来自加利福尼亚大学的3D-LLM项目团队提到:大型语言模型 (LLM) 和视觉语言模型 (VLM) 已被证明在多项任务上表现出色,例如常识推理。尽管这些模型非常强大,但它们并不以 3D 物理世界为基础,而 3D 物理世界涉及更丰富的概念,例如空间关系、可供性、物理、布局等。
在这项工作中,可以将 3D 世界注入大型语言模型中,并引入全新的 3D-LLM 系列。
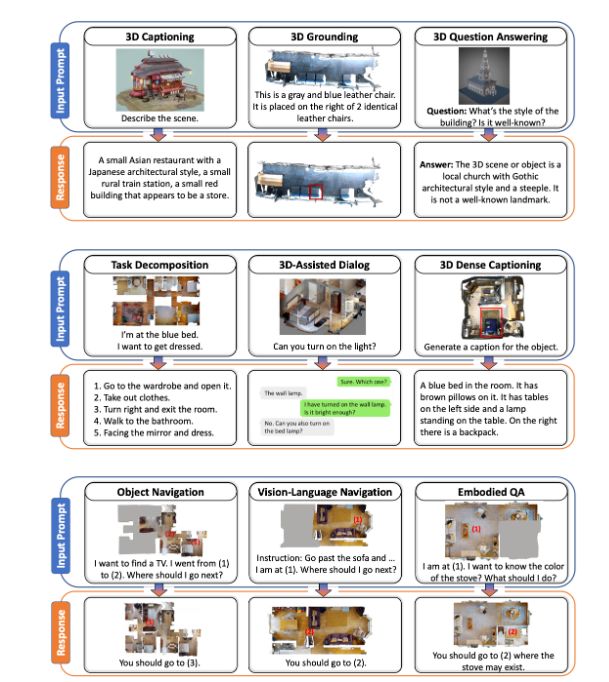
具体来说,3D-LLM 可以将 3D 点云及其特征作为输入,并执行各种 3D 相关任务,包括字幕、密集字幕、3D 问答、任务分解、3D 基础、3D 辅助对话、导航等。
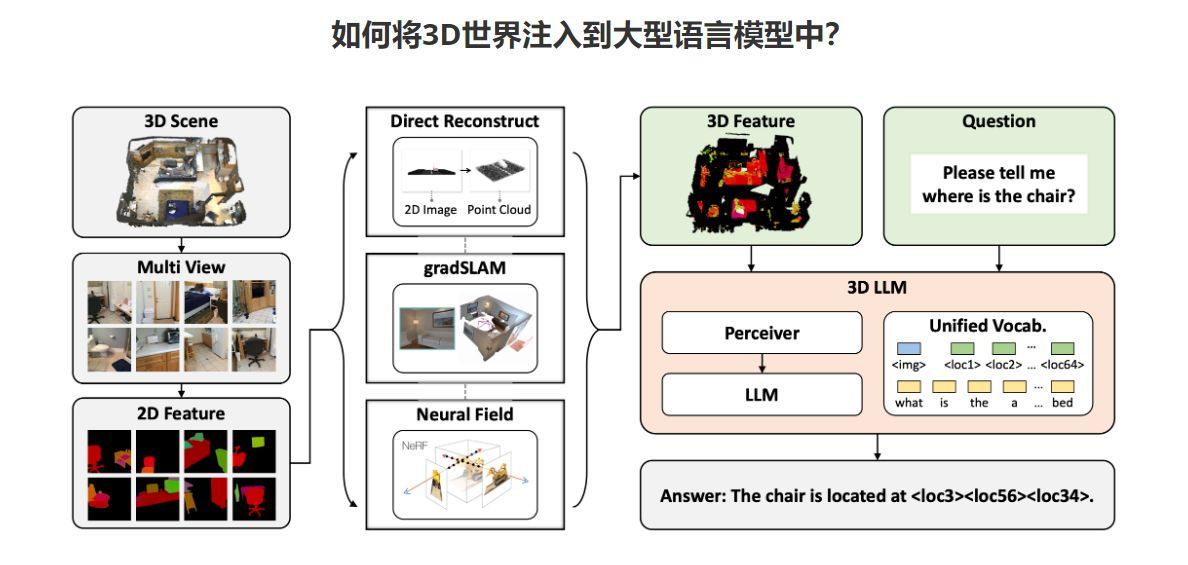
项目中提到:”使用我们设计的三种类型的提示机制,我们能够收集超过 30 万个涵盖这些任务的 3D 语言数据。为了有效地训练 3D-LLM,我们首先利用 3D 特征提取器从渲染的多视图图像中获取 3D 特征。然后,我们使用 2D VLM 作为骨干来训练 3D-LLM。通过引入 3D 定位机制,3D-LLM 可以更好地捕获 3D 空间信息。
ScanQA 上的实验表明,我们的模型大幅优于最先进的基线(例如,BLEU-1 分数超过最先进的分数 9%)。此外,对我们保留的 3D 字幕、任务组合和 3D 辅助对话数据集进行的实验表明,我们的模型优于 2D VLM。
定性示例还表明,我们的模型可以执行超出现有 LLM 和 VLM 范围的更多任务。项目页面: : 我们使用 2D VLM 作为骨干来训练 3D-LLM。通过引入 3D 定位机制,3D-LLM 可以更好地捕获 3D 空间信息。”
以下是3D-LLM的一些应用场景