笔者曾经写过一篇文章,介绍 ShardingSphere 在具体代码细节上的优化案例,但文章中没有介绍如何发现代码优化点。本文将结合之前笔者在 ShardingSphere 相关性能问题排查、优化经验,简要地介绍 ShardingSphere 性能问题排查、优化应如何入手。由于 ShardingSphere 本身也是 Java 应用,本文的经验同样也适用于与 ShardingSphere 无关的 Java 应用。
文章目录
确实需要进行性能优化吗?
Premature optimization is the root of all evil.
– Donald Knuth
进行性能优化之前,可以先想想为什么要优化?
笔者曾经认为性能工程可分为两种情况:
- 应用性能出现异常,与预期运行状况有偏差,需要确认、排查、解决性能问题,使性能达到预期状况;
- 应用工作状态良好,本身没有明显的性能问题,吞吐量已经达到瓶颈,在应用以外的条件不改变的前提下,进一步优化以提升峰值吞吐量。
后来,在多次参与性能相关工作后,发现性能相关的情况其实比较复杂:
- 主观上或通过简单的测试认为性能存在问题,无意中做了负优化却没有发现;
- 性能测试方法存在问题,或问题在不同环境的影响存在差异,导致测不出性能问题;
- 有些应用在表现上看似没有明显问题,但实际上问题存在已久,以至于让人以为应用的表现本该如此;
- 没能关注到性能问题真正所在。例如,系统性能问题出在应用本身,却在数据库层面做了大量工作;
- 性能测试方法与实际场景偏差较大,即使测试指标表现良好,但实际性能表现与测试结果偏差较大;也可能性能测试结果不如预期,但实际上系统运行状况良好且满足业务需求;
- ……
以 ShardingSphere 为例,就曾经出现过:
- TableMetaData 自 4.0.0-RC2 版本使用了 Collections.synchronizedMap 方法,直到 5.0.0 版本才发现其对并发性能的影响并得以解决;
- 通过 ConcurrentHashMap 缓存对象以减少创建的开销,却无意间踩到了 Java 8 下 computeIfAbsent 相关并发性能问题,但可能没有合适的并发性能测试,以至于当时未能发现问题;
- ShardingSphere-Proxy 主流程代码中引入了 synchronized 方法,在某 x86 环境下使用简单场景测试工具没有发现明显的性能下降,在某 aarch64 环境下高并发模拟业务场景测试发现性能下降 40%;
- ……
笔者曾经接触过一个系统,在运行期间向 stdout 和文件同时打着大量日志,完整输出每个 HTTP 请求详情,但是实际业务运转正常,非功能性方面用户体验良好,系统成本上也没有明显的异议。这种情况下,投入成本给系统做性能优化,好像并没有太大的必要。
