企业基本都有自己的IT系统,而每个IT系统都有自己的监控系统。
企业级的IT应用监控架构是一种综合性的解决方案,涉及到很多层级和相应的工具。随着企业IT系统的规模和复杂程度的不断增加,监控和管理系统也面临着越来越大的挑战。
大家有时在建立监控时,不知道从何处入手;有时建立监控系统后,发现很多的盲点无法监控到。
本文将分享IT应用运维监控的基本原理、通用监控体系和应用场景、监控平台设计、智能监控的实现方法等方面的内容,以期对企业 IT 系统的监控和管理提供一定的帮助。
1.监控原理
企业级 IT 应用运维监控架构的基本原理是通过收集、存储、分析和展示各种监控数据,对企业 IT 系统进行全面的监控和管理。其中,监控数据包括系统、网络、应用等各种指标数据、事件数据和日志数据等,可以通过各种数据采集器进行收集。
收集到的数据可以存储在分布式数据库、NoSQL 数据库或者数据仓库等存储系统中,并通过数据分析和处理,将其转化为可视化的监控指标,并通过仪表盘、图表、报表等形式进行展示。
同时,还可以通过警报系统对监控数据进行实时监测和告警,以及通过自动化运维等手段对 IT 系统进行自动化管理和优化。
2.监控层次
一般来说,有IT系统的地方都必须有监控,不同企业IT系统分布不一样。有的企业有大量的边缘系统,比如:电脑,工控机等;有的企业有自己的IDC机房,而自己的IT系统建立在IDC机房内;有的企业把自己的IT系统建立在公有云上;又有的企业建立的混合云架构,IDC机房和公有云兼而有之。
IT监控系统是依附在之上的,对于边缘系统,有类似于IOT的物联网监控系统;IDC机房有网络设备的监控系统(这一般由网络供应商提供);公有云上的系统由云商提供完整的监控系统;如果有混合云的架构,那就需要由监控系统建设团队把云上云下的监控系统做融合提供统一的监控。
以上的这些监控是从系统角度进行分类的,做的是系统监控,而本文讨论的是,如何从应用运维的角度来进行层次划分。
2.1 APIs监控
APIs(应用程序编程接口)监控,又称为前端监控,是指对APIs的使用情况、性能、安全性等进行实时监控和管理的过程。通常包括:
