文章目录
游戏行业最全大数据知识点分析和企业级架构设计分享
1 数据分析流程以及分析指标
1.1 数据来源
a) WEB服务器日志如:Tomcat,Nginx。
b) 游戏打点记录。
1.2 数据收集和落地
a)Nginx日志 + HDFS或S3。
b)Kafka+ Flume+ HDFS或S3 进行输入与输出。
1.3 离线分析
过滤清洗数据Nginx请求日志,ETL工作:
a) 统计每日请求量。
b) 统计哪一时段为用户活跃期。
c) 统计响应请求数量和未能响应的数量。
游戏打点记录业务逻辑:
a) 统计每日新增,新增留存。
b) 统计每日活跃人数维度如:平台(安卓/IOS),国家,终端(华为/iPhone)。
c) 休闲类游戏如有关卡,统计关卡通关率。
d) 统计广告点击率。
e) 游戏中价值替代物如钻石或者金币,统计其产出和消耗。
f) 统计出游戏中作弊用户。
g) 统计分析各种活动的利益价值。
h) 统计内购数量。
i) 统计游戏玩家启动次数,玩游戏的时长。
1.4 实时数据分析
a) 实时统计每小时内新增用户,活跃用户。
b) 实时统计每小时内购数量。
1.5 用户肖像
批处理+实时处理统计每个用户肖像:
a) 基础信息如:性别,国家,年龄,婚否,是否有车房。
b) 购买能力:根据消费金额和频率进行评估过。
c) 是否作弊:是否是破解包。
d) 广告用户:看广告频率多,不进行内购。
e) 玩家分类:频繁,经常,常常,一般,偶尔。
f) 玩家等级:高,较高,中上,中,较低,低。
2 相关知识
2.1 离线数据统计技能相关要求
2.1.1 Hadoop
a) 要求熟练掌握Hadoop读写流程;
b) 要求熟练掌握MapReduce作业流程;
c) 要求熟练掌握Job提交流程以及源码;
d) 要求熟练掌握Map Task和Reduce Task流程;
e) 要求熟练掌握YARN运行原理;
f) 要求掌握小文件优化,小表JOIN大表优化方案;
g) 要求掌握Job串行流程以及TOPN实现方案;
h) 要求熟练掌握ETL;
2.1.2 Hive
a) 要求熟练掌握内部表、外部表、分区表的创建;
b) 要求熟练掌握分区和分桶的区别;
c) 要求熟练掌握数据的导入导出;
d) 要求熟练掌握行转列和列转行的使用场景;
e) 要求熟练掌握窗口函数;
f) 要求熟练掌握Rank函数进行排名;
g) 要求熟练掌握自定义UDF和UDTF;
h) 要求熟练掌握文件存储格式以及区别;
i) 要求熟练掌握调优案例:小表和大表JOIN、大表JOIN大表、MapJoin、合理设置Map数量、小文件合并、合理Reduce数、JVM重用等;
