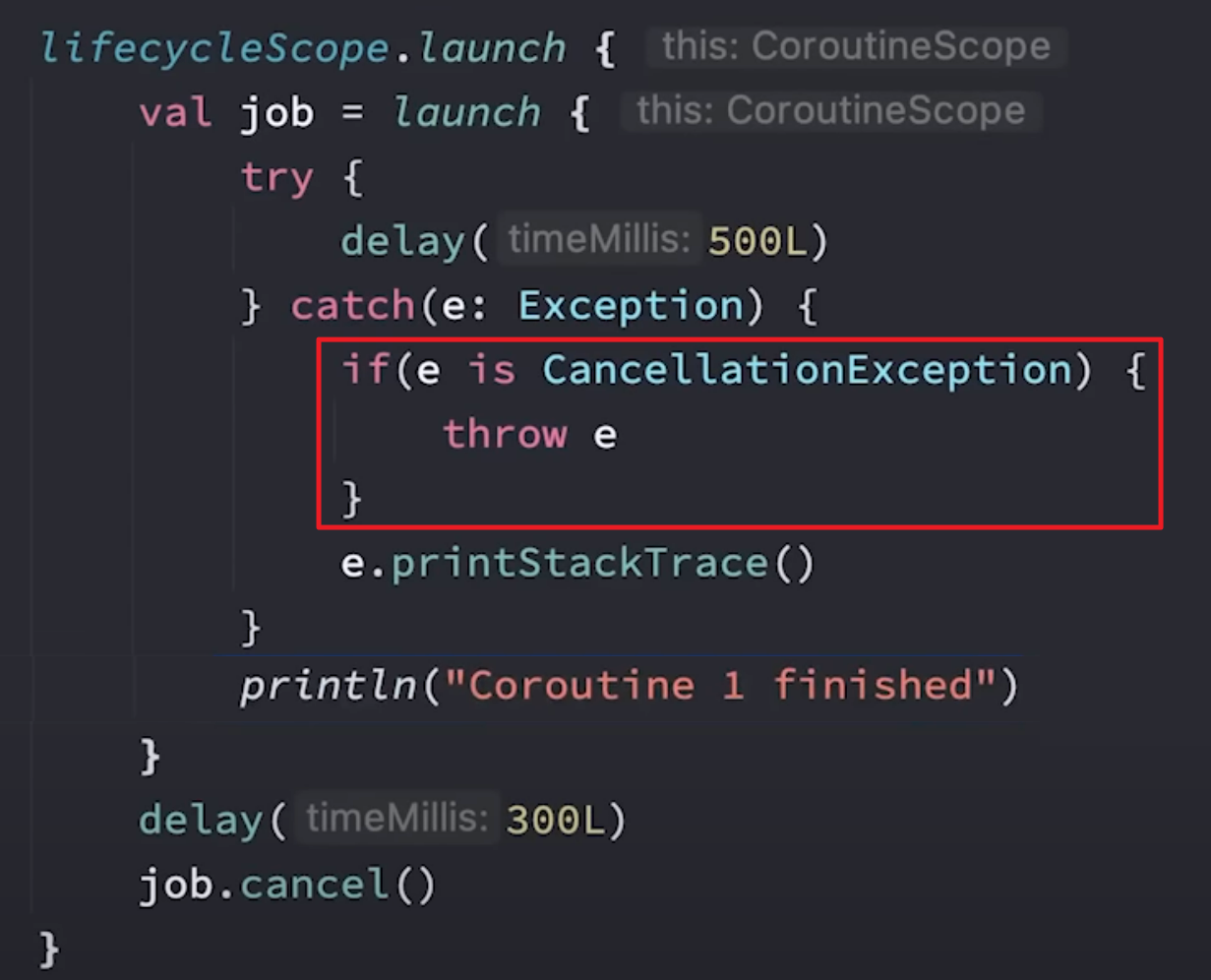
使用CoroutineExceptionHandler对协程的异常进行捕获
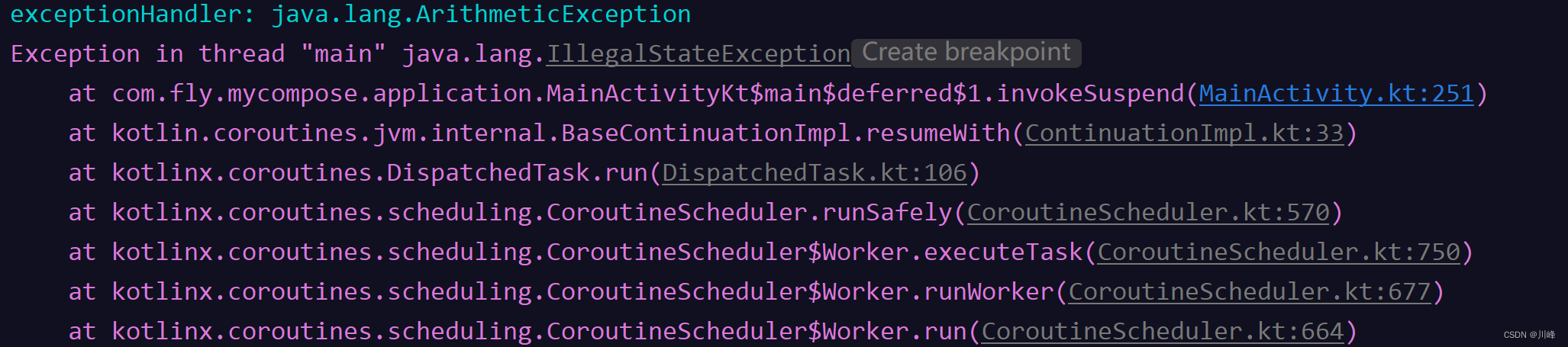
suspend fun main() {
val exceptionHandler = CoroutineExceptionHandler { context, throwable ->
println("exceptionHandler: $throwable")
}
val job = GlobalScope.launch(exceptionHandler) {
throw ArithmeticException()
}
val deferred = GlobalScope.async(exceptionHandler) {
throw IllegalStateException()
}
job.join()
deferred.await()
}
需要注意的是异常处理Handler需要挂在最外部的根协程上,如果挂在子协程上,可能无法捕获异常:

val exceptionHandler = CoroutineExceptionHandler { context, throwable ->
println("exceptionHandler: $throwable")
}
findViewById<Button>(R.id.button).also {
it.setOnClickListener {
lifecycleScope.launch(exceptionHandler) {
"abc".substring(10) // will crash the Main Thread!