A. 使用情况监控:监控APIs的调用情况、使用频率、错误率等,以便了解APIs的使用情况和流量状况。
B. 性能监控:监控APIs的响应时间、延迟、吞吐量等性能指标,以便及时发现APIs的性能问题和瓶颈。
C. 安全监控:监控APIs的安全性,包括身份验证、授权、访问控制等,以保护APIs免受安全威胁。
D. 错误监控:监控APIs的错误情况,包括错误类型、错误代码、错误频率等,以便及时发现和解决APIs的错误问题。
2.2 应用层监控
应用层监控是指对应用程序的性能、可用性、安全性等进行实时监控和管理的过程。通常包括:
A. 应用性能监控:监控应用程序的性能指标,包括请求响应时间、吞吐量、错误率饱和率等黄金四指标,以便及时发现应用程序的性能问题和瓶颈。
B. 可用性监控:监控应用程序的可用性,包括应用程序的运行状态、访问次数、错误率等,以保证应用程序的正常运行和可用性。
C. 安全监控:监控应用程序的安全性,包括应用程序的防火墙、入侵检测、安全事件等,以保护应用程序免受安全威胁,一般这是由安全团队负责,运维人员较少涉及。
D. 日志管理:收集、分析和可视化应用程序的日志信息,以帮助用户快速发现和解决应用程序问题和异常情况。
为了实现应用层监控,相对应的工具和平台:
A. 应用性能监控工具:通过监控应用程序的性能指标,以帮助用户快速发现应用程序的性能问题和瓶颈。
B. 可用性监控工具:通过监控应用程序的运行状态和访问次数,以保证应用程序的正常运行和可用性。
C. 安全监控工具:和APIs的监控类似,主要由漏洞扫描工具,入侵检测系统等工具构成,比如应用新上线的代码中使用了一个第三方的工具,此工具有后门漏洞,就会被监控到。
D. 日志管理工具:通过收集、分析和可视化应用程序的日志信息,以帮助用户快速发现和解决应用程序问题和异常情况。
2.3 资源层监控
资源层监控是指对计算机系统的各种资源(如CPU、内存、磁盘、网络等)进行实时监控和管理的过程,这个不仅包括服务器,还包括容器,而对于容器集群,由于有了水平扩展的资源调度,所以还包括容器的数量及其状态的监控。
