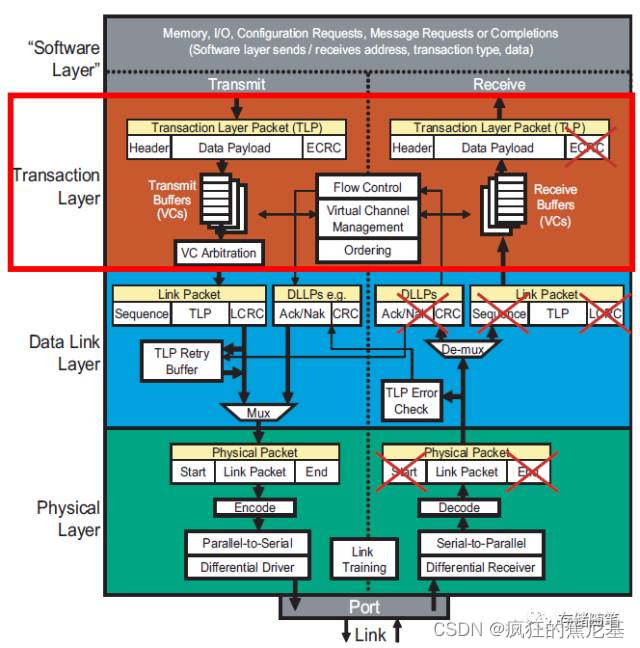
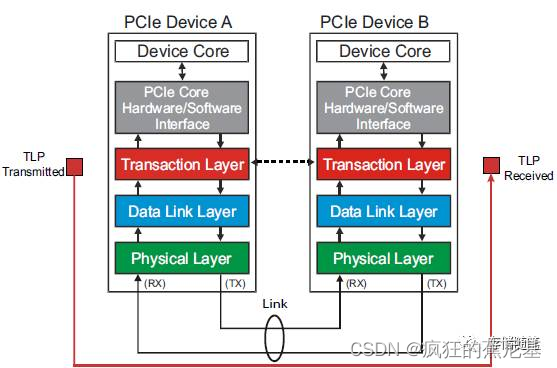
PCIe是一种封装分层协议(packet-based layered protocol),主要包括事务层(Transaction layer), 数据链路层(Data link layer)和物理层(Physical layer)。
事务层概述
在PCIe体系结构中,数据报文首先在设备的核心层(Device Core)中产生,然后再经过该设备的事务层(Transaction Layer)、数据链路层(Data Link Layer)和物理层(Physical Layer),最终发送出去。而接收端的数据也需要通过物理层、数据链路和事务层,并最终到达Device Core。
事务层的主要职责可以概述为:
事务层是PCIe总线层次结构的最高层,该层次将接收PCIe设备核心层的数据请求,并将其转换为PCIe总线事务,PCIe总线使用的这些总线事务在TLP头中定义。
PCIe总线继承了PCI/PCI-X总线的大多数总线事务,如存储器读写(Memory Read/Write)、I/O读写、配置读写总线事务,并增加了Message总线事务和原子操作等总线事务。
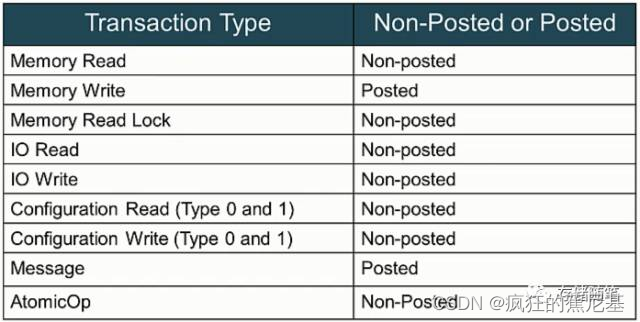
扩展:PCIe中有两大类总线事务:Non-Posted和Posted:
Non-Posted: 需要completion返回响应包;
Posted: 不需要completion返回响应包.
在PCIe总线中,Non-Posted总线事务分两部分进行,首先是发送端向接收端提交总线读写请求,之后接收端再向发送端发送完成(Completion)报文。PCIe总线使用Split传送方式处理所有Non-Posted总线事务,存储器读、I/O读写和配置读写这些Non-Posted总线事务都使用Split传送方式。
PCIe的事务层还支持流量控制(Flow control)和虚通路管理(Virtual Channel Management)等一系列特性,而PCI总线并不支持这些新的特性。
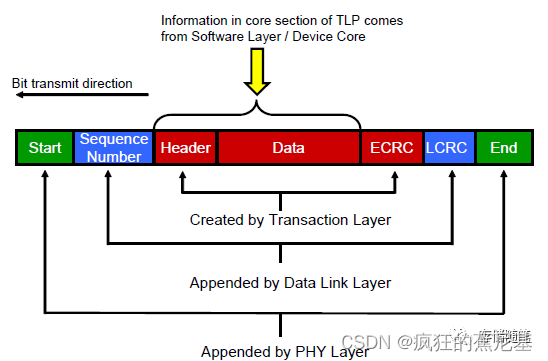
在PCIe总线中,不同的总线事务采用的路由方式不相同。PCIe总线使用的数据报文首先在事务层中形成,这个数据报文也被称之为事务层数据报文,即TLP,TLP在经过数据链路层时被加上Sequence Number前缀和CRC后缀,然后发向物理层。
事务层 TLP
