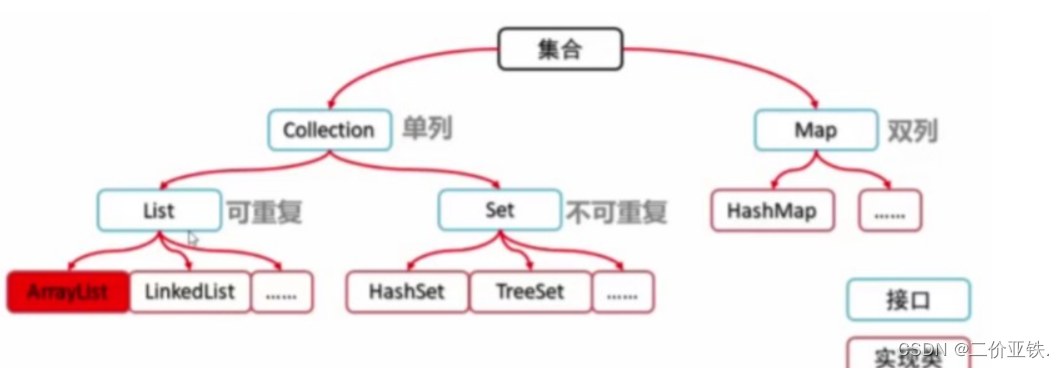
单列集合的顶级父类是:Collection
Collection又分两大类:List(存放的元素可重复) 和 Set(存放的元素不
可重复)
List下又分三大类:ArrayList,LinkedList,Vector(这个技术已被时代淘汰)
在数据结构方面:
-
ArrayList:可以分为两部分去看Array和List。Array代表了这个ArrayList的底层是通过数组实现的,List代表了ArrayList是一个单列集合。ArrayList的底层核心是数组扩容,这就解决了数组的弊端,在使用数组时,你必须规定数组的长度,而你使用ArrayList就可以避免数组的这个弊端。在你实例化ArrayList后,ArrayList底层首先会创建一个长度为0的数组,在你填入元素后会创建长度为10的数组,如果你填入的数字超过长度为10的数组,那么ArrayList的底层会再次创建一个原来数组长度1.5倍的数组,再将原来的数字元素拷贝到新的数组,因此,arraylist的容量可以动态地增加。由于底层数据结构是数组,因此访问元素的速度较快,但插入和删除元素时需要进行数组的复制和移动操作,速度稍慢。
-
LinkedList:也可以分为两部分去看Linked和List。Linked代表了这个LinkedList的底层是通过双链表实现的,List代表了ArrayList是一个单列集合。双链表(Doubly linked list)是一种数据结构,与单链表相比,每个节点包含两个指针:一个指向前一个节点,一个指向后一个节点。双链表的优点是可以从任何一端开始遍历,可以在常数时间内向前或向后遍历任何一个节点,实现了双向遍历。双链表的缺点是需要额外的一个指针,占用了更多的空间。但由于底层采用双链表的数据结构,LinkedList在数据的删除和添加的效率就比ArrayList的效率更高,但由于LinkedList缺少索引,它在查询方面就没有ArrayList效率高,但这也不是绝对的,在LinkedList中,如果只查头节点和尾节点,那么两者效率就差不多
在内存方面:
数组在内存中是连续开辟空间的,这就意味着你的内存要足够大,能
够去创建一个较大数组。
双链表在内存中是不连续开辟空间的,只要内存中有空间,那么就可
以存放数据,不用专门在内存中拿出一块没有存放数据的空间
使用场景
-
如果使用时更偏向数据的查询那么就选择,ArrayList
-
如果使用时更偏向数据的增删那么就选择,LinkedList
-
Set的下面三个子系:HashSet、LinkHashSet、TreeSet
-
HashSet:放在其中的元素是无序的,不重复的,没有索引。在数据结构上采用的是哈希表
1、LinkHashSet:优化了HashSet的无序性,存放在集合中的元素,
在输出的时候按照存进来的顺序输出,在数据结构上采用了哈希表和
单链表,哈希表的作用是存放元素,单链表是保证元素的有序性
2、TreeHasht:具有一个独特特点那就是会对存进来的元素进行排
序,这是因为它的底层是基于红黑树实现的
使用场景
一般情况下,开发中使用最多是HashSet,很少去使用LinkHashSet,
因为会降低代码运行效率
除非业务需求要有序,TreeHasht会在业务要求对存进来的元素进行排
序是,才会使用。