highlight: arduino-light
Netty配置主从Reactor模式
通过将NioServerSocketChannel绑定到了bossGroup。
将NioServerSocketChannel接收到请求创建的SocketChannel放入workerGroup。
将2个不同的SocketChannel绑定到2个不同的Group完成了主从 Reactor 模式。
分配NIOEventLoop的规则
根据不同策略给Channel分配的规则不同。
1.普通:递增取模
2.高级:executors总数是2的幂次方才会使用位运算 效率更高
如何跨平台创建选择器
在创建NioEventLoopGroup的时候,会根据指定的线程数,循环遍历创建NioEventLoop。
java @Override protected EventLoop newChild(Executor executor, Object... args) throws Exception { return new NioEventLoop(this, executor, (SelectorProvider) args[0], ((SelectStrategyFactory) args[1]).newSelectStrategy(), (RejectedExecutionHandler) args[2]); }
java NioEventLoop(NioEventLoopGroup parent, Executor executor, SelectorProvider selectorProvider, SelectStrategy strategy, RejectedExecutionHandler rejectedExecutionHandler) { super(parent, executor, false, DEFAULT_MAX_PENDING_TASKS, rejectedExecutionHandler); if (selectorProvider == null) { throw new NullPointerException("selectorProvider"); } if (strategy == null) { throw new NullPointerException("selectStrategy"); } provider = selectorProvider; //使用selectorProvider创建selector 属于EventLoop的成员变量 final SelectorTuple selectorTuple = openSelector(); selector = selectorTuple.selector; unwrappedSelector = selectorTuple.unwrappedSelector; selectStrategy = strategy; }
那么这个selectorProvider是从哪来的呢?原来是构造NioEventLoopGroup的时候获取的。
java public NioEventLoopGroup(int nThreads, Executor executor) { this(nThreads, executor, SelectorProvider.provider()); }
SelectorProvider.provider()最终会走到sun.nio.ch.DefaultSelectorProvider.create(),查看create()方法,发现该处为Netty的精明之处,调用了JDK自带的DefaultSelectorProvider类,该类会根据不同平台实例化不同的类。策略模式的体现。
下面看下在NIO中Selector的open方法:
java public static Selector open() throws IOException { return SelectorProvider.provider().openSelector(); }
这里使用了SelectorProvider去创建一个Selector,看下provider方法的实现:
```java public static SelectorProvider provider() { synchronized (lock) { if (provider != null) return provider; return AccessController.doPrivileged( new PrivilegedAction () { public SelectorProvider run() { if (loadProviderFromProperty()) return provider; if (loadProviderAsService()) return provider;
