1、 简介
跳跃表(SkipList)是一种能高效实现插入、删除、查找的内存数据结构,这些操作的期望复杂度都是O(logN)。与红黑树以及其他的二分查找树相比,跳跃表的优势在于实现简单,而且在并发场景下加锁粒度更小,从而可以实现更高的并发性。正因为这些优点,跳跃表广泛使用于KV数据库中,诸如Redis、LevelDB、HBase都把跳跃表作为一种维护有序数据集合的基础数据结构。
众所周知,链表这种数据结构的查询复杂度为O(N),这里N是链表中元素的个数。在已经找到要删除元素的情况下,再执行链表的删除操作其实非常高效,只需把待删除元素前一个元素的next指针指向待删除元素的后一个元素即可,复杂度为O(1),但问题是,链表的查询复杂度太高,因为链表在查询的时候,需要逐个元素地查找。如果链表在查找的时候,能够避免依次查找元素,那么查找复杂度将降低。而跳跃表就是利用这一思想,在链表之上额外存储了一些节点的索引信息,达到避免依次查找元素的目的,从而将查询复杂度优化为O(logN)。将查询复杂度优化之后,自然也优化了插入和删除的复杂度。
1.定义
如图所示,跳跃表的定义如下:
·跳跃表由多条分层的链表组成(设为S0,S1,S2,…,Sn),例如图中有6条链表。
·每条链表中的元素都是有序的。
·每条链表都有两个元素:+∞(正无穷大)和-∞(负无穷大),分别表示链表的头部和尾部。
·从上到下,上层链表元素集合是下层链表元素集合的子集,即S1是S0的子集,S2是S1的子集。
·跳跃表的高度定义为水平链表的层数。
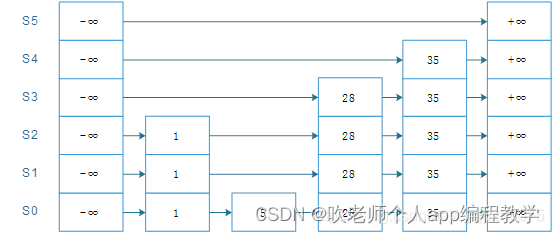
在跳跃表中查找一个指定元素的流程比较简单。上图以左上角元素(设为currentNode)作为起点查询值5:
·如果发现currentNode后继节点的值小于等于待查询值,则沿着这条链表向后查询,否则,切换到当前节点的下一层链表。
·继续查询,直到找到待查询值为止(或者currentNode为空节点)为止。
————————————————
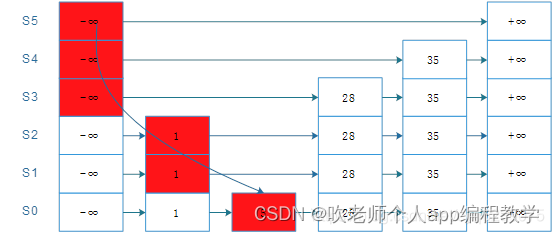
2.插入
跳跃表的插入算法要复杂一点。如下图所示。首先,需要按照上述查找流程找到待插入元素的前驱和后继;然后,按照如下随机算法生成一个高度值:
// p是一个(0,1)之间的常数,一般取p=1/4或者1/2
public void randomHeight(double p){
int height = 0 ;
while(random.nextDouble() < p) height ++ ;
return height + 1;
}
最后,将待插入节点按照高度值生成一个垂直节点(这个节点的层数正好等于高度值),之后插入到跳跃表的多条链表中去。假设height=randomHeight(p),这里需要分两种情况讨论:
·如果height大于跳跃表的高度,那么跳跃表的高度被提升为height,同时需要更新头部节点和尾部节点的指针指向。
·如果height小于等于跳跃表的高度,那么需要更新待插入元素前驱和后继的指针指向。
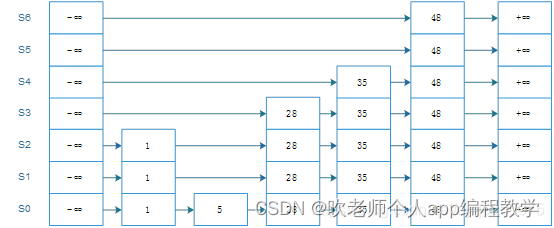
4.删除
删除操作和插入操作有点类似,不再细说。
5.复杂度分析
这里,我们一起来评估跳跃表的时间和空间复杂度。
性质1 一个节点落在第k层的概率为P^(k-1)。
这条性质比较简单,如果randomHeight(p)函数返回的高度为k,那么必须要求前面(k-1)个随机数都小于p,(k-1)个概率为p的独立事件概率相乘,因此高度为k的概率为P^(k-1)。性质2 一个最底层链表有n个元素的跳跃表,总共元素个数为:
其中k为跳跃表的高度。
由于性质1,一个元素落在第k层概率为p(k-1),则第k层插入的元素个数为n×p(k-1),所有k相加得到上述公式。当p <= 1/2时,上述公式小于O(2n),所以空间复杂度为O(n)。
性质3 跳跃表的高度为O(logn)。
考虑第层,落在这层的期望节点数为
当n较大时,该层节点数为0,所以层数在O(logn)这个数据级上。
性质4 跳跃表的查询时间复杂度为O(logN)。
查询时间复杂度关键取决于从最左上角到达最底层走过的横向步数和纵向步数之和。我们反过来考虑这个过程,也就是从最底层达到最左上角s走过的期望步数(包括横向步数)。对第k层第j列节点来说,它只可能从以下两种情况跳过来:
·第k-1层第j列节点往上走,跳到第k层第j列节点。根据randomHeight(p)函数定义,往上走的概率为p。
·第k层第j+1列节点往左走,跳到第k层第j列节点。这种情况,第k层第j+1列节点已经是垂直节点的最高点,也就是说,这个节点已经不能往上走,只能往左走。根据randomHeight(p)函数定义,往左走的概率为(1-p)。
设Ck为往上跳k层的期望步数(包括纵向步数和横向步数),那么有:
由于高度k为O(logN)级别,所以,查询走过的期望步数也为O(logN)。
性质5 跳跃表的插入/删除时间复杂度为O(logN)。
由插入/删除的实现可以看出,插入/删除的时间复杂度和查询时间复杂度相等,故性质5成立。
因此,跳跃表的查找、删除、插入的复杂度都是O(logN)。