目录
3.pip安装label-studio (涉及的包比较多,下载时间比较长)
PS:安装label_studio一定要在label_studio的虚拟环境下安装!!
数据标注的概念
数据标注是指为机器学习和人工智能算法准备训练数据时,人工或专家为每个数据样本分配正确的标签或类别,以便让算法能够学习和理解不同的模式和关系。这样的标签可以是文本分类中的标签,图像识别中的物体类别,语音识别中的语音命令,或者其他各种形式的标记。
自然语言处理信息抽取智能标注方案包括以下几种:
基于规则的标注方案:
1.通过编写一系列规则来识别文本中的实体、关系等信息,并将其标注。
2.基于规则的标注方案是一种传统的方法,它需要人工编写规则来识别文本中的实体、关系等信息,并将其标注。
3.这种方法的优点是易于理解和实现。
4.但缺点是需要大量的人工工作,并且规则难以覆盖所有情况。
基于机器学习的标注方案:
1.通过训练模型来自动识别文本中的实体、关系等信息,并将其标注。
2.基于机器学习的标注方案是一种自动化的方法,它使用已经标注好的数据集训练模型,并使用模型来自动标注文本中的实体、关系等信息。
3.这种方法的优点是可以处理大量的数据,并且可以自适应地调整模型。
4.但缺点是需要大量的标注数据和计算资源,并且模型的性能受到标注数据的质量和数量的限制。
基于深度学习的标注方案:
1.通过使用深度学习模型来自动识别文本中的实体、关系等信息,并将其标注。
2.基于深度学习的标注方案是一种最新的方法,它使用深度学习模型来自动从文本中提取实体、关系等信息,并将其标注。
3.这种方法的优点是可以处理大量的数据,并且具有较高的准确性。
4.但缺点是需要大量的标注数据和计算资源,并且模型的训练和调试需要专业的知识和技能。
基于半监督学习的标注方案:
1.通过使用少量的手工标注数据和大量的未标注数据来训练模型,从而实现自动标注。
2.基于半监督学习的标注方案是一种利用少量的手工标注数据和大量的未标注数据来训练模型的方法。
3.这种方法的优点是可以利用未标注数据来提高模型的性能。
4.但缺点是需要大量的未标注数据和计算资源,并且模型的性能受到标注数据的质量
基于远程监督的标注方案:
1.利用已知的知识库来自动标注文本中的实体、关系等信息,从而减少手工标注的工作量。
使用数据标注的工具:label_studio
Label Studio是一个用于创建、管理和完成数据标注任务的开源工具。它可以帮助你和你的团队有效地进行数据标注,使得你可以轻松地为你的机器学习项目准备训练数据。
因为机器并不知道一句话中哪些是表示开心的情感,哪些是手机号哪些是地址等等.但是我们人类可以告诉它哪些话,哪些物体属于哪一类.
比如可以用它来标记图像中的物体位置,就像下面这样.用人工来区分,让机器知道哪些是飞机,哪些是汽车.

label_studio也可以用来对文本中的文字进行处理,要让机器知道哪些词属于什么类型.

这个是大家都知道的百度拍照中的功能--识万物。
这里面的画面机器会自动识别面前的是一台电脑!