2.1.3 HBase
a) 要求熟练掌握HBase读写流程;
b) 要求熟练掌握HBase的Memstore Flush;
c) 要求熟练掌握HBase的文件合并StoreFile Compaction;
d) 要求熟练掌握HBase的Region拆分流程;
e) 要求熟练掌握HBase的API;
f) 要求熟练掌握HBase的优化如:预分区;RowKey设计、内存优化、优化 HStore 文件大小、优化 HBase 客户端缓存、flush,compact,split 机制等;
2.1.4 Spark Core
a) 要求熟练掌握Spark通信架构;
b) 理解Spark DAG有向无循环图的设计思想;
c) 要求掌握Spark各个节点启动流程;
d) 要求掌握Spark的Job提交和Task的拆分;
e) 要求掌握Spark Shuffle过程;
f) 要求掌握Spark三种部署模式的区别;
g) 要求掌握 Transform和Action算子;
h) 要求掌握groupByKey和reduceByKey的区别;
i) 要求熟练编写wordCount程序;
2.1.5 Spark SQL
a) 要求掌握RDD、DataFrames、DataSet三者的关系;
b) 要求掌握自定义UDF函数和自定义聚合函数;
c) 要求掌握数据的输入与输出;
d) 要求掌握优化方案;
2.2 实时数据统计技能相关要求
2.2.1 KafKa
a) 要求掌握Topic的创建查询删除命令;
b) 要求掌握Kafka的存储机制及高效读写的原理;
c) 要求掌握Kafka生产者:分区原因及原则、ISR机制、故障处理细节、Exactly Once精准一次性;
d) 要求掌握Kafka消费者:push和pull区别和场景、分区分配策略RoundRobin和Range、offest的维护、重新消费等。
e) 要求了解Producer事务和Consumer事务;
f) 要求掌握Kafka自定义拦截器;
g) 熟练掌握Kafka数据积压处理方法;
h) 要求了解kafka如何保证顺序发送;
i) 要求了解会使用Kafka监控插件Kafka Eagle;
2.2.2 Flume
a) 要求掌握Flume组成架构Source、Channel、Sink;
b) 要求掌握Flume Agent内部原理;
c) 要求熟练编写拦截器;
d) 要求掌握Flume整合Kafka和Hdfs;
e) 要求了解数据流监控如:Ganglia;
2.2.3 Flink
a) 要求理解Flink特性:时间驱动型、流与批的世界观、分层Api;