平时也有同学咨询现有的 ShardingSphere 性能测试结果。在不同的场景、环境、方法下测试,ShardingSphere 的性能表现差异可能会很大,参考意义并不大。
性能本身存在较大的主观性,脱离实际场景是无法讨论的。 充分评估业务的非功能性需求、收集真实用户的反馈信息、考虑投入的成本与可能的收益、进行客观准确的性能测试,最后再判断当前是否存在性能问题,或需要对性能进一步优化。
如何选择观察工具?
选择合适的工具观察系统、应用性能,在性能优化的过程中会起到很大的作用。
大多数生产、压测等环境一般都部署了可观察性平台,用于监测系统的各项指标、跟踪全链路等,在必要时进行告警行为。这类可观察性具备规模大、常态化、通用性高等特点,同样,这些特点也注定了可观察性工具在指标的粒度、实时性、针对性等方面存在一定的局限。
直接登录到被优化对象所在的环境,通过各种命令行工具直接查看系统状况,可能会比操作图形化的可观察性平台更繁琐,但这种方式更灵活、更直接,能够观察到更多的细节。
另外,对于特定领域,可能会有更有针对性的观察工具。例如对 JVM 进程进行采集,Linux 下有 perf 工具能够采集系统事件、堆栈等信息,采集的信息可生成火焰图,但 perf 等工具在 Java 代码堆栈的采集有一定局限性;使用 async-profiler 等工具能够采集到堆内存分配、Object Monitor 等信息,JFR 格式的采集结果能够直接导入 Java 性能分析工具,分析 Java 应用性能更方便。
举个例子,以下是一台多核服务器在应用性能测试期间,在监控面板中,观察到的 CPU 使用率可能长下面这个样子:

直接登录到服务器环境,使用 htop 观察到的 CPU 使用率却可能是下面这个样子(上下图没有直接关系):

虽然在可观察性界面中也能够配置具体到每个 CPU 核心的图表,但大部分的面板默认只展示了 CPU 的整体使用率,尤其是在 CPU 核心数较多的环境下,在面板中展示过于详细的信息可能会让界面变得复杂。
以上这种情况,很容易让调优人员忽略了某些 CPU 核心上的异常表现,增加了性能问题的定位难度。
先尽可能排除应用之外的因素
性能问题可能很简单,可能很复杂,也可能让人出乎意料。
例如在上一节案例中展示的诡异的 CPU 使用率,与网卡队列、软中断有关,影响了网络收发性能,导致应用程序无法充分利用整机 CPU 资源。
曾经也遇到过有用户在 aarch64 环境部署 ShardingSphere-Proxy 后,发现 Proxy 性能与预期结果存在数量级上的差异,通过 jstat -gc 发现 JVM 频繁 STW (Stop-The-World),更换了一个 JVM 后问题解决。