PCIe总线使用的数据报文首先在事务层中形成,这个数据报文也被称之为事务层数据报文,即TLP(Transaction Layer Packet),TLP在经过数据链路层时被加上Sequence Number前缀和CRC后缀,然后发向物理层。
生活中,有时,我们会陷入一个哲学性的思考: “我们来自哪里,终归何方?” 同样,TLP也有这个命题的解答。TLP来自发送设备的事务层,历经“磨难”,终归接收端的事务层。
那么,在TLP传递的过程中到底经历哪些“磨难”呢?请看下图~
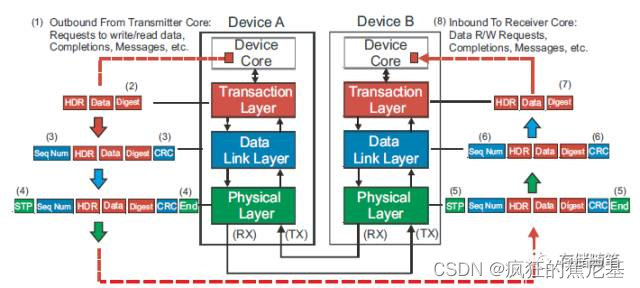
我们逐层解析一下这些“磨难”:
-
发送端Device Core发送事务请求: 数据读写, 完成反馈(Completions),信息(Message)等;
-
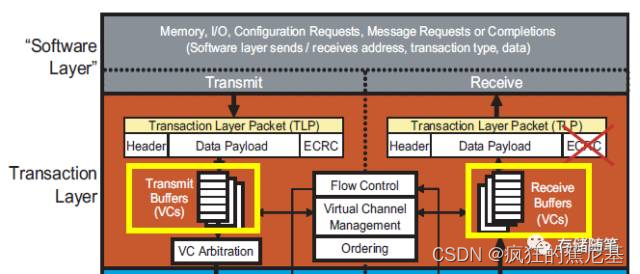
事务层根据Device Core的请求,生成TLP Header,加上Device Core提供的data, 最后加上ECRC(End to End CRC)。此时TLP会放入事务层缓存(Virtual Channel Buffer)之中;
-
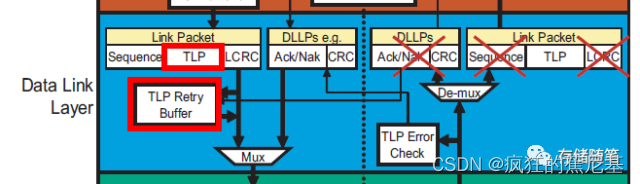
当TLP传递至数据链路层时,会被加上Squeeze Number以及LCRC(Link CRC)。此时,生成"加强版"TLP,并放入数据链路层的Retry buffer;
-
当TLP传至物理层时,被加上头和尾,到这里,TLP在发送端就组装完毕咯;
-
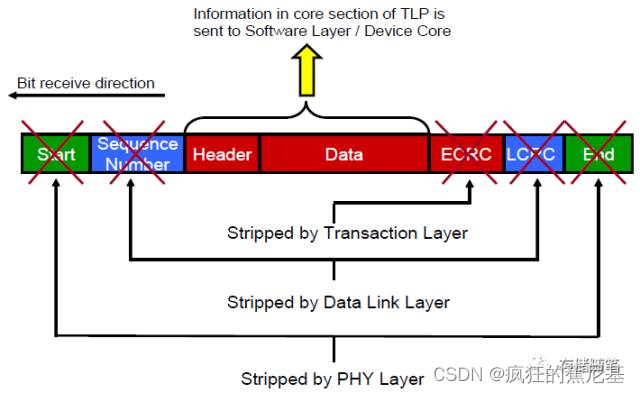
在接收端就跟发送端做的事情相反了,在物理层需要掐头去尾,然后传输至数据链路层;
-
数据链路层收到传入的TLP后,通过计算LCRC验证传输是否正确,正确的话就去掉Sequence Number和LCRC,将TLP传输至事务层;
-
事务层接收到TLP之后,解析其内容,并将信息传给接收端Device Core,至此,发送端传过来的组装TLP已拆解完毕。
TLP事务处理方式解析
TLP很重要,也有很多种类。我们先来个全局的认识,看看PCIe到底定义了多少TLP种类呢?瞅下面的表格~
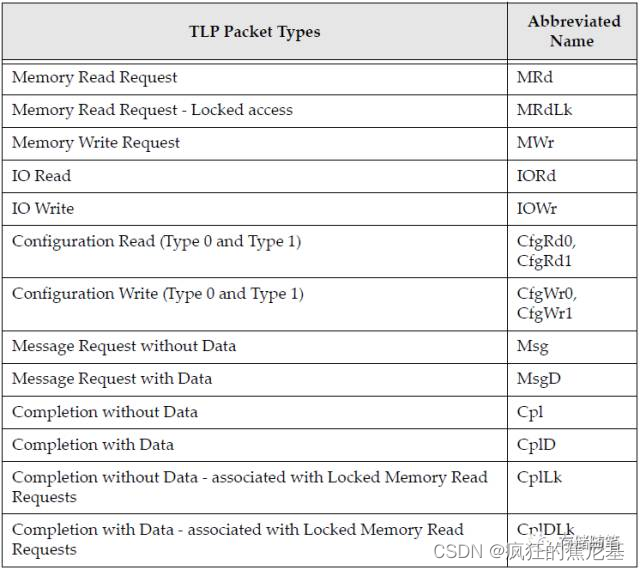
这么多TLP啊,每个都是什么含义,到底是干什么的呢?不急,我们慢慢的揭开他们神秘的面纱~
之前的介绍中,我们提到过PCIe中总线事务有两大类:Non-Posted和Posted:
- Non-Posted: 需要completion返回响应包;
- Posted: 不需要completion返回响应包
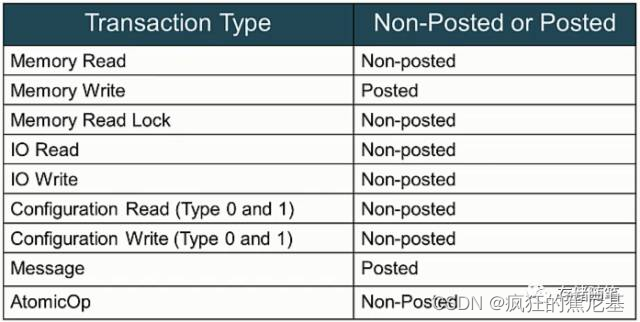