//默认走到了这里
provider = sun.nio.ch.DefaultSelectorProvider.create();
return provider;
}
});
}} ```
看下sun.nio.ch.DefaultSelectorProvider.create()方法,该方法在不同的操作系统中的代码是不同的,在windows中的实现如下:
java public static SelectorProvider create() { return new WindowsSelectorProvider(); }
在Mac OS中的实现如下:
java public static SelectorProvider create() { return new KQueueSelectorProvider(); }
在linux中的实现如下:
java public static SelectorProvider create() { String str = (String)AccessController.doPrivileged(new GetPropertyAction("os.name")); if (str.equals("SunOS")) return createProvider("sun.nio.ch.DevPollSelectorProvider"); if (str.equals("Linux")) return createProvider("sun.nio.ch.EPollSelectorProvider"); return new PollSelectorProvider(); }
我们看到create方法中是通过区分操作系统来返回不同的Provider的。其中SunOs就是Solaris返回的是DevPollSelectorProvider,对于Linux,返回的Provder是EPollSelectorProvider,其余操作系统,返回的是PollSelectorProvider。
Reactor的运行步骤
介绍了上述三种 Reactor 线程模型,再结合它们各自的架构图,我们能大致总结出 Reactor 线程模型运行机制的四个步骤,分别为连接注册、事件轮询、事件分发、任务处理,如下图所示。
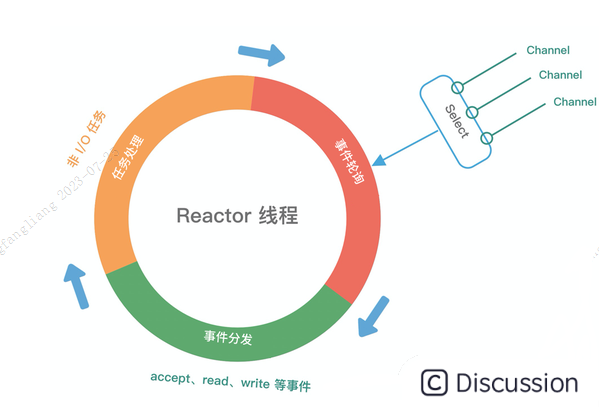
- 连接注册:Channel 建立后,将fd注册至Reactor线程中的Selector选择器。
- 事件轮询:轮询 Selector 选择器中已注册的所有 Channel 的 I/O 事件。
- 事件分发:为准备就绪的 I/O 事件分配相应的处理线程。
- 任务处理:Reactor 线程还负责任务队列中的非 I/O 任务,每个 Worker 线程从各自维护的任务队列中取出任务异步执行。
以上介绍了 Reactor 线程模型的演进过程和基本原理,Netty 也同样遵循 Reactor 线程模型的运行机制,下面我们来了解一下 Netty 是如何实现 Reactor 线程模型的。
事件轮询
EventLoop其实并不是 Netty 独有的,它是一种事件等待和处理的程序模型,可以解决多线程资源消耗高的问题。
例如 Node.js 就采用了 EventLoop 的运行机制,不仅占用资源低,而且能够支撑了大规模的流量访问。
下图展示了 EventLoop 通用的运行模式。
每当事件发生时,应用程序都会将产生的事件放入事件队列当中,然后 EventLoop 会轮询从队列中取出事件执行
或者将事件分发给相应的事件监听者执行。
Netty使用的是局部串行,全局并行的方式。
事件执行的方式通常分为立即执行、延后执行、定期执行几种。
NioEventLoop#run源码
EventLoop 可以理解为 Reactor 线程模型的事件处理引擎。
每个 EventLoop 线程都维护一个 Selector 选择器和任务队列 taskQueue。
它主要负责处理 I/O 事件、普通任务和定时任务。
Netty 中推荐使用 NioEventLoop 作为实现类,那么 Netty 是如何实现 NioEventLoop 的呢?
我们来看 NioEventLoop 最核心的 run() 方法源码,先了解 NioEventLoop 的实现结构。
java switch (selectStrategy.calculateStrategy (selectNowSupplier, hasTasks()))
