前言
with as 详解, [Hive、Oracle、mysql8及以上支持]
with as 也叫做子查询部分,hive 可以通过with查询来提高查询性能,因为先通过with语法将数据查询到内存,然后后面其它查询可以直接使用。
with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以!
其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标(未进行表缓存)。
使用注意事项:
- 1.with子句必须在引用的select语句之前定义,而且后面必须要跟select查询,否则报错。
- 2.with as后面不能加分号,with关键字在同级中只能使用一次,允许跟多个子句,用逗号隔开,
最后一个子句与后面的查询语句之间只能用右括号分隔,不能用逗号。
create table a as
with t1 as (select * from firstTable),
t2 as (select * from secondTable),
t3 as (select * from thirdTable)
select * from t1,t2,t3;
- 3.前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句。
with t1 as (select * from firstTable),
t2 as (select t1.id from t1) #第二个子句t2中用了第一个子句的查询t1
select * from t2
-
当我们书写一些结构相对复杂的SQL语句时,可能某个子查询在多个层级多个地方存在重复使用的情况,这个时候我们可以使用 with as 语句将其独立出来,极大提高SQL可读性,简化SQL~
注:目前 oracle、sql server、hive等均支持 with as 用法,但 mysql并不支持! -
2019-05-31更新:MySQL8.0大量更新优化,支持Common table expressions,即支持 with 语法!
WITH t1 AS (
SELECT *
FROM table1
),
t2 AS (
SELECT *
FROM table2
)
SELECT *
FROM t1, t2
注意事项:
这里必须要整体作为一条sql查询,即with as语句后不能加分号,不然会报错。
- with子句必须在引用的select语句之前定义,同级with关键字只能使用一次,多个只能用逗号分割;最后一个with 子句与下面的查询之间不能有逗号,只通过右括号分割,with 子句的查询必须用括号括起来.
以下写法会报错:
with t1 as (select * from table1)
with t2 as (select * from table2)
select * from t1,t2
with t1 as (select * from table1);
select * from t1
有分号
- 2.如果定义了with子句,但其后没有跟select查询,则会报错!
以下写法会报错:
with t1 as (select * from table1)
- 正 确写法(没有使用 t1没关系,其后有select就行):
with t1 as (select * from table1)
select * from table1
- 3.前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句!
正确写法:
with t1 as (select * from table1),
t2 as (select t1.id from t1)
select * from t2
问题:
- 1、with不适合过大的表,会落盘,频繁shuffle ,过大时直接落表更好。
- 2、with as 是提高了可读性,可若是后面多次利用这个片段,那完整的SQL就会异常庞大,放在大数据Hive中,job数量甚至会翻几倍,这也是一个坑,所以适用情况得看自己权衡。
with as没有缓存数据,减少表扫描,优化速度的作业,其实并不是这样,以下通过实验分析和证明
写一个很简单的语句:
with t as(
select regexp_replace(reflect("java.util.UUID", "randomUUID"), "-", "") AS id --生成一个随机id
,'andy' as name
)
select * from t
union all
select * from t
;
执行结果:
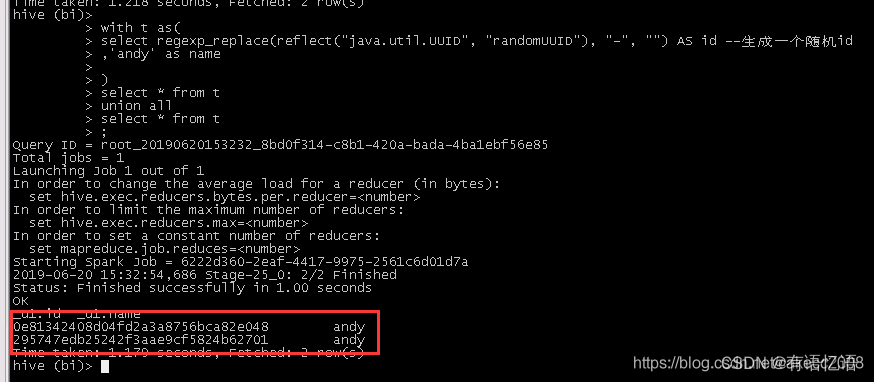
结果中可以看到,产生了两个不一样的id,说明reflect函数被执行了两次,即with as中的子查询被执行了两次。
- 再来看下执行计划:
hive (bi)>
> explain
> with t as(
> select regexp_replace(reflect("java.util.UUID", "randomUUID"), "-", "") AS id --生成一个随机id
> ,'andy' as name
> )
> select * from t
> union all
> select * from t
> ;
OK
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Spark
DagName: root_20190620153535_78057156-80df-4c9b-8c8e-f896ad4d74ed:53
Vertices:
Map 1
Map Operator Tree:
TableScan
alias: _dummy_table
Row Limit Per Split: 1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
Select Operator
expressions: regexp_replace(reflect('java.util.UUID','randomUUID'), '-', '') (type: string), 'andy' (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
File Output Operator
compressed: true
Statistics: Num rows: 2 Data size: 2 Basic stats: COMPLETE Column stats: COMPLETE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Map 2
Map Operator Tree:
TableScan
alias: _dummy_table
Row Limit Per Split: 1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
Select Operator
expressions: regexp_replace(reflect('java.util.UUID','randomUUID'), '-', '') (type: string), 'andy' (type: string)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: COMPLETE
File Output Operator
compressed: true
Statistics: Num rows: 2 Data size: 2 Basic stats: COMPLETE Column stats: COMPLETE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.063 seconds, Fetched: 50 row(s)
从执行计划中可以看到,产生了两个map。
所以说,with as是不能减少表扫描的。
- 为了对比,将以上语句稍作修改,然后在oracle中执行。结果如下:
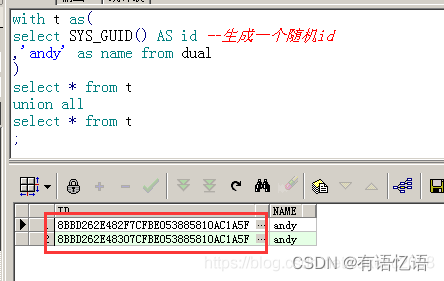
可以看到在oracle中,sys_guid()函数
只被执行了一次。
总结
如果此篇文章有帮助到您, 希望打大佬们能
关注、点赞、收藏、评论支持一波,非常感谢大家!
如果有不对的地方请指正!!!