注:Memory Read Lock只适用在兼容PCI/PCI-X的陈旧设备中,在这里就先忽略了。
我们先从Non-Posted和Posted阵营中的各挑选一些代表介绍一下TLP事务的具体作用。
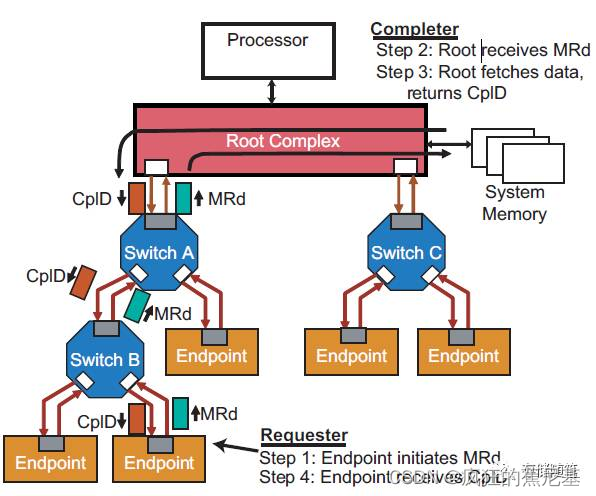
Non-Posted Memory Read:
步骤:
- PCIe端初始化Memory Read请求;
- 经过Switch到达Root Complex;
- Root收到Memory Read之后就在系统缓存中抓取数据并回传完成报告(Completion);
- 同样经过Switch到达设备端,设备端收到完成报告后结束此次事务请求。
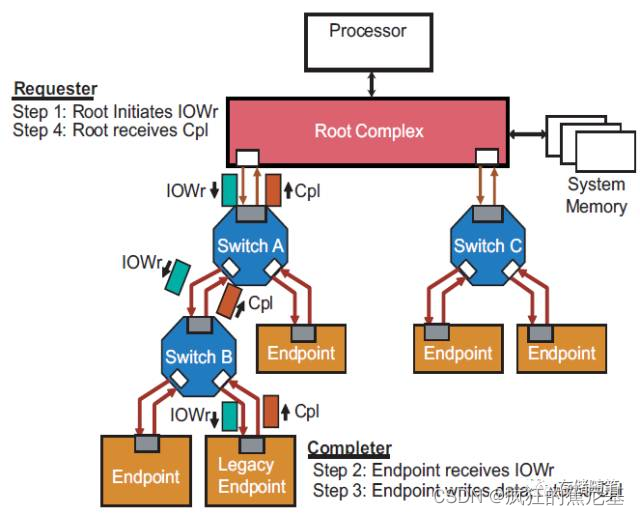
Non-Posted IO and Configuration Write:
步骤:
- Root初始化IO Write请求;
- 请求和数据经过Switch到达设备端;
- 设备端收到IO Write的请求以及数据之后,开始讲数据写入到PCIe设备中,并回传完成报告(Completion);
- 同样经过Switch到达Root,Root收到完成报告后结束此次事务请求。
注意:Non-Posted写请求只能由处理器(也可以理解为Root端)发出!
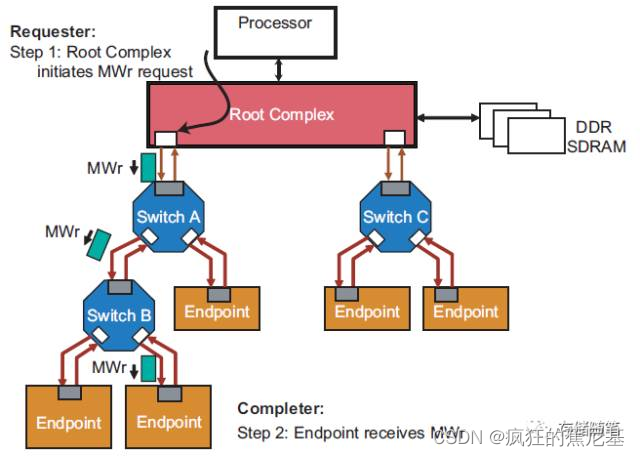
Posted Memory Write:
步骤:
-
Root初始化Memory Write请求;
由于Memory write的请求是Posted方式,不要求有完成回报(Completion). 所以在Memory write请求发送之后,Root不用等任何回应,就可以继续做其他事情啦~ -
PCIe设备端收到Memory Write请求之后就开始专心执行写入动作,也不必准备完成回报(Completion).
不需要完成回报(Completion)虽然可以加速事务处理的速度,从而提高系统性能。但是,如果在设备端出现Error,具体内容也不会回报给Root。而是会给Root发送一条信息让其转告系统软件有Error需要处理。
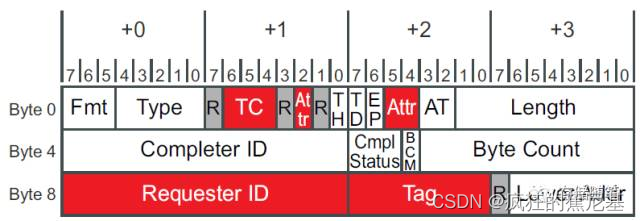
事务层TLP结构解析
PCIe总线在事务层中利用TLP (Transaction Layer Packet) 进行数据传输。那么,TLP具体长什么样子呢?又有哪些关键内容?
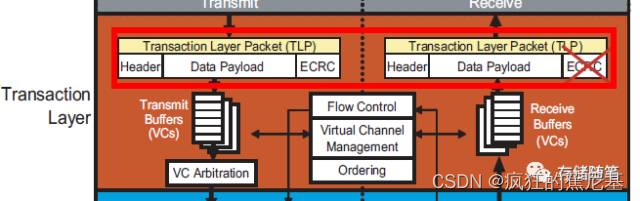
TLP主要包括三个部分:Header, Data Payload和ECRC(End to End CRC).