}
}
}异常聚合
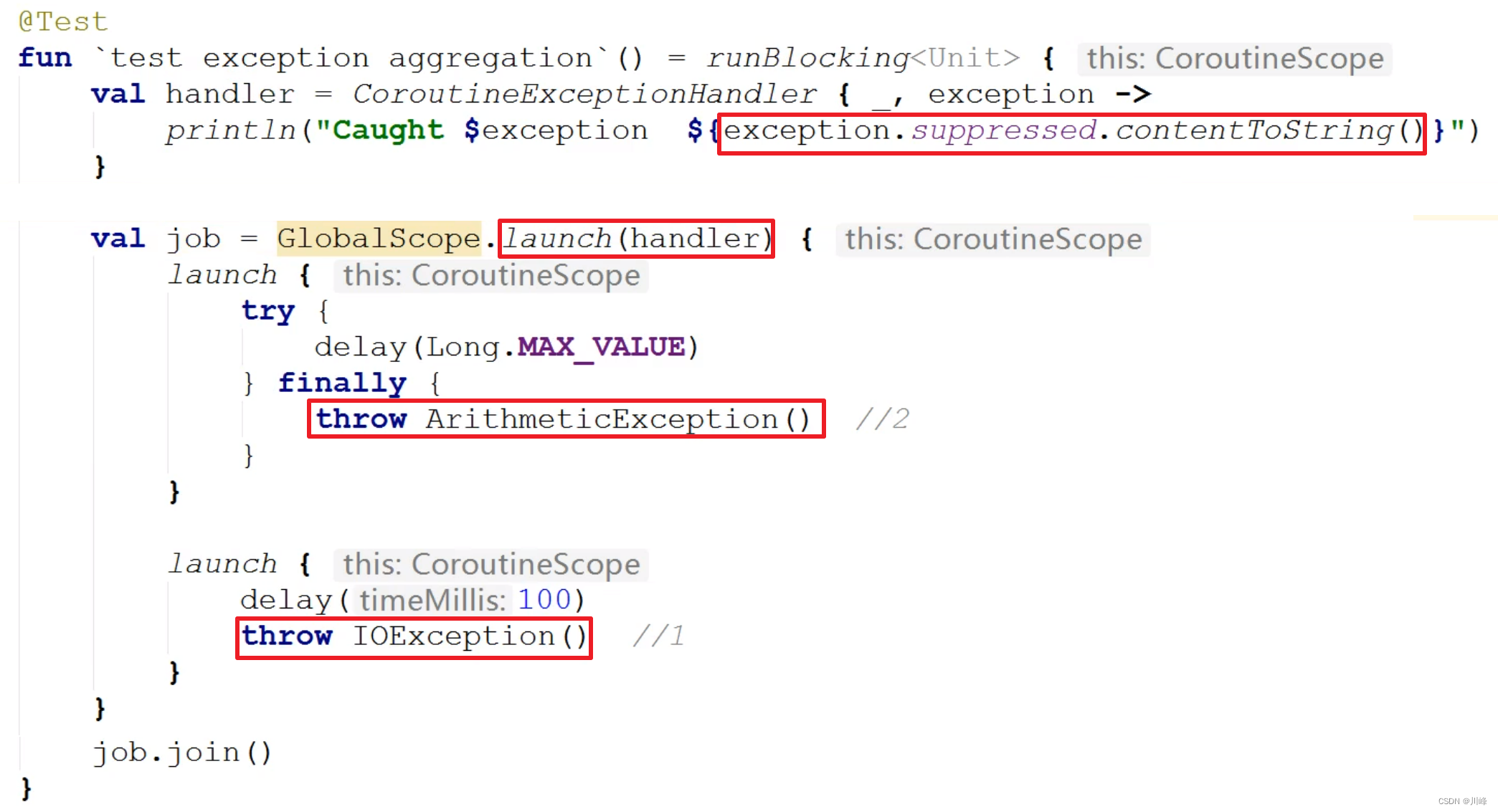
exception.supressed是一个数组,里面保存了所有被抑制的异常,如果想获知所有的异常类型可以通过此方法获取。
协程的全局异常处理器

com.my.kotlin.coroutine.exceptionhandler.GlobalCoroutineExceptionHandler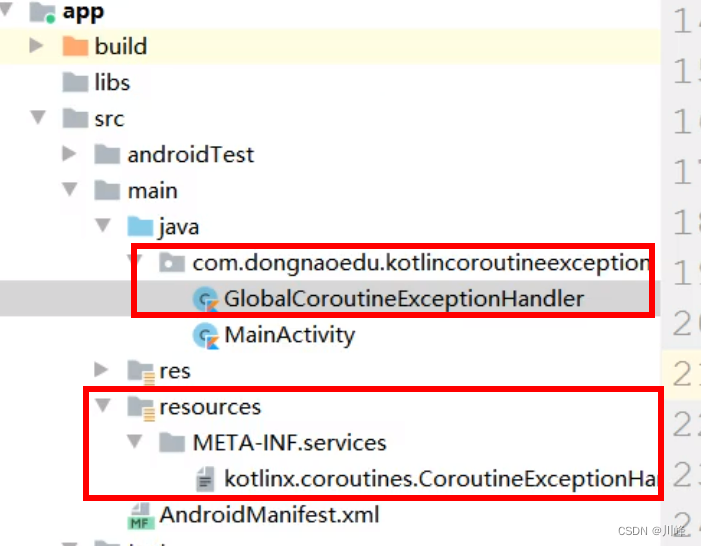

如果大家在 Android 设备上尝试运行该程序,部分机型可能只能看到全局异常处理器输出的异常信息。换言之,如果我们不配置全局异常处理器,在 Default 或者 IO 调度器上遇到未捕获的异常时极有可能发生程序闪退却没有任何异常信息的情况,此时全局异常处理器的配置就显得格外有用了。(提示:全局异常处理器不适用于 JavaScript 和 Native 平台)
注意:发生异常时,全局Handler会打印异常信息,但是并不会阻止App崩溃的发生。
协程的取消检查

这是标准库提供的扩展函数,可以实现流复制。

如果 job 为空 ,那么说明所在的协程是个简单协程,这种情况不存在取消逻辑;job 不为空时,如果 isActive 也不为 true, 则说明当前协程被取消了,抛出它对应的取消异常即可。

yield 函数的作用主要是检查所在协程状态, 如果已经取消,则抛出取消异常予以响应。此外,它还会尝试出让线程的执行权,给其他协程提供执行机会。
协程的超时取消

这看上去没什么问题,只是不够简洁,甚至还有些令人迷惑。幸运的是,官方框架提供了一个可以设定超时的 API withTimeout ,我们可以用这个 API 来优化上面的代码,如代码清单 6-12 所示。

withTimeout 这个 AP 可以设定一个超时,如果它的第二个参数 block 运行超时,那么就会被取消,取消后 withTimeout 直接抛出取消异常。如果不希望在超时的情况下抛出取消异常,也可以使用 withTimeoutOrNull, 它的效果是在超时的情况下返回 null。
隔离协程之间的异常传播
首先要明确一点:协程出现异常后都会根据所在作用域来尝试将异常向上传递。
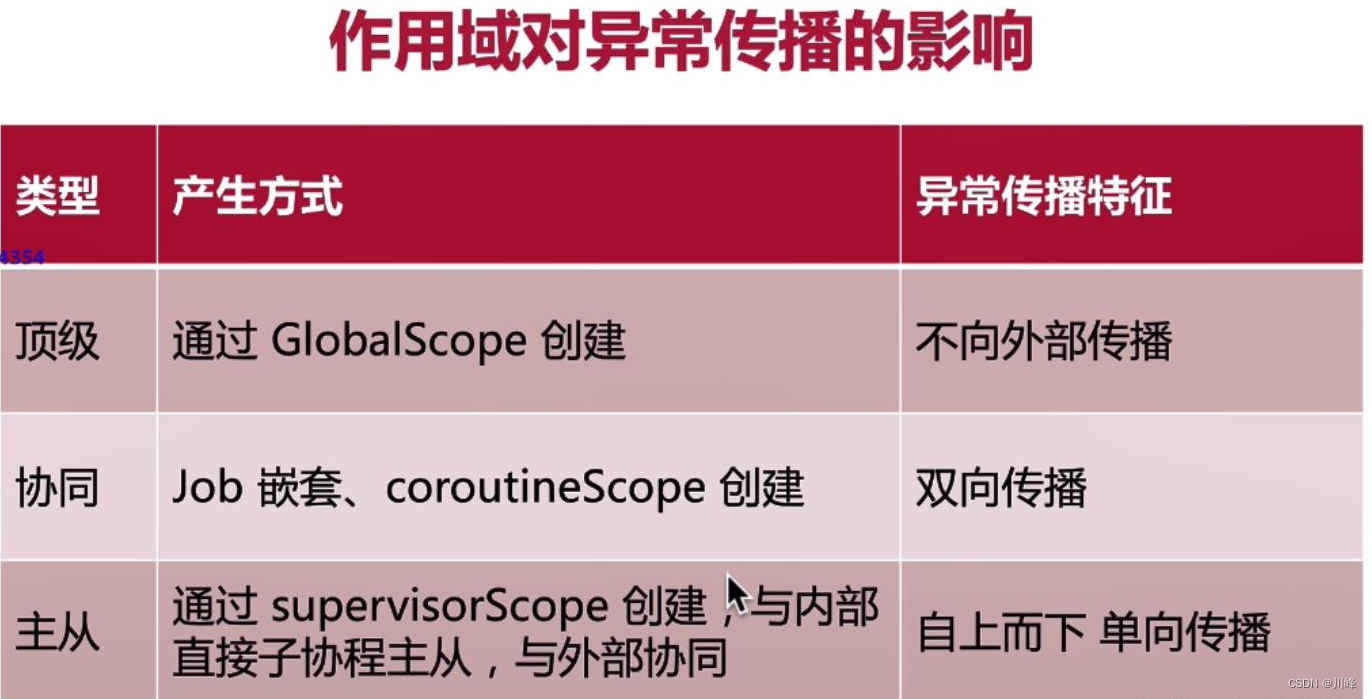
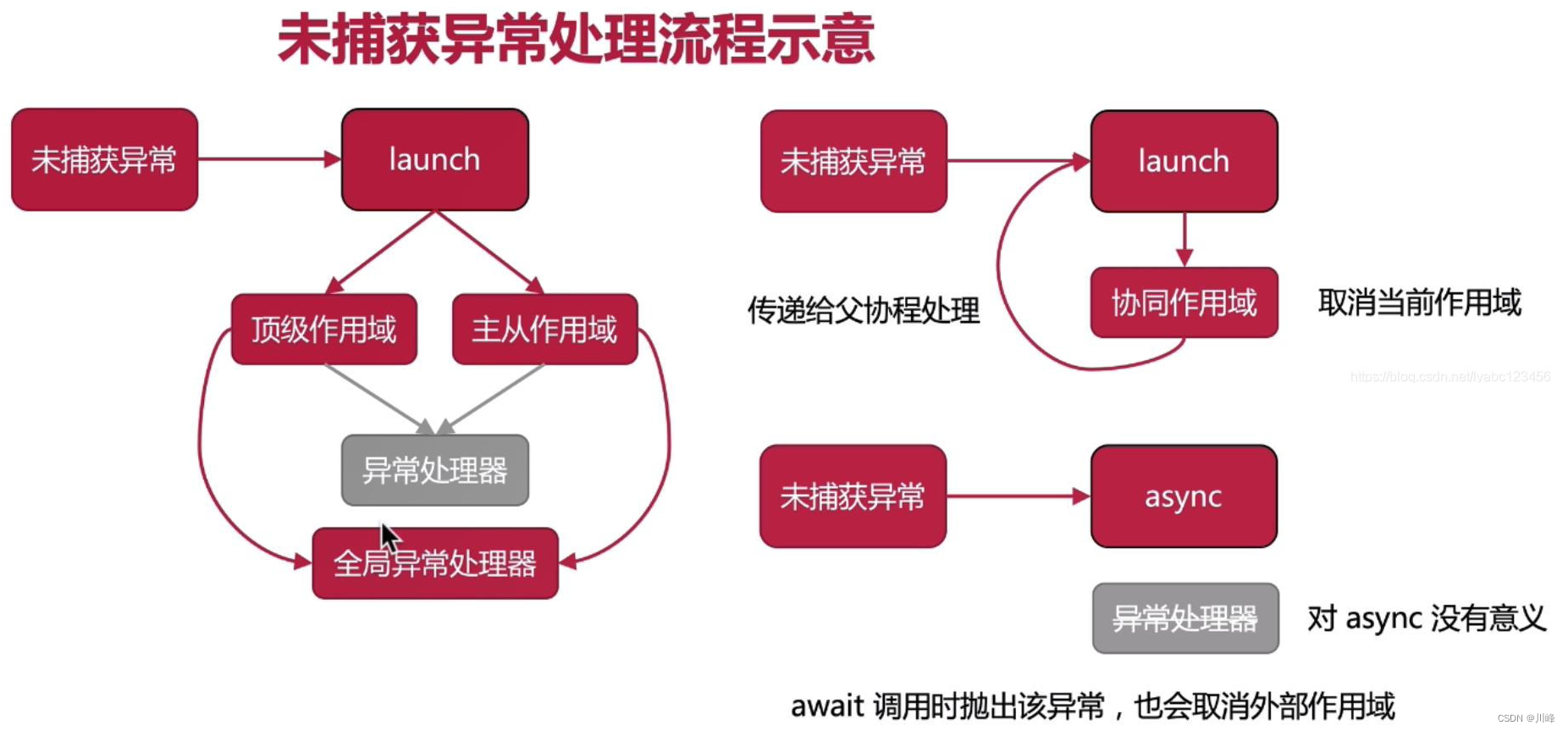
根据前面协程作用域异常传播的结论,子协程产生的未捕获异常会传播给它的父协程,然后父协程会按照如下顺序进行处理:取消所有的子协程、取消自己、将异常继续向上传递。如下图:
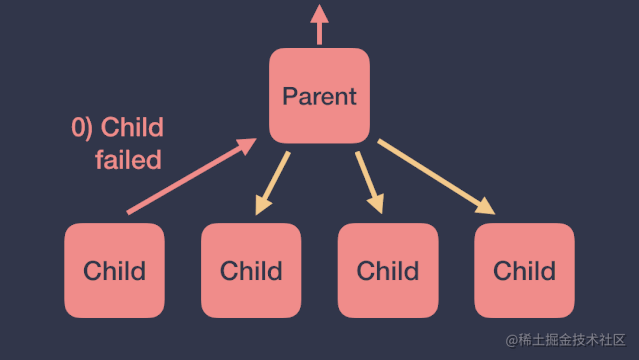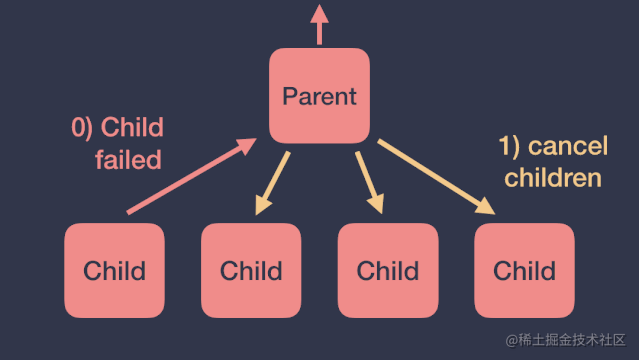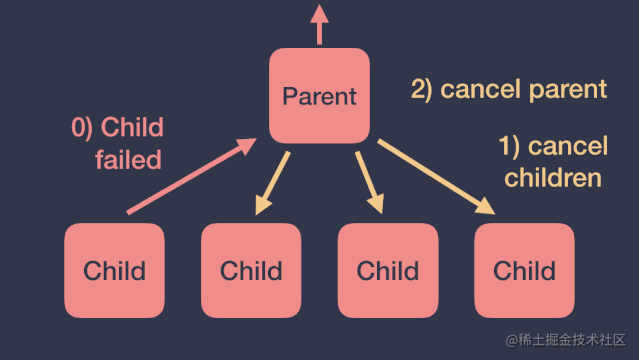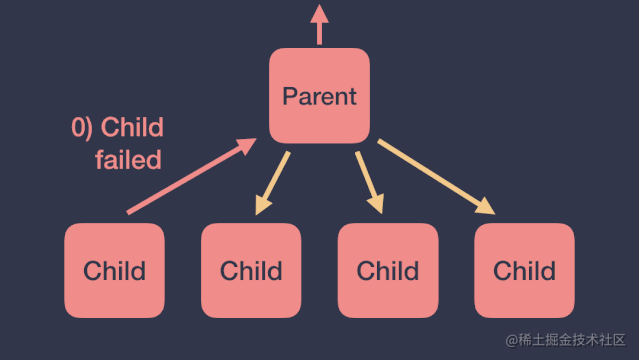
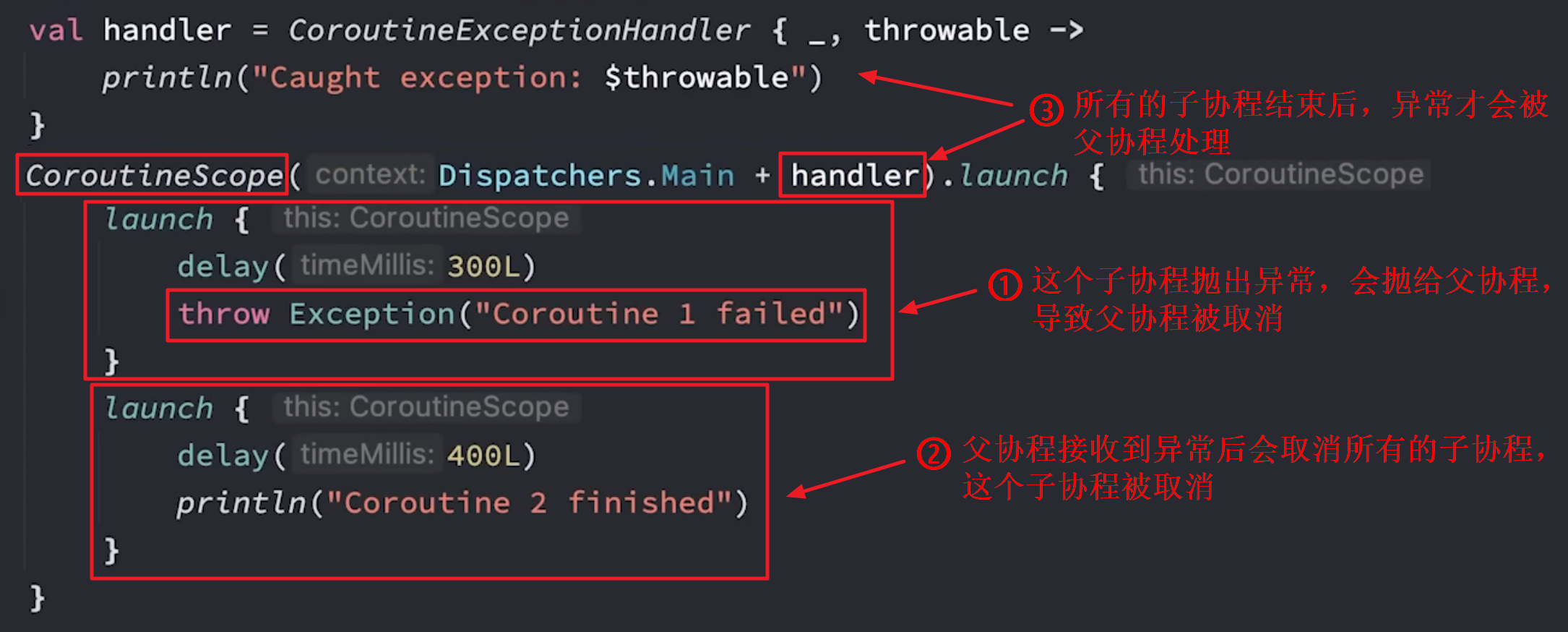
但这种情况有时并不是我们想要的,我们更希望一个协程在产生异常时,不影响其他协程的执行。
使用SupervisorJob
private fun testSupervisorJob() {
val context = Job() + Dispatchers.IO