影响性能的因素难以完全枚举,在进一步关注应用本身的性能表现之前,应该先检查性能是否受其他因素的影响。
Java 应用相关性能问题排查
如果已经尽可能排除应用之外影响性能的因素,下一步就是对应用本身的情况进行观察。
Apache ShardingSphere 提供的 ShardingSphere-Proxy 镜像使用 JDK 而不是尺寸更小 JRE 作为基础镜像,理由之一是 JDK 包含了一些观察 JVM 进程的工具,遇到问题时,这些观察工具能提供不少帮助。

各类工具都有文档说明,但在脱离场景的情况下,单独看文档可能不容易理解。本文将结合与 ShardingSphere 相关案例排查问题的思路,简要介绍相关工具。
JDK 自带工具
jstack
jstack 能让开发者对 JVM 的线程状态有一个初步的了解。笔者曾多次遇到过 Java 应用无法充分使用 CPU 的案例,有些案例问题过于明显,以至于仅通过 jstack 就能发现问题。
案例:
问题现象:对 ShardingSphere-Proxy 进行性能测试,通过 top 命令发现:压测程序、Proxy 进程、数据库 CPU 使用率均比较低,整机 CPU 使用率不超过 20%。

以下为 jstack 输出结果过滤、节选,可以观察到大量 ShardingSphere Command 线程处于 WAITING 状态,且代码路径包含 SQLLogger、Logback。

"ShardingSphere-Command-1560" #1893 daemon prio=5 os_prio=0 tid=0x00007f482c011800 nid=0x4dd64 waiting on condition [0x00007f460a072000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000005c0023bc0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
...
at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285)
at ch.qos.logback.core.OutputStreamAppender.writeBytes(OutputStreamAppender.java:197)
...
at ch.qos.logback.classic.Logger.info(Logger.java:591)
at org.apache.shardingsphere.infra.executor.sql.log.SQLLogger.log(SQLLogger.java:74)
at org.apache.shardingsphere.infra.executor.sql.log.SQLLogger.logSQL(SQLLogger.java:47)