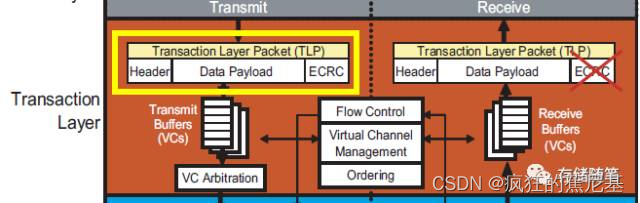
Header: 内容来自于Device
Core。大小一般为3或者4个DWs(12-16bytes)。每个类型TLP中Header格式不尽相同,但是包含的信息大致相同。Data: 内容也来自Device Core。大小为1~1024 DWs。
Digest/ECRC: 这部根据Header和Data内容计算得到。ECRC可以选择性的附加。如果附加在TLP之后,大小一般为1DW。
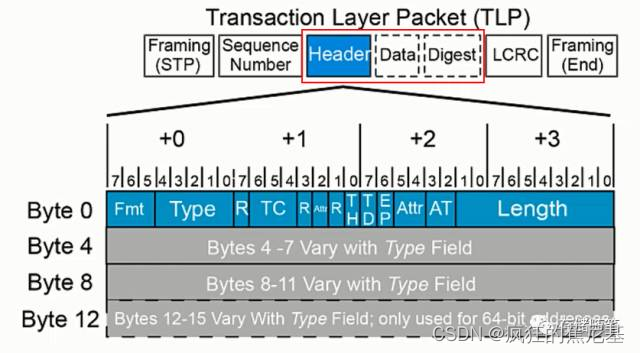
接下来,我们针对上面Header的内容进一步解析:
Fmt2:0: 3 bits, Byte0 Bit7:5, 具体含义如下:
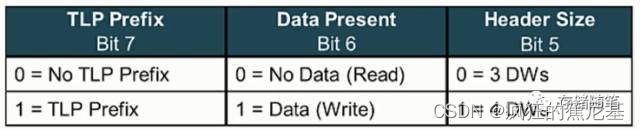
Type[4:0]: 5 bits, Byte0 Bit4:0, 详细定义如下:
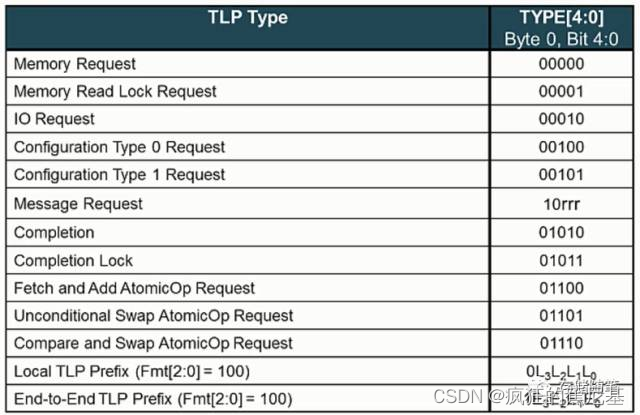
这里需要提一下,通常情况下Type[4:0]与Fmt[2:0]合起来定义具体的TLP事务类型,如下表:

举个例子:
Fmt[2:0]=001, 代表Header长度为4DWs, 并且no data传输;
Type[4:0]=00000, 代表Memory Request;
那么合起来就是,Memory Read Request(MRd).
TC[2:0](Trafic Class): 3bits, Byte1 Bit6:4, 总共定义了8个等级Trafic Class.
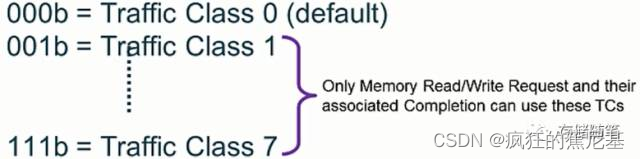
Traffic Class顾名思义可以理解为交通等级。比如在生活中我们遇到救护车或者消防车时,由于救护车和救护车是跟时间赛跑,那么交通等级就高,一般的私家车(可以认为没有交通等级)就必须给救护车和消防车让行!可能这个类比不是很恰当,不过大致意思是这样的~
Attr0: 1 bit, Byte1 Bit2, 这个bit的功能就是是否对TLP进行排序(IDO, ID-based Ordering)。
TH[0](TLP Processing Hints): 1 bit, Byte1 Bit0, 如果TH=1, 就代表在TLP中添加了TLP处理提示,可以告知系统以更有效的措施处理这个TLP。
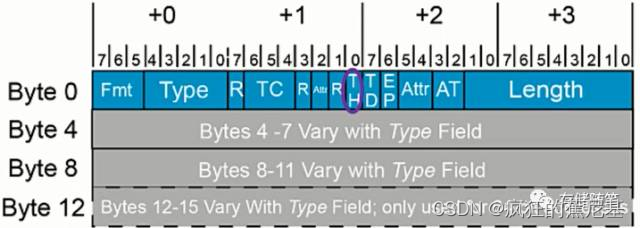
TD[0](TLP Digest): 1 bit, Byte2 Bit7, 如果TD=1,就代表TLP里面包含了ECRC(End-to-End CRC)。
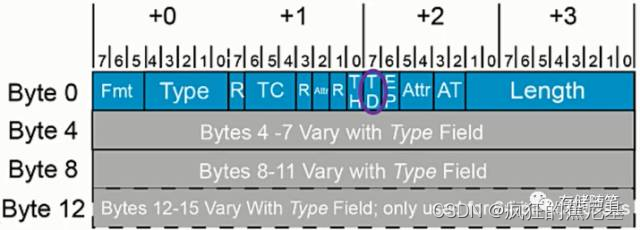
EP[0](Poisoned Data): 1 bit, Byte2 Bit6, 如果EP=1,就代表TLP传输的数据有误。

Attr1:0: 2 bits, Byte2 Bit5:4,
bit5=1代表enable PCI-X Relaxed Ordering功能;
bit4=1代表这个TLP没有主机缓存一致性的问题,不需要缓存窥探措施;
扩展:
缓存一致性: 也就是说只有一块一级缓存,所有处理器都必须共用它。在每一个指令周期,只有一个幸运的CPU能通过一级缓存做内存操作,运行它的指令。
窥探(Snoop): 窥探的思想是,缓存不仅仅在做内存传输的时候才和总线打交道,而是不停地在窥探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其他处理器都会得到通知,它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其他处理器马上就知道这块内存在它们自己的缓存中对应的段已经失效。
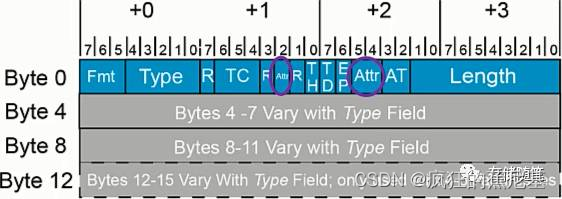
AT[1:0](Address Type): 2 bits, Byte2 Bit3:2, 这两bits针对Memory和AtomicOp请求声明存储地址类型的。
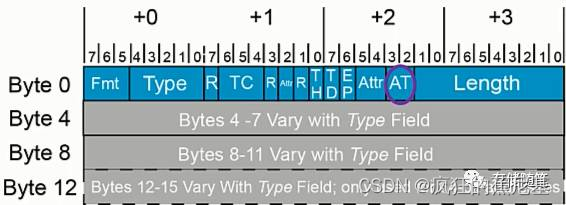
Length[9:0]: TLP传输的长度,已DW为单位,最大1024 DWs.