安装label_studio:
1.创建虚拟环境
conda create -n label_studio python=3.8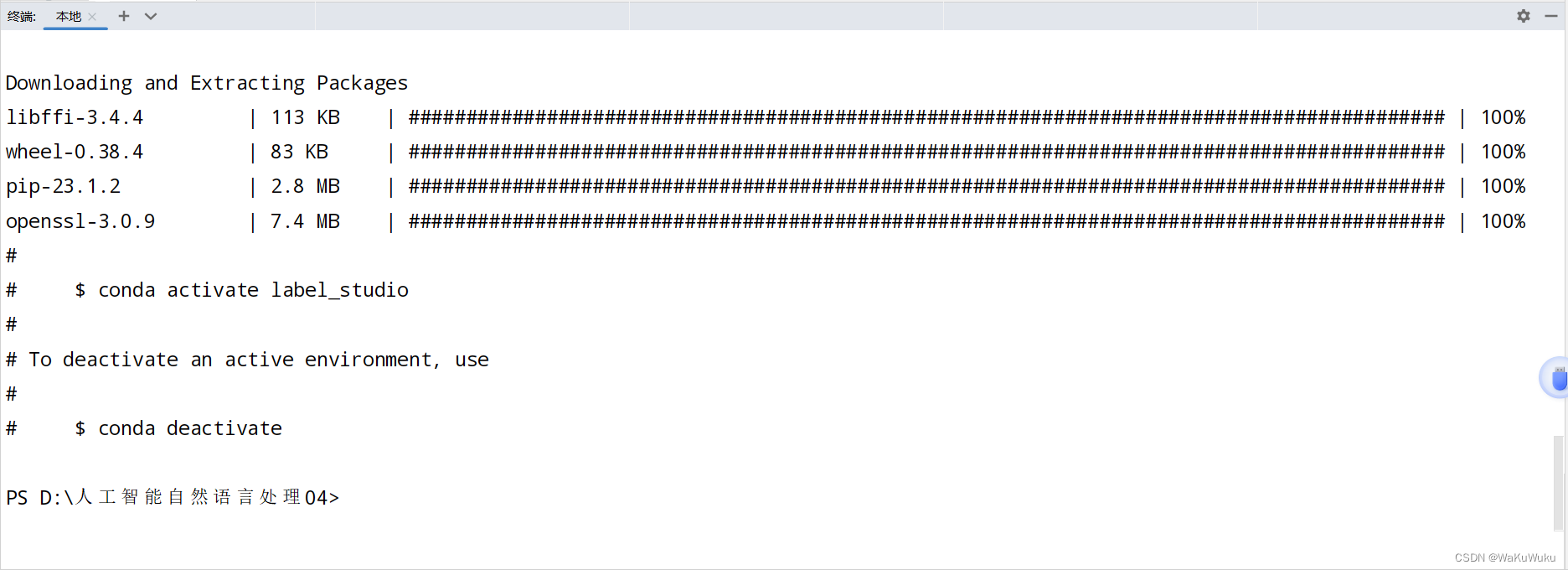
2.激活虚拟环境
conda activate label_studio
3.pip安装label-studio (涉及的包比较多,下载时间比较长)