at org.apache.shardingsphere.infra.context.kernel.KernelProcessor.logSQL(KernelProcessor.java:68)
分析结论:性能测试期间,ShardingSphere 的 SQL 日志为启用状态,大量线程等待获取锁打印日志,导致并发性能受限。
与以上案例中使用锁影响并发性能类似的情况包括但不限于:
- 高频并发调用同一对象的 synchronized 方法或代码块;
- 高频并发使用了 Properties (HashTable)、Collections.synchronized* 修饰方法等数据结构;
- Java 8 下高频并发对同一个 key 的 ConcurrentHashMap.computeIfAbsent (JDK-8161372);
- 第三方依赖中存在以上提到的内容(如分布式事务管理器 Atomikos 使用了较多 synchronized 方法或代码块)。
除了锁、synchronized 相关代码导致并发性能受限,jstack 还能够发现一些其他问题,如因数据库连接池内连接不够导致大量调用方排队、线程意外进入死循环造成 CPU 100% 等。
当然,jstack 获取的是瞬时状态,在线程数量特别多或性能影响不是特别明显的情况,通过 jstack 可能不容易发现问题,可考虑使用专门的采样工具分析调用栈与线程阻塞(例如本文后面会简要介绍的 async-profiler)。
jstat
jstat (Java Virtual Machine Statistics Monitoring Tool) 是查看 JVM 统计信息的工具,能够查看类加载、JIT、GC 等统计信息。GC 是 JVM 性能调优过程中常关注的点,通过 jstat 工具能够输出 JVM 堆内存使用情况、回收次数与耗时等信息。
案例:
问题现象:对 ShardingSphere-Proxy 进行性能测试,在性能测试期间,Proxy 实时 QPS 并不理想。通过 MySQL 客户端连接 ShardingSphere-Proxy,发现客户端需要等待好几秒才能开始操作。
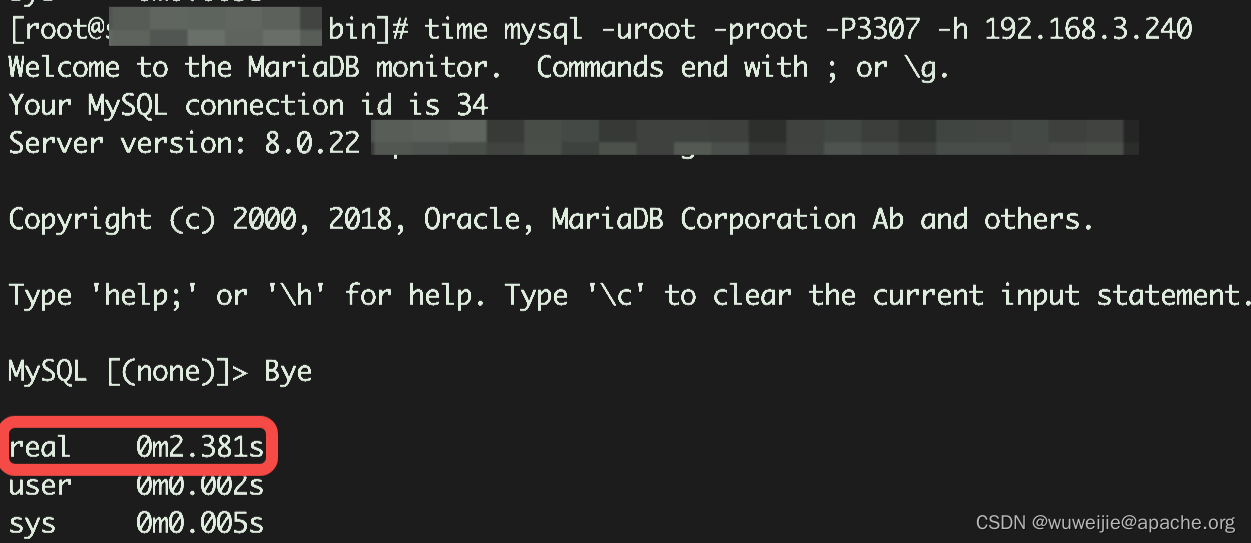
从客户端现象来看,网络延时、线程阻塞、JVM 停顿等情况都有可能造成客户端连接等待时间较长。
通过 jstat -gc 可以查看 JVM 的 GC 统计信息,一下示例是每 3 秒输出 PID 为 30833 的 GC 情况。

对于 GC 时间,主要关注最右侧 5 列:
- YGC:Young GC 次数;
- YGCT:Yound GC 总时间(秒);