lifecycleScope.launch {
launch(context) {
delay(1000)
println("子协程1")
}
launch(context) {
delay(2000)
println("子协程2")
9 / 0 // 此处会抛出ArithmeticException异常
}
launch(context) {
delay(3000)
println("子协程3")
}
launch(context) {
delay(4000)
println("子协程4")
}
delay(5000)
println("父协程")
}
}
} 运行之后直接崩溃了, 后面2个子协程没有被执行,这是因为第2个子协程中发生了未捕获的异常,将它传递给了父协程,而父协程发现也不能处理这个异常,于是交给系统处理,默认处理就是终止应用程序。同时父协程又取消了所有的子协程。假如为子协程指定异常处理器,则不会导致崩溃,如下:
运行之后直接崩溃了, 后面2个子协程没有被执行,这是因为第2个子协程中发生了未捕获的异常,将它传递给了父协程,而父协程发现也不能处理这个异常,于是交给系统处理,默认处理就是终止应用程序。同时父协程又取消了所有的子协程。假如为子协程指定异常处理器,则不会导致崩溃,如下:
private fun testSupervisorJob() {
val context = Job() + Dispatchers.IO + CoroutineExceptionHandler { context, throwable ->
println("${context[CoroutineName]} 发生了异常: $throwable")
}
lifecycleScope.launch {
launch(context + CoroutineName("子协程1")) {
delay(1000)
println("子协程1")
}
launch(context + CoroutineName("子协程2")) {
delay(2000)
println("子协程2")
9 / 0 // 此处会抛出ArithmeticException异常
}
launch(context + CoroutineName("子协程3")) {
delay(3000)
println("子协程3")
}
launch(context + CoroutineName("子协程4")) {
delay(4000)
println("子协程4")
}
delay(5000)
println("父协程")
}
}
此时主线程不会崩溃了,但是由于第二个协程发生了异常,传递给了父协程,导致父协程取消了其他子协程,因此看不到子协程3和4的输出。此时我们将Job替换成SupervisorJob:
private fun testSupervisorJob() {
val context = SupervisorJob() + Dispatchers.IO + CoroutineExceptionHandler { context, throwable ->
println("${context[CoroutineName]} 发生了异常: $throwable")
}
lifecycleScope.launch {
launch(context + CoroutineName("子协程1")) {
