一、 前言
最近对重构Dubbo服务线程池调优,工作线程使用 CachedThreadPool 线程策略,可是上线之后,出现线程池一路上升,差点导致线上事故。

所以本篇文章对线程池揭开谜底。
二、Dubbo线程池介绍
Dubbo中 CachedThreadPool源代码
package org.apache.dubbo.common.threadpool.support.cached;
import org.apache.dubbo.common.URL;
import org.apache.dubbo.common.threadlocal.NamedInternalThreadFactory;
import org.apache.dubbo.common.threadpool.ThreadPool;
import org.apache.dubbo.common.threadpool.support.AbortPolicyWithReport;
import java.util.concurrent.Executor;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import static org.apache.dubbo.common.constants.CommonConstants.ALIVE_KEY;
import static org.apache.dubbo.common.constants.CommonConstants.CORE_THREADS_KEY;
import static org.apache.dubbo.common.constants.CommonConstants.DEFAULT_ALIVE;
import static org.apache.dubbo.common.constants.CommonConstants.DEFAULT_CORE_THREADS;
import static org.apache.dubbo.common.constants.CommonConstants.DEFAULT_QUEUES;
import static org.apache.dubbo.common.constants.CommonConstants.DEFAULT_THREAD_NAME;
import static org.apache.dubbo.common.constants.CommonConstants.QUEUES_KEY;
import static org.apache.dubbo.common.constants.CommonConstants.THREADS_KEY;
import static org.apache.dubbo.common.constants.CommonConstants.THREAD_NAME_KEY;
/**
* This thread pool is self-tuned. Thread will be recycled after idle for one minute, and new thread will be created for
* the upcoming request.
*
* @see java.util.concurrent.Executors#newCachedThreadPool()
*/
public class CachedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
//1 获取线程名称前缀 如果没有 默认是Dubbo
String name = url.getParameter(THREAD_NAME_KEY, DEFAULT_THREAD_NAME);
//2. 获取线程池核心线程数大小
int cores = url.getParameter(CORE_THREADS_KEY, DEFAULT_CORE_THREADS);
//3. 获取线程池最大线程数大小,默认整型最大值
int threads = url.getParameter(THREADS_KEY, Integer.MAX_VALUE);
//4. 获取线程池队列大小
int queues = url.getParameter(QUEUES_KEY, DEFAULT_QUEUES);
//5. 获取线程池多长时间被回收 单位毫秒
int alive = url.getParameter(ALIVE_KEY, DEFAULT_ALIVE);
//6. 使用JUC包里的ThreadPoolExecutor创建线程池
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}可以看出,Dubbo本质上是使用JUC包里的ThreadPoolExecutor创建线程池,源码如下
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}大致流程图如下:
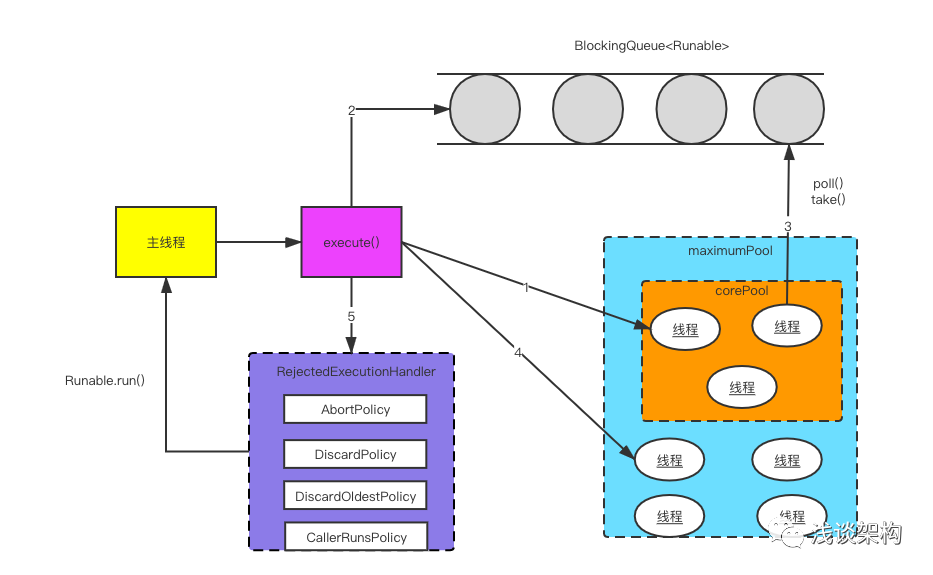
1、 当线程池小于corePoolSize时,新任务将创建一个新的线程,即使此时线程池中存在空闲线程。
2、 当线程池达到corePoolSize时,新提交的任务将被放入workQueue中,等待线程池任务调度执行。
3、 当workQueue已满,且maximumPoolSize>corePoolSize时,新任务会创建新线程执行任务。
4、 当提交任务数超过maximumPoolSize时,新提交任务由RejectedExecutionHandler处理。

5、 当线程池中超过corePoolSize时,空闲时间达到keepAliveTime时,关闭空闲线程。
另外,当设置了allowCoreThreadTimeOut(true)时,线程池中corePoolSize线程空闲时间达到keepAliveTime也将关闭。
RejectedExecutionHandler 默认提供了四种拒绝策略
1、AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作;
2、CallerRunsPolicy策略:如果线程池的线程数量达到上限,该策略会把任务队列中的任务放在调用者线程当中运行;
3、DiscardOledestPolicy策略:该策略会丢弃任务队列中最老的一个任务,也就是当前任务队列中最先被添加进去的,马上要被执行的那个任务,并尝试再次提交。
4、DiscardPolicy策略:该策略会默默丢弃无法处理的任务,不予任何处理。当然使用此策略,业务场景中需允许任务的丢失;
值得注意的是,Dubbo中拒绝策略 AbortPolicyWithReport 实际上是继承了 ThreadPoolExecutor.AbortPolicy 策略,主要是多打印了一些关键信息和堆栈信息。
三、 关于线程池配置
线程池配置非常重要,但是往往很容易忽视,配置不合理或者线程池复用次数少,依然会频繁的创建和销户。
如何合理计算核心线程数?