b) 要求掌握Standalone模式和YARN模式;
c) 要求掌握作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager)、分发器(Dispatcher)它们之间的关系;
d) 要求掌握任务提交流程和任务调度原理;
e) 要求理解TaskManger和Slots之间的关系;
f) 要求掌握Source的类型, 流的合并和侧输出流;
g) 要求掌握Transform算子,常见聚合算子;
h) 要求掌握滚动窗口、滑动窗口、会话窗口;
i) 要求掌握时间语义和Wartermak; Flink底层8个Process Function:
1.ProcessFunction
2.KeyedProcessFunction
3.CoProcessFunction
4.ProcessJoinFunction
5.BroadcastProcessFunction
6.KeyedBroadcastProcessFunction
7.ProcessWindowFunction
8.ProcessAllWindowFunction
j) 要求掌握Sink的输出类型;
k) 要求掌握状态编程;
l) 要求掌握检查点checkPoint的原理;
m) 要求掌握Flink+Kafka实现端到端的exactly-once;
2.2.4 Spark Streaming
a) 要求掌握Spark Streaming消费Kafka的偏移量是如何维护的;
b) 要求掌握Spark Streaming读取Kafka数据的两种方式;
c) 要求掌握Spark Streaming读取kafka数据时如何保证数据不丢失问题,至多,至少,精准一次语义;
d) 要求理解updateStateByKey底层是如何实现保存数据原来的状态;
e) 要求掌握窗口函数;
f) 要求熟练编写WordCount程序;
2.3 其他技能要求
2.3.1 Redis
a) 要求掌握String、Hash 、List、Set、 Sorte Set操作;
b) 要求掌握并理解Redis哨兵模式;
c) 要求掌握RDB和AOF的区别;
d) 要求理解并运用Redis实现游戏周榜、月榜;
e) 要求理解并运用Redis锁实现高并发;
2.3.2 Mysql
a) 要求理解Mysql存储引擎InnoDB、MyISAM的区别;
b) 要求熟练掌握索引创建和索引失效的情况;
c) 要求了解Mysql读写分离;
d) 要求掌握Mysql存储机制;
e) 要求理解并运用实现高并发锁;
2.3.3 MongoDB