- FGC:Full GC 次数;
- FGCT:Full GC 总时间(秒);
- GCT:GC 总时间(秒)。
从上图最右侧的 GCT 列能够发现,进程在 GC 上消耗了大量时间,这是导致客户端连接 Proxy 阻塞的直接原因之一(本案例实际上还存在 Netty 线程处理队列积压等问题,但本节目的为简要介绍工具,其他问题暂不展开讨论)。
jmap
那 JVM 为什么会频繁发生 GC?堆内存里装的又是什么?
jmap (Memory Map) 是查看堆内存中对象的工具,能够输出统计信息、导出内存快照等。当发现 JVM 进程 GC 状况异常时,可以通过 jmap 进一步分析堆内存。
案例:
本案例来源于 ShardingSphere 社区反馈:
MySQL’s prepStmtCacheSize default value of 200000 is not reasonable, which is easy to cause OOM
https://github.com/apache/shardingsphere/issues/18471
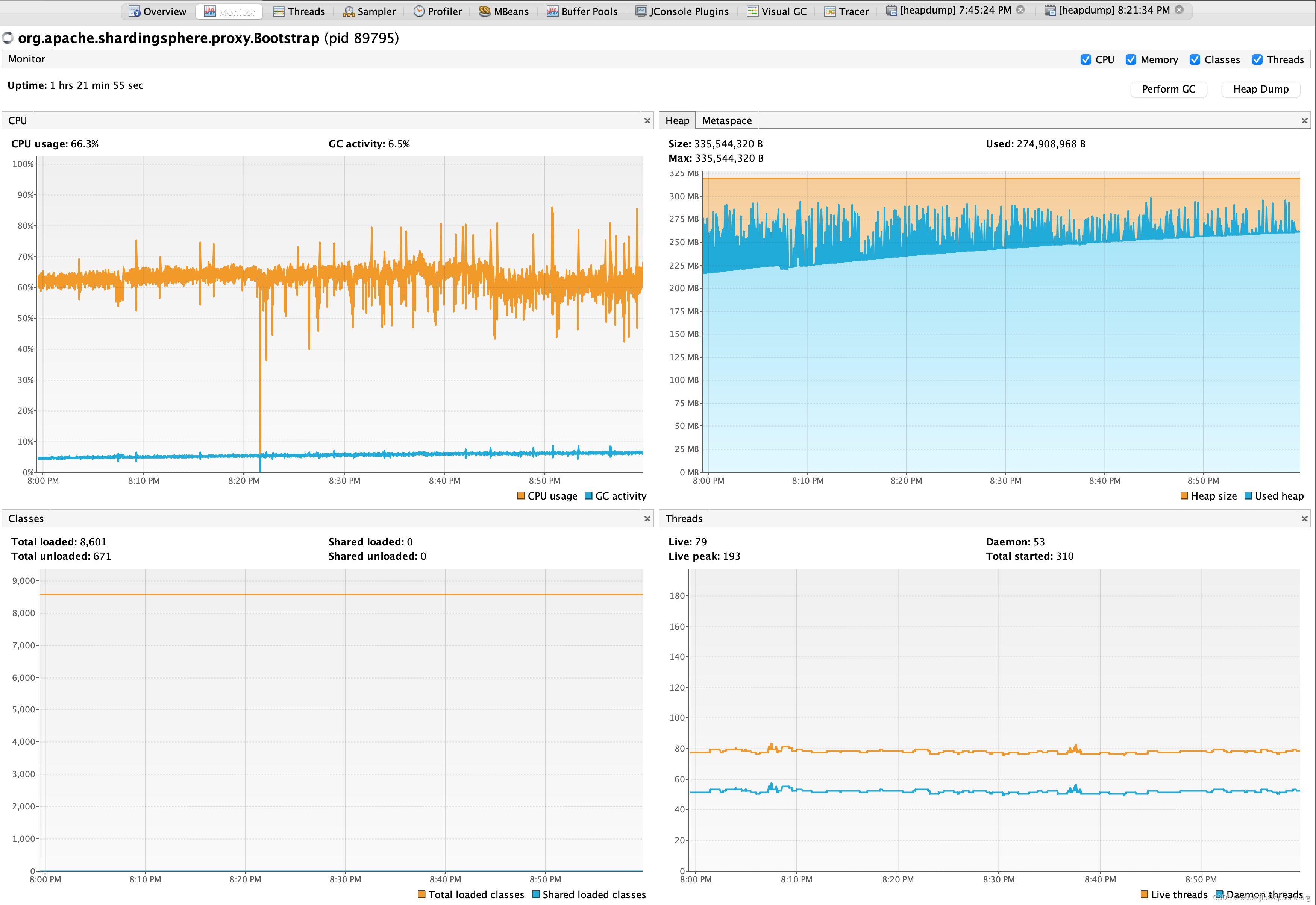
使用 sysbench oltp_point_select 对 ShardingSphere-Proxy 进行长时间性能测试,短时间内看 Proxy QPS 无明显异常,但对比启动时与测试持续一小时后的实时指标,发现 QPS 下滑严重。
以下为 VisualVM 面板,从 JVM 基本情况来看,堆内存使用率看似存在无法释放的情况(这种情况通过 jstat -gc 也能够发现异常状况,累计 GCT 时间应该会比较长)。但是在简单点查场景中,理论上不存在生命周期较长的实例。
通过 jmap -histo:live 能够输出每个类的实例数与占用空间,输出示例如下:
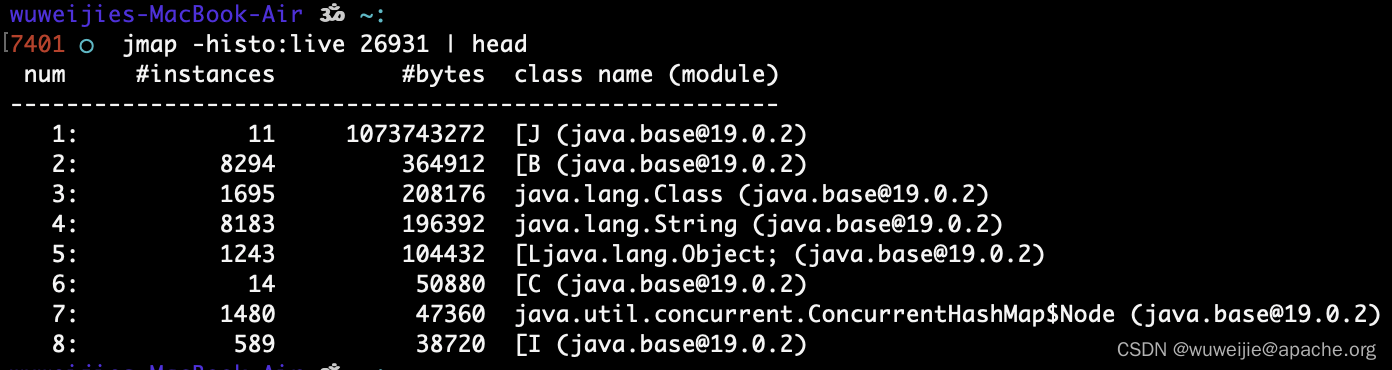
不过在很多时候,占用大量空间的对象都是一些基本类型数组、JDK 数据结构的对象,仅凭每个对象自身占用空间,难以定位内存占用的根本原因。例如上图的 [J (即 long[] 实例)占用了约 1 GB 内存,但除此之外看不出别的信息。
如果环境方便传输大文件,优先考虑导出内存快照文件(Heap Dump),传输到本地分析或留存。
导出的内存快照可以通过 IntelliJ IDEA、VisualVM 等工具查看,通过 IDEA 还能直接定位到代码上,查看更方便。
以下是通过 IDEA 打开的内存快照,左侧 3 列信息对应 jmap -histo 的输出信息,第 4 列 Retained 是通过内存快照分析工具计算得出的。
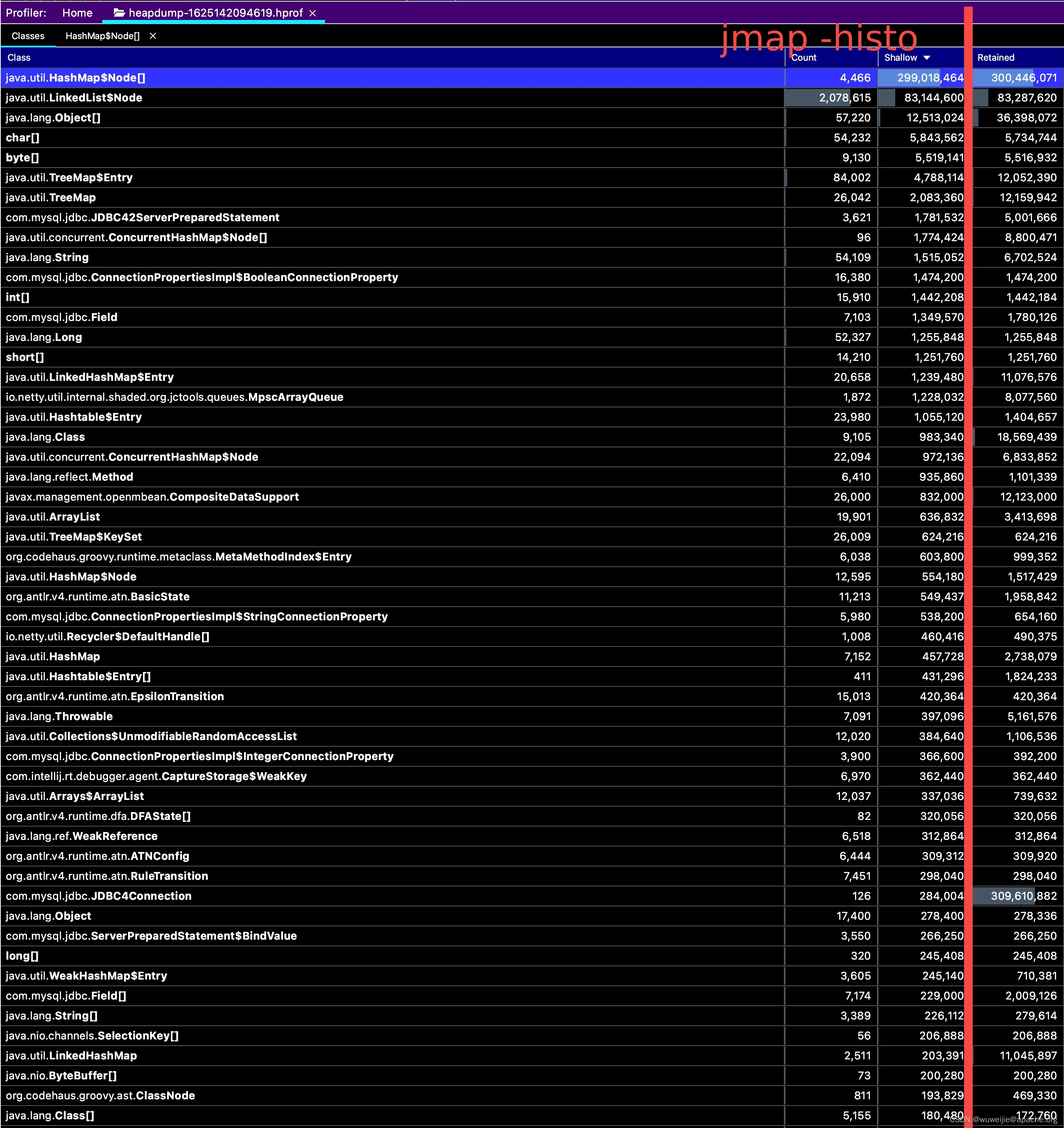