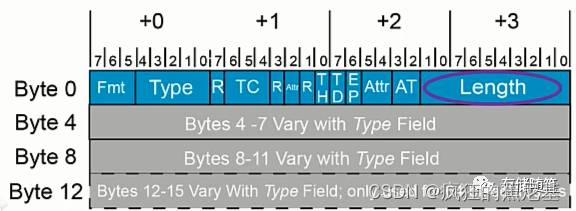
此外,为了区分Requester与Completer之间的事务类型, PCIe Spec定义了一个事务描述块(Transaction Descriptor Fields). 下图中5个红色区域合起来就称为一个事务描述块。
事务层Flow Control概述
在PCIe协议中,如果要发送一个TLP,就必须要保证接收端有足够的缓存(Buffer)来接收。为了实现这一功能,接收端会随时回报可用的缓存空间。
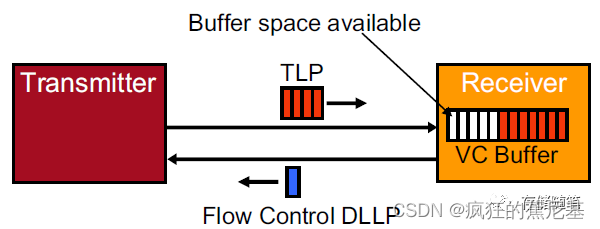
在接收端有一个缓存空间叫作VC buffer, 其中VC代表的是Virtual Channel,翻译过来就是虚拟通道。VC buffer可以存放从发送端传过来的TLPs。
PCIe可以支持8虚拟通道(VC),每个VC之间可以相互独立传输TLPs, 当一个VC buffer满的时候,并不影响其他VC继续传输。
有关VC的详细内容会在后续章节介绍,本文就不再展开了~
在flow control中, 还有一个很重要的概念不得不提一下:信用机制(Credit-based Mechanism)。因为接受端的可用VC buffer是以信用机制的方式告知发送端,在这里,信用积分代表接收端VC buffer的可用空间。
接收端会通过发送DLLPs(Data Link Layer Packets)来告知发送端VC buffer的信用积分(也就是告知VC buffer可用空间),当缓存空间快满的时候,发送端会停止发送TLP,以防VC buffer容量不足而造成发送端传输的数据被丢弃,从而避免要求发送端重新发送刚才发送的数据,最终达到更加有效利用网络带宽。
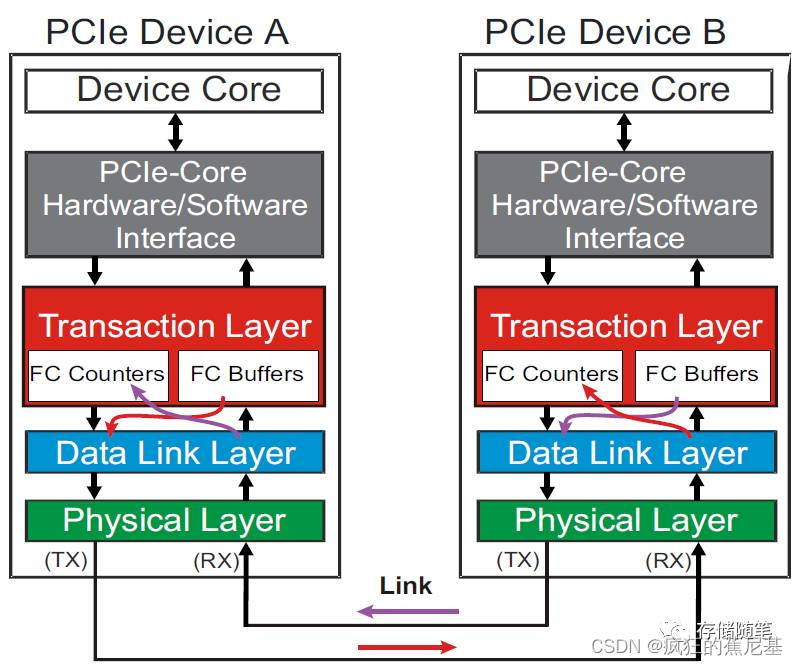
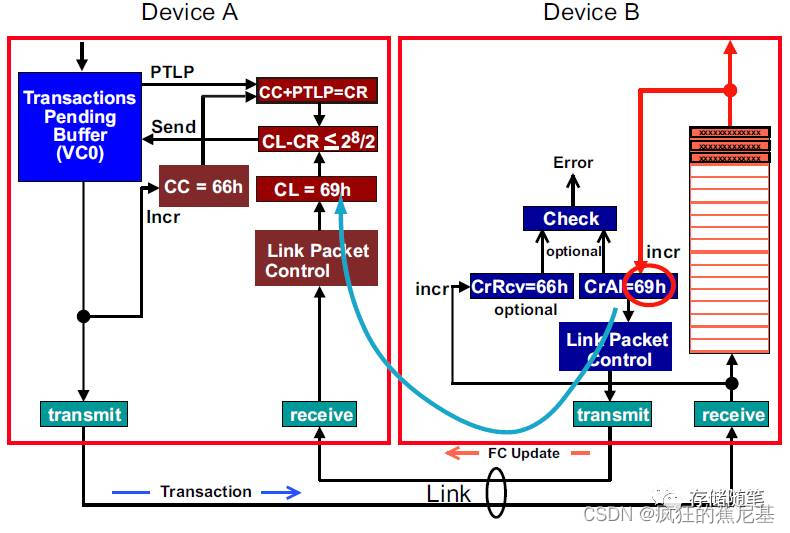
其实,事务层(Transaction Layer)和链路层(Data Link Layer)是Flow Control机制的共同监护人。如下图:
Device A和Device B均会把其事务层对应的可用空间(FC Buffer)告知链路层,链路层会在适当的时间生成Flow control DLLPs将可用空间的信息转送至接收端。(Device A to Device B, Device B to Device A)