pip install -U label-studio(安装之前确保VPN已经关闭,否则会导致安装失败)PS:安装label_studio一定要在label_studio的虚拟环境下安装!!
4.激活label_studio工具
label-studio start激活成功后会出现如下网址:http://0.0.0.0:8080/。并且会自动跳转到label_studio页面
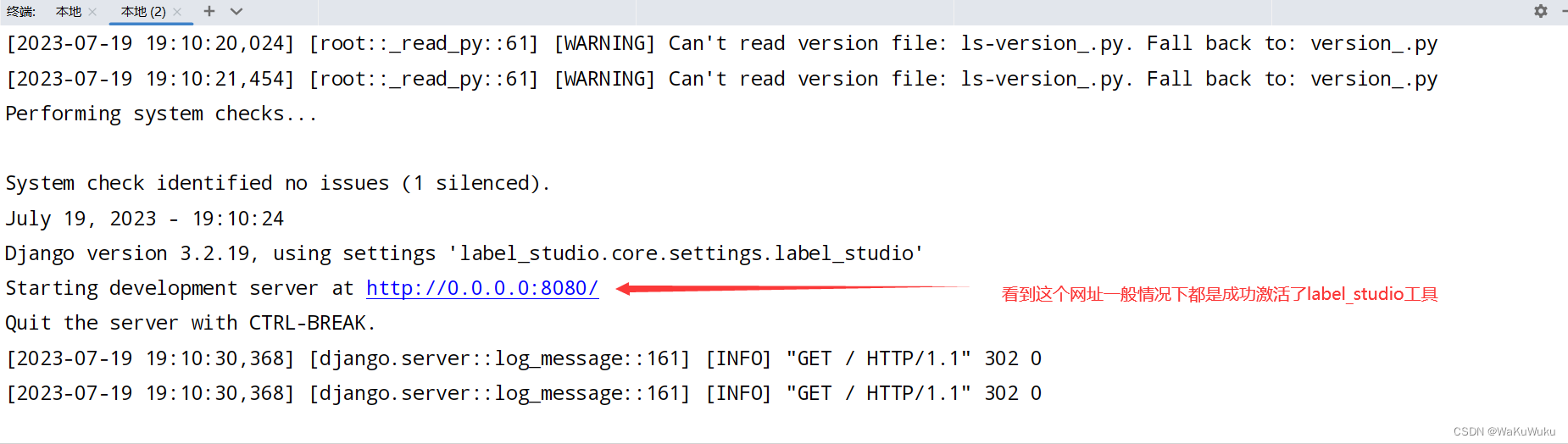