delay(1000)
println("子协程1")
}
launch(context + CoroutineName("子协程2")) {
delay(2000)
println("子协程2")
9 / 0 // 此处会抛出ArithmeticException异常
}
launch(context + CoroutineName("子协程3")) {
delay(3000)
println("子协程3")
}
launch(context + CoroutineName("子协程4")) {
delay(4000)
println("子协程4")
}
delay(5000)
println("父协程")
}
}运行之后输出:

可以看到子协程3和4这两个子协程不会因为子协程2发生了异常而被取消了,也就是说4个子协程都可以独立运行,互不影响。
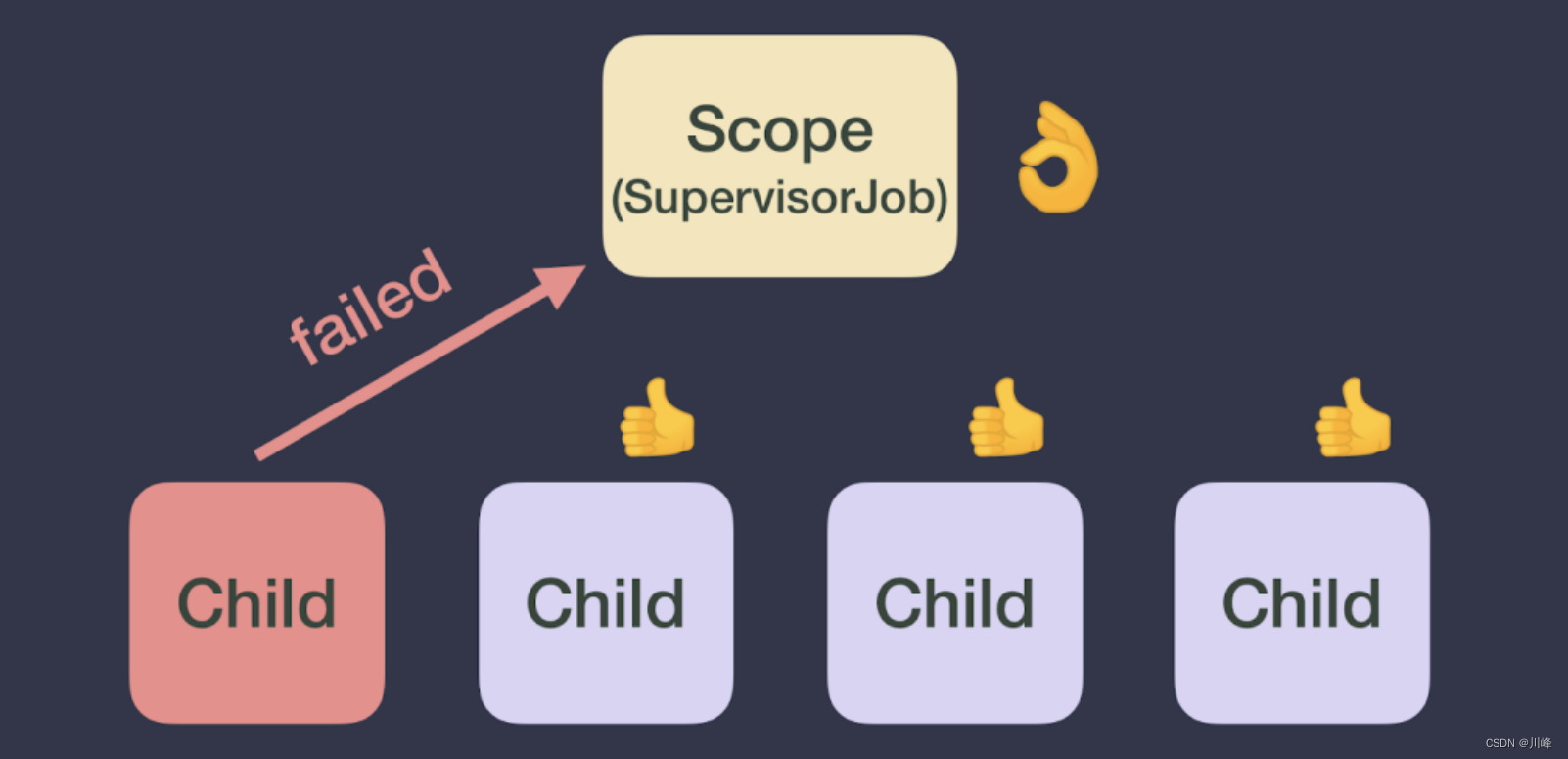
使用上下文自带SupervisorJob的Scope对象
private fun testSupervisorJob() {
val exceptionHandler = CoroutineExceptionHandler { context, throwable ->
println("${context[CoroutineName]} 发生了异常: $throwable")
}
lifecycleScope.launch {
lifecycleScope.launch {
delay(1000)
println("子协程1")
}
lifecycleScope.launch(exceptionHandler) {
delay(2000)
println("子协程2")
9 / 0 // 此处会抛出ArithmeticException异常
}
lifecycleScope.launch {
delay(3000)
println("子协程3")
}
lifecycleScope.launch {
delay(4000)
println("子协程4")
}
delay(5000)
println("父协程")
}
}这样同样可以使得子协程之间的异常互不影响。
使用supervisorScope
private fun testSupervisorJob() {
val exceptionHandler = CoroutineExceptionHandler { context, throwable ->
println("${context[CoroutineName]} 发生了异常: $throwable")
}
lifecycleScope.launch {
supervisorScope {
launch {
delay(1000)
println("子协程1")
}
launch(exceptionHandler) {
delay(2000)
println("子协程2")
9 / 0 // 此处会抛出ArithmeticException异常
}
launch {
delay(3000)
println("子协程3")
}
launch {
delay(4000)
println("子协程4")
}
}
delay(5000)
println("父协程")
}