a) 要求理解MongoDB存储结构;
b) 要求熟练掌握集合的创建、删除、导入导出操作;
c) 要求熟练掌握数据的备份与恢复;
d) 要求熟练掌握索引的创建;
2.3.4 ElasticSearch
a) 要求掌握文档的创建删除查询;
b) 会使用elasticsearch-head;
c) 要求掌握和Kibana联合使用;
2.3.5 常见排序方法
a) 要求熟练掌握冒泡排序;
b) 要求熟练掌握快排;
c) 要求熟练掌握选择排序;
d) 要求熟练掌握插入排序;
e) 要求熟练掌握归并排序;
2.3.6 常见设计模式
a) 要求熟练掌握单例模式;
b) 要求熟练掌握观察者模式;
c) 要求熟练掌握工厂模式;
d)要求熟练掌握代理模式;
3 相关需求
3.1 Hadoop编程
假设下面是一部分nginx请求日志经过数据清洗后的数据。固定格式为:(用户ID IP 日期 请求URI 请求地址 请求状态 请求Agent)
e4ec9bb6f2703eb7 180.21.76.203 2020-06-30T09:11:14+00:00 /u3d/v2/appconfig 127.0.0.1:8080 200 “BestHTTP”
1f85152896978527 171.43.190.8 2020-06-30T09:11:14+00:00 /u3d/v2/userAction 127.0.0.1:8080 200 “BestHTTP”
要求:
a) 统计每天的日活跃人数;
b) 统计每小时的活跃人数;
c) 统计每小时请求URL排名前十名;
d) 统计出国家|省每日活跃数;
e)根据User Agent统计每日终端信息
3.2 Flink编程
假设有下面是一部分用户登录状态的日志。固定格式为:(用户ID IP 请求状态 时间)
e4ec9bb6f2703eb7 180.21.76.203 success 1558430815
1f85152896978527 171.43.190.8 fail 1558430826
要求:
a) 使用状态编程输出5秒内连续登录失败超过3次的用户;
b) 使用CEP输出5秒内连续登录失败超过3次的用户;
3.3 Spark SQL编程
假设有两张表new_users每天大约6M和play_stages表每天大约10G数据。两张表都包含以下字段:
userID 用户ID appName 游戏名称 appVersion 游戏版本 appPlatform 平台安卓|IOS
要求:
统计新增用户留存1-7,15,30,90这10天的留存率;
3.4 Redis编程
