目录
题目
废话不多说,先给各位看官老爷看看题目。


思路
这类问题看着挺复杂,其实真正琢磨透了很容易理解。
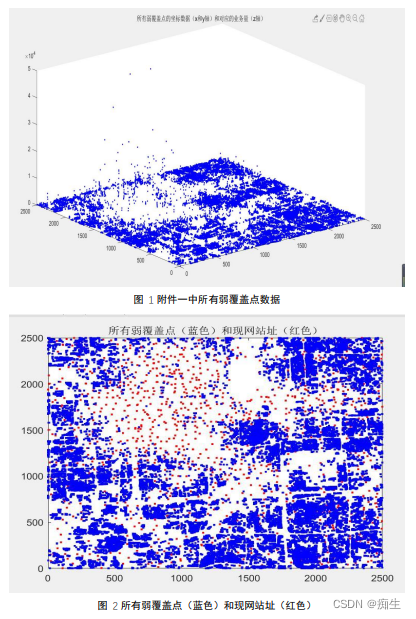
弱覆盖点,不难理解,就是已有基站支撑起的信号网络中的漏洞,在这些点位上,因为周围附近没有基站,所以导致这个点位处信号很差。而题目中附件一给的关于弱覆盖点的数据一共就三列,前两列是弱覆盖点的坐标(即x与y),而第三列给出的数据就是这个位置的业务量。据此,我们可画出一个三维图(z坐标即为该点位的业务量)。
题目理解了,接下来我们具体问题具体分析:
问题一
对于问题一,我们首先要明白题目究竟需要我们干什么。我们首先能注意到一点:弱覆盖点的被覆盖业务量占弱覆盖点的总业务量的90%。这是硬性条件,也是底线。无论选择何种做法,90%必须要达到。
然后再观察题目,建立基站肯定是越少越好,覆盖的业务量又肯定是越多越好。这就涉及到了一个很常见的方法——多目标规划。在这题中,我们队伍应为没有找到二者的相关权重,所以对基站建立的数量、覆盖的弱覆盖点的业务量这两者采用对半分,即各占1/2。随后根据题目条件(基站之间要有距离之类的)寻找约束条件。最后建立好模型并且求解。
值得一提的是,在问题一的处理过程中,我们队伍进行了一个降噪。我们把一些虽然是弱覆盖点,但业务量少得可怜的点位去掉了,最终降噪完的总业务量约占原业务量的95%。于是在我们队伍的实际解题过程中,附件一中弱覆盖点业务量大于12.5的点位被我们保存,点位数于是从182807降为55244。
问题二
细看题目,其实就是第一问的进阶版。
在第二问中,基站覆盖范围不再是一整个圆形。

目标函数不变,限制条件中需考虑到由圆形到扇形的转变。
问题三
题目非常明确做出了要求:聚类,总时间复杂度尽可能低。
这道题仁者见仁智者见智,我们队伍使用了非支配遗传排序算法+K-means聚类的方法。
总结
题目难度不高,认真做即可。这算是本人第二次参加数模,经历过美赛的毒打,这次觉得还好。