Flow Control的实现过程
要实现flow control功能,我们需要了解Flow control的控制逻辑单元。在之前的文章介绍中,我们了解了VC buffer有六个部分,每部分对应的Flow控制逻辑单元是一样的,所以,在这里,我们仅以Non-Posted Request Header对应的Flow control控制逻辑单元为例,如下图:
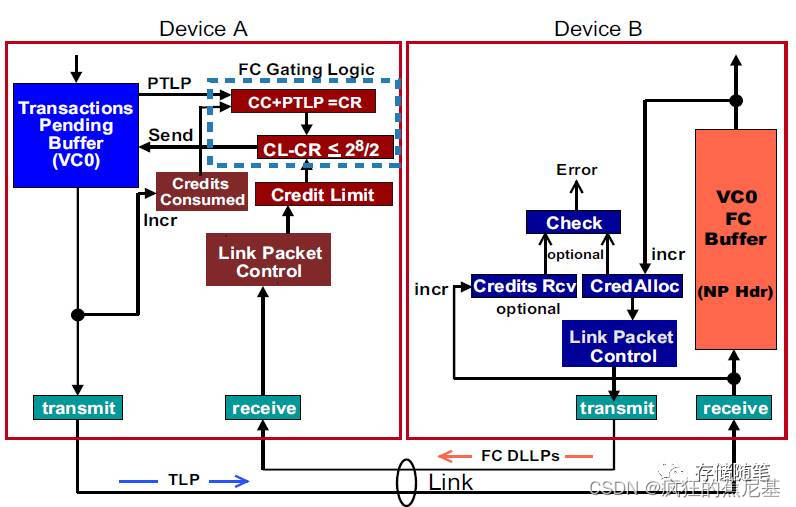
从上图中,我们可以看到Flow control控制逻辑单元主要包括:
发送端:
- Transaction Pending Buffer:发送端用于存放正在等待在同一虚拟通道(VC)传输的TLPs.
- Credits Consumed Counter:在发送端在VC buffer中所有TLPs的信用单元总和,简称“CC”.
- Credit Limit Counter:这部分由接收端的VC buffer的大小决定,简称“CL”。接收端会在TLPs 传输的过程中不断发送FC DLLPs来更新CL的大小.
- Flow Control Gating Logic:这个逻辑单元主要根据CC,CL以及待发送的TLPs的数量来判断接收端是否有足够的空间接收下一个TLPs. 判断公式如下:
{CL-(CC+PTLP)} mod 21 <= 22/2
注释: Header Field Size=8, Data Field Size=12.
PTLP= Pending TLP,待发送TLP.
接受端:
- Flow Control Buffer:存储传进来的Data和Header数据.
- Credits Allocated:接送端VC buffer已经分配的存储空间记录.
- Credit Received Counter:这部分主要记录接收端接收的所有TLPs对应的信用单位总和。
我们看一个例子看一下Flow control具体过程:
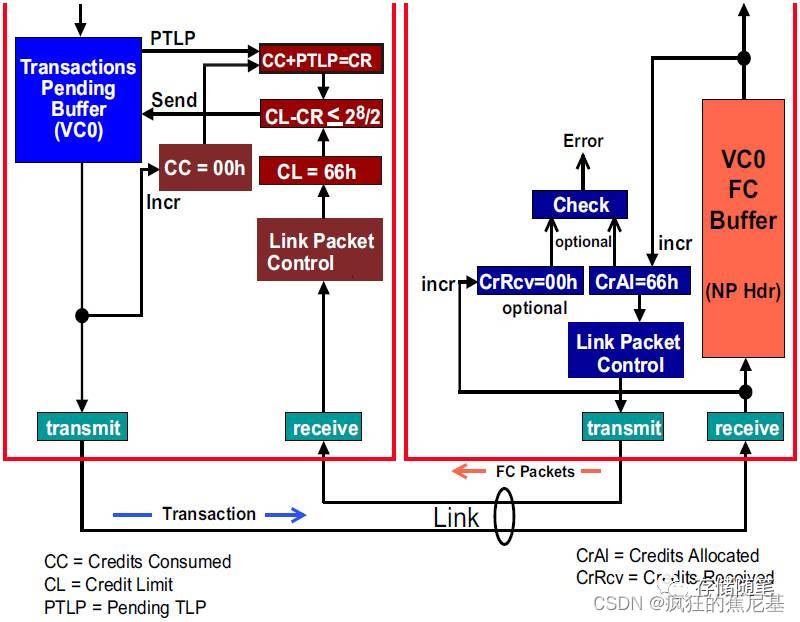
1. 初始状态下 Flow control控制逻辑单元:
在这里例子中,我们假设VC buffer大小为2KB,之前的文章介绍过Non-Posted Header的信用大小为5DW,也就是20Bytes, 所以Flow control单元数目最大为2KB/20Bytes=102d=66h.