假设一个游戏有2000W用户,每天DAU大约100W左右,现在要求根据关卡值做一个游戏排行榜 ,你会如何设计?
4 大数据企业级架构设计
4.1 架构设计
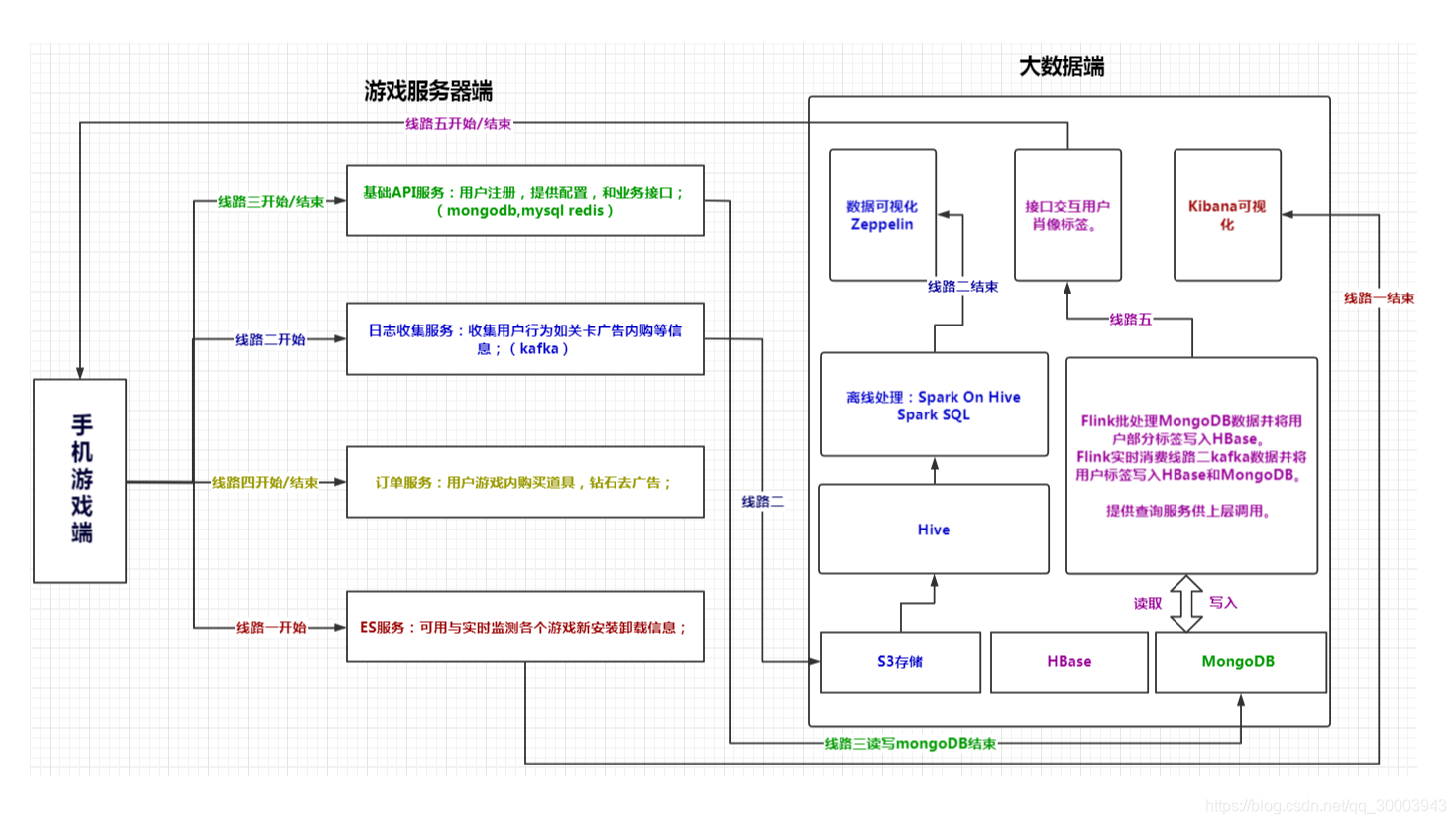
4.2 数据收集
客户端发送日志到接口,将数据发送到kafka消息中间件, flume将kafka作为source写入到亚马逊s3。
4.2.1 创建kafka的topic
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-diamond
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-ads
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-launch
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-stage
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-gift
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-shop
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-prop
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-ball
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic topic-s3-airdrop
4.2.2 配置Flume脚本(自定义拦截器将Kafka数据存储到S3)
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.pusidun.applogs.flume.interceptor.S3CollInterceptor$Builder
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = localhost:9092
a1.sources.r1.kafka.zookeeperConnect = localhost:2181
a1.sources.r1.kafka.topics.regex = ^topic-s3-.*$
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=10000