首先,在 run()方法中,会通过选择策略(selectStrategy )来计算 switch 语句中的条件值。在计算的时候,会先通过 hasTasks() 方法来判断 taskQueue 和 tailQueue 中是否有任务等待被执行,如果有任务,则将调用 selectNow()方法从操作系统中来轮询网络 IO 事件;如果没有任务,则将调用 select(timeout)方法来轮询网络 IO 事件。这个应该好理解。如果有任务正在等待,那么应该使用无阻塞的 selectNow(),如果没有任务在等待,那么就可以使用带阻塞的 select 操作。
为什么要这样做呢?因为 Netty 中为了保证任务被及时执行,selectNow()方法是个非阻塞方法,如果操作系统中没有已经准备好的网络 IO 事件,那么就会立即返回,有已经准备好的网络 IO 事件,那么就会将这些网络 IO 事件查询出来并立马返回。而 select(timeout)方法也是从操作系统中轮询网络 IO 事件,但是它是一个阻塞方法,当 netty 中有任务等待被执行时,使用阻塞方法,显然会造成任务被执行不及时的问题。
如果selectStrategy计算出来的值为-1,那么就会执行到下面这一行代码。
java case SelectStrategy.SELECT: select(wakenUp.getAndSet(false)); // 轮询 I/O 事件 if (wakenUp.get()) { selector.wakeup(); }
这行代码首先会将 wakenUp 的值置为 false。wakenUp 字段表示的含义是是否需要唤醒 selector,在每次进行新的轮询时,都会将 wakenUp 设置为 false。然后调用 select()方法,从操作系统中轮询出来网络 IO 事件。
接着在 run()方法中会对 ioRatio 的值进行判断,ioRatio 的含义又是什么呢?在 Netty 中,NioEventLoop 每一次循环其实主要干两类事,一是处理网络 IO 事件,二是执行任务(包括普通任务和定时任务),但是处理这两类任务的所消耗的时间是不一样的。而且有些系统可能期望分配给处理网络 IO 事件的时间多一点,有些系统可能期望分配给处理任务的时间多一些,那么 netty 就需要提供一个变量来控制执行这两类事的所花的时间的占比,这个变量就是 ioRatio,翻译过来就是 IO 的时间占比。
默认情况下,ioRatio 的值为 50,即处理网络 IO 的时间和处理任务的时间各占一半。所以默认情况下,会进入到 else 语句块中,在 else 语句块中,先进行了网络 IO 的处理(processSelectedKeys()),然后进行任务的处理(runAllTasks(timeoutNanos))。
java final long ioStartTime = System.nanoTime(); try { processSelectedKeys(); // 处理 I/O 事件 } finally { final long ioTime = System.nanoTime() - ioStartTime; // 处理完 I/O 事件,再处理异步任务队列 // (100 - ioRatio) / ioRatio = 1 // 也就是处理io的时间和处理任务的时间耗时是一样的 runAllTasks(ioTime * (100 - ioRatio) / ioRatio); }
(31条消息) Netty源码分析系列之NioEventLoop的执行流程_天堂的博客-CSDN博客
回过神来,我们前面在 register 的时候提交了 register 任务给 NioEventLoop,这是 NioEventLoop 接收到的第一个任务,所以这里会实例化 Thread 并且启动,然后进入到 NioEventLoop 中的 run 方法。
当然了,实际情况也有可能是,Channel 实例被 register 到一个已经启动线程的 NioEventLoop 实例中。
```java protected void run() { for (;;) { try { try { switch (selectStrategy.calculateStrategy (selectNowSupplier, hasTasks())) { case SelectStrategy.CONTINUE: continue; case SelectStrategy.BUSY_WAIT: case SelectStrategy.SELECT: select(wakenUp.getAndSet(false)); // 轮询 I/O 事件 if (wakenUp.get()) { selector.wakeup(); } default: } } catch (IOException e) { rebuildSelector0(); handleLoopException(e); continue; }