}相比之下,SupervisorJob可能更适合用于自定义Scope的场景中(例如在ViewModel或Service中),除了官方库自带的几种Scope,我们有时可以通过继承或组合的方式来使用CoroutineScope来创建自己的Scope对象,例如:
class MyViewModel : ViewModel() {
private val exceptionHandler = CoroutineExceptionHandler { _, throwable ->
println("发生了异常: $throwable")
}
private val scopeWithNoEffect = CoroutineScope(Dispatchers.IO + SupervisorJob() + exceptionHandler)
fun doBusiness() {
viewModelScope.launch {
scopeWithNoEffect.launch {
// ... 业务1
}
launch {
// ... 业务2
}
}
}
override fun onCleared() {
super.onCleared()
scopeWithNoEffect.cancel()
}
}这样业务1挂掉了不会影响业务2的执行。
private fun testSupervisorJob() {
lifecycleScope.launch {
launch {
throw Exception()
}
launch { }
}
}而实际上这个代码中的子协程的异常依然传递给了父协程导致崩溃,所以说子协程并没有从父协程继承SupervisorJob。
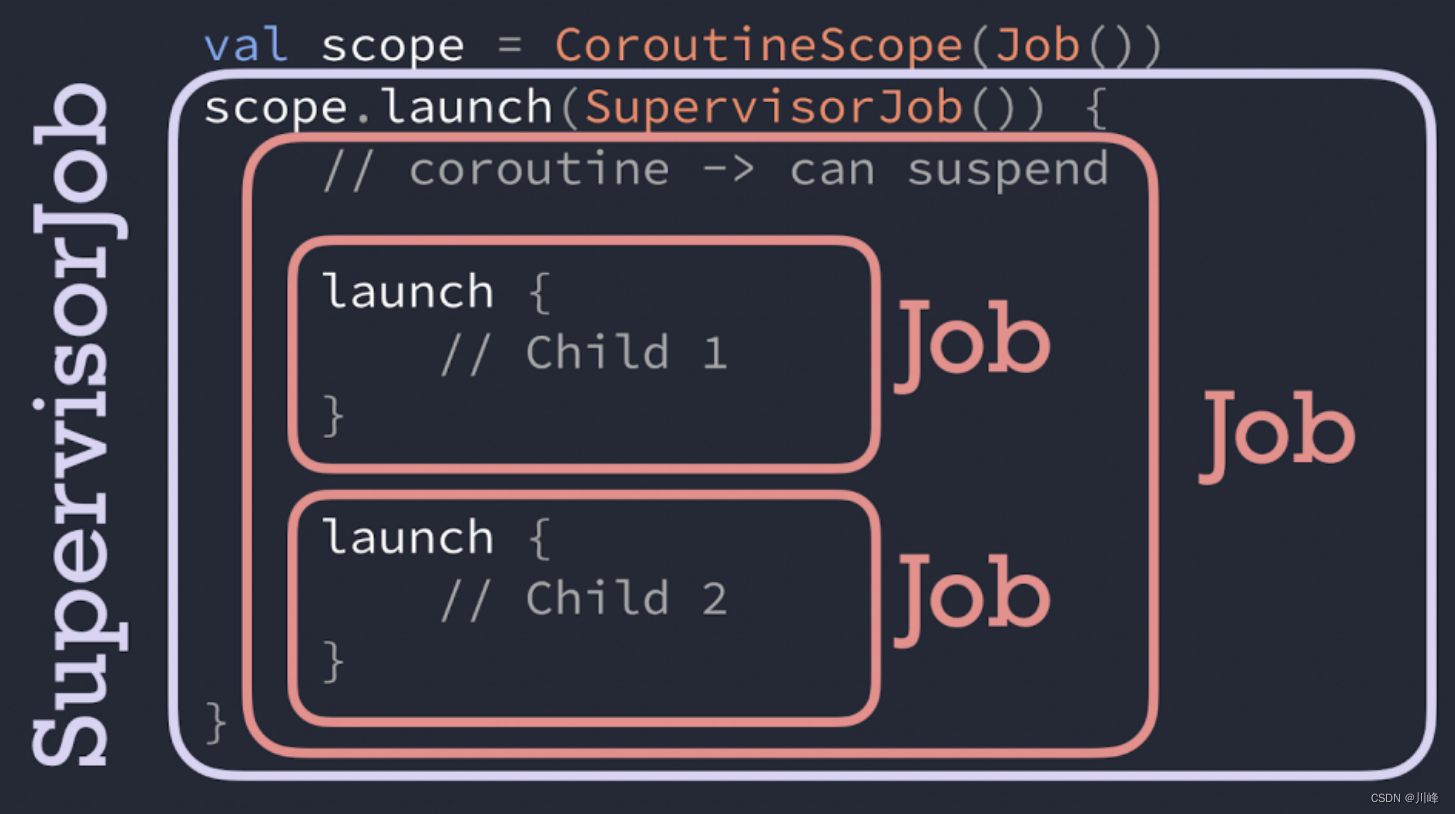
注入调度程序
在创建新协程或调用 withContext 时,请勿对 Dispatchers 进行硬编码。
// DO inject Dispatchers
class NewsRepository(
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
suspend fun loadNews() = withContext(defaultDispatcher) { /* ... */ }
}
// DO NOT hardcode Dispatchers
class NewsRepository {
// DO NOT use Dispatchers.Default directly, inject it instead
suspend fun loadNews() = withContext(Dispatchers.Default) { /* ... */ }
}这种依赖项注入模式可以降低测试难度,因为您可以使用测试调度程序替换单元测试和插桩测试中的这些调度程序,以提高测试的确定性。
挂起函数应该能够安全地从主线程调用
class NewsRepository(private val ioDispatcher: CoroutineDispatcher) {
// 因为该操作是从服务器手动获取新闻,使用阻塞Http请求,它需要将代码执行到IO调度器上,以使主线程安全
suspend fun fetchLatestNews(): List<Article> {
withContext(ioDispatcher) { /* ... implementation ... */ }
}