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = s3a://bricks-playable/logs/%{logType}/%Y%m/%d
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.rollInterval = 600
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = DataStream
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
4.2.3 启动Flume
nohup bin/flume-ng agent \
-c conf \
-n a1 \
-f conf/s3.conf & \
-Dflume.root.logger=DEBUG,console &
4.2.4 S3存储数据分类效果概览
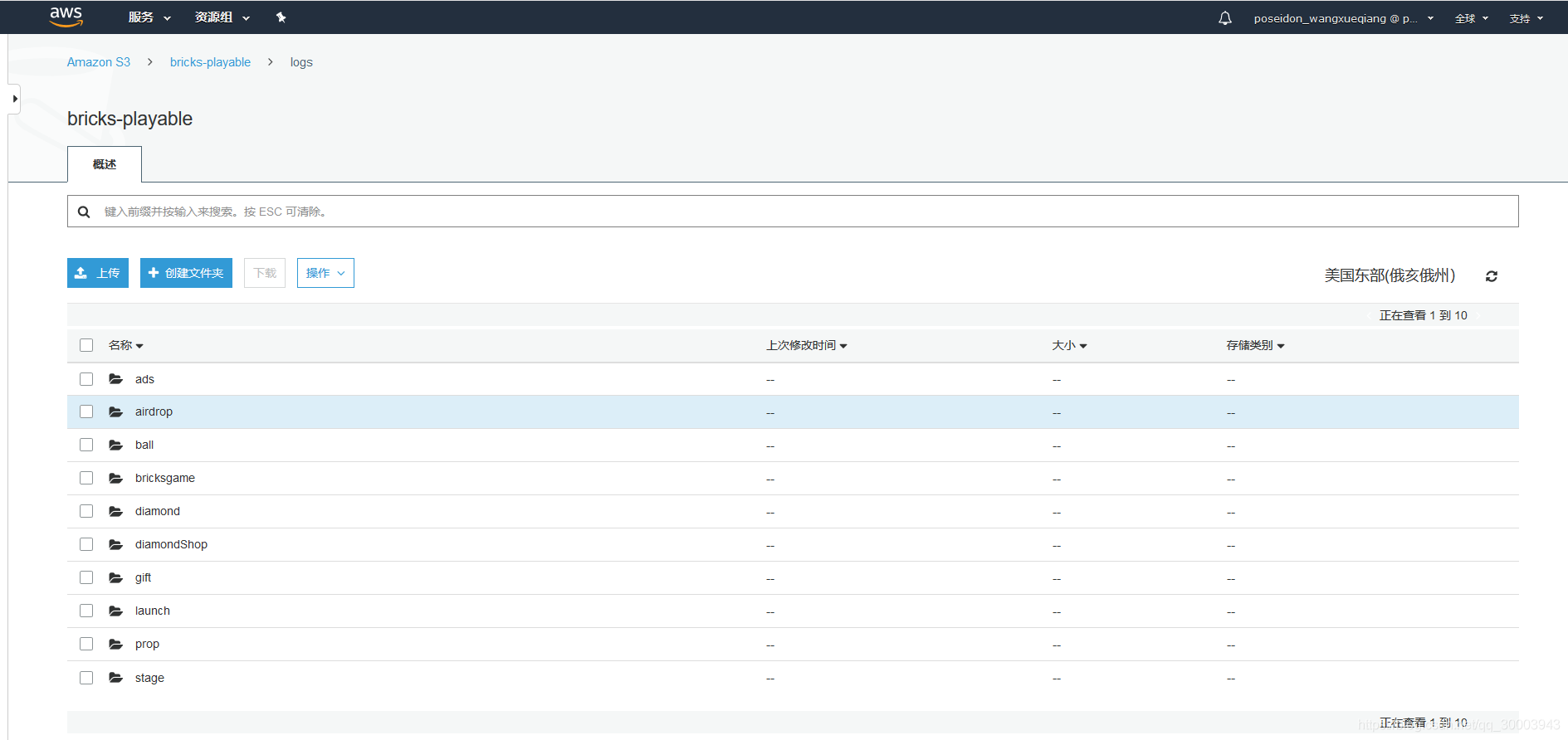
4.2.5 150w日活每天产生数据大小
| 文件名称 | 文件大小/天 | 文件描述 |
|---|---|---|
| ads | 2.8G | iOS用户广告行为 |
| diamond | 2G | iOS钻石产出与消耗数据 |
| diamondShop | 30M | 钻石商店页面 |
| dingyue | 7KB | 订阅消息 |
| gift | 1.2G | 礼物盒子消息 |
| launch | 650M | 游戏启动上报数据 |
| prop | 500M | 游戏道具产出消耗 |
| shopWindow | 60M | 弹窗消息 |
| stage | 10G | 关卡信息 |
| airdrop | 400M | 空头包 |
| ball | 900KB | 球皮肤 |
| bussiness | 17G | 安卓商业广告消息 |
| appsflyer | 18.7G | 安卓用户广告消息 |
| nginx-logs | 5G | WEB端请求日志 |
4.3 离线数据分析
Hive On Spark进行离线数据分析。
4.3.1 Hive表的创建
# 创建Hive外部表
# s3_stage | s3_launch | s3_ads | s3_diamond | s3_diamondShop | s3_gift | s3_airdrop | s3_prop | s3_ball|s3_shopWindow
CREATE EXTERNAL TABLE 表名(