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
try {
processSelectedKeys(); // 处理 I/O 事件
} finally {
runAllTasks(); // 处理所有任务
}
} else {
final long ioStartTime = System.nanoTime();
try {
processSelectedKeys(); // 处理 I/O 事件
} finally {
final long ioTime = System.nanoTime() - ioStartTime;
// 处理完 I/O 事件,再处理异步任务队列
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
}
} catch (Throwable t) {
handleLoopException(t);
}
try {
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
return;
}
}
} catch (Throwable t) {
handleLoopException(t);
}
}} ```
上述源码的结构比较清晰,NioEventLoop 每次循环的处理流程都包含事件轮询 select()、事件处理 processSelectedKeys()、任务处理 runAllTasks() 几个步骤,是典型的 Reactor 线程模型的运行机制。
而且 Netty 提供了一个参数 ioRatio,可以调整 I/O 事件处理和任务处理的时间比例。下面我们将着重从事件处理和任务处理两个核心部分出发,详细介绍 Netty EventLoop 的实现原理。
processSelectedKeys
processSelectedKeys主要是IO事件处理
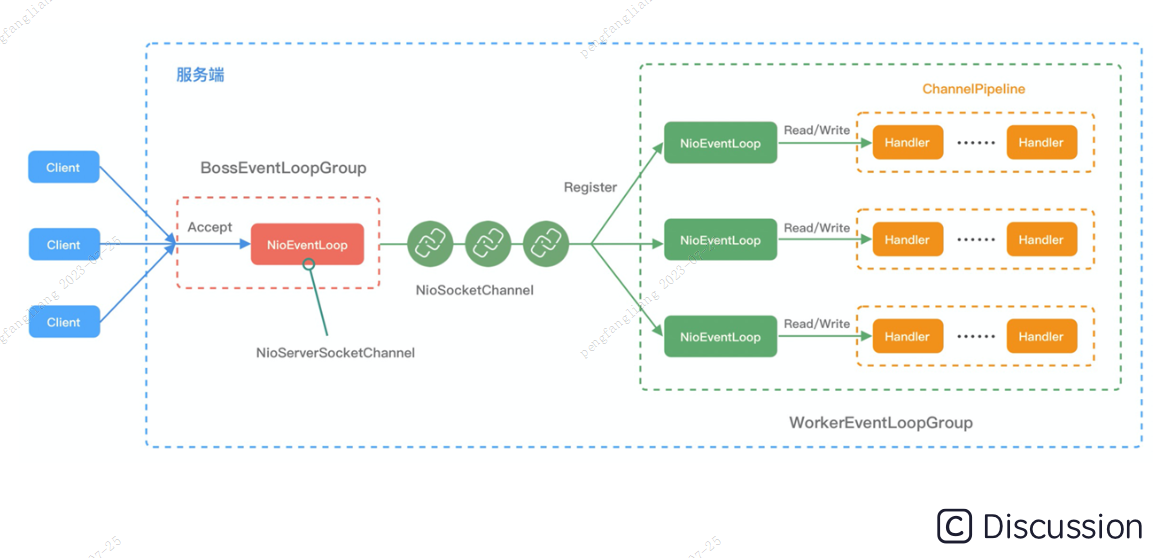
结合 Netty 的整体架构,看下 EventLoop 的事件流转图。
NioEventLoop 的事件处理机制采用的是无锁串行化的设计思路。
BossEventLoopGroup 和 WorkerEventLoopGroup 包含一个或者多个 NioEventLoop。BossEventLoopGroup 负责监听客户端的 Accept 事件,当事件触发时,将事件注册至 WorkerEventLoopGroup 中的一个 NioEventLoop 上。
每新建一个 Channel, 只选择一个 NioEventLoop 与其绑定。所以说 Channel 生命周期的所有事件处理都是线程独立的,不同的 NioEventLoop 线程之间不会发生任何交集。
NioEventLoop 完成io数据读取后,会调用绑定的 ChannelPipeline 进行事件传播,ChannelPipeline 也是线程安全的,数据会被传递到 ChannelPipeline 的第一个 ChannelHandler 中。数据处理完成后,将加工完成的数据再传递给下一个 ChannelHandler,整个过程是串行化执行,不会发生线程上下文切换的问题。
NioEventLoop 无锁串行化的设计不仅使系统吞吐量达到最大化,而且降低了用户开发业务逻辑的难度,不需要花太多精力关心线程安全问题。
虽然单线程执行避免了线程切换,但是它的缺陷就是不能执行时间过长的 I/O 操作,一旦某个 I/O 事件发生阻塞,那么后续的所有 I/O 事件都无法执行,甚至造成事件积压。
在使用 Netty 进行程序开发时,我们一定要对 ChannelHandler 的实现逻辑有充分的风险意识。
JDK中Epoll空轮询Bug
NioEventLoop 线程的可靠性至关重要,一旦 NioEventLoop 发生阻塞或者陷入空轮询,就会导致整个系统不可用。
在 JDK 中, Epoll 的实现是存在漏洞的,即使 Selector 轮询的事件列表为空,NIO 线程一样可以被唤醒,导致 CPU 100% 占用。这就是臭名昭著的 JDK epoll 空轮询的 Bug。
Netty 作为一个高性能、高可靠的网络框架,需要保证 I/O 线程的安全性。
那么它是如何解决 JDK epoll空轮询的Bug 呢?