}
// 这个用例获取最新的新闻和相关的作者。
class GetLatestNewsWithAuthorsUseCase(
private val newsRepository: NewsRepository,
private val authorsRepository: AuthorsRepository
) {
// 该方法不需要移动协程到不同的线程,因为newsRepository是主线程安全的,
// 协程中完成的工作是轻量级的,因为它只创建一个列表,并向其中添加元素
suspend operator fun invoke(): List<ArticleWithAuthor> {
val news = newsRepository.fetchLatestNews()
val response: List<ArticleWithAuthor> = mutableEmptyList()
for (article in news) {
val author = authorsRepository.getAuthor(article.author)
response.add(ArticleWithAuthor(article, author))
}
return Result.Success(response)
}
}此模式可以提高应用的可伸缩性,因为调用挂起函数的类无需担心使用哪个 Dispatcher 来处理哪种类型的工作。该责任将由执行相关工作的类承担。
ViewModel 应创建协程
// DO create coroutines in the ViewModel
class LatestNewsViewModel(
private val getLatestNewsWithAuthors: GetLatestNewsWithAuthorsUseCase
) : ViewModel() {
private val _uiState = MutableStateFlow<LatestNewsUiState>(LatestNewsUiState.Loading)
val uiState: StateFlow<LatestNewsUiState> = _uiState
fun loadNews() {
viewModelScope.launch {
val latestNewsWithAuthors = getLatestNewsWithAuthors()
_uiState.value = LatestNewsUiState.Success(latestNewsWithAuthors)
}
}
}
// Prefer observable state rather than suspend functions from the ViewModel
class LatestNewsViewModel(
private val getLatestNewsWithAuthors: GetLatestNewsWithAuthorsUseCase
) : ViewModel() {
// DO NOT do this. News would probably need to be refreshed as well.
// Instead of exposing a single value with a suspend function, news should
