第十届CCF大数据与计算智能大赛(2022 CCF BDCI)已圆满结束。大赛官方竞赛平台DataFountain(简称DF平台)将陆续释出各赛题获奖队伍的方案思路。本方案为【系统访问风险识别】赛题的二等奖获奖方案,赛题地址:
https://www.datafountain.cn/competitions/580(戳底部“阅读原文”可直达)

获奖团队简介
团队名称:LOL四缺一
团队成员:团队成员是来自华南理工大学2020级软件学院的四名大三学生。在校期间成员数次获得学校以及企业奖学金,积极参加实验室活动,积极参加华为众智计划以及智能基座项目,打下了良好编程的基础。
所获奖项:二等奖
摘要
当前IAM的探索进程当中,目前最为可具落地的方法,是基于规则的行为分析技术。
但其局限性很明显,它是基于经验的,有宁错杀一千,不放过一个的特点,缺少从数据层面来证明是否有人正在尝试窃取或验证非法获取的身份信息,又或者正在使用窃取的身份信息,以此来提前进行风险预警和处置。
针对此问题,我们团队结合机器学习,建立了一个完整的项目流程。
关键词
lgb模型、特征工程、误判率分析
数据分析
| 变量名称 |
业务含义 |
说明 |
| id |
样本ID |
_ |
| user_name |
用户名 |
若该变量为空,则说明该条日志为用户登录系统前产生 |
| department |
用户所在部门 |
_ |
| ip_transform |
认证IP (加密后) |
真实认证 IP 与加密字符一一对应脱敏处理 |
| device_num_tran sform |
认证设备号 (加密后) |
真实认证设备号与加密字符一一对应脱敏处理 |
| browser_version |
浏览器版本 |
_ |
| browser |
浏览器 |
_ |
| os_type |
操作系统类型 |
_ |
| os_version |
操作系统版本 |
_ |
| op_datetime |
认证日期时间 |
_ |
| ip_type |
IP 类型 |
_ |
| http_status_code |
HTTP类型码 |
_ |
| op_city |
认证城市 |
_ |
| log_system_trans form |
接入系统 (加密后) |
真实接入系统与加密字符一一对应脱敏处理 |
| url |
访问URL |
_ |
| op_month |
认证月份 |
_ |
| is_risk |
是否存在风险 |
1:有风险;0:无风险。仅train.csv数据包含该字段 |
数据集除去id字段一共有16个特征,其中一个是是否被系统判断为风险的特征,其他的是例如用户名、ip号、网络状况、操作时间等登录信息,由此可以还原出用户的行为,以及网络的特征信息等。接着我们分析了所有特征中字段的构成以及数据分布,同时分析了各个字段间的关系,试图还原出这个系统的现实场景。
因为所以能登录进的ip类型都是内网,因此我们判断这是一个公司的私有系统,不对外开放,公司分为5个部门,会计、工程师、销售、人力以及其他,每一个部门都只能访问与其部门内容相对应的网页,不能跨部门访问,例如工程师不能登录到会计网站。各个部门的上下班时间大致相同,但又不完全一致,例如工程师的在岗时间要比其他岗位要再长一些。各部门电脑配备都配备有多种操作系统、浏览器、浏览器版本等。该公司在全国12个主要城市设立分公司,因此访问也相对集中,访问记录正常,因此在国外以及未知地点的访问通常会被判断为危险。同样,当试图登录进系统时,如果触发获取登录码或者获取登录类型时,被系统识别为风险的概率也会较高。
特征工程
2.1 特征拆解
原始数据集中的操作时间特征包含许多信息,因此我们把操作时间拆分成了年、月、日、时、星期几等信息,并且将其转化成了便于运算操作的int64类型。
2.2 特征提取
我们观察了数据集中的数据类型并且绘制了数据分布散点图,通过方差过滤法去除了取值一样的年特征。同时因为检验集中的月份特征与测试集不一样,所以去除了月份特征。
2.3 时序特征衍生
因为系统的使用者是人,而人的行为特征与时间特征具有很强的相关性。在反常的时序中操作必定会伴随一定的风险性。因此我们着重处理时序特征。我们首先引入chinese_calendar 库来进行假期处理,同时统计相同用户的登录时间间隔,并且按照离散型变量分类求出每种离散型变量登录间隔的均值和标准差。最后,因为小时时间是一个周期型变量,单纯用数值型来进行编码是欠妥的,会严重误导模型的训练结果,因此我们将小时正余弦化加入到特征中,取得了不错的效果。
2.4 分组统计特征衍生
除了时序特征之外,我们也可以从登录链路的角度进行分析,如果某些访问与一些系统攻击行为有相同的特征,那么其风险的概率也会增大。因此我们把同一用户前一分钟的访问下载次数纳入考量,如果一分钟之内访问次数过多,可能会有数据泄露的风险。另外,统计部门以及整个系统的前段时间访问量也对总体的访问趋势有影响,因此我们统计了这些访问量并且加入到模型中。
2.5 LabelEncoder 标签编码
因为本题许多离散型变量的取值都是字符类型,因此我们使用labelEncoder对离散型变量进行编码,有利于模型的预测,提高模型的准确率。
模型构造
3.1 数据集选取方法
本次我们使用了五折交叉验证的方法,把训练集划分成五份,并且使用了StratifiedKFold分层抽样,使得每一份子集中都保持和原始数据集相同的类别比例,避免由于样本分配不均而导致的模型偏差。然后将每个子集都做一次验证集,其他四个子集作为训练集,训练出五个不同的模型,用这五个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标,可以有效地避免过拟合。
3.2 模型选择
本次我们使用了XGBoost、LightGBM和CatBoost三个模型,因为本次我们处理的训练样本是数据较少的结构化数据领域,因此这三个模型具备较大优势。实验后发现LightGBM表现较好,因此选择其为主模型进行优化。
3.3 参数调整
首先通过人工调参的方式依据拟合程度调整num_leaves、lambda_l1、lambda_l2、learning_rate、max_depth等参数,然后再通过网格搜索搜寻最佳参数,发现了模型的最佳参数。
3.4 模型融合
我们尝试了多个模型的加权融合以及单模型的融合,得到了新的数据结果。
3.5 模型与特征工程的结合——误判率修正
在评估一个分类模型预测效果的好坏时,会出现两个重要的概念:假阳性(False Positive):指的是预测为阳性,但实际上是阴性的情况;假阴性(False Negative):指的是预测为阴性,但实际上是阳性的情况。显而易见,要想继续提高我们现有模型的预测准确度,关键就是减少假阳性和假阴性的情况。
在模型的训练过程当中,会通过五折交叉验证来评估模型预测效果的好坏。其中对于训练集的每一个样本,都会被选中作为验证集的样本被模型预测。将预测结果与实际标签进行比对,就可以识别出假阳性和假阴性的情况。