如何理解 Shallow 与 Retained?
- Shallow 与
jmap -histo:live中看到的 bytes 列对应,表示实例本身占用的空间; - Retained 表示实例本身及其引用的实例所占用的空间,需要计算得出。
在本案例中,GC 频繁执行的直接原因是 HashMap 本身的存储结构占用空间 (Shallow) 较大,但单凭这一点无法判断根本原因。
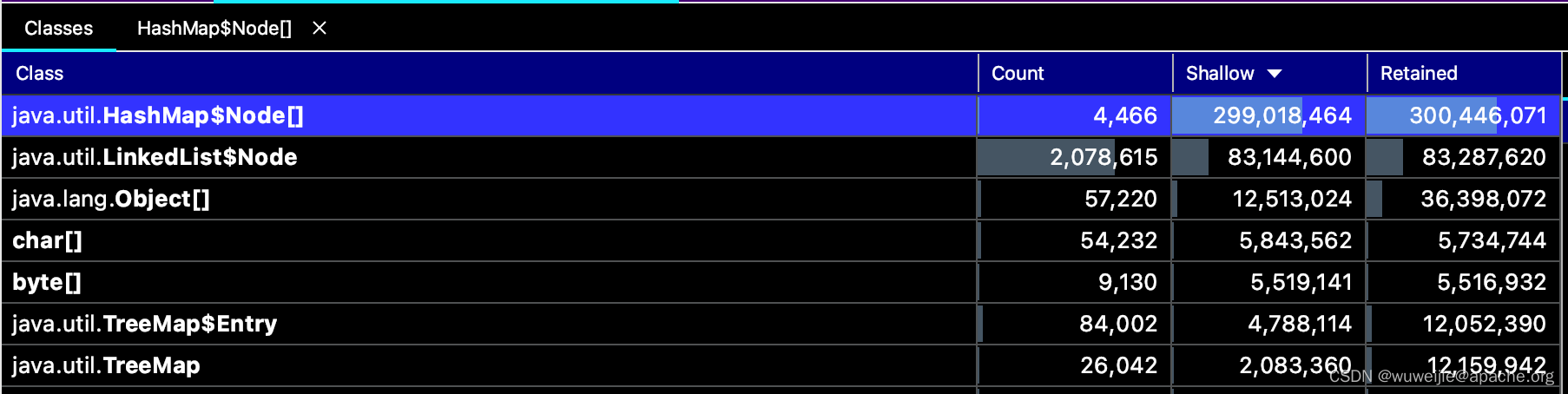
如果按照 Retained 降序排序,能够发现:MySQL 连接 JDBC4Connection 本身占用的空间 (Shallow) 并不大,不足 300 KB;但 JDBC4Connection 引用的实例占用空间 (Retained) 近 300 MB。

进一步分析发现,占用内存的主要是 JDBC4Connection 内部的服务端 Prepared Statement 缓存。

最终得出结论,本案例的内存占用问题是由于 MySQL JDBC 参数 prepStmtCacheSize 设置不合理导致(ShardingSphere-Proxy 5.0.0-beta ~ 5.2.0 版本默认设置了 200,000)。
所以,平时在查内存相关问题时,通过对 Retained 占用较大的对象进行分析,大概率能够确定内存占用的根本原因。主流内存分析工具还具备跟踪引用链、执行 OQL 查询等功能,本文篇幅有限,请读者自行探索。
async-profiler
笔者曾在《代码细节带来的极致体验,ShardingSphere 5.1.0 性能提升密钥》中介绍了 ShardingSphere 在代码细节方面的性能优化,async-profiler 在发现这些代码细节优化点的过程中提供了很大的帮助。
async-profiler 是针对 JVM 的采样分析工具。具备以下特点:
- 不受 Safepoint Bias 影响;
- 性能开销低(采样频率可调整),生产可用;
- 使用方便,可基于 Java Agent 启动,或指定 PID 连接已有 JVM;
- 支持多种输出格式(HTML、SVG、JFR 等)及格式转换。
支持事件:
- CPU 周期;
- 硬件和软件性能指标,如缓存未命中、分支未命中、缺页、上下文切换等;
- Java 堆中的分配;
- 锁,包括 Java 对象监视器和 ReentrantLock;
- ……
与一些常见的采样工具相比,async-profiler 能够同时支持 Java、本地方法、内核代码路径采样,性能开销可控,用于 JVM 采样,选它不会有错。

图片来源:https://github.com/apangin/java-profiling-presentation/blob/master/presentation/java-profiling.pdf