// be exposed using a stream of data as in the code snippet above.
suspend fun loadNews() = getLatestNewsWithAuthors()
}视图不应直接触发任何协程来执行业务逻辑,而应将这项工作委托给 ViewModel。这样一来,业务逻辑就会变得更易于测试,因为可以对 ViewModel 对象进行单元测试,而不必使用测试视图所必需的插桩测试。
不要公开可变类型
// DO expose immutable types
class LatestNewsViewModel : ViewModel() {
private val _uiState = MutableStateFlow(LatestNewsUiState.Loading)
val uiState: StateFlow<LatestNewsUiState> = _uiState
/* ... */
}
class LatestNewsViewModel : ViewModel() {
// DO NOT expose mutable types
val uiState = MutableStateFlow(LatestNewsUiState.Loading)
/* ... */
}数据层和业务层应公开挂起函数和数据流
// Classes in the data and business layer expose either suspend functions or Flows
class ExampleRepository {
suspend fun makeNetworkRequest() { /* ... */ }
fun getExamples(): Flow<Example> { /* ... */ }
}采用该最佳实践后,调用方(通常是演示层)能够控制这些层中发生的工作的执行和生命周期,并在需要时取消相应工作。
在业务层和数据层中创建协程
class GetAllBooksAndAuthorsUseCase(
private val booksRepository: BooksRepository,
private val authorsRepository: AuthorsRepository,
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
suspend fun getBookAndAuthors(): BookAndAuthors {
// 并行地获取书籍和作者,并在两者请求时返回完成,数据准备好
return coroutineScope {
val books = async(defaultDispatcher) {
booksRepository.getAllBooks()
}
val authors = async(defaultDispatcher) {
authorsRepository.getAllAuthors()
}
BookAndAuthors(books.await(), authors.await())
}
}
}如果只要应用处于打开状态,要完成的工作就具有相关性,并且此工作不限于特定屏幕,那么此工作的存在时间应该比调用方的生命周期更长。对于这种情况,您应使用外部 CoroutineScope。
class ArticlesRepository(
