Python没有提供直接的将用户定义的数据类型和文件IO关联起来的功能,但是它提供了struct库(是一个内置库)——我们可以以二进制模式来写这些数据(有趣的是,它真的是设计来讲文本数据写为缓存的)
概述
1)bytes、str
bytes是Python3.x新加的数据类型(在Python2.x中被合并在str)中
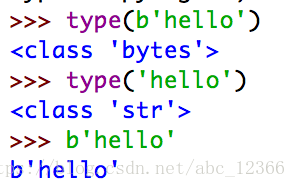
bytes是byte的序列,而str是unicode的序列
bytes通过decode()方法转换为str类型;str通过encode()方法转换为bytes类型
在互联网上是通过二进制进行传输,所以就需要将str通过encode()编码成bytes进行传输,而在接收中通过decode()解码成我们需要的编码进行处理数据这样不管对方是什么编码而本地是我们使用的编码这样就不会乱码
2)bytes()
bytes()是Python3的一个内置函数
英文文档:
class bytes([source[, encoding[, errors]]])
Return a new “bytes” object, which is an immutable sequence of integers in the range 0 <= x < 256. bytes is an immutable version of bytearray – it has the same non-mutating methods and the same indexing and slicing behavior.
Accordingly, constructor arguments are interpreted as for bytearray().
准确的讲,Python没有提供专门处理字节的数据类型
但由于b'str_obj'可以表示bytes_obj
所以,字节数组 <=> 二进制str
C语言中,我们可以很方便地用struct、union来处理字节,以及字节和int、float的转换
你可以使用位运算把其他数据类型转换为字节类型
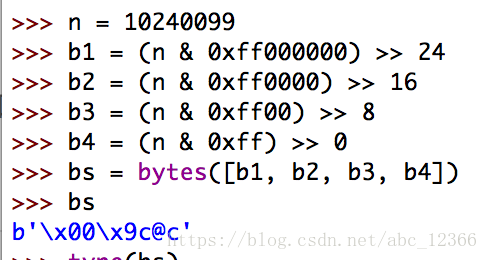
但是这样不但操作麻烦,而且就上例而言对于浮点数也无能为力
3)struct模块
在Python中,『一切皆对象』,基本数据类型也不列外
C语言的数组int a[3] = {1, 2, 4};,存储的是真正的值
Python的列表lyst = [1, 2, 4],存储的是元素的指针
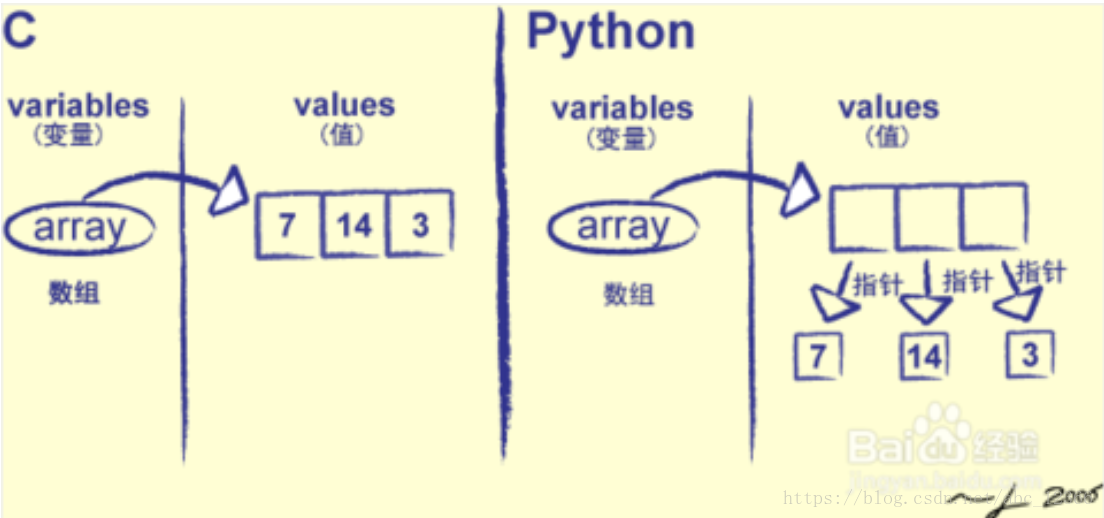
这就造成了『列表元素的不连续存储』,在Python中列表中的数据可能不会被存储为连续的字节块
为了处理它们,将python值转换为C结构很重要,即将它们打包成连续的数据字节,或者将一个连续的字节块分解成Python对象
struct模块执行Python值和以Pythonbytes表示的C结构体之间的转换,这可以用于处理存储在文件中或来自网络连接以及其他源的二进制数据;它使用一定格式的字符串作为C语言结构布局的简洁描述以及到或从Python值的预期转换
两个函数:pack()、unpack()
struct模块最重要的两个函数就是pack()、unpack()方法
打包函数:pack(fmt, v1, v2, v3, ...)
解包函数:unpack(fmt, buffer)
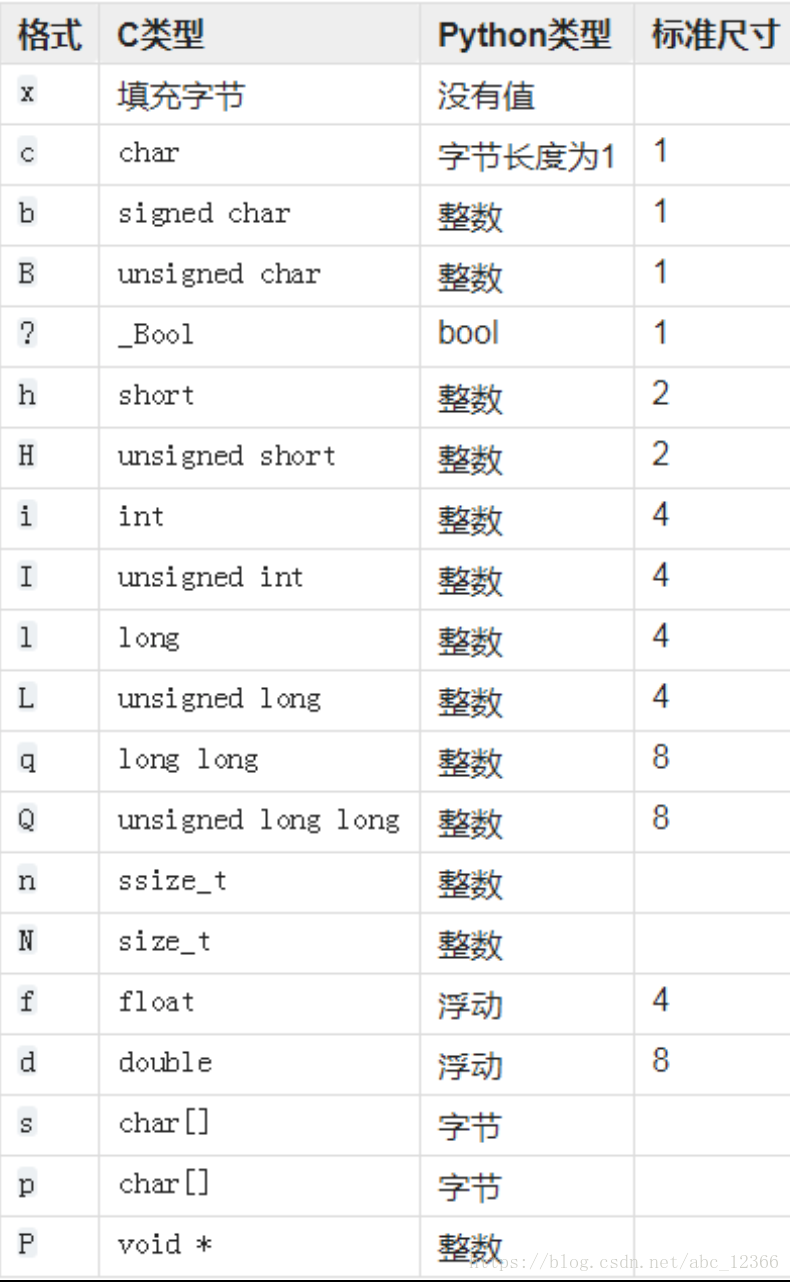
其中,fmt是格式字符(format的谐音),struct模块支持的格式化字符如下表
pack()函数
写个文件简单测试下