2.4 链路层监控
链路层监控是指对分布式系统中各个组件、模块之间的交互过程进行实时监控和管理的过程。链路层监控可以帮助用户快速发现和解决应用程序的问题和瓶颈,提高应用程序的可靠性和性能。
2.5 后端监控
后端监控是指对应用程序后端(如数据库、缓存、消息队列等)进行实时监控和管理的过程。数据库监控是后端监控中的一个重要部分,主要是对数据库的性能、可用性和安全性进行监控和管理,以保证应用程序的正常运行和稳定性。
后端监控的也包括,性能监控、可用性监控、安全监控、日志监控等同应用层监控类似的监控。
在公有云大行其道的今天,越来越多的企业把后端(数据库,redis等)迁移到了公有云端,这些指标公有云都会提供,我们所要做的是把这些指标从公有云上引入到本地展示。
2.6 业务监控
业务监控是指对应用程序的业务功能进行实时监控和管理的过程,主要关注应用程序的业务流程和业务指标,以保证应用程序的业务功能的正常运行和业务价值的实现。
2.7 运维能力的监控
SLA(Service Level Agreement)、SLO(Service Level Objective)和 SLI(Service Level Indicator)是衡量运维能力指标的重要指标。SLA 是一种衡量客户服务质量的协议,SLO 和SLO是一种衡量所运维的系统可靠性是否达标的指标。
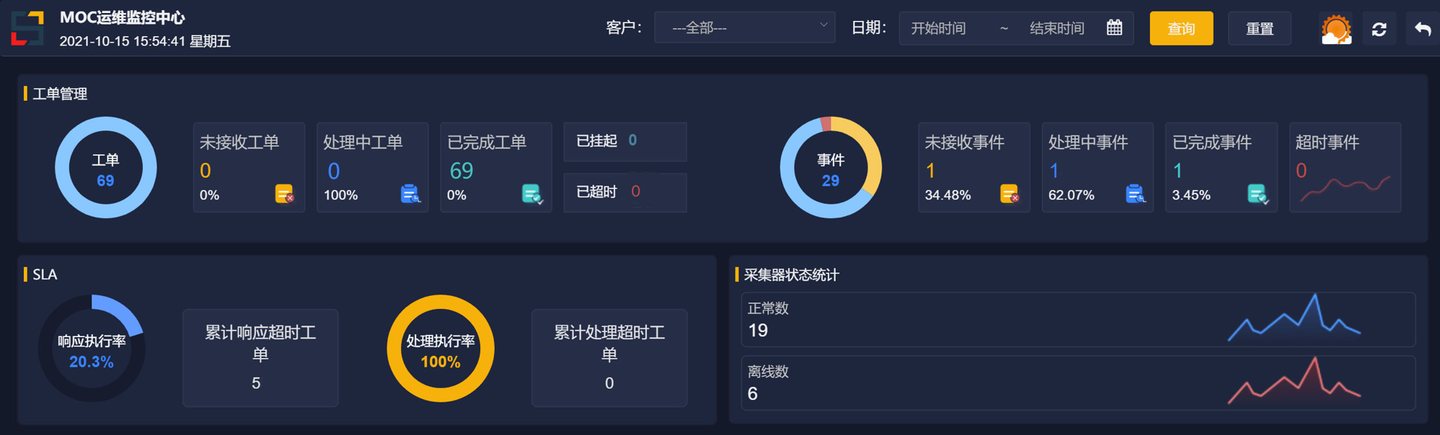
3.监控大盘与合成监控指标
这个问题的解决就要依赖监控大盘了
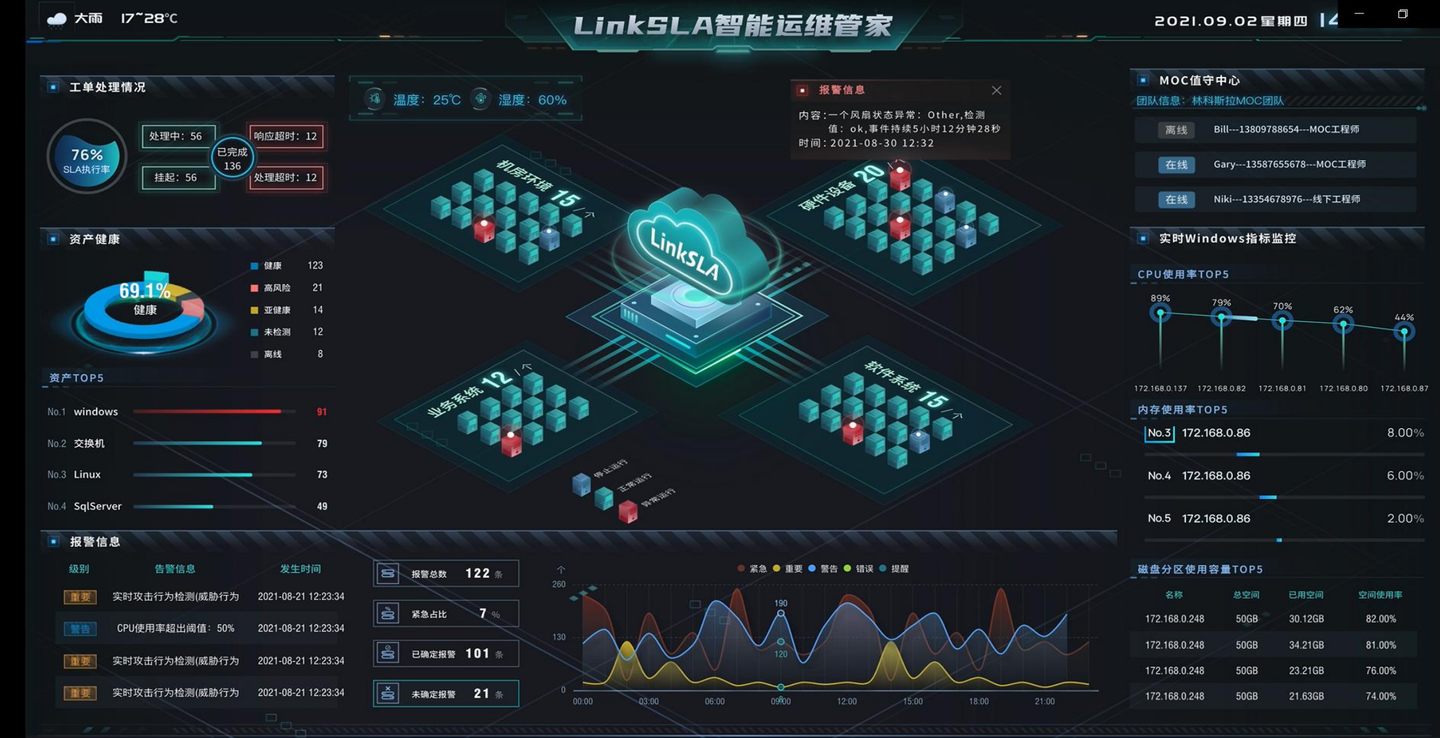
林科斯拉监控平台
监控指标太多了,我们就要对其合成,于是合成监控指标就诞生了。
合成监控指标是指通过对多个监控指标进行组合和计算得到的综合性指标,用于判断应用程序的整体健康状况和性能状况。合成监控指标通常是由多个单独的指标组合而成,可以反映出应用程序的整体性能和健康状况。
合成监控指标的计算方式可以根据具体情况而定,常见的计算方式包括以下几种:
A. 平均值:对多个指标的平均值进行计算,如请求响应时间的平均值、服务器负载的平均值等。
