前言
MLC LLM 是一个通用的解决方案
它允许任何语言模型在不同的硬件后端和本地应用程序集上进行本地部署
并为每个人提供一个高效的框架,以进一步优化模型的性能,满足他们自己的用例
其使命是让每个人都能在自己的设备(如手机端)上开发、优化和部署人工智能模型
项目地址:https://github.com/mlc-ai/mlc-llm
什么是MLC-LLM
自ChatGPT发布以来,大语言模型(Large language model, LLM)就成了AI乃至整个计算机科学的话题中心
学术界,工业界围绕大语言模型本身及其应用展开了广泛的讨论,大量的新的实践层出不穷
由于LLM对计算资源的需求极大
有能力部署大语言模型的公司和实验室一般通过搭建集群,然后开放API或者网页demo的方式让用户可以使用模型
在人们纷纷发挥想象力尝试各种prompt与模型对话的时候
同时也注意到在一些应用场景中,出于定制化、个性化或者隐私性的目的
人们想要自己在各种终端设备中本地运行大语言模型,不需要/不希望连接互联网或者依赖于服务器
为了解决这一类问题
MLC-LLM是我们在各种不同硬件上原生部署任意大语言模型的解决方案。可以将大语言模型部署到这些平台上
- 移动端:iPhone (Android平台的app正在开发中)
- Metal GPU和Intel/ARM MacBook
- 在Linux/Windows上,通过Vulkan驱动的AMD和NVIDIA GPU
- 在Linux/Windows上,通过Cuda驱动的NVIDIA GPU
- 浏览器,通过WebGPU ,我们也有这一方向的尝试
MLC-LLM的目标是什么
近年来,生成性人工智能(AI)和大语言模型(LLM)的研究取得了长足的进展,并日益普及
多亏了开源计划,现在可以使用开源模型来开发个人人工智能助手
然而,LLM 往往是资源密集型和计算要求
为了创建可伸缩的服务,开发人员可能需要依赖强大的集群和昂贵的硬件来运行模型推理
此外,部署 LLM 提出了一些挑战,例如它们不断发展的模型创新、内存约束以及对潜在优化技术的需求
MLC-LLM的目标是开发、优化和部署人工智能模型
以便在一系列设备上进行推理,这些设备不仅包括服务器级硬件,还包括用户的浏览器、笔记本电脑和移动应用程序
为了实现这一点,我们需要解决计算设备和部署环境的多样性。一些主要挑战包括:
- 支持不同型号的 CPU、 GPU 以及可能的其他协处理器和加速器
- 在用户设备的本机环境上部署,这些设备可能没有 Python 或其他必要的可用依赖项
- 通过仔细规划分配和积极压缩模型参数来解决内存约束
MLC LLM 提供了一个可重复的、系统化的和可定制的工作流程
使开发人员和人工智能系统研究人员能够以以生产力为中心、 Python 优先的方法实现模型和优化
这种方法可以快速尝试新的模型、新的想法和新的编译器传递,然后将本机部署到所需的目标
此外,我们不断扩大 LLM 加速通过扩大 TVM 后端,使模型编译更加透明和高效。
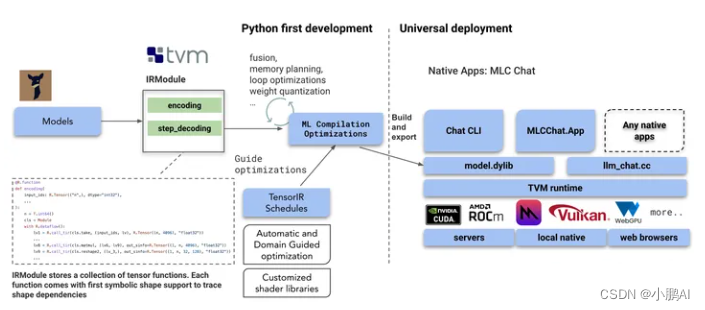
MLC 如何本地部署?
MLC LLM的解决方案的基石是机器学习编译(MLC) 利用它来有效地部署 AI 模型, 部署时有如下特征
-
LLM天然具有输入变长的特点,我们将原生支持dynamic shape输入的模型编译成TVM IRModule,使我们能够避免必须padding到最大长度,从而减少计算开销和内存需求(对于移动端来说尤其重要,例如iPhone限制了每个应用最多使用4G内存)
-
组合机器学习编译优化: 我们执行许多模型部署优化,例如更好的编译代码转换、融合、内存规划、库卸载和手动代码优化,可以很容易地将 TVM 的 IRModule 转换作为 Python API 公开
-
利用低位量化来压缩模型权重,并利用 TVM 的环路级 TensorIR 来快速定制不同压缩编码方案的代码生成
-
TVM编译生成的库通过TVM runtime在设备的原生环境下运行(不同于WebGPU)TVM runtime支持CUDA/Vulkan/Metal等主流GPU驱动以及C, JavaScript等语言的绑定
-
提供了一个轻量级的基于 C + + 的示例 CLI 应用程序,它展示了如何包装已编译的构件和必要的预/后处理,这将有望澄清工作流程,以便将它们嵌入到本地应用程序中。
-
作为一个起点,MLC 为 CUDA、 Vulkan 和 Metal 生成 GPU 着色器。通过对 TVM 编译器和运行时的改进,可以增加更多的支持,比如 OpenCL、 sycl、 webgpu 本机。MLC 还通过 LLVM 支持各种 CPU 目标,包括 ARM 和 x86。
MLC LLM依赖于开源生态系统,更具体地说,是 TVM Unity,这是 TVM 项目中一个令人兴奋的最新发展,它支持 Python 优先的交互式 MLC 开发体验,使我们能够轻松地用 Python 编写新的优化,并逐步将我们的应用带到感兴趣的环境中。利用优化,如融合量化内核,一流的动态形状支持和不同的 GPU 后端。
关键技术-Dynamic shape的支持
Dynamic shape是MLC LLM成功运行大语言模型的关键,因为sequence length(seq_len)和kv cache的大小都是动态的
seq_len根据模型输入决定,而kv cache的大小随每次模型forward而增长
之前的大部分基于编译的深度学习框架采用static shape
采用那些框架必须使用padding技术和bucketing技术,会造成重复编译,极大增加编译时间
TVM Unity 原生支持dynamic shape,所以我们可以将seq_len和kv cache 大小分别表示成抽象变量,避免重复编译
TVM的symbolic shape的支持可以使得我们针对动态的计算也可以进行如算子融合, TensorIR融合和内存分配等优化,并且灵活地和其他优化结合起来。
Dynamic shape引发了新的问题
如何对一个dynamic shape的算子优化?
因为TVM unity的灵活特性,我们可以采用各种自己的优化策略
我们采用了专家知识和自动调优结合的方法
首先,我们得知大部分库采用高度优化的固定shape的micro-kernel,循环调用它,来实现dynamic shape的优化。我们采用相似的方法,使用auto tuning优化一个micro-kernel,如323232的矩阵乘法(下文以该micro-kernel举例),然后使用专家知识,手工pad算子的形状为32的倍数
然后在tiling之后,使用micro-kernel替换内部循环
在推动模型的支持的过程中我们也基本确认TVM Unity可以有效针对性地处理动态shape的编译迭代
相信相关的代码也可以让其它对于机器学习编译和大模型优化有兴趣的同学有所帮助,或者帮助大家部署大模型到更多硬件上。
整体结构
参考文献
- https://github.com/mlc-ai/mlc-llm
- https://zhuanlan.zhihu.com/p/625959003
- https://mlc.ai/mlc-llm/