实际上 Netty 并没有从根源上解决该问题,而是巧妙地规避了这个问题。
我们抛开其他细枝末节,直接定位到事件轮询 select() 方法中的最后一部分代码,一起看下 Netty 是如何解决 epoll 空轮询的 Bug。
Netty中的解决思路:
对Selector()方法中的阻塞定时 select(timeMIllinois)操作的 次数进行统计,每完成一次select操作进行一次计数,若在循环周期内 发生N次空轮询,如果N值大于BUG阈值(默认为512),就进行空轮询BUG处理。 重建Selector,判断是否是其他线程发起的重建请求,若不是则将原SocketChannel从旧的Selector上去除注册,重新注册到新的 Selector上,并将原来的Selector关闭。 https://blog.csdn.net/qq_41884976/article/details/91913820
java select方法分三个部分: //第一部分:超时处理逻辑 //第二部分:定时阻塞select(timeMillins) //第三部分: 解决空轮询 BUG long time = System.nanoTime(); //当前时间 - 循环开始时间 >= 定时select的时间timeoutMillis,说明已经执行过一次阻塞select() if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) { //说明发生过一次阻塞式轮询 重置次数 selectCnt = 1; } else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 && selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) { // 如果空轮询的次数大于空轮询次数阈值 SELECTOR_AUTO_REBUILD_THRESHOLD(512) //1.首先创建一个新的Selecor //2.将旧的Selector上面的键及其一系列的信息放到新的selector上面。 selector = selectRebuildSelector(selectCnt); selectCnt = 1; break; }
Netty 提供了一种检测机制判断线程是否可能陷入空轮询,具体的实现方式如下:
- 每次执行 Select 操作之前记录当前时间 currentTimeNanos。
- time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos,如果事件轮询的持续时间大于等于 timeoutMillis,那么说明是正常的,否则表明阻塞时间并未达到预期,可能触发了空轮询的 Bug。
- Netty 引入了计数变量 selectCnt。在正常情况下,selectCnt 会重置,否则会对 selectCnt 自增计数。当 selectCnt 达到 SELECTORAUTOREBUILD_THRESHOLD(默认512) 阈值时,会触发重建 Selector 对象。
Netty 采用这种方法巧妙地规避了 JDK Bug。异常的 Selector 中所有的 SelectionKey 会重新注册到新建的 Selector 上,重建完成之后异常的 Selector 就可以废弃了。
runAllTasks:任务处理
NioEventLoop 不仅负责处理 I/O 事件,还要兼顾执行任务队列中的任务。
任务队列遵循 FIFO 规则,可以保证任务执行的公平性。NioEventLoop 处理的任务类型基本可以分为三类。
普通任务
通过 NioEventLoop 的 execute() 方法向任务队列 taskQueue 中添加任务。例如 Netty 在写数据时会封装 WriteAndFlushTask 提交给 taskQueue。
taskQueue 的实现类是多生产者单消费者队列 MpscChunkedArrayQueue,在多线程并发添加任务时,可以保证线程安全。
普通任务代码示例
```java /* 说明 1. 我们自定义一个Handler 需要继续netty 规定好的某个HandlerAdapter(规范) 2. 这时我们自定义一个Handler , 才能称为一个handler */ public class NettyServerHandler extends ChannelInboundHandlerAdapter {
//读取数据实际(这里我们可以读取客户端发送的消息)
/*
1. ChannelHandlerContext ctx:上下文对象, 含有 管道pipeline , 通道channel, 地址
2. Object msg: 就是客户端发送的数据 默认Object
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//比如这里我们有一个非常耗时长的业务-> 异步执行 -> 提交到该channel 对应的NIOEventLoop 的 taskQueue中
//解决方案1 用户程序自定义的普通任务
//会有1个判断
ctx.channel().eventLoop().execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(5 * 1000);
ctx.writeAndFlush(Unpooled.copiedBuffer("hello, 客户端~(>^ω^<)喵2", CharsetUtil.UTF_8));
System.out.println("channel code=" + ctx.channel().hashCode());
} catch (Exception ex) {
System.out.println("发生异常" + ex.getMessage());
}
}
});
}
//数据读取完毕
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
//writeAndFlush 是 write + flush
//将数据写入到缓存,并刷新
//一般讲,我们对这个发送的数据进行编码
ctx.writeAndFlush(Unpooled.copiedBuffer("hello, 客户端~(>^ω^<)喵1", CharsetUtil.UTF_8));
}
//处理异常, 一般是需要关闭通道
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.close();
}}
参考链接:https://blog.csdn.net/cold_play/article/details/104343549 ```
定时任务
通过调用 NioEventLoop 的 schedule() 方法向定时任务队列 scheduledTaskQueue 添加一个定时任务,用于周期性执行该任务。例如,心跳消息发送等。定时任务队列 scheduledTaskQueue 采用优先队列 PriorityQueue 实现。
