在学习userbasedCF推荐算法的过程中,我尝试了从宏观和微观两个角度分析推荐算法系统的多样性
Intra diversity:
函数表达式如下,m为训练集长度,L为用户推荐列表长度,ajαajβ为用户j推荐列表中α和β两物品的相似度。先求一个用户的推荐列表多样性,再求系统总体多样性。
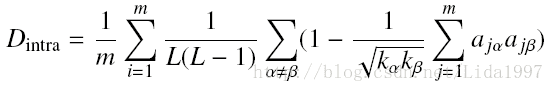
计算物品-物品相似度的代码如下
def itemSimilarity(self,train = None):
train = train or self.traindata
self.itemSim = dict()
C = dict()
N = dict()
user_items = dict()
itemsN=set() #创建物品集合
for u,item in train.items():
for i in item.keys():
itemsN.add(i)
for i in itemsN:
for j in itemsN:
if i == j:
continue
C.setdefault(i,{})
C[i].setdefault(j,0) #创建一个物品-物品值全为0的字典
for u,item in train.items():
for i in item.keys():
user_items.setdefault(u,set())
user_items[u].add(i)
for user,items in user_items.items():
for i in items:
N.setdefault(i,0)
N[i] += 1
for j in items:
if i == j:
continue
C.setdefault(i,{})
C[i].setdefault(j,0)
C[i][j] += 1
for i,related_items in C.items():
self.itemSim.setdefault(i,dict())
for j,cij in related_items.items():
self.itemSim[i][j] = cij / math.sqrt(N[i]*N[j]*1.0)
#计算物品i与物品j之间相似度intraDiversity的代码实现:
def intraDiversity():
ubcf = UserBasedCF('C:\Users\Desktop\PythonDatabase\\u.data')
ubcf.readData()
ubcf.splitData(4,100)
ubcf.userSimilarityBest()
ubcf.itemSimilarity()
IntraD=0
m=943
R=0
for w in range(m):
rank = ubcf.recommend(user="%s"%(w+1),k = 3)
ret=0
for u,item in rank.items():
for v,item in rank.items():
if u == v:
continue
ret += ubcf.itemSim["%s"%(u)]["%s"%(v)]
R += (1-ret/(40*(40-1)))#每个用户的推荐列表的inIntraD += R/m
print"IntraD:"%.5f"%IntraDInter diversity:
函数表达式如下,根据列表物品同现矩阵计算两用户推荐列表相似性得出系统总体多样性。
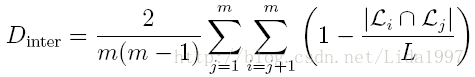
def interDiversity():
ubcf = UserBasedCF('C:\Users\Desktop\PythonDatabase\\u.data')
ubcf.readData()
ubcf.splitData(4,100)
ubcf.userSimilarityBest()
InterD=0
m=943
for w in range(m):
rank = ubcf.recommend(user="%s"%(w+1),k = 3)
for u in range(m):
if w>=u:
continue
rant = ubcf.recommend(user="%s"%(u+1),k = 3)
ret=0
c=0
for i in rank.items():
for j in rant.items():
if i[0]==j[0]:
c += 1
ret +=(1-c*1.0/40) #两个用户推荐列表间多样性,列表长度L=40
InterD += ret*2/(m*(m-1))
print InterD:""%.5f"%InterD