IDEA 也集成了 async-profiler 等工具,能够在启动应用的时候直接使用。

on-CPU 与 off-CPU 采样
on-CPU 采样:对应 async-profiler event 为 cpu。对当前正在消耗 CPU 的线程进行采样,即采样结果中只包含 Running 状态的代码路径(例如线程池中正在等待任务的空闲线程、正在等待 I/O 操作的线程等,这些线程的代码路径不会被大量记录到样本中)。最终的采样记录,代码路径与其样本数在总样本数中的占比,表示对应代码在采样期间大致的 CPU 使用率。在火焰图中,即 样本宽度越大,其对应的代码占用的 CPU 可能越多 。
off-CPU 采样:对应 async-profiler event 为 wall。无论当前线程状态如何,其代码路径均会被记录到样本中。
cpu 与 wall 无法同时使用。
案例:
本案例来源于 PR:https://github.com/apache/shardingsphere/pull/21005
ShardingSphere 曾经发生过在代码重构过程中,因编码不当,在主流程代码中引入了大量创建异常对象的开销。
使用 async-profiler 对 JVM 进程进行 120 秒 on-CPU 采样,结果以 JFR 格式输出到文件中:
./profiler.sh -e cpu -f %t-output-%p.jfr -d 120 ${JVM_PID}
JFR 格式可以直接使用 IDEA 打开。从火焰图中可以看出,代码路径中出现了大量的 fillInStackTrace。fillInStackTrace 是创建异常实例过程中,用于获取异常代码堆栈的方法,由于获取堆栈的过程存在一定的开销,大量执行的情况下会消耗较多 CPU。
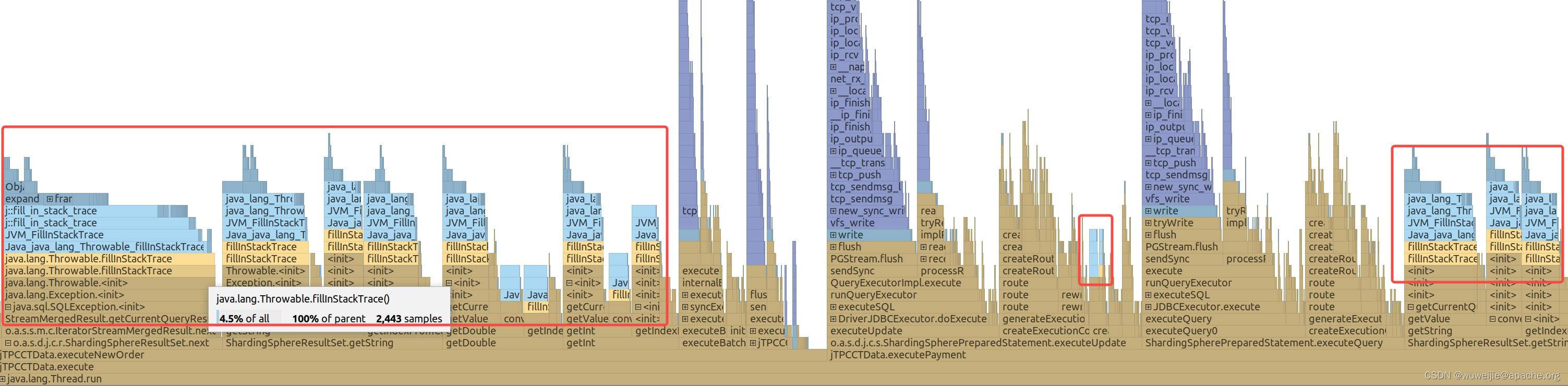
根据采集到的代码路径,对代码进行优化即可。
内存分配采样
模拟试验:
使用 jshell 创建一个类 AllocExample,这个类的每个实例会持有一个 1 GB 的 long[]。
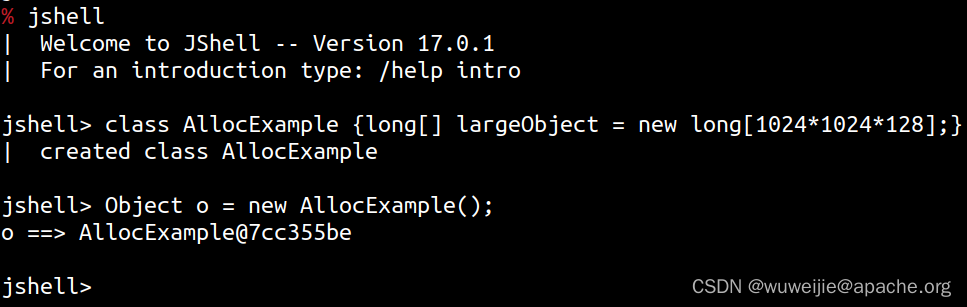
使用 async-profiler 对 jshell 进程进行内存采样:
./profiler.sh start -e cpu,alloc -f /tmp/%t-alloc-%p.jfr $JVM_PID
# jshell 内执行 new AllocExample()
./profiler.sh stop -e cpu,alloc -f /tmp/%t-alloc-%p.jfr $JVM_PID