B. 加权平均值:对多个指标的加权平均值进行计算,根据不同指标的重要性为其分配权重,如请求响应时间和服务器负载的加权平均值。
C. 百分位数:对多个指标的百分位数进行计算,反映出指标的分布情况和极端值情况,如请求响应时间的95th百分位数。
D. 综合指数:通过对多个指标进行加权和,生成一个综合指数,用于衡量应用程序的整体性能和健康状况,如应用程序健康得分、性能指数等。
合成监控指标可以帮助用户更全面地了解应用程序的性能和健康状况,更快速地发现和解决问题。
4.智能监控告警
智能监控告警是指利用人工智能和机器学习技术对应用程序进行智能化监控和管理的过程。智能监控可以帮助用户更快速、更准确地发现和解决问题,提高应用程序的稳定性和可靠性。
A. 自动识别异常:不单独依赖于阈值进行告警,利用机器学习和统计分析等技术,对应用程序的监控指标进行分析和建模,自动识别异常情况并生成警报或自动触发预设的响应动作。
B. 自动调整配置:自动优化应用程序参数,利用机器学习和优化算法等技术,自动调整应用程序的配置参数,以优化应用程序的性能和稳定性。
C. 预测性分析:提前预测可能的故障风险,利用机器学习和时间序列分析等技术,对应用程序的历史数据进行分析和建模,预测未来的趋势和可能出现的问题,并提前采取措施防范和解决问题。
D. 减少重复告警:告警合并,利用机器学习对已经产生的告警进行判断,将不重要的告警级别降低或类似的告警合并,在告警中不触发或少触发。
E. 减少告警抖动:告警收敛,监控数据产生异常抖动时,监控系统到底要不要告警一直以来是个问题,利用机器学习多维度的监控数据、并用聚类算法进行分析,确定事件的关联性,以减少多告警或告错警的可能。
F. 告警场景生成:贴靠用户业务场景的告警,监控数据进行极值分析和降噪处理,将和用户业务相关的告警关联起来,和CI项关联,构成场景。
智能监控告警并不是推翻原有的监控告警系统,它是原监控告警的延伸,为企业提供更好的监控报警的体验。
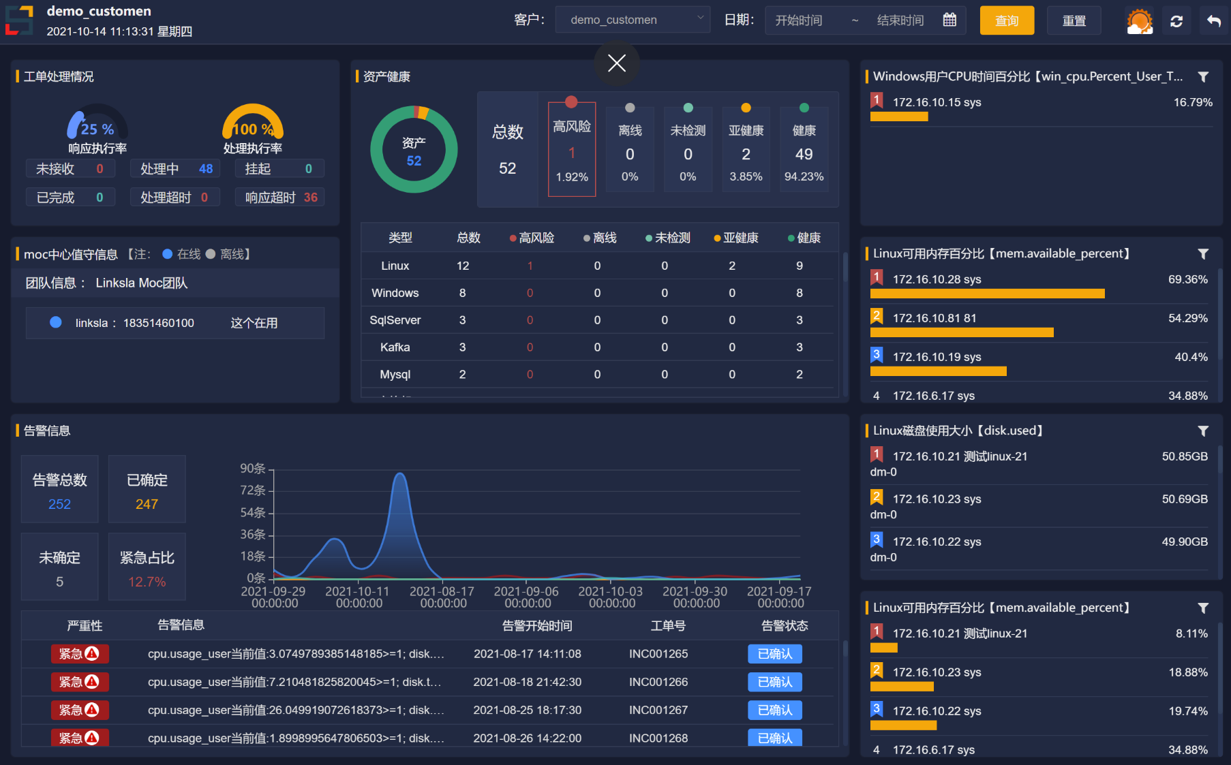
林科斯拉智能运维管家