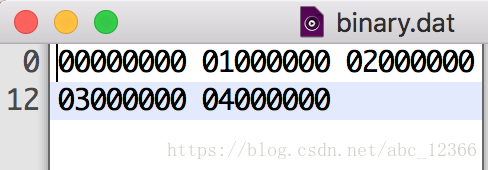
unpack()函数
使用unpack()函数从写好的二进制文件中读出文件


先用二进制编辑器随便写一个文件
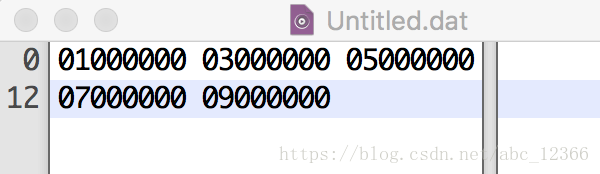
然后调用struct模块的unpack()函数读取数据

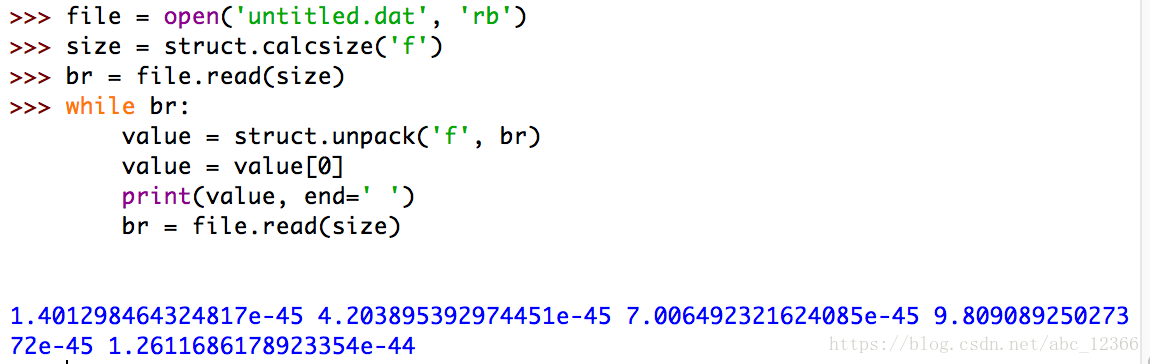
可以看到,同样的一个文件读取方式不同,输出的结果也就不同
在文件操作结束后,不要忘了file.close()