使用 IDEA 可以打开采集的 JFR 文件,代码路径显示 AllocExample 构造方法创建了约 1 GB 的 long[] 实例:
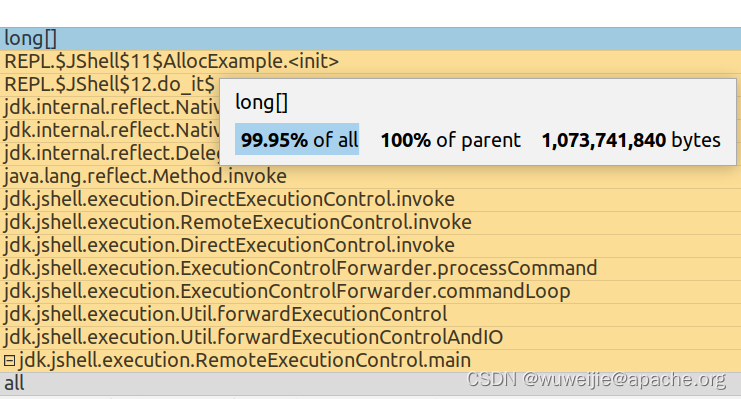
在 Events 详情中可以看到,这个 1 GB 的实例创建是在 TLAB 之外的。
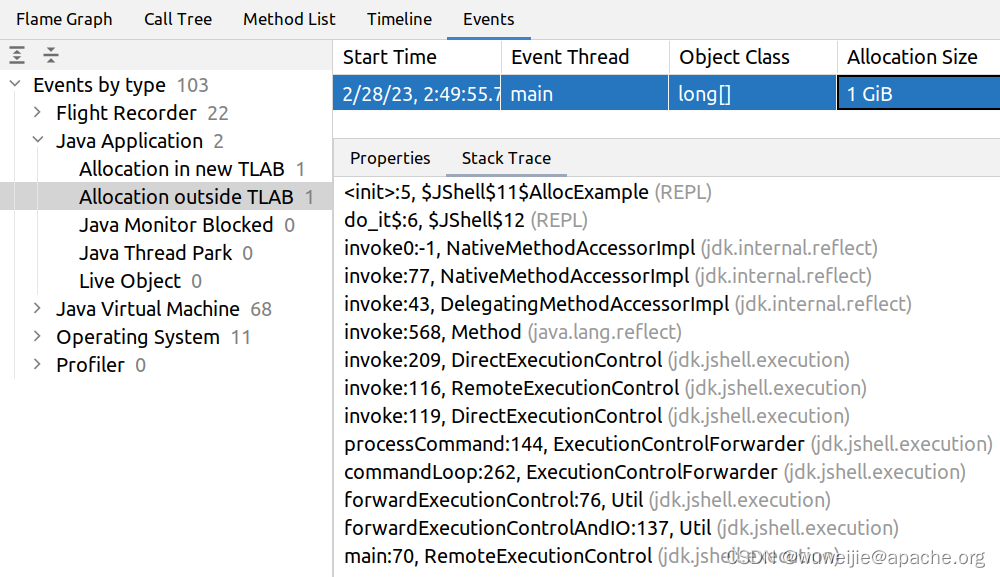
通过内存分配采样,能够可视化 HashMap、ArrayList 等数据结构的扩容开销,或发现代码中不合理的内存分配表现。
阻塞事件记录
async-profiler 支持的 lock 事件在应用并发性能调优过程中能够发挥很大作用。本文前面介绍 jstack 时也提到,当线程因锁、synchronized 阻塞的情况不是特别明显但又存在一定并发性能影响时,async-profiler 能够帮助调优人员发现这类情况。
ShardingSphere 历史版本在并发性能受限这一问题上有较多案例,其中多起与 JDK-8161372 有关。
案例:
本案例来源于 ShardingSphere 社区:
Potentially concurrent performance issue in DriverExecutionPrepareEngine
https://github.com/apache/shardingsphere/issues/13274
在 ShardingSphere-Proxy 高并发性能测试过程中,压测程序、Proxy、数据库的 CPU、内存、I/O 等指标使用率均没有明显瓶颈,实时 TPS 低于预期。
使用 async-profiler 只要指定 --lock 100us 参数即启用 lock 事件采样,100us 指的是仅记录持续 100 微秒以上的阻塞事件。
./profiler.sh -e cpu --lock 100us -f %t-cpu-lock-%p.jfr -d 120 $JVM_PID
采集到的 JFR 文件同样可以使用 IDEA 或 Java Mission Control 等程序进行分析,以下为 Java Mission Control 的展示结果。
采样过程只持续了 2 分钟,但从结果中看总阻塞时间长达 10 小时 57 分。这个总时长实际上是将所有线程的总阻塞时间之和,本案例并发线程数为 350,每条线程阻塞总时长约 1 分 53 秒,350 * 1 分 53 秒大约为 10.98 小时。
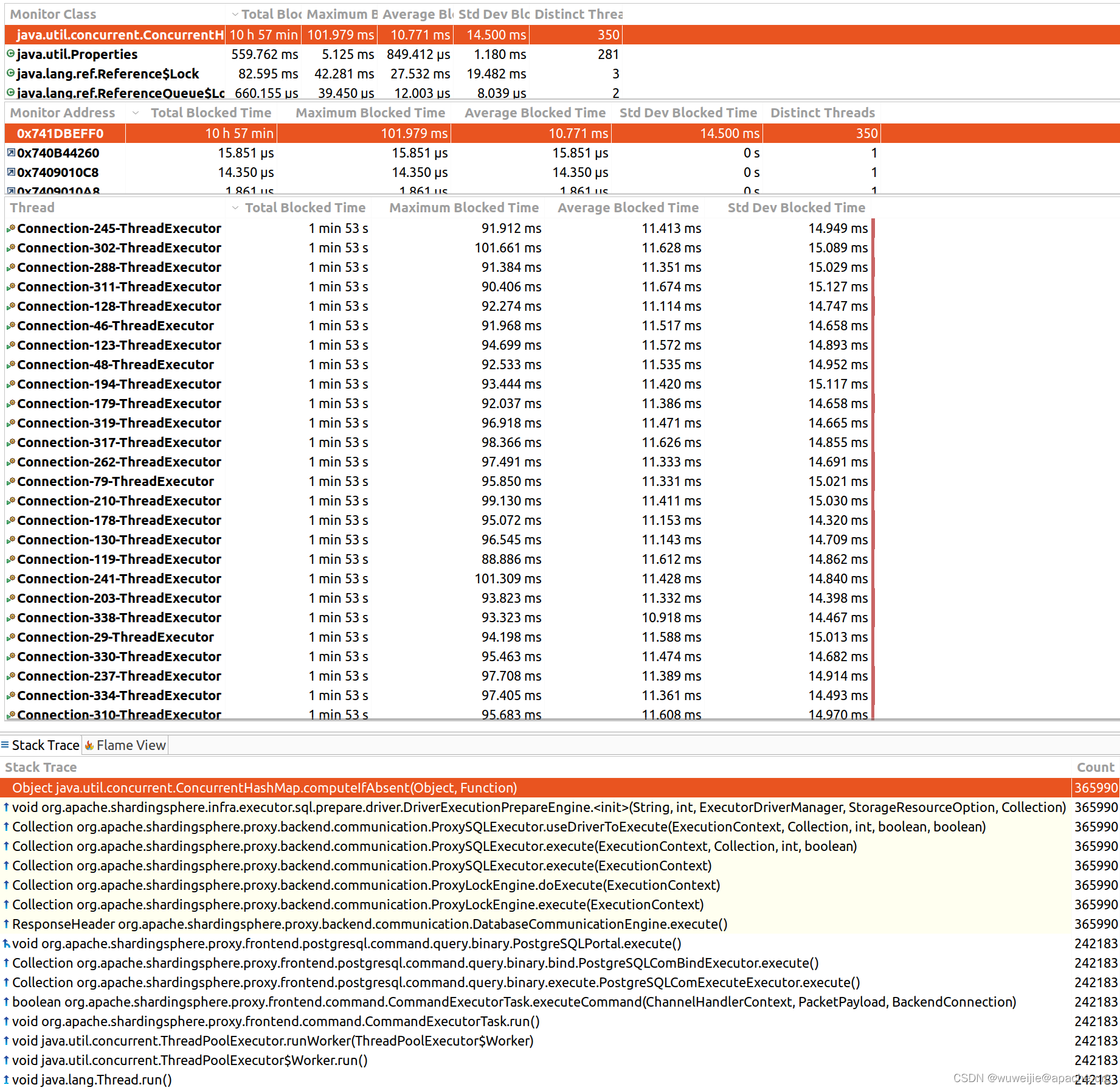
开发者可以根据 lock 采样分析结果,优化可能会限制并发性能的代码。
以上就是部分 JDK 自带工具、async-profiler 基本使用方法的介绍,掌握这些方法,就能够发现大部分代码层面的性能问题及优化点。