初始状态下:CC=00h, CL=66h, CrRcv=00h, CrAl=66h,
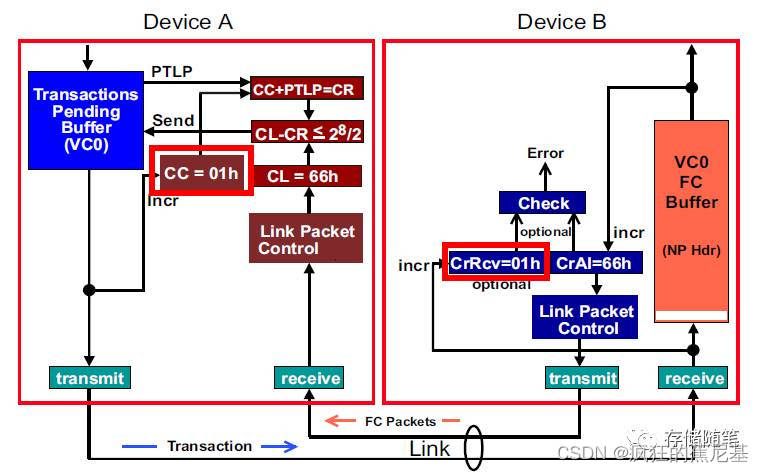
2. 传输一个TLP之后的Flow Control控制逻辑单元:
此时,CC=01h,CrRcv=01h,
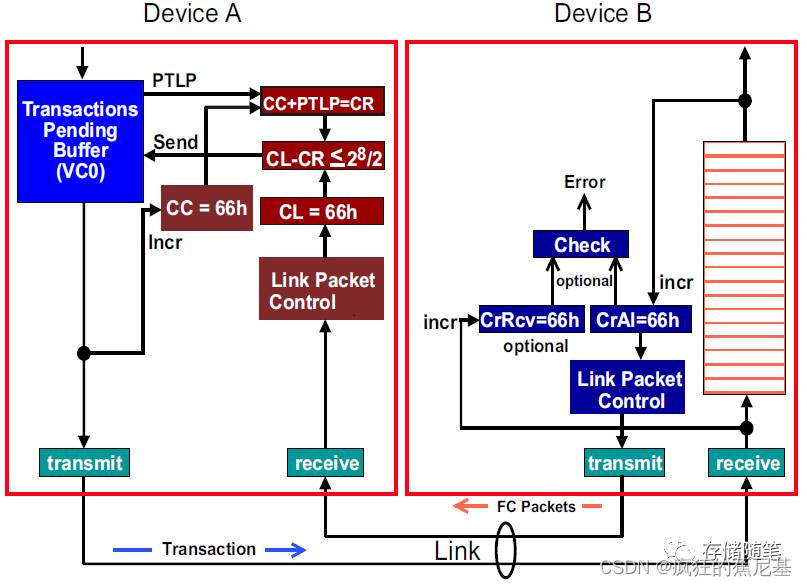
3. VC buffer出于满的状态时的Flow Control控制逻辑单元:
发送端: CC=CL=66h, CR=CC+PTLP=66h+01h=67h,
CL-CR=66h-67h=66h+99h=FFh不满足判断公式.
接收端: CrRcv=CrAl=66h,
此时,说明了VC buffer已经满了,暂停传输TLPs.
4. VC buffer清空部分数据的Flow Control控制逻辑单元:
接收端VC buffer清空了3个Non-Posted Header数据,此时VC buffer有了新的可用空间,可以继续接受TLPs. 但此时发送端并不知道,怎么办呢?
放大招!!!
PCIe协议中有定义一个Flow Control update packets, 也即Flow Control update DLLPs.格式如下图,
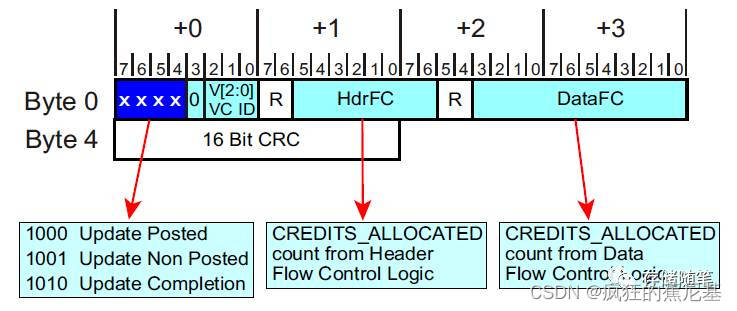
有了大招就好办了,接受端通过发送Flow control update DLLPs告知发送端:“我这边腾出地方了,可以传TLPs过来咯!”
同时,CL更新为69h, CC=66h, CR=66h+01h=67h,
CL-CR=69h-67h=02h<128, 满足判断公式,TLPs可以继续传输。
事务排序
与其他协议一样,当同一个通信等级(Traffic Class, TC)的多个事务(Transactions)同时通过同一个通道时,PCIe对这些事务设置了一些排序(Transaction Ordering)规则。
这样做的好处有以下几点:
- 保持与传统总线的兼容性。比如PCI,PCI-X等;
- 保证事务的完成具有准确性,并且按照设计人员的意愿完成;
- 避免死锁的状况发生;
- 最大限度的优化PCIe总线的传输效率。
注释:死锁是指两个以上的设备在访问临界资源时,相互等待对方释放这些资源,而无法访问这些资源的情况。
在PCI总线上,只支持Strong Ordering传送规则,而在PCIe总线中新增了Relaxed Ordering(RO) 和 ID-based Ordering(IDO)传递方式。
Strong Ordering:
何为Strong Ordering? 顾名思义,Strong,就是很强壮,很彪悍的意思。Strong Ordering强制总线上的TLP按照先来后到的方式进行传递,一视同仁,不管是否有特殊情况,均不允许插队和绿色通道。但是事情总有轻重缓急,对于一些紧急的状况,这个强制规则难免会影响到总线的传递效率和用户体验。
我们看下面一个例子,
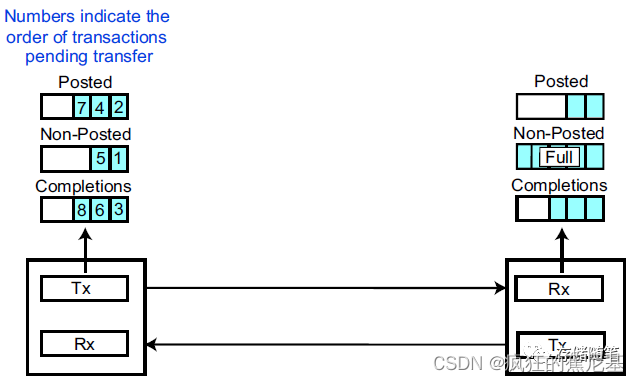
-
所有的TLPs类型统一编号;
-
发送端VC buffer有8个待传输的TLPs,依次编号为#1~8,这8个TLPs分为三类:
Posted:2, 4, 7;
Non-Posted: 1, 5;
Completions: 3, 6, 8; -
接收端对应的VC buffer如上图,其中,Non-Posted buffer已满,而Posted、Completions buffer则仍有可用空间;
此时,接收端Non-Posted buffer已满,TLP 1,5则需要暂停发送。由于这8个TLPs属于同一VC,需要按照Strong-Ordering规则排序。所以TLP 2,3,4对应接收端VC buffer即使有可用空间,也必须等TLP 1传输完成之后才能发送。