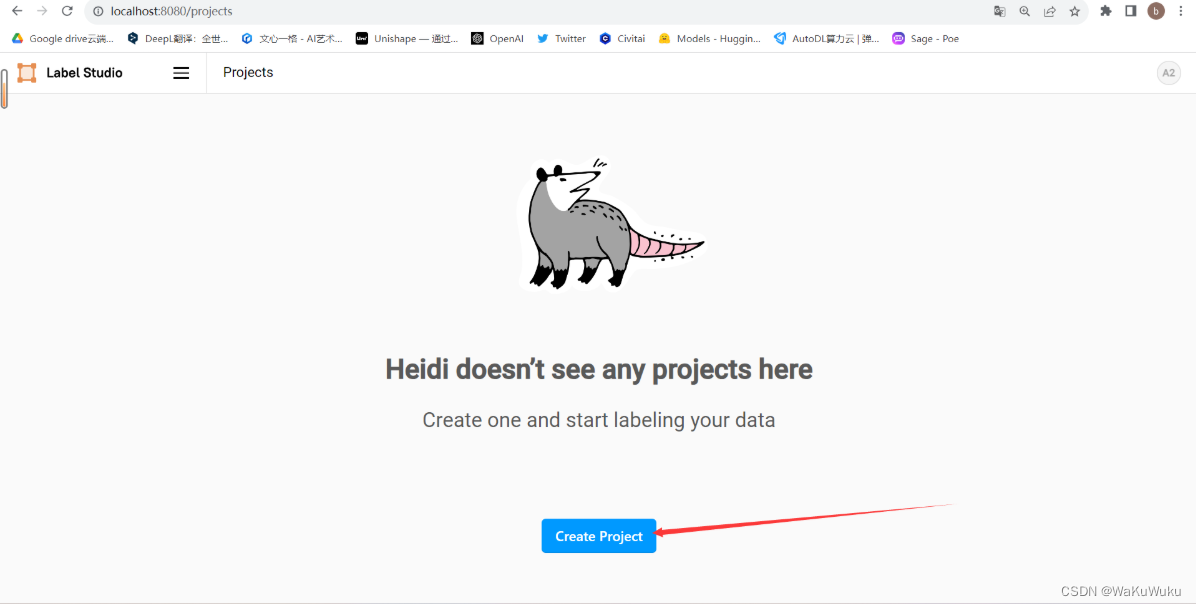
5.使用label_studio工具
登陆账号后,创建新的数据标注项目

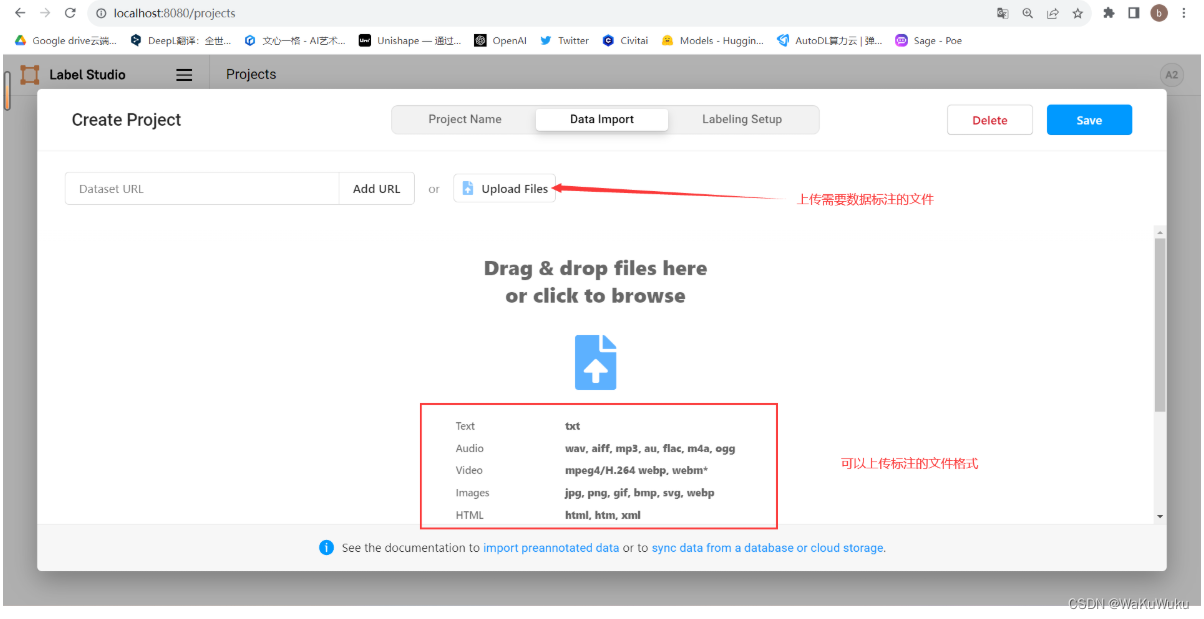



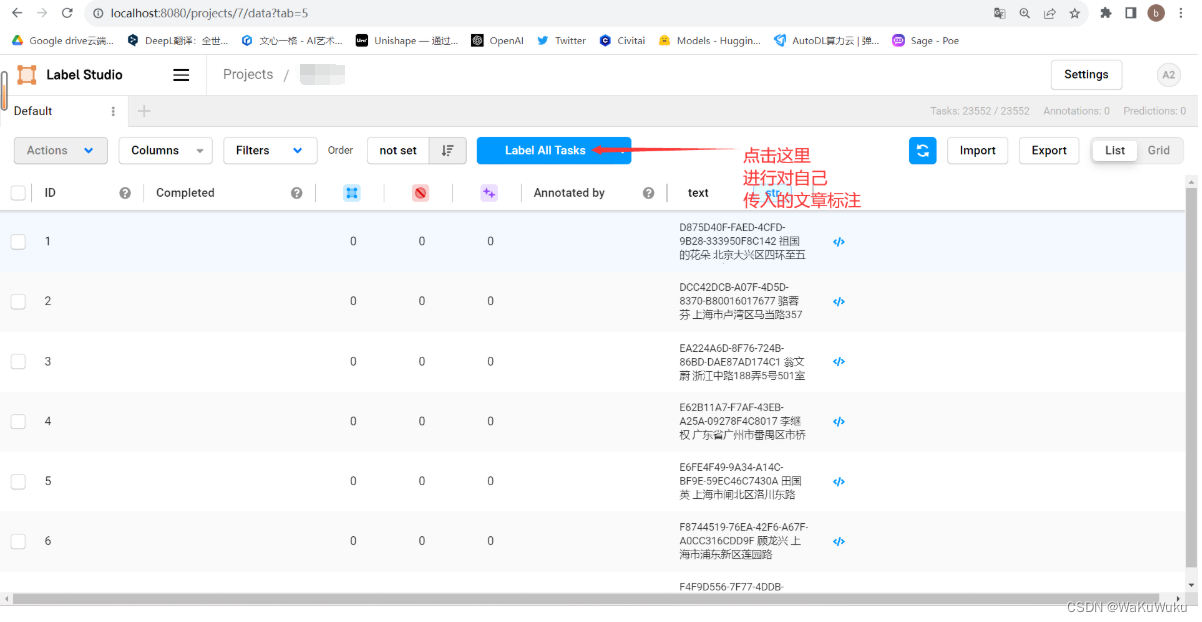

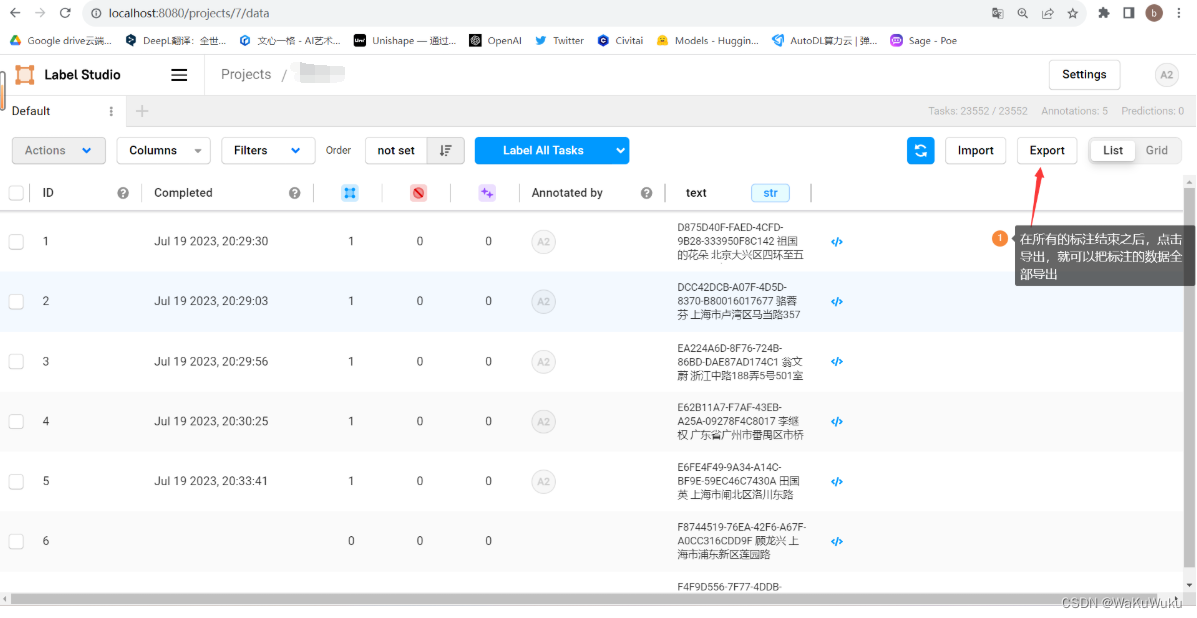

标注后的数据
在所有的数据标注完,并且成功导出你想要的文件之后,机器就会知道图片中的物体,句子中文字都会有了一个标准答案.剩下的就是把这些文件交给机器进行学习,为后面的无监督输入数据做更为准确的预测.

最后的浏览器选择问题:
使用label-stuidio的浏览器一定一定,可以说是反复实验下,选择Google Chrome和Microsoft Edge这两个浏览器,其他的国内浏览器大部分会出现标注完数据之后无法提交的问题。