我们可以通过接口平均响应时间和服务需要支撑的QPS计算 例如: 我们接口平均RT 0.005s,那么,一个工作线程可以处理任务数200 如果单机需要支撑QPS 3W,那么可以计算出 需要核心线程数 150
即公式: QPS ➗ (1 ➗ 平均RT) = QPS * RT
容易忽视的 @Async 注解
Spring中使用 @Async 注解 默认线程池是 SimpleAsyncTaskExecutor,默认情况下如果没有配置等于没有使用线程池,因为它每次都会重新创建一个新的线程,不会复用。
所以切记,如果使用@Async 一定要配置.
@EnableAsync
@Configuration
@Slf4j
public class ThreadPoolConfig {
private static final int corePoolSize = 100; // 核心线程数(默认线程数)
private static final int maxPoolSize = 400; // 最大线程数
private static final int keepAliveTime = 60; // 允许线程空闲时间(单位:默认为秒)
private static final int queueCapacity = 0; // 缓冲队列数
private static final String threadNamePrefix = "Async-Service-"; // 线程池名前缀
@Bean("taskExecutor")
public ThreadPoolTaskExecutor getAsyncExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSize);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveTime);
executor.setThreadNamePrefix(threadNamePrefix);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
// 初始化
executor.initialize();
return executor;
}
}四、 线程池飙升如何引起的?
Dubbo服务端工作线程我们配置如下:
corethreads: 150
threads: 800
threadpool: cached
queues: 10看上去是不是挺合理的,设置很小队列数,是为了防止抖动引起短暂线程池不足情况。从上面看,貌似也没什么问题,从白天业务量来说核心线程数是完全够用的(RT<5ms, QPS<1w)。可是上线之后,线程池一路飙升,最大达到阈值最大值800, 报警信息如下:
org.apache.dubbo.remoting.RemotingException("Server side(IP,20880) thread pool is exhausted, detail msg:Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-IP:20880, Pool Size: 800 (active: 4, core: 300, max: 800, largest: 800), Task: 4101304 (completed: 4101301), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://IP:20880!"从上可以看出,到达最大线程数时,active线程数是很少的,这完全不符合预期。
五、场景模拟
由源码
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues))可知:
当队列元素为0时,阻塞队列使用的是SynchronousQueue;当队列元素小于0时,使用的是无界阻塞队列LinkedBlockingQueue;当队列元素大于0时,使用的是有界的队列LinkedBlockingQueue。
核心线程数和最大线程数肯定不会有问题,所以我猜想是否队列数设置是否有问题。
为了复现,我写了个简单的代码模拟
package com.bytearch.fast.cloud;
import java.util.concurrent.*;
public class TestThreadPool {
public final static int queueSize = 10;
public static void main(String[] args) {
ExecutorService executorService = getThreadPool(queueSize);
for (int i = 0; i < 100000; i++) {
int finalI = i;
try {
executorService.execute(new Runnable() {
@Override
public void run() {
doSomething(finalI);
}
});
} catch (Exception e) {
System.out.println("emsg:" + e.getMessage());
}
if (i % 20 == 0) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
System.out.println("all done!");
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static ExecutorService getThreadPool(int queues) {
int cores = 150;
int threads = 800;
int alive = 60 * 1000;
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)));
}
public static void doSomething(final int i) {
try {
Thread.sleep(5);
System.out.println("thread:" + Thread.currentThread().getName() + ", active:" + Thread.activeCount() + ", do:" + i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}模拟结果:
| queueSize值 | 现象 |
|---|---|
| 0 | 没有出现异常 |
| 10 | 出现拒绝异常 |
| 100 | 没有出现异常 |
异常如下:
emsg:Task com.bytearch.fast.cloud.TestThreadPool$1@733aa9d8 rejected from java.util.concurrent.ThreadPoolExecutor@6615435c[Running, pool size = 800, active threads = 32, queued tasks = 9, completed tasks = 89755]
all done!很显然,当并发较高时,使用LinkedBlockingQueue有界队列, 队列数设置相对较小时,线程池会出现问题。
将queues配置改为0后上线,恢复正常。
至于更深层原因,感兴趣同学可以深度分析下,也可以公众号后台与我交流。
六、总结
这次分享了线程池 ThreadPoolExecutor 基本原理、线程池配置计算方式,和容易忽视的使用注解@Async 配置问题。
另外介绍了下我们使用线程池遇到的诡异问题,一个参数问题,可能导致不可预期的后果。
希望以上分享对你们有所帮助。