```java /* 说明 1. 我们自定义一个Handler 需要继续netty 规定好的某个HandlerAdapter(规范) 2. 这时我们自定义一个Handler , 才能称为一个handler */ public class NettyServerHandler extends ChannelInboundHandlerAdapter {
//读取数据实际(这里我们可以读取客户端发送的消息)
/*
1. ChannelHandlerContext ctx:上下文对象, 含有 管道pipeline , 通道channel, 地址
2. Object msg: 就是客户端发送的数据 默认Object
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//比如这里我们有一个非常耗时长的业务-> 异步执行 -> 提交该channel 对应的
//NIOEventLoop 的 taskQueue中,
//解决方案2 : 用户自定义定时任务 -》 该任务是提交到 scheduleTaskQueue中
ctx.channel().eventLoop().schedule(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(5 * 1000);
ctx.writeAndFlush(Unpooled.copiedBuffer("hello, 客户端~(>^ω^<)喵4", CharsetUtil.UTF_8));
System.out.println("channel code=" + ctx.channel().hashCode());
} catch (Exception ex) {
System.out.println("发生异常" + ex.getMessage());
}
}
}, 5, TimeUnit.SECONDS);
}
//数据读取完毕
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
//writeAndFlush 是 write + flush
//将数据写入到缓存,并刷新
//一般讲,我们对这个发送的数据进行编码
ctx.writeAndFlush(Unpooled.copiedBuffer("hello, 客户端~(>^ω^<)喵1", CharsetUtil.UTF_8));
}
//处理异常, 一般是需要关闭通道
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.close();
}} 参考链接:https://blog.csdn.net/cold_play/article/details/104343549 ```
尾部队列
tailTasks 相比于普通任务队列优先级较低,在每次执行完 taskQueue 中任务后会去获取尾部队列中任务执行。尾部任务并不常用,主要用于做一些收尾工作,例如统计事件循环的执行时间、监控信息上报等。
runAllTasks源码分析
下面结合任务处理 runAllTasks 的源码结构,分析下 NioEventLoop 处理任务的逻辑,源码实现如下:
java protected boolean runAllTasks(long timeoutNanos) { // 1. 合并定时任务到普通任务队列 fetchFromScheduledTaskQueue(); // 2. 从普通任务队列中取出任务 Runnable task = pollTask(); if (task == null) { afterRunningAllTasks(); return false; } // 3. 计算任务处理的超时时间 final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos; long runTasks = 0; long lastExecutionTime; for (;;) { // 4. 安全执行任务 safeExecute(task); runTasks ++; // 5. 每执行 64 个任务检查一下是否超时 if ((runTasks & 0x3F) == 0) { lastExecutionTime = ScheduledFutureTask.nanoTime(); if (lastExecutionTime >= deadline) { break; } } task = pollTask(); if (task == null) { lastExecutionTime = ScheduledFutureTask.nanoTime(); break; } } // 6. 收尾工作 afterRunningAllTasks(); this.lastExecutionTime = lastExecutionTime; return true; }
我在代码中以注释的方式标注了具体的实现步骤,可以分为 6 个步骤。
java 1. fetchFromScheduledTaskQueue 函数:将定时任务从 scheduledTaskQueue 中取出,聚合放入普通任务队列 taskQueue 中,只有定时任务的截止时间小于当前时间才可以被合并。 2. 从普通任务队列 taskQueue 中取出任务。 3. 计算任务执行的最大超时时间。 4. safeExecute 函数:安全执行任务,实际直接调用的 Runnable 的 run() 方法。 5. 每执行 64 个任务进行超时时间的检查,如果执行时间大于最大超时时间,则立即停止执行任务,避免影响下一轮的 I/O 事件的处理。 6. 最后获取尾部队列中的任务执行。
EventLoop 最佳实践
在日常开发中用好 EventLoop 至关重要,这里结合实际工作中的经验给出一些 EventLoop 的最佳实践方案。
- 网络连接建立过程中三次握手、安全认证的过程会消耗不少时间。这里建议采用 Boss 和 Worker 两个 EventLoopGroup,有助于分担 Reactor 线程的压力。
- 由于 Reactor 线程模式适合处理耗时短的任务场景,对于耗时较长的 ChannelHandler 可以考虑维护一个业务线程池,将编解码后的数据封装成 Task 进行异步处理,避免 ChannelHandler 阻塞而造成 EventLoop 不可用。
- 如果业务逻辑执行时间较短,建议直接在 ChannelHandler 中执行。例如编解码操作,这样可以避免过度设计而造成架构的复杂性。
- 不宜设计过多的 ChannelHandler。对于系统性能和可维护性都会存在问题,在设计业务架构的时候,需要明确业务分层和 Netty 分层之间的界限。不要一味地将业务逻辑都添加到 ChannelHandler 中。