private val articlesDataSource: ArticlesDataSource,
private val externalScope: CoroutineScope,
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
// As we want to complete bookmarking the article even if the user moves
// away from the screen, the work is done creating a new coroutine
// from an external scope
suspend fun bookmarkArticle(article: Article) {
externalScope.launch(defaultDispatcher) {
articlesDataSource.bookmarkArticle(article)
}
.join() // Wait for the coroutine to complete
}
}在测试中注入 TestDispatcher
-
StandardTestDispatcher:使用调度器将已在其上启动的协程加入队列,并在测试线程不繁忙时执行这些协程。您可以使用 advanceUntilIdle 等方法挂起测试线程,以允许其他加入队列的协程运行。
-
UnconfinedTestDispatcher:以阻塞方式即刻运行新协程。这样做通常可以更轻松地编写测试,但会使您无法更好地控制测试期间协程的执行方式。
class ArticlesRepositoryTest {
@Test
fun testBookmarkArticle() = runTest {
// Pass the testScheduler provided by runTest's coroutine scope to the test dispatcher
val testDispatcher = UnconfinedTestDispatcher(testScheduler)
val articlesDataSource = FakeArticlesDataSource()
val repository = ArticlesRepository(
articlesDataSource,
testDispatcher
)
val article = Article()
repository.bookmarkArticle(article)
assertThat(articlesDataSource.isBookmarked(article)).isTrue()
}
}所有 TestDispatchers 都应共用同一调度器。这样可让您在单个测试线程上运行所有协程代码,从而使测试具有确定性。runTest 会等待同一调度器上的所有协程或测试协程的所有子协程完成运行后再返回。
避免使用 GlobalScope
-
提高硬编码值。如果您对 GlobalScope 进行硬编码,则可能同时对 Dispatchers 进行硬编码。
-
这会让测试变得非常困难,因为您的代码是在非受控的作用域内执行的,您将无法控制其执行。
-
您无法设置一个通用的 CoroutineContext 来对内置于作用域本身的所有协程执行。