这不就是浪费时间嘛,浪费别人的时间,就等于谋杀呀Strong-Ordering太不厚道咯~~
Relaxed Ordering(RO):
相比PCI, PCIe则深得中庸之道,更加善解人意。PCIe支持的Relaxed Ordering的传递规则不会要求TLPs严格遵守先来后到,也意味着根据轻重缓急找到最佳的方案,提高数据的传输效率。
不过,Relaxed Ordering是有条件的。因为每个TLP只能对应一个TC(通信等级), 而这个TC有只能对应唯一一个VC(虚拟通道)。所以说:
- VC相同的TLPs遵循Relaxed Ordering规则,
- VC不同的TLPs则没有事务排序的要求,不必遵循Relaxed Ordering规则。
VC相同的TLPs需要遵循的排序规则具体如下表:
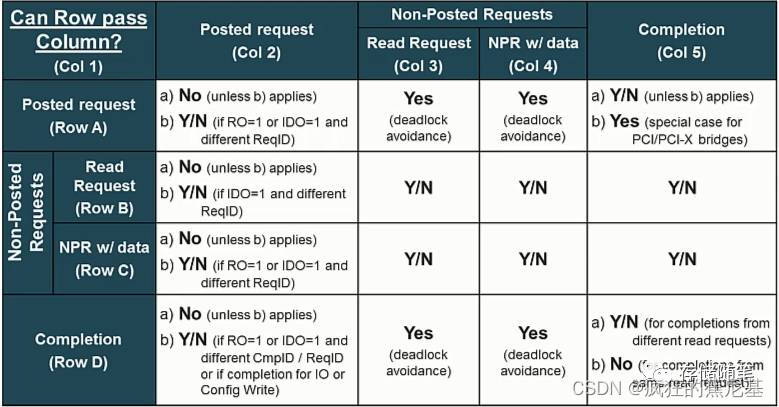
先解释一下表格中的Yes, Y/N, No对应的含义:
Yes: 代表第二个事务必须在第一个事务之前通过,也就是强制性"超车";
Y/N: 没有排序要求;
No: 代表第二个事务绝对不允许在第一个事务之前通过,也就是"超车"违法.
我们解析一下表格中的A2b, B2, C2b, D2b的内容来阐述一下Relaxed-Ordering的效果:
A2b: 当RO=1, 也即Enable Relaxed-Ordering规则。此时,Memory Writes or Messages被允许超车之前的Memory Writes or Messages而抢先通过;
B2: 无论RO bit是否被置起来, Read Requests均不被允许超车之前的Memory Writes or Messages而抢先通过;
C2b: 当RO=1, IO writes和Configuration writes被允许超车之前的Memory Writes or Messages而抢先通过;
D2b: 当RO=1, Competitions被允许超车之前的Memory Writes or Messages而抢先通过;
ID-based Ordering(IDO):
IDO的模型是在PCIe V2.1版本之后新增的功能。该模型引入了"数据流"(Stream)的概念,即:
- 相同数据源发送的TLPs属于同一数据流;
- 不同数据源发送的TLPs属于不同的数据流;
IDO模型允许不同数据流的TLPs之间不必遵循事务排序的约定。
我们来看个例子:
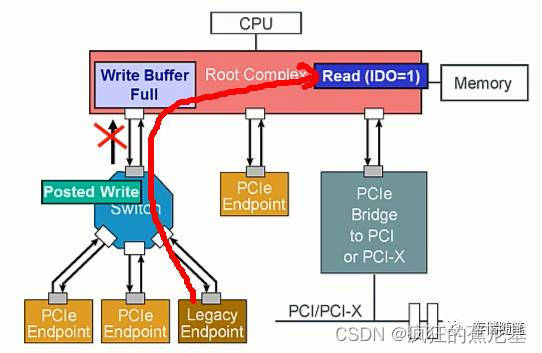
-
设备1发送了Posted Write Request, 但是,此时Write Buffer已处于满的状态,所以Posted-Write被锁定在Switch。
-
随后,设备3发送了Non-Posted Read Request, 通过Switch时,正好撞到了上面表格B2所指规则(B2: 无论RO bit是否被置起来, Read Requests均不被允许超车之前的Memory Writes or Messages而抢先通过;), 所以,Read request同样被锁定在Switch。
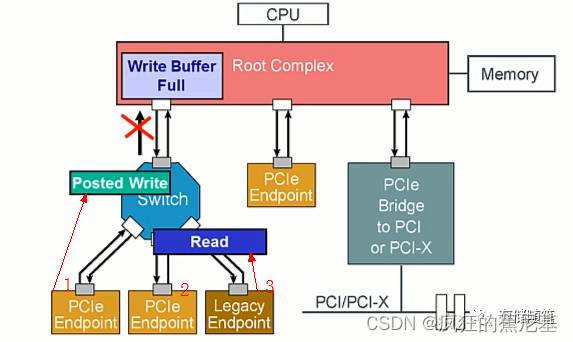
此时,就要靠IDO这位大神出手咯~
依照IDO模型的思想,Posted Write request和Read request的数据源不一样,可以不遵循事务排序规则。
所以,当PCIe总线enable IDO功能时,Read request可以很开心的通过Switch,这个时候,Posted Write只有羡慕嫉妒恨的份儿咯~~~