uid STRING,
appVersion STRING,
appName STRING,
appPlatform STRING,
ip STRING,
countryCode STRING,
systimestamp BIGINT,
currentTime BIGINT,
clientTimeStamp STRING,
groupId STRING,
kindType STRING,
params Map<STRING,STRING>
)PARTITIONED BY
(ym string, day string)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
STORED AS TEXTFILE;
4.3.2 自定义UDF函数天周月起始时间
#添加编写的jar
ADD JAR /opt/apache/hive-3.1.2/lib/app-logs-hive-udf.jar
#注册UDF自定义函数 天周月起始时间
CREATE FUNCTION getdaybegin AS 'com.pusidun.applogs.udf.hive.DayBeginUDF';
CREATE FUNCTION getweekbegin AS 'com.pusidun.applogs.udf.hive.WeekBeginUDF';
CREATE FUNCTION getmonthbegin AS 'com.pusidun.applogs.udf.hive.MonthBeginUDF';
CREATE FUNCTION formattime AS 'com.pusidun.applogs.udf.hive.FormatTimeUDF';
4.3.3 Hive加载分区脚本
vim .exportData.sql
ALTER TABLE s3_stage ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/stage/${ym}/${day}/';
ALTER TABLE s3_launch ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/launch/${ym}/${day}/';
ALTER TABLE s3_ads ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/ads/${ym}/${day}/';