图1:误判样本的判定演示图

下面是对hour的误判率分析:

图2:不同hour类别对应的样本误判率
这里我们列出了训练集中以访问时间hour分类的不同类别对应的误判率曲线,可以看到,在24个小时中,误判率最低的是第一个小时,仅有百分之1.04,而最高的是第12个小时,有百分之13.18,两者的差值高达百分之12.14。
在实际场景中,这种误判率的不同很有可能是因为这家公司在第8个小时和第12个小时这两个高峰时段有更多的突发事件,因此容易导致模型误判。引入误判率的修正使得模型对特定时段的访问记录的风险判断有了更多的反馈信息。

图3:实际模型训练操作的演示
实际操作中,我们首先对模型进行第一次训练,然后用该模型去预测训练集样本的访问风险概率,将预测结果按hour进行分类,统计得到若干个类别的误判率,将得到的不同类别的误判率作为新特征,用来对模型进行第二次训练,最终得出对测试集预测结果。
应用效果
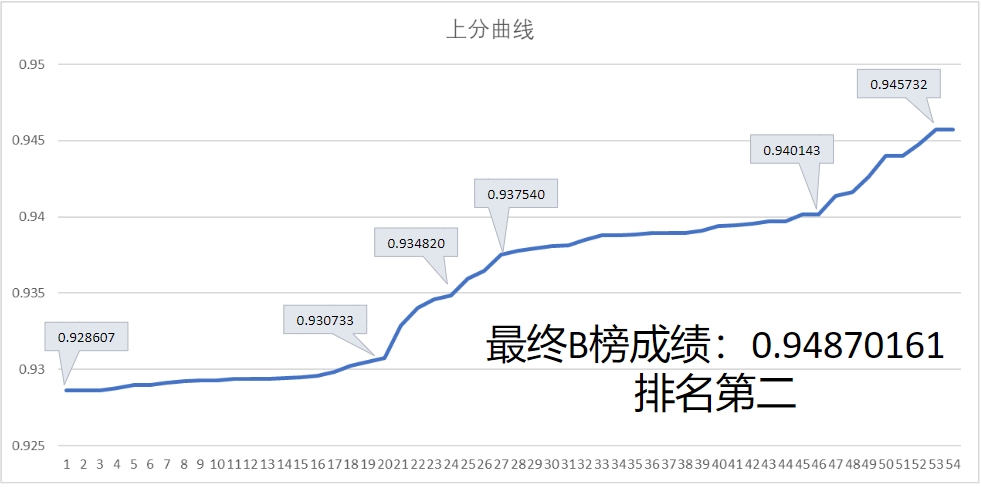
图4:模型迭代过程中的得分曲线
加入了每分钟访问量和法定节假日在内的多个特征之后,我们的a榜分数从baseline的0.928607提升到了0.937540。后面,误判率修正这个方法对测试集的预测正确率有了很大的提升,A榜分数从0.940143提升到0.945732,排名上升30多名。最后B榜成绩出来,我们的成绩位列第二名。
致谢
感谢主办方提供的这么一个平台,让我们在这里遇到了更好的自己。也要感谢蔡毅老师以及谢嘉元师兄的指导,他们渊博的学识令我们深深敬佩,他们悉心的指导我们不胜感激。最后,也要感谢那个一直努力奋斗的自己,路漫漫其修远兮,吾将上下而求索。
参考
[1] datafountain,系统访问风险识别数据与评测,https://www.datafountain.cn/competitions/580/datasets
[2] Meng Q . LightGBM: A Highly Efficient Gradient Boosting Decision Tree. 2018.n/
[3] 黄博的机器学习圈子,XGBoost、LightGBM与CatBoost算法对比与调参,https://cloud.tencent.com/developer/article/1814287