ALTER TABLE s3_diamond ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/diamond/${ym}/${day}/';
ALTER TABLE s3_gift ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/gift/${ym}/${day}/';
ALTER TABLE s3_airdrop ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/airdrop/${ym}/${day}/';
ALTER TABLE s3_prop ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/prop/${ym}/${day}/';
ALTER TABLE s3_ball ADD PARTITION(ym='${ym}',day='${day}') LOCATION 's3a://bricks-playable/logs/ball/${ym}/${day}/';
4.3.4 Hive定时任务脚本
vim hive-exec.sh
#!/bin/bash
systime=`date -d "1 day ago" +%Y%m-%d`
ym=`echo ${systime} | awk -F '-' '{print $1}'`
day=`echo ${systime} | awk -F '-' '{print $2}'`
cp /opt/s3/.exportData.sql /opt/s3/exportData.sql
sed -i 's/${ym}/'${ym}'/g' /opt/s3/exportData.sql
sed -i 's/${day}/'${day}'/g' /opt/s3/exportData.sql
4.3.5 Zeppelin整合Spark和Hive

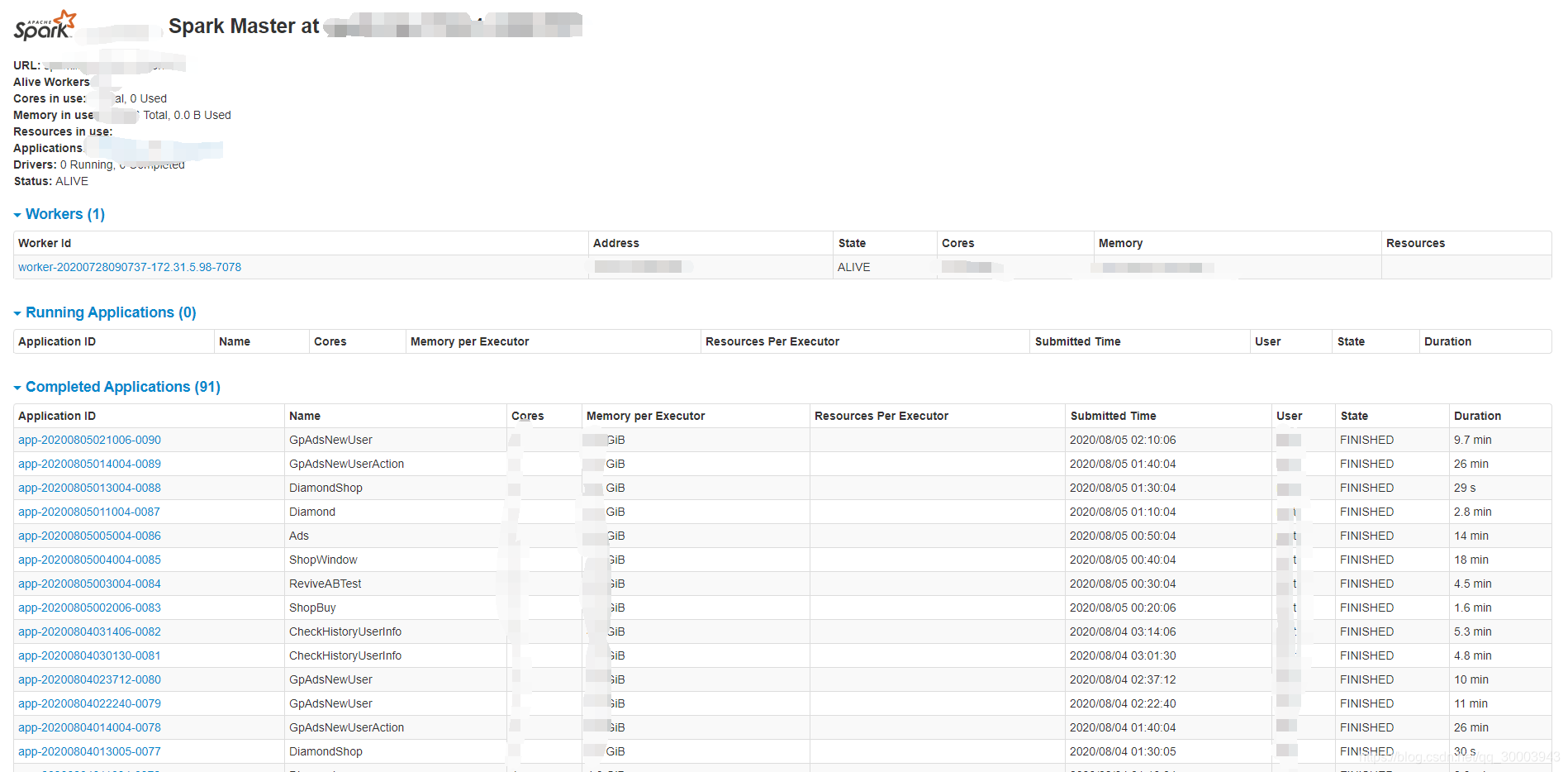
4.3.6 Spark作业日志
4.4 实时数据分析
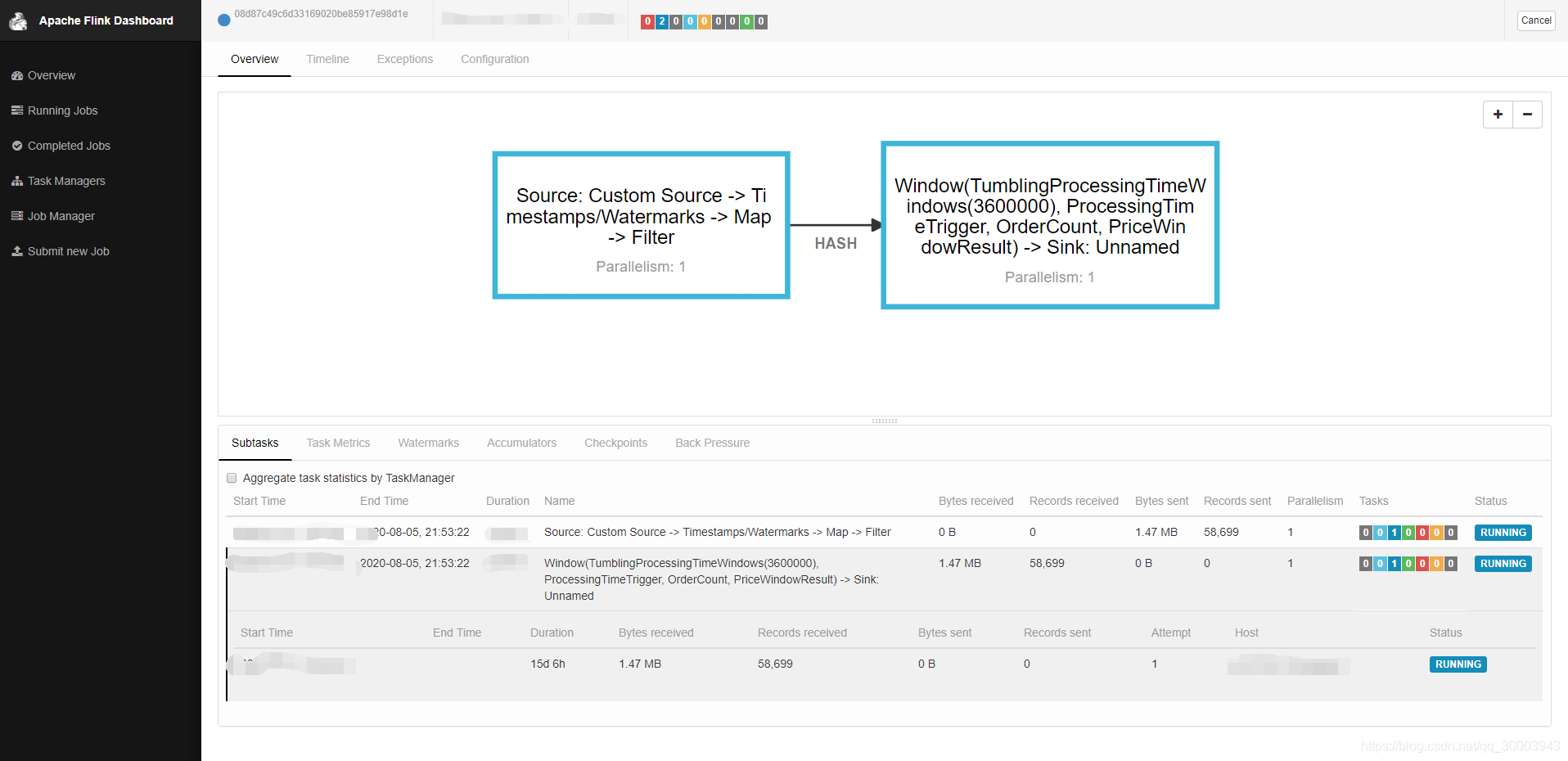
Fink消费kafka数据统计每1小时内购总额并写入ES、每小时url请求Top10、每小时日活人数。
4.4.1 Flink的WebUI
4.4.2 Flink统计每小时内购总数并写到ES
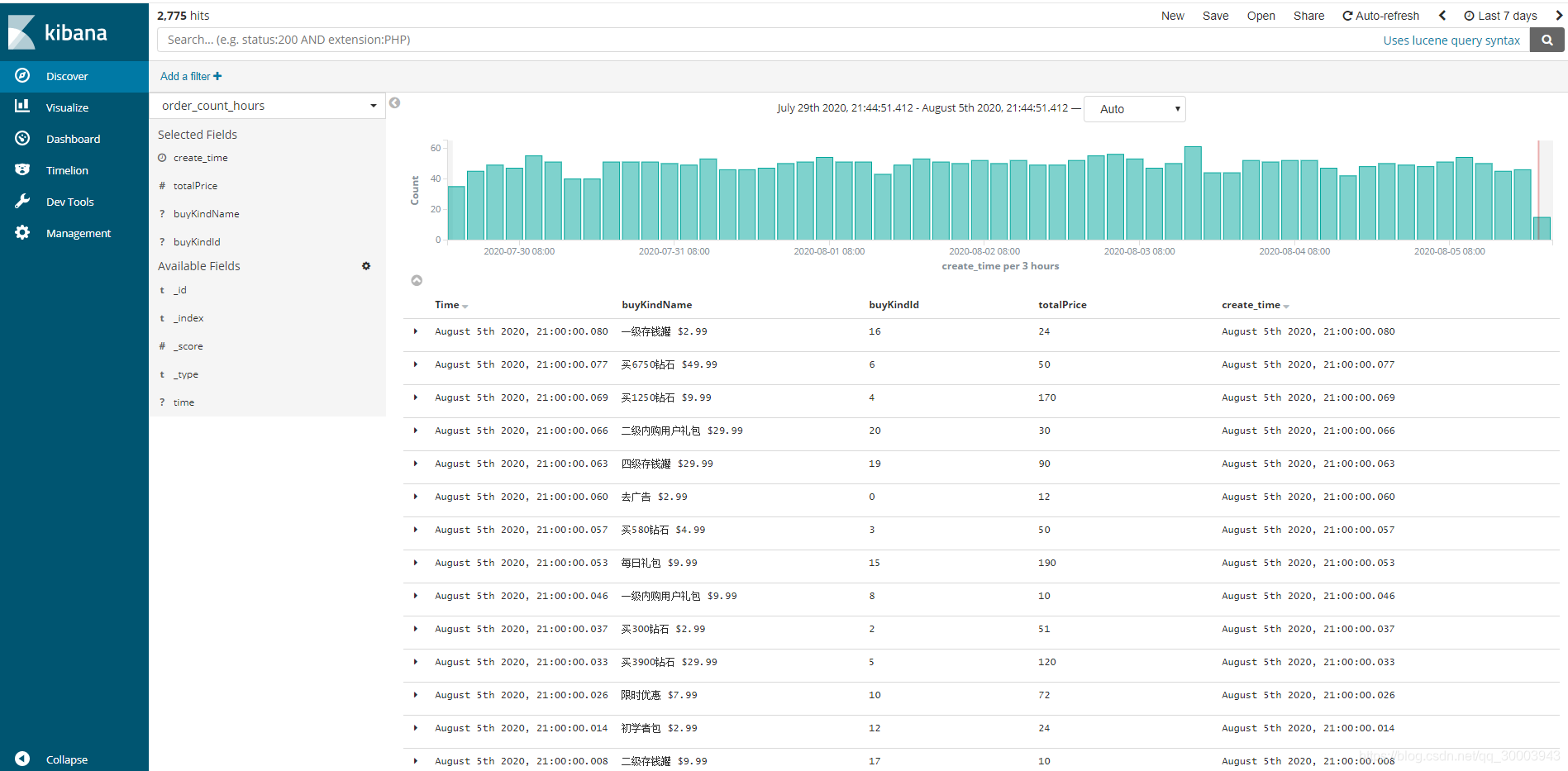
4.5 大数据集群监测
